
Abstract
The ongoing coronavirus pandemic reached Mexico in late February 2020. Since then Mexico has observed a sustained elevation in the number of COVID-19 deaths. Mexico’s delayed response to the COVID-19 pandemic until late March 2020 hastened the spread of the virus in the following months. However, the government followed a phased reopening of the country in June 2020 despite sustained virus transmission. In order to analyze the dynamics of the COVID-19 pandemic in Mexico, we systematically generate and compare the 30-day ahead forecasts of national mortality trends using various growth models in near real-time and compare forecasting performance with those derived using the COVID-19 model developed by the Institute for Health Metrics and Evaluation. We also estimate and compare reproduction numbers for SARS-CoV-2 based on methods that rely on both the genomic data as well as case incidence data to gauge the transmission potential of the virus. Moreover, we perform a spatial analysis of the COVID-19 epidemic in Mexico by analyzing the shapes of COVID-19 growth rate curves at the state level, using techniques from functional data analysis. The early estimate of reproduction number indicates sustained disease transmission in the country with R∼1.3. However, the estimate of R as of September 27, 2020 is ∼0.91 indicating a slowing down of the epidemic. The spatial analysis divides the Mexican states into four groups or clusters based on the growth rate curves, each with its distinct epidemic trajectory. Moreover, the sequential forecasts from the GLM and Richards model also indicate a sustained downward trend in the number of deaths for Mexico and Mexico City compared to the sub-epidemic and IHME model that outperformed the others and predict a more stable trajectory of COVID-19 deaths for the last three forecast periods.
Author summary Mexico has been confronting the COVID-19 epidemic since late February under a fragile health care system and economic recession. The country delayed the implementation of social distancing interventions resulting in continued virus transmission in the country and reopened its economy in June 2020. In order to investigate the unfolding of the COVID-19 epidemic in Mexico and Mexico City the authors utilize the mortality data to generate and compare thirteen sequentially generated short-term forecasts using phenomenological growth models. Moreover, the reproduction number is estimated from genomic and time series data to determine the transmission potential of the epidemic, and spatial analysis using case incidence data is conducted to identify the characteristic growth patterns of the epidemic in different Mexican states including rapid increase in the growth rate followed by a rapid decline and slow growth rate followed by a rapid rise and a rapid decline. The best performing models indicate a more sustained transmission of the pandemic in Mexico. The forecasts generated from the GLM and Richards growth model indicate towards a sustained decline in the number of deaths whereas the sub-epidemic model and IHME model point towards a stable epidemic trajectory for forecasting periods as of August 23, 2020.
Introduction
The ongoing COVID-19 (coronavirus disease 2019) pandemic is a global challenge that calls for scientists, health professionals and policy makers to collaboratively address the challenges posed by this deadly infectious disease. The causative SARS-CoV-2 (severe acute respiratory syndrome virus 2) is highly transmissible via respiratory droplets and aerosols and presents a clinical spectrum that ranges from asymptomatic individuals to conditions that require the use of mechanical ventilation to multiorgan failure and septic shock leading to death [1]. The ongoing pandemic has not only exerted significant morbidity but also excruciating mortality burden with more than 79.2 million cases and 1.7 million deaths reported worldwide as of December 29, 2020 [2]. Approximately 27 countries globally including 9 countries in the Americas have reported more than 10,000 deaths attributable to SARS-CoV-2 as of December 29, 2020 despite the implementation of social distancing policies to limit the death toll. In comparison, a total of 774 deaths were reported during the 2003 SARS multi-country epidemic and 858 deaths were reported during the 2012 MERS epidemic in Saudi Arabia [3-5].
While effective vaccines against the novel coronavirus have begun to roll out, many scientific uncertainties exist that will dictate how vaccination campaigns will affect the course of the pandemic. For instance, it is still unclear if the vaccine will prevent the transmission of SARS-CoV-2 or just protect against more severe disease outcomes and death [6, 7]. In these circumstances epidemiological and mathematical models can help quantify the effects of non-pharmaceutical interventions including facemask wearing and physical distancing to contain the COVID-19 pandemic [8]. However, recent studies have indicated that population density, poverty, over-crowding and inappropriate work place conditions hinder the social distancing interventions, propagating the unmitigated spread of the virus, especially in developing countries [9, 10]. Moreover, the differential mortality burden is also influenced by the disparate disease burden driven by the socioeconomic gradients with the poorest areas showing highest preventable mortality rates [11]. In Mexico, a highly populated country [12] with ∼42% of the population living in poverty (defined as the state if a person or group of people lack a specified amount of money or material possessions) [13] and ∼60% of the population working informally (jobs and workers are not protected or regulated by the state) [14], the pandemic has already exerted some of the highest COVID-19 mortality levels [15]. Mexico ranks fourth in the world in terms of the number of COVID-19 deaths, approximating a 9.8% case fatality rate (probability of dying for a person who has tested positive for the virus and is one of the most important features of the COVID-19), including the highest number of health worker deaths (∼2000 deaths) reported in any country [16-18]. Mexico also remains one of the countries with the lowest number of tests conducted for COVID-19 [19].
