
Abstract
The duration of immunity to SARS-CoV-2 is uncertain. Delineating immune memory typically requires longitudinal serological studies that track antibody prevalence in the same cohort for an extended time. However, this information is needed in faster timescales. Notably, the dynamics of an epidemic where recovered patients become immune for any period should differ significantly from those of one where the recovered promptly become susceptible. Here, we exploit this difference to provide a reliable protocol that can estimate immunity early in an epidemic. We verify this protocol with synthetic data, discuss its limitations, and then apply it to evaluate human immunity to SARS-CoV-2 in mortality data series from New York City. Our results indicate that New York’s mortality figures are incompatible with immunity lasting anything below 105 or above 211 days (90% CI.), and set an example on how to assess immune memory in emerging pandemics before serological studies can be deployed.
Introduction
The presence and duration of immunity to novel viruses is traditionally determined through longitudinal serological studies. By characterizing antibodies against a problem virus and tracking the serum levels of these antibodies in a population, for a long enough period, it can be determined with a solid standard of evidence whether the virus induces immunity and how long that immunity lasts.
This method for studying immunity is statistically reliable, but it can demand a very long time and requires ample human and technical resources. Such caveats do not usually pose a problem, but they have become relevant in the case of the recent 2019 coronavirus out-break. COVID-19 presents the right combination of infectivity and mortality to cause a pandemic of unprecedented global proportions that became clinically and economically relevant in very short timescales, far exceeded by those required for longitudinal serological studies.
Common human coronaviruses causing cold and flulike symptoms of mild degree typically leave an immune memory lasting from six to twenty-eight months [1]. The determinants of coronavirus and rhinovirus immunity have been widely studied for decades and are moderately well understood, as are those of influenza [2]. These diseases leave some immunity, but they can reinfect patients as soon as half a year after.
The mechanisms enabling reinfection strive from simple to elaborate. In the case of influenza and rhinoviruses, highly polymorphic proteins change yearly or faster and thus pathogens escape immune memory through mutation: they are virtually a new pathogen [2, 3]. There is also some evidence that homologous reinfection may contribute to multi-wave influenza outbreaks. Due to previous infections generating an insufficient or non-lasting immune response, recovered patients can become infected again [4]. Other human pathogens such as herpes virus, human cytomegalovirus (HCMV), and human immunodeficiency virus (HIV) elude immunity without fully leaving the human body. This persistence in the face of immune surveillance and medicine is not unique to viruses, as it is well documented in bacteria and tumor cells [5–8]. The populations of these cellular pathogens achieve persistence through the complex interplay of different factors, including extrinsic and intrinsic noise in therapeutic targets, mutation, directly compromising immune function, subpopulations with distinct growth rates, and other phenomena. In viruses, lysogeny often plays a pivotal role, as may do infection of immune cell types.
SARS-CoV-2 is phylogenetically a coronavirus, so the standard of evidence by default would indicate that it induces immunity lasting from one to two years. However, since early in the pandemic, recovered patients have tested positive after previously testing negative. For a while, this rose concerns that SARS-CoV-2 could be not inducing immunity, or persisting in the body after recovery. It is now becoming evident that these positives at least were induced by harmless remains of viral material that endure in the human bloodstream weeks after disease has subsided. But, could immunity after infection be virtually non-existing after all? The presence, extent, and particularities of human immunity to SARS-CoV-2 are still relevant for academics, health professionals and the broader public, and require further research.
Serological studies are the main tool to that aim and continue to unfold as we write this study, with preliminary results already being published [9, 10]. In the meantime, lack of further evidence on human immunity to SARS-CoV-2 delays our full understanding of COVID-19, leads to mismanagement of medical resources such as masks in conditions of scarcity (as the ones we have seen during this pandemic), and sets recovered patients as putative contagion sources, among other undesirable outcomes.
Theoretical alternative approaches to detecting immunity would be desirable in these circumstances; and in principle identifying immunity times should be as simple as inferring the value of a free parameter by fitting an epidemiological model to field data. However, nonlinear dynamical systems like those characteristic of epidemics have a high degree of inherent uncertainty, which makes prediction through conventional, deterministic means inefficient. System variables such as the population of infectious or recovered patients may follow any of a wide array of possible trajectories, and we cannot know which one they will take until they do so [11].
Despite these hurdles, data assimilation techniques are a set of mathematical tools that have provided success in forecasting epidemics [12]. Within these methods, ensemble adjustment Kalman filters (EAKF) have shown capable of providing accurate predictions in a system with many variables [13].
