
Abstract
Medical texts such as radiology reports or electronic health records are a powerful source of data for researchers. Anonymization methods must be developed to de-identify documents containing personal information from both patients and medical staff. Although currently there are several anonymization strategies for the English language, they are also language-dependent. Here, we introduce a named entity recognition strategy for Spanish medical texts, translatable to other languages. We tested 4 neural networks on our radiology reports dataset, achieving a recall of 97.18% of the identifying entities. Along-side, we developed a randomization algorithm to substitute the detected entities with new ones from the same category, making it virtually impossible to differentiate real data from synthetic data. The three best architectures were tested with the MEDDOCAN challenge dataset of electronic health records as an external test, achieving a recall of 69.18%. The strategy proposed, combining named entity recognition tasks with randomization of entities, is suitable for Spanish radiology reports. It does not require a big training corpus, thus it can be easily extended to other languages and medical texts, such as electronic health records.
- Natural Language Processing
- Named Entity Recognition
- radiology reports
- medical texts
- Spanish
Background
Medical imaging is widely used in clinical practice for the diagnosis and treatment of several diseases, such as alzheimer, cancer or pneumothorax. Data from radiology reports, electronic health records and other medical texts such as clinical trial protocols are being used for research purposes (1, 2). Health care institutions, researchers and patients can greatly benefit from these datasets. However, these records and reports contain patient notes known as personal data that can challenge patient confidentiality and privacy, as provided for in the European Regulation on the protection of personal data (3). All words that could identify a patient must be removed or de-identified before data analysts start their research or even more before the dataset is published.
From a legal point of view, Regulation (EU) 2016/67 on the protection of natural persons and with regard to the processing of personal data and on the free movement of such data (3) provides the regulatory framework in the European Union. Although its application is mandatory to all its member states, its concrete implementation varies depending on each of them. In Spain, the Organic Law 3/2018 (4) establishes the legal framework for data protection in biomedical research. Reuse of personal data for medical research needs to be approved by an ethics committee, and data must be at least pseudonymized before the researchers get access to it. Legal issues regarding data privacy are not the only source of concern. Direct consequences to patients are also a very important factor to be carefully considered. It is crucial to protect the private health details of a patient from any third party’s access, and avoid exposing identifiable personal data such as identifier numbers or addresses. De-identification is therefore essential to ensure patient privacy and comply with legal requirements.
From a data management point of view, the de-identification methodology needs to be precise and recallable. Precision is needed to minimize the data loss of the de-identification process and to preserve the semantic meaning of the radiology report; recall allows getting the best de-identification possible and avoiding losing any identifiable information (5).
Even though several de-identification or anonymization methodologies have been proposed in English, legislation differs on a national level worldwide and language-specific problems can arise, hence a different method for each language must be developed. These difficulties extend to any Natural Language Processing (NLP) implementation. In the biomedical field, NLP has been applied successfully in English, including for de-identification purposes (6), but many of these strategies rely on language-specific resources and are not extensible to other languages (7). Apart from the English language, this problem has been assessed in French, where different strategies from machine learning to the use of dictionaries and lists have been proposed, along with protocols for corpus development (8, 9). In other languages such as German, Swedish, Dutch or Chinese some strategies and methodologies have also been proposed (5, 10–13), but there have been so far rather limited attempts in automatic de-identification for Spanish medical texts (14, 15), including the MEDDOCAN task (16).
Most of the works around text de-identification are based on pattern matching or machine learning, or even a combination of both. Whereas pattern matching does not account for the context of a word and is unaware of typographical errors, machine learning techniques require a large corpus of annotated text (17). Since our radiology reports were mostly free text with sensible data outside headers, we opted for annotating our own corpus and developing a Named Entity Recognition (NER) based de-identification method.
Methods
Named Entities
Given that there is no specific guidance in the Spanish legal system on what information has to be removed to deidentify medical texts, we decided to search in our reports for the Protected Health Information (PHI) categories defined by the Health Insurance Portability and Accountability Act (HIPAA) in the United States of America (18). After manual inspection of the data and considering the scope of this work, we performed a sub-selection of PHI categories and finally grouped them in 6 Named Entities (NEs) as shown in Table 1. Some NEs included other information that should be protected to preserve the privacy of patients or doctors but was not included in PHI categories, such as digital signatures or healthcare centres.
