
Abstract
Background Manual chart abstraction is a major bottleneck in clinical research. In oncology, important outcomes such as disease recurrence and the treatment history are often only documented in clinical notes, limiting the scale and quality of observational and epidemiologic studies. We developed an open-source pipeline that, in a HIPAA-compliant setting, can use any commercially available large language model (LLM) to abstract variables. We sought to understand if a wide range of variables could be abstracted from complex longitudinal oncology records with performance similar to that of expert medical oncologists.
Methods We randomly selected 100 patients from an institutional breast cancer cohort enriched for complex care. We abstracted a range of key variables from unstructured data, including dates of diagnosis and recurrence, clinical stage, biomarker subtype, genetic testing results, and prescribed systemic therapies, including treatment timing, intent, and reason for discontinuation. The inputs to the LLMs were unnormalized, unlabeled, and unedited clinical notes, pathology reports, med admin records, and demographics. Breast oncologists abstracted the same variables to create the reference standard. For systemic therapy extraction, a second oncologist and research coordinators served as comparators. In addition to variable-level performance, we examined whether survival and hazard-ratio estimates were similar for fully LLM-derived datasets compared with expert-derived datasets.
Results Among 100 patients, the median chart had more than 3,100 pages of text; patients received a median of 7 lines of therapy over 6.5 years of follow-up. The best-performing LLM achieved 99% concordance with the expert for recurrence status, 100% for germline BRCA1/2 pathogenic variant detection, 99% for hormone receptor status, 96% for HER2 status, 91% for clinical stage, 91% for PIK3CA mutation status, and 90% for ESR1 mutation status. For anti-cancer drug extraction, the best-performing LLM approached inter-oncologist variability. For exact therapy-line reconstruction, mean patient-level performance remained 9 percentage points lower than the second oncologist, although inter-LLM disagreement was similar to inter-oncologist disagreement. All four LLMs tested outperformed the research coordinators on systemic therapy abstraction. Recurrence-free survival, overall survival, and hazard ratio estimates were similar between expert-derived and LLM-derived datasets. In an external cohort of 97 young patients with early-stage breast cancer, the unmodified pipeline showed similar performance for recurrence detection and adjuvant endocrine therapy use.
Conclusions Off-the-shelf general-purpose LLMs in a fixed retrieval pipeline were able to abstract a range of variables from complex longitudinal oncology records with performance approaching inter-oncologist variability for key tasks, without any fine-tuning or institution-specific retraining. This approach offers a practical path to scaling the creation of research-grade retrospective datasets from narrative medical records.
Introduction
Clinical research depends on abstracting key variables from the electronic medical record and converting them into structured data for analysis.1,2 This manual process is how we build disease registries, retrospective cohorts, and many real-world evidence datasets. Abstracting information from the chart is labor-intensive and vulnerable to inconsistency across reviewers. Many key variables such as diagnoses, outcomes, biomarker results, treatment exposures, and disease progression are often documented only in free text rather than in structured fields. As a result, much of the clinically meaningful information in the narrative record is not currently used for research, which limits the completeness and quality of observational datasets.3,4
Breast cancer illustrates this problem clearly. Most metastatic breast cancers are recurrences of earlier-stage disease, but SEER only captures initial treatment for patients with de novo metastatic disease, who represent just 6% of new breast diagnoses.5,6 As a result, population-level estimates of metastatic breast cancer burden in the United States depend on simulation models and claims-based inference.5,7,8 Retrospective studies that inform clinical decision-making often rely on labor-intensive manual abstraction of smaller-than-ideal cohorts because identifying cancer recurrence is challenging at scale.9,10 Answering the full range of clinically meaningful questions through manual chart review is impossible.
Large language models (LLMs) may offer a practical way to automate this work. To date, most approaches have relied on proprietary systems or developing task-specific models trained on institutional data. These approaches limit the reproducibility, portability, and local control over protected health information.11-14 Therefore, we sought to understand if off-the-shelf general-purpose LLMs (e.g. ChatGPT, Gemini), available to many healthcare systems today in HIPAA-compliant environments, can reliably abstract complex longitudinal cancer records without fine-tuning, labeled training data, or institution-specific retraining.15 If successful, this approach could provide a practical path toward unlocking large volumes of clinical data for research.