By using Bayes’s theorem to update a model’s predictions with observations at a series of points, uncertainty in a further forecast is reduced, and the span of possible posterior trajectories is limited [14]. The better the measurements (having less uncertainty themselves than the predictions) and the closer in time to the present, the better the updated forecast will be. These Bayesian approaches were originally developed in the context of large-scale geophysical problems and readily and most notably applied to weather predictions [15, 16]. More recently, they have been adapted to epidemiology too, where they became the state of the art in epidemiological forecasting, also in the COVID-19 pandemic, e.g., [17], see also [18] for a related method.
Here, we first examine the impact of immunity memory in the dynamics of a sound epidemiological model of COVID-19. We then estimate the capacity of EAKF techniques to infer the duration of this memory and then apply this approach to mortality time series from New York City (NYC), discerning immunity times against SARS-CoV-2 with reasonable accuracy. Finally, we examine the implications of the presence of immunity in the post-pandemic dynamics. This work thus provides reliable information about human immunity to SARS-CoV-2 and also represents an alternative to longitudinal serological studies for use against future emergent pandemics.
Results
Impact of immunity memory on a COVID-19 epidemiological model
We used an epidemiological model in which the total population is divided into a number of classes [19] (Figure 1). The specific compartments represent our current understanding of COVID-19 progression. Note that the infected population is divided into five (right column in Fig. 1) and that we also included two different mortality rates for critical cases because mortality depends strongly on whether there are available beds in Intensive Care Units (ICUs; Methods and Supplementary Material for the model details). All associated parameters in this model are available except for the infection rate β and the immunity memory τ (Supplementary Material). The fundamental categories resemble those of the well-known SEIRS model [20] in that the recovered population becomes susceptible after some duration of immunity (τ). However, the particularities of the COVID-19 progression are such that a minimal SEIRS cannot predict the mid- and long-term dynamics of the population well enough (Fig. S1 and Supplementary Material).
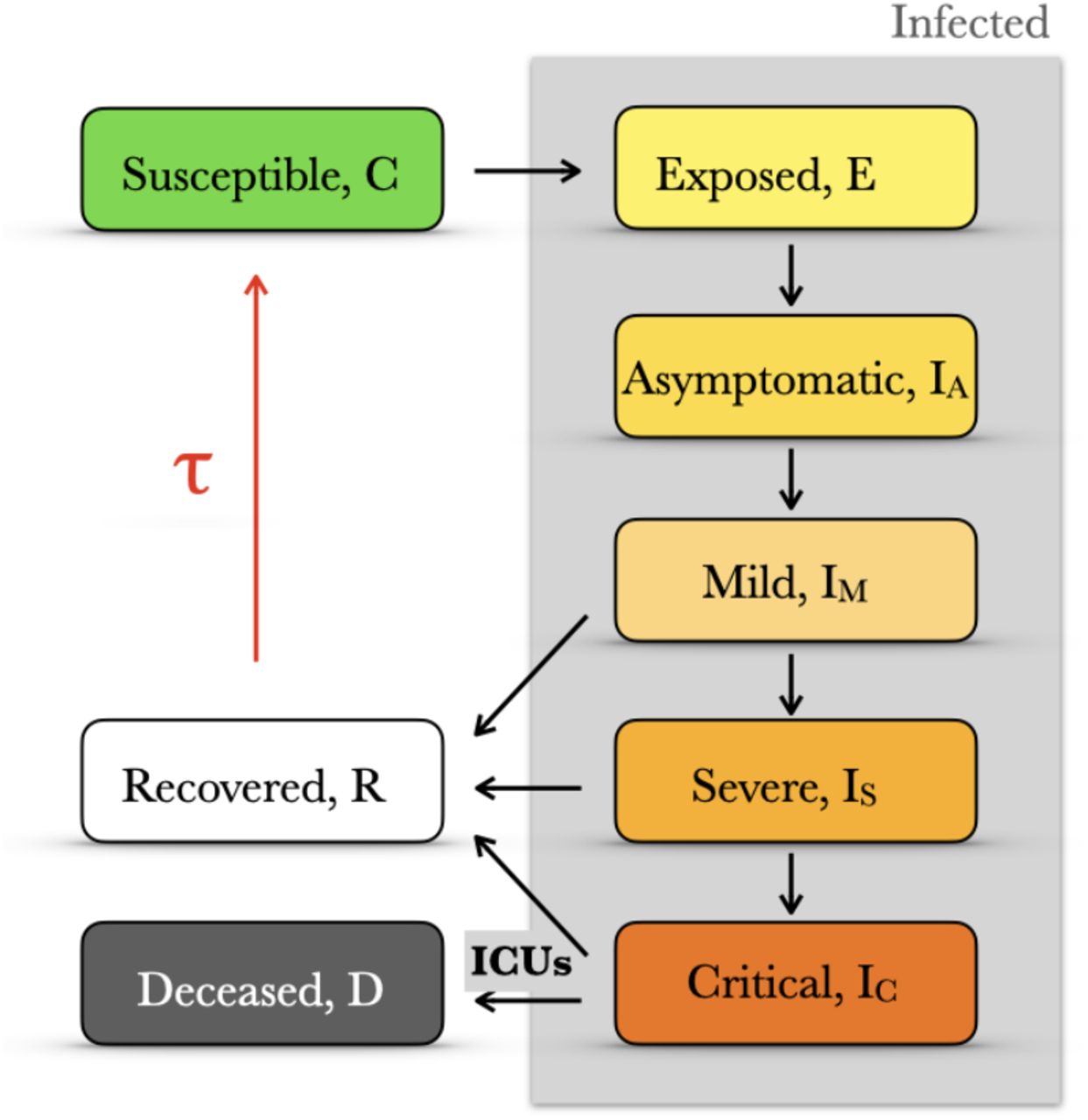
We introduce a compartmentalized epidemiological model with five infected categories (gray shading). Note that the accessibility of ICUs determines the rate to deceased and that those individuals recovered after infection may lose their immunity and become again susceptible after a finite time τ (red arrow). See Supplementary Material for model details.
In addition, we performed a variance-based global sensitivity analysis [21, 22] of the model (Fig. S2 and Supplementary Material). In particular, it illustrates the importance of the parameters related to the mild cases in shaping the deceases time series, the peak height and the total number of deceases after a year of pandemic whereas the infection rate tunes mainly the timing of the pandemic peak.