Named Entities selected for this task and their associated Protected Health Information categories
Header sections were included as a NE to ensure that they were not removed from the final text. These headers are nec-essary for further analysis, being key to extract the most relevant information of a radiology report.
Corpus construction
The de-identification corpus consists of brain imaging radiology reports randomly extracted from the Medical Imaging Databank of the Valencian Region (BIMCV) database (19, 20), distributed among 17 health departments of the Valencian Region (Figure 1). A total of 7848 records were initially retrieved and automatically pre-annotated using the Spanish National Statistics Institute name and surname database (21), including those names with a frequency higher or equal to 20 in Spain, and a list of the hospital names in the Valencian Region. To ensure the presence of personal information in our corpus, a subset of reports with at least two ‘NAME’ tags was extracted. One-third of those reports were randomly selected to be manually corrected and annotated, with a final corpus of 692 records. The annotations were manually reviewed by three annotators, including finally all the NE tags.

Data curation process and corpus preparation workflow. (A) 7848 radiology reports in total were retrieved from BIMCV database. (B) We used a custom Python script to automatically annotate the names, surnames and hospital names from radiology reports. (C) A subset of records was made meeting the condition that more than one ‘name’ tag was present, remaining 2214 reports. (D) Another subsetting was performed to randomly select one-third of reports to be manually annotated and corrected by three annotators. After the manual revision, 692 reports remain.(E) Ground Truth dataset was divided into 3 subsets: the training set included 447 reports, test A 213, and test B 32 reports from healthcare department number 7.
Radiology reports were not preprocessed so that they remain unchanged after the de-identification, apart from the identifying information. Although our radiology reports were mostly free-text sections preceded by headers, the 7th health department lacked headers and had an increased number of entities entirely out of context: this is, a name or a surname with no more text in an independent line, as shown in Figure 2. With this in mind, we divided our dataset into three sets, one for training and two for testing:

Partial examples of radiological records from Test A (A) and B (B). Test A has metadata headers clearly defined. In turn, test B has metadata headers in Valencian language and metadata information detached from these headers by a line break. Both structures include identifiable information in new lines without metadata headers.
Training set, including 447 randomly selected records from all the departments.
Test A set, including 213 randomly selected records from all the departments except 7th department.
Test B set, including 32 randomly selected records from the 7th department.
Whereas both training and test A set present similar distribution of NEs (Table 2), test B shows an increase of addresses, locations and institutions. Having a separate test for department 7 allows us to check the performance of our method with highly unstructured data, with a distribution of NEs different from the training. As shown in Table 2, addresses and locations are the NEs with the lowest sample size.
Number and percentage of annotations per corpus subset: Training, Test A and Test B.
To assess the performance of our final model with external data, we decided to incorporate 100 randomly selected clinical records from the MEDDOCAN task (16). These records have a different structure and are not related to radiology.
NE randomization
We developed a methodology to randomize the PHIs found in a text, and applied it to the manually labelled dataset, obtaining a synthetic corpus. This methodology applies a set of rules depending on the NE associated with each tagged word. It is based on the substitution of tagged entities with new words randomly extracted from different databases available online:
Spanish National Statistics Institute name and surname database (21), weighted by frequency
Spanish National Statistics Institute municipal register database (22), weighted by population in 2019
National Hospital Index (23)
National Outpatients Clinic Index (24)
Municipality addresses (25)
With the aim of avoiding the leakage of sensitive personal data, this methodology also checks that the randomly chosen word or number is not the same as the original one.
Networks
A variety of neural networks were tested and evaluated, all of them designed for NER tasks. Three network architectures were based on Bidirectional Long Short-Term Memory (BiLSTM) layers, obtained from Guillaume Genthial’s GitHub repository (26):
LSTM-CRF: GloVe vectors, BiLSTM and Conditional Random Fields (CRF) based on the work of Huang et al (27).
LSTM-LSTM-CRF: GloVe vectors, character embeddings, BiLSTM for character embeddings, BiLSTM and CRF, based on the work of Lample et al (28).
Conv-LSTM-CRF: GloVe vectors, character embeddings with 1D convolution and max pooling, BiLSTM and CRF, based on the work of Ma and Hovy (29).
These networks were trained with and without Exponential Moving Average (EMA) of the weights. We also trained a spaCy (30) NER model, based partly on the work of Lample et al (28) with dense embeddings along with Convolutional Neural Networks (CNNs) with an attention mechanism.