We developed a chart abstraction pipeline able to use commercially available LLMs and applied it to patients with complex breast cancer histories. We compared the performance of the LLM-derived abstraction with expert oncologist review for recurrence, systemic therapy, tumor characteristics, and genomic testing across multiple LLMs. We chose a wide range of tasks to understand if the design was flexible, and to capture the key variables often missing from observational cancer datasets. Because it was unclear how to best measure abstraction of systemic therapies, we decided to benchmark this task to a second oncologist and to research coordinators. Lastly, we assessed if LLM-derived datasets preserved downstream survival and epidemiologic inference.
Methods
Study design and objectives
We compared a fully automated retrieval-based pipeline using commercially available LLMs to expert oncologist chart review for a range of variables (Table 1). The primary endpoints were agreement between LLM-derived and expert-derived data on cancer recurrence, including whether recurrence occurred and its timing, and on the number and composition of systemic treatment lines. Secondary endpoints were agreement on other clinical variables, comparison with research coordinators for selected variables, inter-oncologist variability in systemic therapy abstraction, and preservation of downstream inference when fully LLM-derived datasets were substituted for expert-derived datasets. This study was approved by the Stanford IRB under protocol 19482.
Date-based variables were evaluated using concordance within ±90 days in the primary analysis, with sensitivity analyses using alternate thresholds. Categorical variables were evaluated using exact concordance. Systemic therapy abstraction included both exact lines of therapy and component anti-cancer drugs, as well as matched-line start and stop dates, treatment intent, and reason for discontinuation. For genetic testing we had access to the files from Foundation Medicine and from the companies doing the germline genetic testing and so this was used as the reference.
^ Patient-level mean Jaccard similarity was used as the benchmark for inter-expert agreement in systemic therapy abstraction.
# For analysis, discontinuation reasons were collapsed to disease progression versus other. Progression included documented progressive disease, hospice enrollment related to advancing cancer, death, or decline in performance status in the setting of progressing disease. Other included planned completion, toxicity or adverse event, patient preference, clinician choice, and transfer of care.
Clinical characteristics from the first expert derived dataset of the 100-patient breast cancer cohort and measures of chart complexity and size.
Study cohort and data extraction
We randomly selected 100 patients from an institutional database of patients with breast cancer who had undergone either tissue or blood-based FoundationOne testing (Foundation Medicine, Cambridge, MA, USA).16 This intentionally enriched the sample for complex disease trajectories while preserving heterogeneity in documentation patterns and treating clinicians across the academic flagship campus and a community-affiliate practice.
Reference standard generation and human comparators
Four medical oncologists specializing in breast cancer care (JCD, NHD, MBM, and JLC) were each assigned a random subset of patients and asked to abstract the variables listed in Table 1. They were instructed to use all available data in the medical record, excluding external notes accessible only through Epic’s external note viewer Care Everywhere (Epic Systems, Verona, WI, USA).17 Experts were provided the clinical definitions used in the study (Supplementary Methods), but were not told how to abstract the variables.
For most clinical variables, a single expert abstraction served as the reference standard. Because systemic therapy abstraction was expected to be the most difficult task, and the hardest to directly measure, a second oncologist independently abstracted the same systemic therapy variables for each patient. This allowed inter-expert variability, rather than a single ground truth, to serve as the benchmark for performance. Experts were asked to reconstruct lines of therapy, list their component drugs, assign start and stop dates, classify treatment intent as curative or palliative, and determine whether discontinuation was due to disease progression or another reason such as toxicity or patient preference.
As an additional point of comparison, research coordinators had previously abstracted the original date of diagnosis, the date of distant metastatic disease, and the same systemic therapy variables. Because the research coordinator abstraction was performed in 2022, all comparisons involving research coordinators were censored on June 1, 2022.