First, we study how the loss of immunity after infection impacts daily deaths (dD/dt) in our COVID-19 epidemiological model. The initial condition is a single exposed case, with a constant and intermediate value of the infection rate (Figure 2A). We find analytically that in the short term, i.e., during the exponential growth of infected cases, the development of immunity has no effect on the initial number of secondary infections R0 (Supplementary Material): there is not enough time for the re-circulation of the recovered back to the susceptible population.

(A) Different time series of daily deceases depending on the value of the immunity memory τ (β = 0.5 days-1). (B) The peak height, i.e. maximum number of deceased individuals in a single day, and the duration of the “first-wave” (inset) increase with shorter immunity times. However, the former increases with the infection rate, as opposed to the latter. (C) A finite value of immunity memory induces intrinsic seasonality on the model what produces subsequent epidemic peaks with time. This seasonality depends heavily on the interplay between the infection rate and the immune memory. Data shown for τ =3 months.
However, in the mid-term of the epidemic starting at the departure from exponential growth and up to the first noticeable reduction in daily deceases, a shorter immunity memory time raises the overall number of daily deceases. It also promotes a more prolonged duration of the epidemic as estimated by the time daily deceases stay above 75% of the maximum. Finally, in the long term, beyond the first peak, a finite immunity memory promotes the appearance of new epidemic waves.
The duration of the immunity time also shapes the dependence with β of the peak number of daily cases dD/dtmax and the duration of the epidemic (Figure 2B). As expected, dD/dtmax increases with the infection rate β but decreases for increasing τ. In addition, we observe that dD/dtmax for τs beyond a threshold are hardly distinguishable, e.g., data for τ = 3 months and τ = 1 year. Moreover, the duration of the first peak decreases together with both increasing β and τ. Figure 2C displays the intrinsic seasonality derived from a finite immunity time. The height and timing of the secondary peaks are strongly dependent on both β and τ, data shown is for a fixed value of τ = 3 months. This subscribes earlier projections obtained with a multi-strain model [23].
Predicting immunity memory of an ongoing epidemic
A finite value of the immunity time impacts the time series of daily deceases only after the exponential growth, and starting around the peak of the first wave. To notice these implications, we required a considerably advanced epidemic. What about an ongoing epidemic? This would need the real-time assessment of the epidemic parameters and the ability to forecast the short-term dynamics after the epidemic passes the peak.
While this kind of forecasting is intrinsically difficult [13], it is now possible to apply filtering techniques that recently demonstrated valid in this problem by integrating model predictions and data [17, 23–25]. We thus adopted a specific recursive filtering technique known as EAKF to infer the immunity memory duration in the course of an ongoing epidemic (see Supplementary Material for a brief intro to EAKF) [11, 14].