Evaluation metrics
To assess the performance of the different models trained we computed precision, recall and F1-score metrics. These metrics can be defined as:
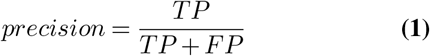
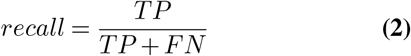
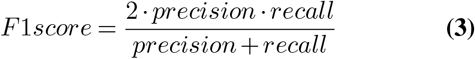 being TP the number of true positives, FP the number of false positives, and FN the number of false negatives.
being TP the number of true positives, FP the number of false positives, and FN the number of false negatives.
To compute the amount of de-identification achieved by the model, we did not only applied these metrics to each NE, but to the set of words that should have been labelled as an identifying NE. With this approach, we obtained quantitative indicators of global de-identification.
Results
First, models for each neural network were trained and then evaluated. Table 3 shows the mean global results of the different networks, given three replicates for each one.
Evaluation metrics for the best model obtained with each of the different neural networks tested. Bold font highlights the best metric in each data subset.
The recall is one of the most relevant evaluation metrics in any de-identification process (5), to avoid the leakage of sensitive information. Taking this into account, LSTM-LSTM-CRF with EMA shows the highest recall in test B, and Conv-LSTM-CRF with EMA in test A. Although these are the two best-performing networks in both test sets, we decided to include also spaCy for further analysis and leave outside the worst-performing architecture: LSTM-CRF.
The performance stats of each NE for LSTM-LSTM-CRF with EMA, Conv-LSTM-CRF with EMA and spaCy are displayed in tables 4, 5 and 6. Whereas in training set spaCy outperforms the other networks in every NE, in test A and test B results are more contested. Evaluating F1-score in test A, LSTM-LSTM-CRF classifies better dates, locations, names and numbers, while spaCy stands out with institutions. On the other hand, Conv-LSTM-CRF performs better with addresses and shows higher recall in names than LSTM-LSTM-CRF. In test B, the spaCy model shows better results in dates and better recall in institutions whereas LSTM-LSTM-CRF has a higher F1-score in institutions, locations and names. Conv-LSTM-CRF again performs better with addresses, but also with numbers and shows the highest recall in locations and names. When applying the models to MEDDOCAN dataset there’s a decay of the performance, although spaCy has higher recall rates in addresses, dates, institutions and name, whilst Conv-LSTM-CRF outperforms in locations and numbers.
Evaluation metrics obtained with LSTM-LSTM-CRF with EMA model for each named entity.
Evaluation metrics obtained with Conv-LSTM-CRF with EMA model for each named entity.
Evaluation metrics obtained with spaCy model for each named entity.
Given that our aim was not to correctly classify NE, but to completely remove sensitive information from the text, global de-identification metrics were computed (Table 7). Conv-LSTM-CRF with EMA shows better recall in test A and test B sets (Figure 3), whilst LSTM-LSTM-CRF has higher F1-score on test B. On MEDDOCAN data the model that better maintains recall and F1-score is LSTM-LSTM-CRF (Figure 3, Table 7). To assess the performance of our models with external data, we wanted to apply the models generated at MEDDOCAN to our data. Only one of the participants made their models available (31), being one of the implemented networks spaCy. Their spaCy model achieved a precision of 87.89% and 80.31%, a recall of 42.66% and 26.54%, and an F1-score of 57.44% and 39.89% in our test A and our test B, respectively (Table 7).
Global de-identification metrics for LSTM-LSTM-CRF, Conv-LSTM-CRF, spaCy and the model retrieved from MEDDOCAN. (*) : Results extracted from the original publication (31).

Precision (A), recall (B) and F1-score (C) for the three best performing architectures, LSTM-LSTM-CRF with EMA (blue), Conv-LSTM-CRF with EMA (yellow) and spaCy (grey) by data subset.
Discussion
This work has defined and evaluated a methodology based on NER to de-identify radiology reports in Spanish language. In comparison with traditional approaches based on regular expressions, NLP and neural networks do not underperform due to human misspellings or the absence of a clear and repeated structure. Neural networks are also context-dependent, and words like Parkinson will be detected as a ‘NAME’ entity when used as a surname but left unchanged when used as a medical word, avoiding the loss of meaningful information. The main drawback of this methodology is the requirement of a learning corpus of de-identified reports, which is not necessary for regular expression-based strategies. Although the curation of a corpus is a tedious and methodical task, there is no need for a big dataset: with a training set of 447 texts, we achieved a suitable performance.