LLM abstraction pipeline overview
A detailed description of the pipeline is in the Supplement and GitHub repository (Figure 1). On January 10, 2026, we downloaded all available text-based electronic medical record documents for each patient from Stanford’s research warehouse.18 Pathology reports, demographics, clinical notes, and medication administration records were exported as separate CSV files, with one row per document and one folder per patient. Original metadata, including document type, author, and entry date, were preserved. The warehouse does not preserve images, scanned documents, or screenshots in the notes. No preprocessing, normalization, or cleaning of source documents was performed before ingestion into the pipeline.

Text documents from the electronic medical record were exported from the institutional research warehouse, segmented into chunks, and indexed for exact-word, BM25, and semantic retrieval. For each task, retrieved text was then passed to commercially available LLMs using schema-constrained prompts to generate structured outputs.
The pipeline takes each narrative document and segments it into chunks approximating paragraph-length excerpts. These then can be retrieved and passed to the LLM with a task-specific prompt. Chunks are embedded to enable semantic retrieval.19 For each variable in Table 1, retrieval was restricted to the document types most relevant to manual abstraction of that variable, and custom prompts were used for each variable. For example, for the dates of diagnosis, pathology reports were used first, followed by clinical notes. Retrieval used a combination of search strategies to find candidate text chunks including exact word search, BM25, and semantic embedding queries depending on the variable (Supplementary Table S1).20,21
Retrieved text chunks were then provided to HIPAA-compliant, commercially available LLMs. We evaluated GPT-5, GPT-4o, DeepSeek-R1, and Gemini 2.5 Pro through Stanford’s SecureGPT platform.22 Prompts and the evidence sent to the LLMs were identical for each task. Tasks were stateless (i.e. no chat history), but for multi-pass tasks, intermediate outputs were carried forward. After pilot development, prompts, retrieval parameters, and task-specific workflows were fixed before final model evaluation. For a given task, all models received identical text chunks and prompts. The LLMs had no access to expert annotations nor structured reference data.
Outcomes and statistical analysis
The primary endpoints of this descriptive study were agreement between LLM-derived and expert-derived abstraction for recurrence dates and lines of systemic therapy. We also evaluated the concordance for the additional variables listed in Table 1. For all non-drug variables, we prespecified greater than 90% agreement with expert-derived data for at least two LLMs as an arbitrary threshold for encouraging performance. For date-based variables, agreement was defined as concordance within ± 90 days, which we prespecified as a clinically meaningful threshold and examined ± 30 days for select variables. Categorical variables required exact concordance. For mutation testing, the primary analysis focused on mutation presence, with all other outcomes treated as negative or not found.
For prescribed systemic therapy, we evaluated both exact lines of therapy and the anti-cancer drugs contained within those lines. We prespecified inter-oncologist variability as the benchmark for systemic therapy performance. We considered overlap of the confidence intervals for patient-level mean Jaccard similarity between at least two LLMs and the second oncologist as encouraging performance.23 After therapy-name normalization, predicted and reference lines were matched using a greedy one-to-one algorithm based on temporal proximity. We also calculated precision, recall, and F1 score for both line-level and drug-level extraction. Additional analyses included agreement on the number of therapy lines and, among matched lines, agreement on start and stop dates within ± 30 days, treatment intent, and reason for discontinuation.
After abstraction, we created two separate analytic datasets: one fully LLM-derived and one expert-derived. We then examined overall survival from initial breast cancer diagnosis and invasive recurrence-free survival. Censoring was done at the last note in the chart. Differences in survival were measured using log-rank tests and visualized with Kaplan–Meier curves. Because death registry linkage was not used, and less than half the cohort had a documented death date in the ground truth data, we conservatively estimated survival by assuming that patients without a recorded death date were dead at their last clinical follow-up. The standard Kaplan-Meier censoring approach is also presented.24 To compare effect estimates in human-derived and LLM-derived datasets, we evaluated univariate hazard ratio estimates for stage (4 vs 1 – 3) and hormone receptor status (negative vs positive) on overall survival and recurrence-free survival for the early stage patients. We compared hazard ratio estimates and 95% confidence intervals from expert-derived and LLM-derived datasets and used Cochran’s Q test as a formal test for heterogeneity between effect estimates.