To describe a typical scenario, we first simulated a synthetic time-series with the deterministic model that would represent real data (Figure 3A-C). We then ran 100 independent iterations of the EAKF protocol, with different initial conditions, to estimate dD/dt (everyday deaths) and the “hidden” parameters (βsynth and τsynth). To assess the performance of our protocol, we compute the relative errors between the target values and the median of predictions. The similarity between the predicted and real curve of dD/dt is evident (Fig. 3A). Note that the estimates of β and τ improve mostly before and after the epidemic peak, respectively (Fig. 3B-C). This trend is in agreement with our results from the previous section.
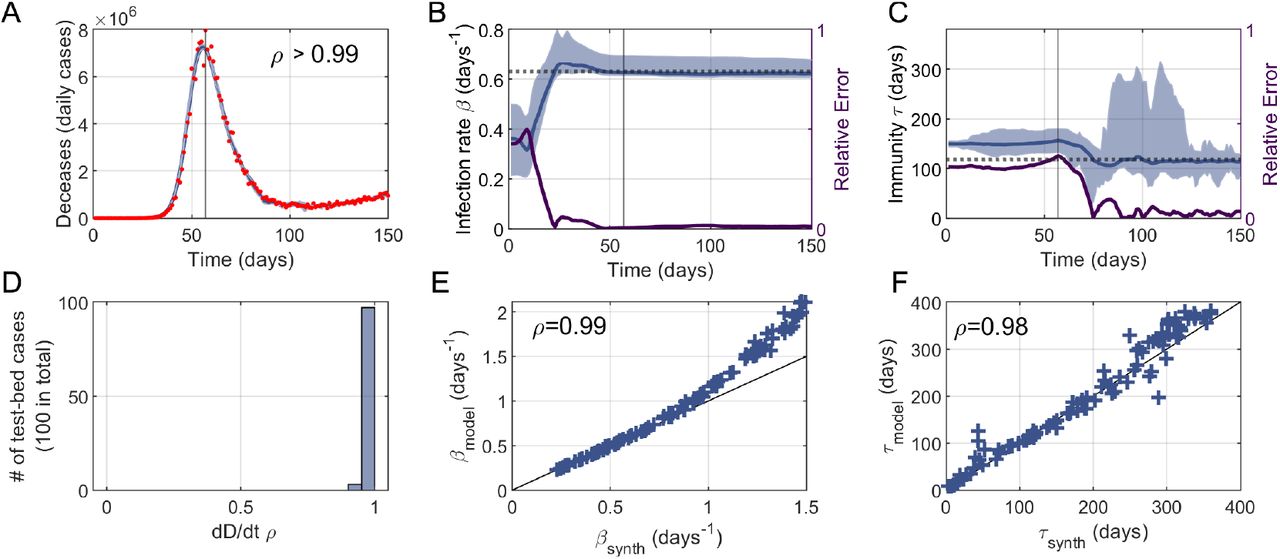
We tested the performance of the EAKF-based protocol over a test bed of synthetic data made of 100 time-series generated with the model and random values of β and τ. Panels A-C illustrate the analysis of a single example whereas panels D-F show the overall performance on the entire test bed. (A) Our protocol (blue) is able to accurately capture data of daily deceases (red), with a linear correlation between data and model ρ > 0.99. (B) The value of the synthetic infection rate βsynth (dotted line) is captured by the protocol βmodel (blue) after some data assimilation steps, and prior to the pandemic peak. Accordingly, the relative error between βsynth and βmodel decreases as more data is assimilated (purple solid, right y-axis). (C) The immune memory τmodel (blue) follows similar dynamics as βmodel and approaches the synthetic value τsynth (dotted line). However, its relative error (purple solid, right y-axis) drops later than βmodel, at about the epidemic’s peak, in agreement with the results of our previous section. In panels A-C, shadings represent 95%CI, while vertical lines denote time of peak. (D) Histogram of linear correlations between model and data of daily deceases (as in panel A) for the entire test bed. (E-F) Synthetic values and EAKF estimates of the infection rate and immune memory largely correlate, ρ = 0.99 and ρ = 0.98, respectively. We find however that our protocol tends to overestimate larger infection rates when βsynth > 1.
To further evaluate the limits of this approach, we generated a test bed of 100 synthetic data series for a range of parameters (note that for each series we ran again 100 iterations). Specifically, each series correspond to random values of βsynth 2 [0.2, 1.5] days-1 and τsynth 2 [0, 360] days to which we added relative random noise normally distributed with zero mean and standard deviation up to 10%. The initial exposed population is also selected randomly from a uniform distribution Esynth (t = 0) 2 [0, 10]. The goal is to apply EAKF within this range to estimate once again the dD/dt series and the “hidden” parameters.