Mexico is fighting the COVID-19 pandemic under three phases of COVID-19 contingency identified by the Ministry of Health: Viral importation, community transmission and epidemic [20]. The COVID-19 pandemic in Mexico was likely seeded by imported COVID-19 cases reported on February 28, 2020 [21, 22]. As the virus spread across the nation in phase one of the pandemic, some universities switched to virtual classes, and some festivals and sporting events were postponed [23]. However, the government initially downplayed the impact of the virus and did not enforce strict social distancing measures. This led to large gatherings at some social events such as concerts, festivals and women’s soccer championship despite the sustained disease transmission in the country, with the early reproduction number estimated between ∼2.9-4.9 for the first 10 days of the epidemic [24, 25]. Despite the ongoing viral transmission, pandemic was generally under-estimated in Mexico [26].
Mexico entered phase 2 (community transmission) of the pandemic on March 24, 2020 as the virus started to generate local clusters of the disease [27, 28]. This was followed by closure of public and entertainment places along with suspension of gatherings of more than 50 people as late as March 25, 2020 [29]. Moreover, a national emergency declaration was issued on March 30, 2020, halting the majority of activities around the country with the aim to mitigate the spread of the virus [30]. However, the virus continued to spread across the country, ravaging through the poor and rural communities, resulting in the delayed implementation of stay-at-home orders by the government on April 12, 2020 [31]. These preventive orders were met with mixed reactions from people belonging to different socio-economic sectors of the community [32]. Moreover, restrictions on transportation to and from the regions most affected by COVID-19 were not implemented until April 16, 2020 as the virus continued to spread [33]. Shortly after, on April 21, 2020, Mexico announced phase 3 of the contingency (epidemic phase) with wide-spread community transmission [34].
With lockdowns and other restrictions in place, Mexican officials shared model output [35] predicting that COVID-19 case counts would peak in early May and that the epidemic was expected to end before July of 2020 [36]. Despite notorious disagreement between surveillance data and government forecasts, these model predictions continued to be cited by official and independent sources [37, 38]. The extent to which these overly optimistic predictions skewed the plans and budgets of private and public institutions remains unknown. Under the official narrative that the pandemic would soon be over, Mexico planned a gradual phased re-opening of its economy in early June 2020, as the “new normal” phase [30].
In Mexico, reopening of the economic activities started on June 1 under a four color traffic light monitoring system to alert the residents of the epidemiological risks based on the level of severity of the pandemic in each state on a weekly basis [39, 40]. As of December 29, 2020 Mexico exhibits high estimates of cumulative COVID-19 cases and deaths; 1,401,529 and 123,845 respectively [15]. Given the high transmission potential of the virus and limited application of tests in the country, testing only 24.54 people for every 1000 people (as of December 28, 2020) [19], estimates of the effective reproduction number from the case data and near real-time epidemic projections using mortality data could prove to be highly beneficial to understand the epidemic trajectory. It may also be useful to assess the effect of intervention strategies such as the stay-at-home orders and mobility patterns on the trajectory of the epidemic curve along with the spatiotemporal dynamics of the virus.
In order to investigate the transmission dynamics of the unfolding COVID-19 epidemic in Mexico, we analyze the case data by date of symptoms onset and the death data by date of reporting using mathematical models that are useful to characterize the empirical patterns of epidemic [41, 42]. We also examine the mobility trends and their relationship with the epidemic curve for death along with estimating the effective reproduction number of SARS-CoV-2 to understand the transmission dynamics during the course of the pandemic in Mexico. Moreover, we employ statistical methods from functional data analysis to study the shapes of the COVID-19 growth rate curves at the state level. This helps us characterize the spatio-temporal dynamics of the pandemic based on the shape features of these curves. Lastly, twitter data showing the frequency of tweets indicating stay-at-home-order is analyzed in relation to COVID-19 cases counts at the national level.