Confidence intervals (CIs) for all agreement and performance metrics were estimated using bias-corrected and accelerated bootstrap resampling at the patient level with 1,000 iterations.25 All analyses were conducted in R version 4.5.2 (R Foundation for Statistical Computing, Vienna, Austria) using base functions and the boot and survival packages. The analytic code is available on GitHub.
External Validation in Young Breast Cancer Patients
To examine performance in a clinically distinct population, we evaluated a previously manually abstracted cohort of young patients diagnosed with breast cancer before becoming pregnant.26 We compared recurrence detection and receipt of adjuvant endocrine therapy for patients who had an initial invasive diagnosis and hormone receptor–positive disease. We compared expert-abstraction to the two best performing LLMs. The pipeline, retrieval strategy, and prompts were applied to this cohort without modification.
Results
For simplicity, the main text focuses on the two LLMs that performed best overall; results for all four models are in Supplementary Figure S1 and Supplementary Table S2.
The 100-patient cohort was complex with around 1,100 individual drugs prescribed in a median of 7 lines of therapy (interquartile range [IQR], 4.75 – 9) over 6.5 years of follow-up from diagnosis (IQR, 3.7 – 9.9 years). The median chart size was approximately 2.3 million tokens or roughly 3,100 pages of text. The average time to process an individual patient ranged from 1 – 11 minutes (Supplementary Table S7).
Agreement for non-systemic therapy variables
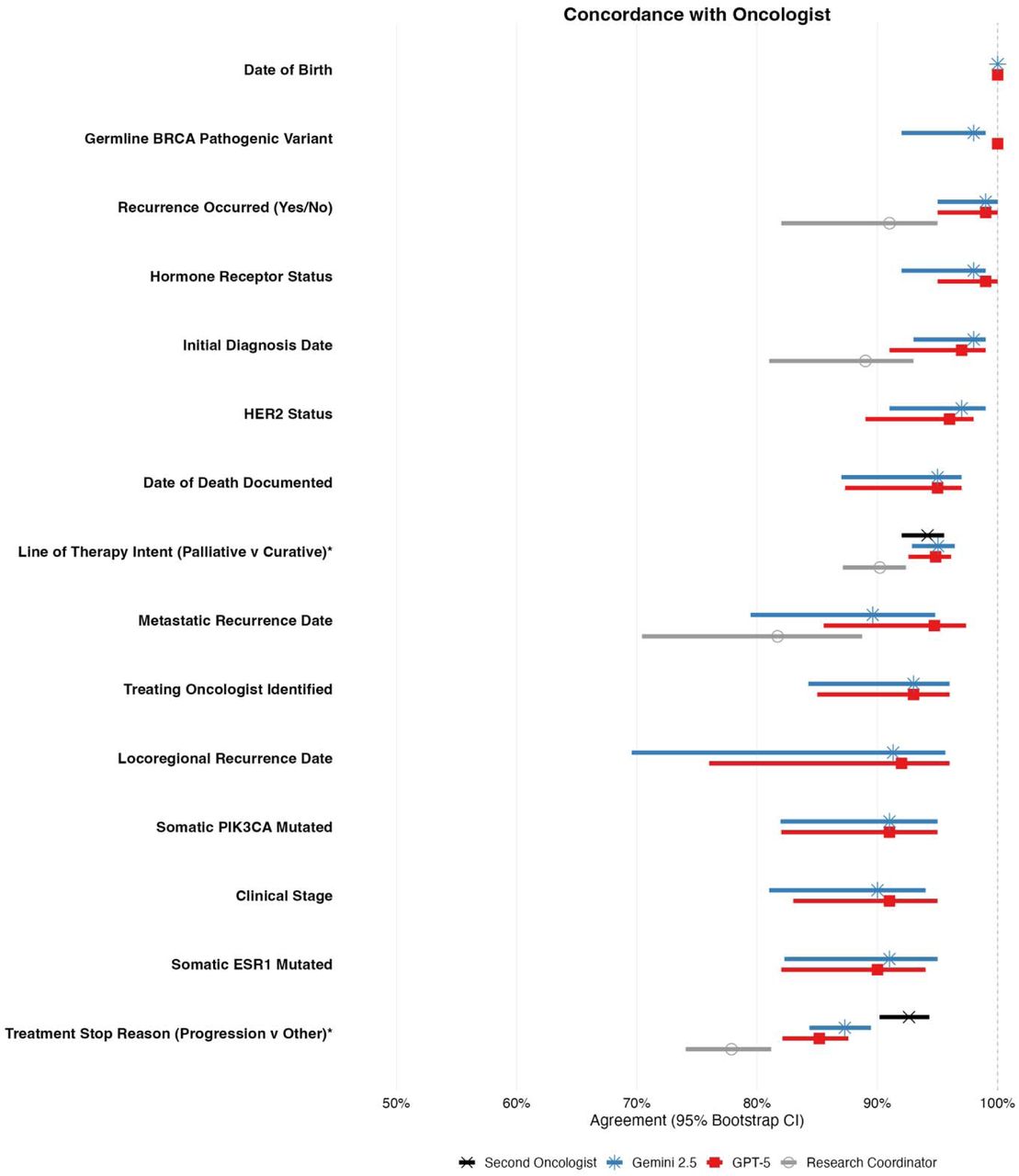
Across non-systemic variables, the pipeline showed high agreement with expert oncologist abstraction (Figure 2; Supplementary Figure S1; Supplementary Table S2). The two best-LLMs achieved at least 90% agreement across all 13 variables. Agreement was highest for variables anchored to pathology reports or demographic data. Variables with heterogeneous documentation, those requiring longitudinal reasoning such as stage assignment, and variables often available only in scanned PDFs or screenshots not retained in the research warehouse had lower agreement (Figure 2; Supplementary Table S6).

Forest plot showing agreement with expert oncologist abstraction and 95% bootstrap confidence intervals for the best and second-best performing LLMs across key clinical variables. Research coordinators are shown for variables they previously abstracted. Date-based variables were evaluated using concordance within ± 90 days. Categorical variables were evaluated using exact concordance.