Figure 3D-E shows the performance of our protocol when applied to the entire test bed of synthetic data. On the one hand, we find that infection rates β < 1 are excellently captured whereas β > 1 are slightly overestimated (Fig. 3E). On the other hand, τ is more difficult to estimate in its entire range (smaller correlation between model and synthetic values), but the estimates are not biased towards upper/lower values (Fig. 3F). Moreover we found that the errors between estimates of τ and β barely correlate (ρ = −0.18, not shown), so a better estimation of β does not necessarily lead to a worse estimation of τ. Also, neither errors in the estimates of τ nor β correlate with the magnitude of the noise added to dD/dt (ρ = 0.04 and ρ = −0.12, respectively; not shown).
In sum, filtering and data assimilation techniques successfully identify the values of the infection rate, β, and immunity memory, τ, when enough data points are available. The value estimates are robustly captured for different initial conditions. Finally, we also found that our protocol can handle up to 10% relative errors with little to no impact on the estimation of β and τ.
Quick and strong social distancing measures conceal the mid-term effect of immunity
We now apply the protocol used in the previous section to real time series of new daily deceases reported for COVID-19 in different heavily-affected regions. We performed a preliminary test to rank these regions (world-wide countries and counties/cities within the US) to narrow down potential candidates for signal detection. From over 30 regions, we selected NYC because it had the largest number of deceases per 105 inhabitants and it did not exhibit volatile field data like other regions, e.g. Nassau (NY, USA) or Belgium, (Fig. S3 and S4 in Supplementary Material).
To be certain that the signal in τ is not an artifact, we added to the protocol a control variable 8 that has no effect on the model, is initialized as a different sample of the same initial distribution as τ and follows the same update rules as τ. Thus, statistically significant deviations between the distributions of τ and 8 highlight the influence of τ in the results.
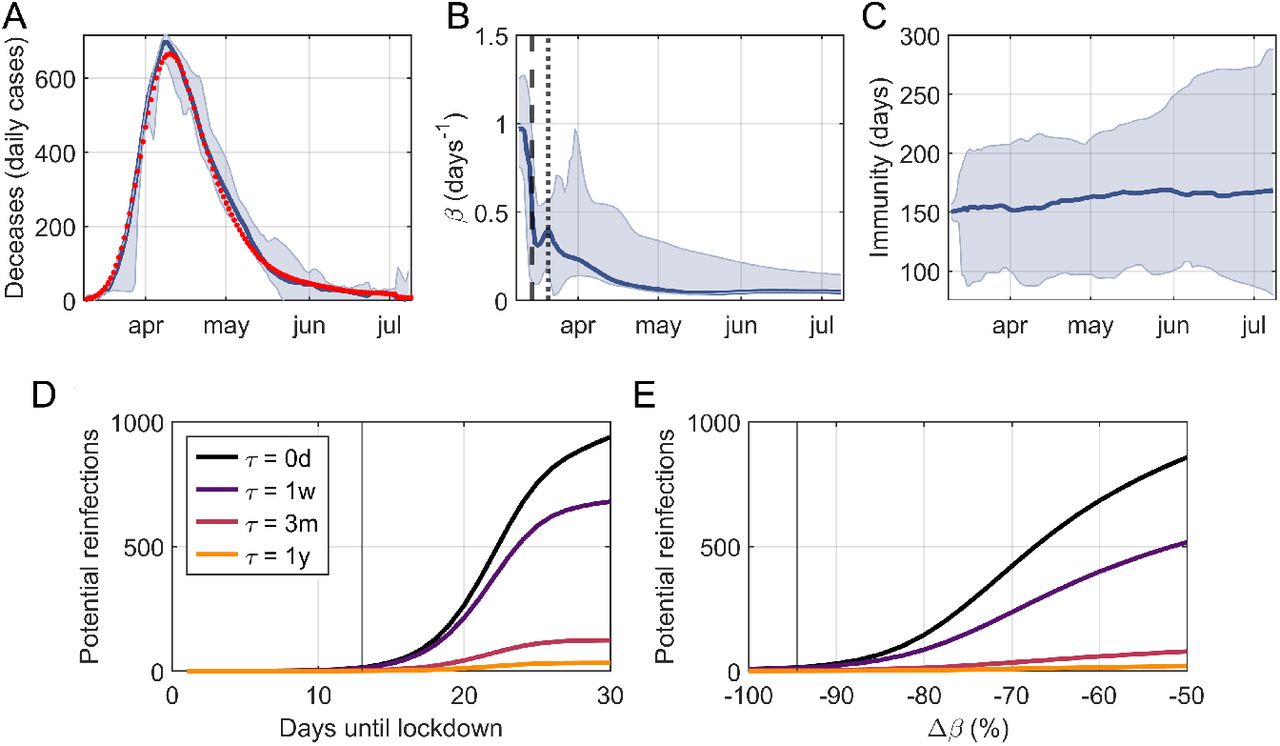
In Figure 4A-C we show the results of NYC. The success of the EAKF protocol to capture the dynamics of dD/dt is apparent with a root mean squared error RMSE= 18 deceases and a linear correlation between data and the model median ρ > 0.99 (Fig. 4A). In particular, our protocol also captures the time-dynamics of the infection rate, which is well aligned with the days on which NYC promoted social distancing measures: schools and library closings on March 16th, and the pause order of March 22nd (Fig. 4).