Methods
Data
Five sources of data are analyzed in this manuscript. A brief description of the datasets and their sources are described below.
(i) IHME data for short term forecasts Apple mobility trends data
We utilized the openly published IHME smoothed trend in daily and cumulative COVID-19 reported deaths for (i) Mexico (country) and (ii) Mexico City (capital of Mexico) as of October 9, 2020 to generate the forecasts [43]. IHME smoothed data estimates were utilized as they were corrected for the irregularities in the daily death data reporting, by averaging model results over the last seven days. As this was our source of data for prediction modeling, it was chosen for its regular updates. The statistical procedure of spline regressions obtained from MR-BRT (“meta-regression—Bayesian, regularized, trimmed”) smooths the trend in COVID-19 reported deaths as described in ref [44]. This data are publicly available from the IHME COVID-19 estimates downloads page [43]. For this analysis, deaths as reported by the IHME model (current projection scenario as described ahead) on November 11, 2020 are used as a proxy for actual reported deaths attributed to COVID-19.
(ii) Apple mobility trends data
Mobility data for Mexico published publicly by Apple’s mobility trends reports was retrieved as of December 5, 2020 [45]. This aggregated and anonymized data is updated daily and includes the relative volume of directions requests per country compared to a baseline volume on January 13, 2020. Apple has released the data for the three modes of human mobility: Driving, walking and public transit. The mobility measures are normalized in the range 0-100 for each country at the beginning of the series, so trends are relative to this baseline.
(iii) Case incidence and genomic data for estimating reproduction number
In order to estimate the early reproduction number we use two different data sources. For estimating the reproduction number from the genomic data, 111 SARS-CoV-2 genome samples were obtained from the Global initiative on sharing all influenza data (GISAID) repository between February 27-May 29, 2020 [46]. For estimating the reproduction number from the case incidence data (early reproduction number and the effective reproduction number), we utilized publicly available time series of laboratory-confirmed cases by dates of symptom onset which were obtained from the Mexican Ministry of Health as of December 5, 2020 [15].
(iv) Case incidence data for Spatial analysis
We recovered daily case incidence data for all 32 states of Mexico from March 20 to December 5 from the Ministry of Health Mexico, as of December 5, 2020 [15].
(v) Twitter data for twitter analysis
For the twitter data analysis, we retrieved data from the publicly available twitter data set of COVID-19 chatter from March 12 to November 11, 2020 [47].
Modeling framework for forecast generation
We harness three dynamics phenomenological models previously applied to various infectious diseases (e.g., SARS, pandemic influenza, Ebola [48, 49] and the current COVID-19 outbreak [50, 51]) for mortality modeling and short-term forecasting in Mexico and Mexico City. These models include the simple scalar differential equation models such as the generalized logistic growth model [49] and the Richards growth model [52]. We also utilize the sub-epidemic wave model [48] that captures complex epidemic trajectories by assembling the contribution of multiple overlapping sub-epidemic waves. The mortality forecasts obtained from these mathematical models can provide valuable insights on the disease transmission mechanisms, the efficacy of intervention strategies and the evaluation of optimal resource allocation procedures to inform public health policies. COVID-19 pandemic forecasts generated by The Institute for Health Metrics and Evaluation (IHME) are used as a competing benchmark model. The description of these models is provided in the supplementary file.
The forecasts generated by calibrating our three phenomenological models using the IHME smoothed data estimates (reference scenario) are compared with the forecasts generated by the IHME reference scenario and two IHME counterfactual scenarios. The IHME reference scenario depicts the “current projection”, which assumes that the social distancing measures are re-imposed for six weeks whenever daily deaths reach eight per million. The second scenario “mandates easing” implies what would happen if the government continues to ease social distancing measures without re-imposition. Lastly, the third scenario, “universal masks” accounts for universal facemask wearing, that reflects 95% mask usage in public and social distancing mandates reimposed at 8 deaths per million. Detailed description of these modeling scenarios and their assumptions is explained in ref. [43].