Neural networks should be trained with a corpus diverse in structure to avoid overfitting. Machine learning models tend to learn the structure or format of the text, finding the position of words containing sensible data when performing deidentification. If a model was trained with a corpus with a determined structure, it will only be able to de-identify similarly-formatted texts. By comparing our spaCy model with the spaCy model retrieved from MEDDOCAN (31), we show the high impact that text structure has in the outcome. The MEDDOCAN training set was similar in size to ours (500 and 447 texts with a median of 20 and 22 lines per text, respectively), but their text structure was highly defined and invariant. With a training set diverse in its structure we can obtain higher recall and precision in external data, generating a de-identification model better prepared to deal with new data. Figure 2 illustrates the structure and format diversity of radiological reports between health departments included in our dataset.
Considering that the recall metric assesses the capability to avoid the leakage of sensitive information of a model, we propose LSTM-LSTM-CRF with EMA as the best neural network to address a de-identification task based on NER. This neural network showed higher statistics in all three pro-posed test sets, and its recall in test A and test B are comparable to those obtained with Conv-LSTM-CRF with EMA. Thus, we expect LSTM-LSTM-CRF with EMA to behave optimally when presenting new data to it. Although its recall is very good, it is not perfect. When new radiology reports from the Valencian Region are included in BIMCV database, 97.18% of recall in test B means that almost 3% of identifying words will remain in the text. It might not be enough to re-identify the patient: could be left only a surname, a city name, or a part of an address. To ensure that the identity of a patient is not restorable, a final check of the texts by an authorized person remains necessary. Nevertheless, we propose a randomization strategy to change the identified NEs for synthetic ones of the same category. This strategy masks the identifying words left by the neural network with synthetic information, making it more difficult to discern between real and synthetic identifying words than by simply erasing words (Figure 4). Further efforts need to be done to validate whether this strategy makes original information unretrievable or not.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Anonymization strategies. When applying word elimination (A) errors are easily detectable whereas with synthetic substitution (B) any mistake is hidden with randomized synthetic information.
Conclusions
Medical texts hold great potential for research, but legal and privacy concerns arise with its use, even more, when institutions external to the hospital are involved. Realworld medical texts tend to be semi-structured with free text that includes sensible information, thus classical deidentification approaches based on regular expressions are not good enough. We propose a robust and flexible methodology based on NER for Spanish medical texts, tested on radiology reports from the Valencian Region. This method is generic and relatively simple and can be easily generalizable to other Spanish medical texts by re-training the network with additional data. We believe it can be also replicated in other languages, at least Romance derived languages, being the easiest network to implement spaCy, although it is not the best performing. The proposed de-identification methodology still missed identifiers after training, thus a final check of the texts by an authorized person remains necessary. Nevertheless, we believe a combination of NER with the generation of synthetic data will make it virtually impossible to extract real identifying words from the text. Further efforts need to be done to assess and test this hypothesis.
Data Availability
The data that support the findings of this study are available from BIMCV but restrictions apply to the availability of these data under a research use agreement. Data access can be requested at http://bimcv.cipf.es/. Supplementary information and code are available online at https://github.com/BIMCV-CSUSP/DiSMed.
ETHICS APPROVAL
The study was approved by the local institutional ethics committee DGSP-CSISP NÚM. 20190503/12.
AVAILABILITY OF DATA AND MATERIALS
The data that support the findings of this study are available from BIMCV but restrictions apply to the availability of these data under a research use agreement. Data access can be requested at http://bimcv.cipf.es/.
Supplementary information and code are available online in GitHub.
Project name: DiSMed - De-identifying Spanish medical texts
Project home page: https://github.com/BIMCV-CSUSP/DiSMed
Operating system(s): Platform independent
Programming language: Python
Other requirements: Python (version≥ 3.5). DiSMed imports the following Python non-built-in libraries: pandas, numpy, codecs, spacy, tensorflow (version < 2)
License: MIT
ACKNOWLEDGEMENTS
This article describes work undertaken in the context of the DeepHealth project, “Deep-Learning and HPC to Boost Biomedical Applications for Health” (https://deephealth-project.eu/) which has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 825111”. The contents of this publication reflect only the author’s view, can in no way be taken to reflect the views of the European Union and the Community is not liable for any use that may be made of the information contained therein.