(A) Data (red dots) and algorithm estimate (blue solid, median and 95% CI) of New York City’s daily deceases of COVID-19. Data and prediction are in good agreement, with a root mean squared error RMSE=18 deceases and with a linear correlation coefficient ρ => 0.99. Estimate of the infection rate, β, dynamics (median and 95% CI). Drops in β are well aligned with the days on which social distancing measures took place: school closings (black dashed) and the pause order (black dotted). (C) Estimate of the immune memory duration τ (median and 95% CI). The distribution of τ becomes significantly different from that of a control variable 8 (two-sample Kolmogorov-Smirnov test p= 0.017) and sets the lower and upper to τ 2 [80, 288] days with (95% CI). We also simulated a hypothetical scenario based on NYC data with (D) lockdowns established on different days since the first decease, and with (E) different decreases in β due to the lockdown. As a proxy for the difficulty of detecting τ, we use the number of potential reinfections, i.e. the number of recovered people that has lost its immunity by the 50th day since the start of the epidemic, for different values of τ. Observe that specific data for NYC (black vertical lines in panels D and E) illustrates how their quick action in closing schools and passing a pause order (on March 22nd 2020) and their large effectiveness (with β decreasing > −90%) ensure a small amount of possible reinfections, and hence the difficulty to capture τ with fitting methods.
Most importantly, we found a final estimate of 105 < τ < 211 days with 90% confidence (80 < τ < 288 days with 95% CI). We obtained this estimate from a statistically significant change in the distribution of τ with respect to the control variable 8 (two-sample Kolmogorov Smirnov, p= 0.017). The upper bound should be considered with caution, given the limited availability of COVID-19 data due to its recent appearance, and future data assimilation steps could alter this bound.
We attribute the difficulty to capture the value of τ in real data as opposed to synthetic data to the ubiquity of a strong reduction of the infection rate during the initial days of the epidemic in all data sets that we studied (results of Belgium, Spain and France are available in Fig. S5). We tested this idea by computing the number of recovered cases that have lost their immunity against the virus after 50 days of the start of the epidemic. This number, which we call potential reinfections, is a proxy for the difficulty of capturing τ. We consider a scenario similar to NYC, with equal population and equal initial and final infection rates β, but with different timing and effectiveness of lockdowns (Fig.4DE). The effectiveness is measured by the relative change between the infection rate pre- and post-lockdown. Simulation data supports our hypothesis since the number of potential reinfections is both close to zero and independent of τ when lock-downs are quickly established and/or when they are very effective with infection rate drops > 90%.
Although we confirmed the potential of EAKF algorithms to distinguish the duration of immune memory during an ongoing epidemic, we also noted that the application of our methods is bounded by the expected control measures that are aimed to reduce epidemic progression, i.e., to decrease the infection rate.
Potential consequences of immunity on post-pandemic COVID-19 dynamics
How could the immune memory for COVID-19 affect a secondary wave of infection? We tackle this by integrating the final state of the EAKF ensembles of NYC with our COVID-19 model deterministically. To account for the relaxation of social distancing measures we include a linear increase of the infection rate during the month of July, specifically, β doubles by the 1st of August and remains constant from then on, which is a conservative scenario. In terms of the effective number of secondary infections Re, a doubling of β is equivalent to an Re increase from ∼ 0.7 to ∼ 1.3 (Supplementary Material).
Figure 5 shows the model forecast of daily deceases due to COVID-19 considering the lower and upper bounds of the 95% CI, τ = 80 and τ = 288 days, respectively. First, in this scenario where social distancing is only slightly relaxed and where the infection rate remains constant from then on, a new epidemic wave in terms of deceases would shortly take place. Its precise timing will depend strongly on the number of ICU beds available, but it can be expected to start in mid September. Moreover, without further social distancing measures during this second epidemic wave, we anticipate that it could last up until January and beyond.