Model calibration and forecasting approach
We conducted 30-day ahead short-term forecasts utilizing thirteen data sets spanned over a period of four months (July 4-October 9, 2020) (Table 1). Each forecast was fitted to the daily death counts from the IHME smoothed data estimates reported between March 20-September 27, 2020 for (i) Mexico and (ii) Mexico City. The first calibration period relies on data from March 20-July 4, 2020. Sequentially models are recalibrated each week with the most up-to-date data, meaning the length of the calibration period increases by one week up to August 2, 2020. However, owing to irregular publishing of data estimates by the IHME, after August 2, 2020 the length of calibration period increased by 2 weeks, followed by a one week increase from August 17-September 27, 2020 as the data estimates were again published every week.
Characteristics of the data sets used for the sequential calibration and forecasting of the COVID-19 pandemic in Mexico and Mexico City (2020).
We compare the cumulative mortality forecasting results obtained from our models to the cumulative smoothed death estimates reported by IHME reference scenario as of November 11, 2020. Weekly forecasts obtained from our models were compared to the forecasts obtained from the three IHME modeling scenarios for the same calibration and forecasting periods.
For each of the three models; GLM, Richards and the sub-epidemic model, we estimate the best fit solution for each model using non-linear least square fitting [53]. This process minimizes the sum of squared errors between the model fit,  and the smoothed data estimates, yt and yields the best set of parameter estimates Θ = (θ1, θ2, …, θm). The parameters
and the smoothed data estimates, yt and yields the best set of parameter estimates Θ = (θ1, θ2, …, θm). The parameters  defines the best fit model f(t=Θ) where
defines the best fit model f(t=Θ) where  corresponds to the set of parameters of the sub-epidemic model,
corresponds to the set of parameters of the sub-epidemic model,  corresponds to set of parameters of the Richards model and
corresponds to set of parameters of the Richards model and  corresponds to the set of parameters of the GLM model. For the GLM and sub-epidemic wave model, we provide initial best guesses of the parameter estimates. However, for the Richards growth model, we initialize the parameters for the nonlinear least squares’ method [53] over a wide range of feasible parameters from a uniform distribution using Latin hypercube sampling [54] in order to test the uniqueness of the best fit model. Moreover, the initial conditions are set at the first data point for each of the three models [55]. Uncertainty bounds around the best-fit solution are generated using parametric bootstrap approach with replacement of data assuming a Poisson error structure for the GLM and sub-epidemic model, whereas a negative binomial error structure was used to generate the uncertainty bounds of the Richards growth model; where we assume the mean to be three times the variance based on the noise in the data. Detailed description of this method is provided in ref [55].
corresponds to the set of parameters of the GLM model. For the GLM and sub-epidemic wave model, we provide initial best guesses of the parameter estimates. However, for the Richards growth model, we initialize the parameters for the nonlinear least squares’ method [53] over a wide range of feasible parameters from a uniform distribution using Latin hypercube sampling [54] in order to test the uniqueness of the best fit model. Moreover, the initial conditions are set at the first data point for each of the three models [55]. Uncertainty bounds around the best-fit solution are generated using parametric bootstrap approach with replacement of data assuming a Poisson error structure for the GLM and sub-epidemic model, whereas a negative binomial error structure was used to generate the uncertainty bounds of the Richards growth model; where we assume the mean to be three times the variance based on the noise in the data. Detailed description of this method is provided in ref [55].
Each of the M best-fit parameter sets are used to construct the 95% confidence intervals for each parameter by refitting the models to each of the M = 300 datasets generated by the bootstrap approach during the calibration phase. Further, each M best fit model solution is used to generate m= 30 additional simulations with Poisson error structure for GLM and sub-epidemic model and negative binomial error structure for Richards model extended through a 30-day forecasting period. We construct the 95% prediction intervals with these 9000 (M × m) curves for the forecasting period. Detailed description of the methods of parameter estimation can be found in references [55-57]
Performance metrics
We utilized the following four performance metrics to assess the quality of our model fit and the 30-day ahead short term forecasts: the mean absolute error (MAE) [58], the mean squared error (MSE) [59], the coverage of the 95% prediction intervals [59], and the mean interval score (MIS) [59] for each of the three models: GLM, Richards model and the sub-epidemic model. For calibration performance, we compare the model fit to the observed smoothed death data estimates fitted to the model, whereas for the performance of forecasts, we compare our forecasts with the smoothed death data reported on November 11, 2020 for the time period of the forecast.