* Treatment intent and reason for discontinuation were evaluated only among matched therapy lines; evaluable denominators were n = 651 for the second oncologist, n = 645 for Gemini, n = 620 for GPT-5, and n = 551 for the research coordinator.
For the original diagnosis date, the two best-performing LLMs agreed with the expert on more than 97% of patients. No original diagnosis dates differed by more than 1 year (Supplementary Figure S2). For metastatic recurrence, agreement within ± 90 days was 90% and 96% for the two best-performing LLMs; 90% and 82% of recurrence dates were within 30 days. Locoregional recurrence had high date concordance (Supplementary Figure S2), but with more false negatives than metastatic recurrence. The two best-performing LLMs missed 3 and 5 events, respectively. In the 6 total unique cases, the LLMs had classified the recurrence as distant metastatic rather than locoregional. Full model-by-model results are shown in Supplementary Table S2, with an expanded forest plot in Supplementary Figure S1, confusion matrices for stage and hormone receptor and HER2 status in Supplementary Figure S3, and a qualitative error analysis in Supplementary Table S6.
Systemic therapy abstraction relative to inter-expert variability
Compared with the first expert oncologist, the second oncologist achieved a mean patient-level Jaccard similarity of 0.95 (95% CI, 0.92 to 0.96) for all prescribed anti-cancer drugs and 0.86 (95% CI, 0.81 to 0.89) for reconstructing the exact lines of therapy (Figure 4; Supplementary Tables S2 and S3). Among matched lines (n = 651), oncologist agreement was 93% for treatment intent, 92% for reason for discontinuation, 98% for start date within ± 30 days, and 90% for stop date within ± 30 days.

Kaplan–Meier curves comparing survival estimates generated from fully expert-derived data and fully LLM-derived data for the two best-performing LLMs. Solid curves show a conservative lower bound analysis where censoring is assumed to represent death/recurrence. The dashed curves show the standard Kaplan–Meier approach with censoring at last follow-up for comparison. (A) Overall survival. (B) Invasive recurrence-free survival among patients with stage 1 – 3 diseases. Differences between expert and LLM curves were separately assessed using log-rank tests.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Violin plots showing patient-level Jaccard similarity for abstraction of all prescribed anti-cancer drugs (Panel A) and exact therapy lines (Panel B). Diamonds indicate medians and bars are the interquartile ranges. Results are shown for the second oncologist, the two best-performing LLMs, and research coordinators relative to the expert oncologist reference.