We show the forecast of a second epidemic wave starting in early September if the infection rate β doubles its value during July, for two cases of immune memory τ = 80 and τ = 288 days (purple and orange respectively, shadings denote 95% CI). Observe that τ slightly affects the timing of the second wave: the shorter τ has a narrower CI. The second wave becomes quickly a real problem due to the little immunity developed during the first (black).
This is due to the fact that, during the first wave, most of the population did not develop immunity to the virus and hence is yet susceptible through the second wave. Such a secondary peak has already been suggested in other specific scenarios [23, 26].
However, if we focus on the maximum effect that different τs have in the short run, we find that, although the median trajectory is independent of τ, the confidence region is narrower for τ = 80 days. In fact, we expect the immune memory to be relevant only after a considerable fraction of the population has undergone a first infection by COVID-19, or in the case that the time between epidemic waves (or intermittent social distancing) is shorter than that of τ where there is enough time to build a sufficiently large pool of immune population.
Discussion
We propose an alternative approach for estimating the duration of immunity. The protocol relies on the computational analysis of epidemiological time series, which requires far fewer resources and may be deployed faster than its alternatives. Although longitudinal serological studies may be preferred, the evidence for immunity they provide is as indirect as the one we may detect in epidemiological data series. In fact, a direct experimental test of human immunity to SARS-CoV-2 would require intentionally infecting and monitoring recovered human patients with the virus, which would be highly controversial, although this approach has been tested in monkeys [27].
To circumvent this, serological studies obtain indirect evidence based on the premise that antibody prevalence equates immunity, which is generally accurate. However, this is not the case for all diseases. Different mechanisms of persistence deployed by pathogens can uncouple antibody memory from actually being protected against the disease and/or being asymptomatic. Moreover, the effect of immunity on mortality series can hardly be mimicked by any other factors and draws information from field data. Thus, its standard of evidence for immunity is not necessarily lower than the one traditionally employed.
Despite all these points in its favor, the reach of the protocol in its current form is limited, and some requirements must be satisfied to discern immunity. Data series must have surpassed the peak following social distancing measures, which will increase the time necessary to begin a proper examination. In this regard, capturing τ was highly dependent on lockdown policies, as evidenced by our potential reinfections metric. The maximum portion of infected people in the population must be sufficiently large for there to be a signal. However, most regions will implement comparable measures to reduce the number of deceased and its growth that make the signal barely distinguishable. In some cases, different stages of social alarm stratified with political or legal restrictions of varying strength are what makes for very volatile infection rates or completely renders changes in immunity irrelevant to early population mortality.
However, segregating exposure and likeliness of infection should improve signal detection as all individuals are not equally likely to be infected. On the one hand, long-lasting cross-immunity with other coronaviruses can significantly reduce the susceptible population [28, 29], and on the other hand, re-infections are most likely occurring in only a subset of the population (such as the working as opposed to the non-working population, age-based classifications, or metropolitan vs suburban or rural). A second way of improving immunity would be to use another observable on top of the deceased during data assimilation. In fact, predictions would improve considerably should data of the infected population be reliable and independent of the limited availability of PCR tests. In addition, the improper mapping of field-measured variables (the “confirmed”, sampling-biased metric) to model variables (exposed, asymptomatic, mild, severe and critical populations) prevents predictability.
But leaving aside reliability in the field tracking of epidemiological variables, it is also worth noting that the protocol is unworkable without a moderately predictive model. Concomitantly, having an accurate model requires some knowledge of the disease’s progression, symptomatology, and outcomes, as well as any notable resources or clinical agents involved in them (as in this case were ICU beds or oxygen). Still, none of these requirements is particularly unlikely to be reached during emergent pandemics. For instance, all of them had been satisfied after 3 months of COVID-19. And the information needed to produce a reasonable model was already public after the second month.
Lastly, perhaps the most significant obstacle in this and more conventional approaches is their inability to discriminate heterogeneity in immunity [30] from groups of recovered patients that have experienced varying degrees of symptomatology. Indeed, patients with many kinds of symptoms and/or peak viral loads may vary in their development of immunity. It could be, for instance, that mild cases do not result in enduring immunity, or result in a shorter immune span, than severe or critical cases. If that were the case, our approach would similarly identify a single overall value for immunity from the statistical overlap of different genuine immunity times, offering a weighed, non-real centrality measure of all immune times in the population.
All these things considered, the present protocol can be thought of as an additional first-hand tool that can always provide necessary evidence in the early stages of a pandemic, until more and varied methods can be deployed.