The mean squared error (MSE) and the mean absolute error (MAE) assess the average deviations of the model fit to the observed death data. The mean absolute error (MAE) is given by:
 The mean squared error (MSE) is given by:
The mean squared error (MSE) is given by:
 where
where  is the time series of reported smoothed death estimates,ti is the time stamp and
is the time series of reported smoothed death estimates,ti is the time stamp and  is the set of model parameters. For the calibration period, n equals the number of data points used for calibration, and for the forecasting period, n = 30 for the 30-day ahead short-term forecast.
is the set of model parameters. For the calibration period, n equals the number of data points used for calibration, and for the forecasting period, n = 30 for the 30-day ahead short-term forecast.
Moreover, in order to assess the model uncertainty and performance of prediction interval, we use the 95% PI and MIS. The prediction coverage is defined as the proportion of observations that fall within 95% prediction interval and is calculated as:
 where Yt are the smoothed death data estimates, Lt and Ut are the lower and upper bounds of the 95% prediction intervals, respectively, n is the length of the period, and I is an indicator variable that equals 1 if value of Yt is in the specified interval and 0 otherwise
where Yt are the smoothed death data estimates, Lt and Ut are the lower and upper bounds of the 95% prediction intervals, respectively, n is the length of the period, and I is an indicator variable that equals 1 if value of Yt is in the specified interval and 0 otherwise
The mean interval score addresses the width of the prediction interval as well as the coverage. The mean interval score (MIS) is given by:
 In this equation Lt, Ut, n and I are as specified above for PI coverage. Therefore, if the PI coverage is 1, the MIS is the average width of the interval across each time point. For two models that have an equivalent PI coverage, a lower value of MIS indicates narrower intervals [59].
In this equation Lt, Ut, n and I are as specified above for PI coverage. Therefore, if the PI coverage is 1, the MIS is the average width of the interval across each time point. For two models that have an equivalent PI coverage, a lower value of MIS indicates narrower intervals [59].
Mobility data analysis
In order to analyze the time series data for Mexico from March 20-December 5, 2020 for three modes of mobility; driving, walking and public transport we utilize the R code developed by Kieran Healy [60]. We analyze the mobility trends to look for any pattern in sync with the curve of COVID-19 death counts. The time series for mobility requests is decomposed into trends, weekly and remainder components. The trend is a locally weighted regression fitted to the data and remainder is any residual left over on any given day after the underlying trend and normal daily fluctuations have been accounted for.
Reproduction number
We estimate the reproduction number, R, for the early ascending phase of the COVID-19 epidemic in Mexico and the instantaneous reproduction number Rt throughout the epidemic. Reproduction number, Rt, is a crucial parameter that characterizes the average number of secondary cases generated by a primary case at calendar time t during the outbreak. This quantity is critical to identify the magnitude of public health interventions required to contain an epidemic [61-63]. Estimates of Rt indicate if the widespread disease transmission continues (Rt >1) or disease transmission declines (Rt <1). Therefore, in order to contain an outbreak, it is vital to maintain Rt <1.
Estimating the reproduction number, Rt, from case incidence using generalized growth model (GGM)
The GGM is a useful phenomenological model that allows relaxation of the exponential growth during early ascending phase of the outbreak via a modulating “deceleration of growth” parameter, p. The GGM is as follows:
 In this equation the solution C(t) describes the cumulative number of cases at time t C′(t) describes the incidence curve over time t,r is the growth rate and p∈[0,1] is a “deceleration of growth” parameter. If p =0, this equation becomes constant incidence over time, whereas for cumulative cases if p =1, the equation provides an exponential solution. If p is in the intermediate range i.e. 0< p <1, then the model solution describes the sub-exponential growth dynamics [55, 64].
In this equation the solution C(t) describes the cumulative number of cases at time t C′(t) describes the incidence curve over time t,r is the growth rate and p∈[0,1] is a “deceleration of growth” parameter. If p =0, this equation becomes constant incidence over time, whereas for cumulative cases if p =1, the equation provides an exponential solution. If p is in the intermediate range i.e. 0< p <1, then the model solution describes the sub-exponential growth dynamics [55, 64].
We estimate the reproduction number by calibrating the GGM (as described in the supplemental file) to the early growth phase of the epidemic (February 27-May 29, 2020) [64]. The generation interval of SARS-CoV-2 is modeled assuming gamma distribution with a mean of 5.2 days and a standard deviation of 1.72 days [65]. We estimate the growth rate parameter r, and the deceleration of growth parameter p, as described above. The GGM model is used to simulate the progression of local incidence cases Ii at calendar time ti This is followed by the application of the discretized probability distribution of the generation interval denoted by ρi to the renewal equation to estimate the reproduction number at time ti [66-68]:
 The numerator represents the total new cases Ii, and the denominator represents the total number of cases that contribute (as primary cases) to generating the new cases Ii (as secondary cases) at time Ri This way, Rt, represents the average number of secondary cases generated by a single case at calendar time t The uncertainty bounds around the curve of Rt are derived directly from the uncertainty associated with the parameter estimates (r, p) obtained from the GGM. We estimate Rt for 300 simulated curves assuming a negative binomial error structure [55].