The LLMs had a similar mean patient-level Jaccard similarity of 0.91 (95% CI, 0.89 to 0.93) and 0.90 (95% CI, 0.87 to 0.92) for prescribed anti-cancer drugs with CIs that overlapped those of the second oncologist. For lines of therapy, they were notably lower at 0.77 (95% CI, 0.72 to 0.81) and 0.73 (95% CI, 0.69 to 0.78). When the two best-performing LLMs were compared with each other, they disagreed to a similar extent as the two expert oncologists did with Jaccard similarities of 0.96 (95% CI, 0.94 to 0.98) for drugs and 0.84 (95% CI, 0.79 to 0.87) for lines of therapy. Violin plots for all four LLMs are shown in Supplementary Figure S6.
Research coordinators performed worse than all LLMs on systemic therapy abstraction, with a patient-level Jaccard similarity of 0.70 (95% CI, 0.67 to 0.74) for prescribed anti-cancer drugs and 0.53 (95% CI, 0.49 to 0.58) for the lines of therapy. Even after we post hoc collapsed all aromatase inhibitors and all taxanes into single entities, research coordinators still had worse performance than the worst LLM for line reconstruction (0.65 vs 0.71). Abstraction performance was stable for most LLMs across large and long charts, but performance declined for research coordinators as the chart got bigger (Supplementary Figure S5). A representative treatment timeline for a complex patient is shown in Supplementary Figure S4.
Preservation of survival and effect estimates
Cohort level inference for survival was preserved when fully LLM-derived datasets were used in place of fully expert-derived datasets (Figure 3). Because fewer than half of patients had a documented date of death, overall survival estimates were sensitive to censoring assumptions, with the median in the expert-derived dataset differing by approximately 3 years depending on the censoring rule; Figure 3’s solid lines uses a conservative approach in which patients without a documented death date are treated as having died at their last clinical follow-up. The dashed lines show traditional censoring at last follow-up. The censoring rule did not change the similarity of survival estimates for LLM and expert. Median overall survival was 78.2 months for the expert and 78.2 months for the two LLMs (log-rank P = 0.99 and 1.00). Median recurrence-free survival was 34.9 months for the expert and 34.9 months for the two LLMs (P = 0.91 and 0.97).
When comparing the hazard ratio and confidence intervals for the risk of death for disease stage they were similar for expert-derived and LLM derived datasets: 2.80 (95% CI, 1.57 to 5.00) in the expert-derived dataset, compared with 2.85 (95% CI, 1.38 to 5.86) and 2.58 (95% CI, 1.25 to 5.32) for the best two LLMs. For hormone receptor-negative versus hormone receptor-positive disease, the hazard ratio was 1.86 (95% CI, 1.18 to 2.93) in the expert-derived dataset, compared with estimates that were numerically similar but did cross 1.00 for the LLMs with ratios of 1.66 (95% CI, 0.91 to 3.00) and 1.60 (95% CI, 0.87 to 2.91) in the corresponding LLM-derived datasets. Cochran Q heterogeneity testing did not identify significant differences in these effect estimates (Supplementary Table S5).
External Validation in Young Breast Cancer Patients
In an external cohort of 97 young patients with hormone receptor–positive invasive breast cancer diagnosed before pregnancy, expert manual abstraction identified 11 recurrences, compared with 13 and 13 identified by the two leading LLMs. One discordant case was an expert error; the other was an LLM error. The LLM error was on the smallest chart in the cohort—there were no Stanfrd notes within 7 years of the documented recurrence event and it could only be identified in outside hospital notes that were not in the research warehouse for data ingestion. Receipt of adjuvant endocrine therapy had an F1 score of 0.99 and 0.96 for the two LLMs.