Now, several issues have arisen surrounding persistence and immunity in COVID-19 throughout the last months. For the majority of the time, the best estimate for immunity to SARS-CoV-2 the community could work with was a presumed range stemming from phylogenetic comparisons pertaining seasonal human coronaviruses like HCoV-OC43 and HCoV-HKU1 [23]. Nevertheless, the standard of evidence of phylogenetic assumptions is not very reliable, particularly with regards to microorganism. According to these suppositions, COVID-19 may elicit immunity lasting from 6 months to 2 years.
Because these were potentially inaccurate measures, early cases of apparent reinfection sparked controversies, and even now as some countries are re-experiencing out-breaks recurring positives are a concern. Our work adds on to other very recent publications that appear to indicate immunity will last at least several months [10], and provides COVID-19-specific evidence that recovered patients will maintain at the very least 3.5 months of immunity, most likely around 5, and possibly no more than 7; so long as there are no significant differences in immunity due to case severity.
While we recognize the complexity of the human immune response to SARS-CoV-2, as it is to many other viruses, we trust that our work contributes to a more solid comprehension of the epidemiological implications of this response.
Materials and Methods
Data acquisition
We obtained death counts of COVID-19 aggregated by country and USA county from the COVID-19 Data Repository by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University [31] (last updated on July 9th), and information of ICU beds from a variety of sources depending on the region of study (for the case of NYC see the city’s coronavirus tracker). We used Worl-dometer to obtain the populations of the regions and countries we selected for analysis [32]. We also used data from the Oxford COVID-19 Government Response Tracker to find the days that different social distancing measures took place in some countries [33].
Epidemiological model
We introduced a compartmental model that exploits what is currently known about COVID-19 progression and associated accessible data such as the fraction and times at which different infected cases recover or worsen (Supplementary Material, Table S1). Namely the compartments are: susceptible (S), exposed to the virus but not yet contagious (E), infected and contagious but asymptomatic (IA), with mild symptoms (IM), with severe symptoms (needs hospitalization - IS), and critical symptoms (requires urgent admittance to an ICU - IC); recovered cases (R) and the deceased (D).
The basic reproductive number, R0, and its temporal-dependent counterpart Re (effective reproductive number) are composite parameters that integrate information on not only the infection rate but also the contact rate, susceptible population, and most importantly model architecture [34, 35]. For this reason, we have prioritized the use of the infection rate β throughout. However, we have used Re sparingly due to its biological relevance, which lies in whether it is larger/smaller than the unit, indicating whether the outbreak is expected to continue. To compute Re we have applied the Next Generation Matrices (NGM) algorithm to our model [36], hence Re is the largest eigenvalue of the NGM KL=-T S-1 where T and S are respectively the transmissions and transitions matrices (Supplementary Material for more details). A sensitivity analysis of R0 with respect to the model parameters is available in Fig. S6.
Data assimilation
The EAKF filtering method consists in propagating and updating ensemble members, which constitute a probabilistic description of the state variables and model parameters [13]. Ensembles are samples of the distributions that the variables are expected to have. In our case, the time-dependent state variables are the infection rate β, the immunity memory τ and the population in each compartment of the model. We also introduced a dummy variable 8 that does not affect the model results against which to test the ensemble dynamics of τ. The time-dependent observable is the number of daily deceases officially reported, to which we applied a 2 week running average to account for miscommunications and reporting delays.
In the data assimilation step, the ensemble members are integrated with the model to obtain their expected state at the time of the succeeding observation. Next, together with the likelihood distribution of the actual observation, the algorithm calculates the posterior probability assuming that all distributions are normal. Lastly, the unobserved state variables are updated according to their correlation with the observable. For the assimilation of the next data-point, the posterior probability then becomes prior. A more detailed description of the protocol is available in the Supplementary Material.
Importantly, considering that τ did not correlate linearly with the observable, we used rank correlations instead to update both τ and 8. We also used a 3% inflation in the ensemble variance of all variables except τ and 8 since they showed no convergence problems. We have run 100 EAKF instances with ensemble sizes of 200 members. The days in which confinement measures took place (school closing, lockdown…) we added a 200% inflation to better accommodate parameter discontinuities.
Data Availability
Data availability is discussed in Data acquisition section
Footnotes
Funding information This work was supported by PhD fellowship BES-2016-079127 (P.Y.) and grant FIS2016-78781-R (J.F.P.) from the Spanish Ministerio de Economía y Competitividad and the European Social Fund.
This version edited some parts of the manuscript and added an additional sensitivity analysis.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}