The numerator represents the total new cases Ii, and the denominator represents the total number of cases that contribute (as primary cases) to generating the new cases Ii (as secondary cases) at time Ri This way, Rt, represents the average number of secondary cases generated by a single case at calendar time t The uncertainty bounds around the curve of Rt are derived directly from the uncertainty associated with the parameter estimates (r, p) obtained from the GGM. We estimate Rt for 300 simulated curves assuming a negative binomial error structure [55].
Instantaneous reproduction number Rt, using the Cori method
The instantaneous Rt is estimated by the ratio of number of new infections generated at calendar time t (It), to the total infectiousness of infected individuals at time t given by  [69, 70]. Hence Rt can be written as:
[69, 70]. Hence Rt can be written as:
 In this equation, It is the number of new infections on day t and ws represents the infectivity function, which is the infectivity profile of the infected individual. This is dependent on the time since infection (s), but is independent of the calendar time (t) [71, 72].
In this equation, It is the number of new infections on day t and ws represents the infectivity function, which is the infectivity profile of the infected individual. This is dependent on the time since infection (s), but is independent of the calendar time (t) [71, 72].
The term  describes the sum of infection incidence up to time step t − 1, weighted by the infectivity function. The distribution of the generation time can be applied to approximate ws, however, since the time of infection is a rarely observed event, measuring the distribution of generation time becomes difficult [69]. Therefore, the time of symptom onset is usually used to estimate the distribution of serial interval (SI), which is defined as the time interval between the dates of symptom onset among two successive cases in a disease transmission chain [73].
describes the sum of infection incidence up to time step t − 1, weighted by the infectivity function. The distribution of the generation time can be applied to approximate ws, however, since the time of infection is a rarely observed event, measuring the distribution of generation time becomes difficult [69]. Therefore, the time of symptom onset is usually used to estimate the distribution of serial interval (SI), which is defined as the time interval between the dates of symptom onset among two successive cases in a disease transmission chain [73].
The infectiousness of a case is a function of the time since infection, which is proportional to if the timing of infection in the primary case is set as time zero of ws and we assume that the generation interval equals the SI. The SI was assumed to follow a gamma distribution with a mean of 5.2 days and a standard deviation of 1.72 days [65]. Analytical estimates of Rt were obtained within a Bayesian framework using EpiEstim R package in R language [73]. Rt was estimated at 7-day intervals. We reported the median and 95% credible interval (CrI).
Estimating the reproduction number, R, from the genomic analysis
In order to estimate the reproduction number for the SARS-CoV-2 between February 27-May 29, 2020, from the genomic data, 111 SARS-CoV-2 genomes sampled from infected patients from Mexico and their sampling times were obtained from GISAID repository [46]. Short sequences and sequences with significant number of gaps and non-identified nucleotides were removed, yielding 83 high-quality sequences. For clustering, they were complemented by sequences from other geographical regions, down sampled to n=4325 representative sequences. We used the sequence subsample from Nextstrain (www.nextstrain.org) global analysis as of August 15, 2020. These sequences were aligned to the reference genome taken from the literature [74] using MUSCLE [75] and trimmed to the same length of 29772 bp. The maximum likelihood phylogeny has been constructed using RAxML[76]
The largest Mexican cluster that possibly corresponds to within-country transmissions has been identified using hierarchical clustering of sequences. The phylodynamics analysis of that cluster have been carried out using BEAST v1.10.4 [77]. We used strict molecular clock and the tree prior with exponential growth coalescent. Markov Chain Monte Carlo sampling has been run for 10,000,000 iterations, and the parameters were sampled every 1000 iterations. The exponential growth rate f estimated by BEAST was used to calculate the reproductive number R. For that, we utilized the standard assumption that SARS-CoV-2 generation intervals (times between infection and onward transmission) are gamma-distributed [78]. In that case R can be estimated as  , where µ and σ are the mean and standard deviation of that gamma distribution. Their values were taken from ref [65].