Discussion
In this retrospective study of 100 patients with complex breast cancer histories, a pipeline using off-the-shelf general-purpose LLMs abstracted clinical variables from the medical record with high concordance with expert oncologists. Concordance was highest for variables anchored to pathology, such as estrogen receptor status, and lowest for variables requiring clinical reasoning, such as why a treatment was stopped. For abstracting the anti-cancer treatments, the best-performing model approached inter-oncologist variability. However, there was a clear difference in how the oncologists and LLMs reconstructed therapy lines. Despite differences at the individual patient level, cohort level survival and hazard ratio estimates were similar when fully LLM-derived datasets were compared to expert-derived datasets.
Manual chart abstraction is a major bottleneck in clinical research. Because we write notes in unstructured text, answering many of the clinically meaningful questions is impractical because creating the analytic dataset is too labor-intensive.5 We have high uncertainty across many clinical domains even when, in principle, the information needed to answer these questions exists in the medical record. This is especially true for rare and complex diseases, settings with heterogeneous practice patterns, areas in which unreplicated retrospective studies dominate clinical decision-making, and domains with less mature disease registries than cancer. A practical implication of our approach is that it would make conducting multi-institutional cohort studies much easier: institutions can share a validated common abstraction pipeline while keeping patient-level data local.13 Doing this would allow consortiums to build large harmonized cohorts to address a broad range of clinically important questions.
Our results highlight challenges that extend beyond LLMs to any research in which chart review is a central component. Sparse documentation remains a major barrier, particularly in fragmented health systems such as the United States. In health systems with more centralized longitudinal records, we would expect the LLM-pipeline approach to be powerful. As an example, the lack of high-quality death records in our analysis shows how a lack of data integration, and the downstream analytic assumptions, shift results by clinically meaningful amounts. Variables, syndromes, and diseases with ambiguous clinical definitions remain difficult to abstract and to study. Poorly designed abstraction frameworks, whether given to an LLM or a human-abstractor, will generate poor datasets.27
As LLM-based abstraction becomes more common, whether through abstractors copying and pasting into chatbots or through validated pipelines, it will be critical to establish norms for study design, transparent definitions, statistical rigor, and benchmarking against domain experts.28 Most retrospective studies are fundamentally correlative and, on their own, do not support causal inference.29 Scaling abstraction will not get us closer to the truth without corresponding scientific rigor.
This study has limitations: it was conducted in a single healthcare system and focused on a single disease. Effective abstraction was contingent on the relevant data being present in the record. Errors could be because of a lack of data, badly designed retrievers, badly designed prompts, or LLM reasoning errors. There remains a clear gap between experts and LLMs on the most complex abstraction tasks, although we expect this gap to narrow as the LLMs improve over time (Supplementary Figure S1).
Conclusion
Off-the-shelf general-purpose LLMs in a fixed retrieval pipeline can abstract clinically meaningful variables from complex longitudinal oncology records. Performance was strongest for variables anchored to pathology and lower for ones that required clinical interpretation. Although a gap remained at the individual-patient level, survival and hazard ratio estimates at the cohort level were preserved. These findings suggest that LLM-based abstraction could enable the creation of large research-grade retrospective datasets that were previously impractical to assemble, thereby supporting a broad range of clinical questions. Realizing this potential will require carefully designed abstraction tasks, validated outputs, and cautious interpretation of results.
Data Availability
The analytic code and core abstraction pipeline will be made publicly available on GitHub upon publication.
Prior Presentations
This work was presented as a poster at American Society of Clinical Oncology Annual Meeting 2025 and the San Antonio Breast Cancer Symposium 2025
Funding
This work was supported by the Stanford Center for Digital Health
Competing Interests / Conflicts of Interest
JCD: Stock Ownership: Johnson & Johnson, Merck. JLC: research funding to her institution from Effector Therapeutics and Novartis.
Data and Code Availability
The analytic code and core abstraction pipeline will be made publicly available upon publication. Please contact jcdicker{at}stanford.edu for collaborations and early access to the pipeline.
Acknowledgements
We would like to thank our research coordinators Jessica Orford, Sonia Rios-Ventura, and Rozelle Laquindanum.
References