, where µ and σ are the mean and standard deviation of that gamma distribution. Their values were taken from ref [65].
Spatial analysis
For the shape analysis of incidence rate curves we followed ref. [79] to pre-process the daily cumulative COVID-19 data at state level as follows:
Time differencing: If fi(t) denotes the given cumulative number of confirmed cases for state i on day t, then per day growth rate at time t is given by gi(t) = fi(t) − fi(t − 1).
Smoothing: We then smooth the normalized curves using smooth function in Matlab.
Rescaling: Rescaling of each curve is done by dividing each gi by the total confirmed cases for a state i. That is, compute hi(t) = gi(t)/ri where ri =∑t gi(t).
To identify the clusters by comparing the curves, we used a simple metric. For any two rate curves, hi and hj, we compute the norm ||hi −hj||, where the double bars denote the L2 norm of the difference function, i.e.  .
.
This process is depicted in S17 Fig. To identify the clusters by comparing the curves, we used a simple metric. For any two rate curves, hi and hj, we compute the norm ||hi − hj ||, where the double bars denote the L2 norm of the difference function, i.e.  . To perform clustering of 32 curves into smaller groups, we apply the dendrogram function in Matlab using the “ward” linkage as done in the previous work [80]. The number of clusters is decided empirically based on the display of overall clustering results. After clustering the states into different groups, we derived average curve for each cluster after using a time wrapping algorithm as done in previous work [80, 81].
. To perform clustering of 32 curves into smaller groups, we apply the dendrogram function in Matlab using the “ward” linkage as done in the previous work [80]. The number of clusters is decided empirically based on the display of overall clustering results. After clustering the states into different groups, we derived average curve for each cluster after using a time wrapping algorithm as done in previous work [80, 81].
Twitter data analysis
To observe any relationship between the COVID-19 cases by dates of symptom onset and the frequency of tweets indicating stay-at-home orders we used a public dataset of 698 Million tweets of COVID-19 chatter [47]. The frequency of tweets indicating stay-at-home order is used to gauge the compliance of people with the orders of staying at home to avoid spread of the virus by maintaining social distance. Tweets indicate the magnitude of the people being pro-lockdown and show how these numbers have dwindled over the course of the pandemic. To get to the plotted data, we removed all retweets and tweets not in the Spanish language. We also filtered by the following hashtags: #quedateencasa, and #trabajardesdecasa, which are two of the most used hashtags when users refer to the COVID-19 pandemic and their engagement with health measures. Lastly, we limited the tweets to the ones that originated from Mexico, via its 2-code country code: MX. A set of 521,359 unique tweets were gathered from March 12 to November 11, 2020. We then overlay the curve of tweets over the epi-curve in Mexico to observe any relation between the shape of the epidemic case trajectory and the frequency of tweets during the time period, March 12-November 11, 2020. We also estimate the correlation coefficient between the cases and frequency of tweets.
Results
Fig 1 (upper panel) shows the daily COVID-19 death curve in Mexico and Mexico City from March 20-November 11, 2020. As of November 11, 2020, Mexico has reported 105,656 deaths whereas Mexico City has reported 15,742 deaths as per the IHME smoothed death estimates. The mobility trend for Mexico (Fig 1, lower panel) shows that the human mobility tracked in the form of walking, driving and public transportation declined from end of March to the beginning of June, corresponding to the implementation of social distancing interventions and the Jornada Nacional de Sana Distancia that was put in place between March 23-May 30, 2020 encompassing the suspension of non-essential activities in public, private and social sectors [82]. The driving and walking trend subsequently increased in June with the reopening of the non-essential services. Fig 1 (upper panel) shows that reopening coincides with the highest levels of daily deaths. These remain at a high level for just over two months (June and July). Then, from mid-August, the number of deaths begins to fall, reaching a reduction of nearly 50% by mid-October. But at the end of October a new growth begins.

Upper panel: Epidemic curve for the COVID-19 deaths in Mexico and Mexico City from March 20-November 11, 2020. Blue line depicts the confirmed deaths in Mexico and green line depicts the confirmed deaths in Mexico City.
Lower panel: The mobility trends for Mexico. Orange line shows the driving trend, blue line shows the transit trend and the black line shows the walking trend.
In the subsequent sections, we first present the results for the short-term forecasting, followed by the estimation of the reproduction numbers from the early phase of the COVID-19 epidemic in Mexico and the instantaneous reproduction number. Then we present the results of the spatial analysis followed by the results of the twitter data analysis.
Model calibration and forecasting
Here we compare the calibration and 30-day ahead forecasting performance of our three models: the GLM, Richards growth model and the sub-epidemic wave model between March 20-September 27, 2020 for (i) Mexico and (ii) Mexico City. We also compare the results of our cumulative forecasts with the IHME forecasting estimates (for the three scenarios) obtained from the IHME data.
Calibration performance
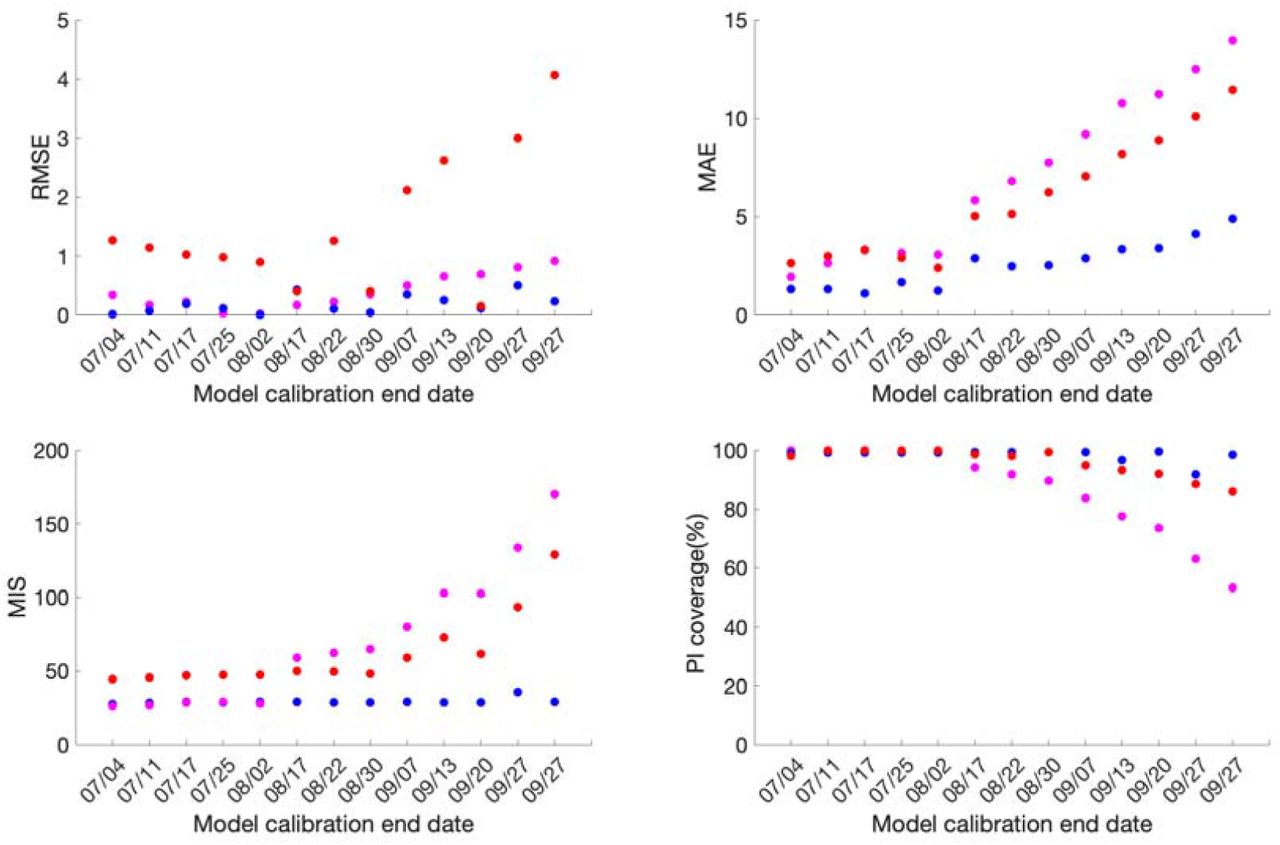
Across the thirteen sequential model calibration phases for Mexico over a period of seven months (March-September), based on the calibration phases as provided in Table S1 and Fig 2, the sub-epidemic model outperforms the GLM with lower RMSE estimates for the seven calibration phases 3/20-07/04, 3/20-7/17, 3/20-8/17, 3/20-08/22, 3/20-09/13, 3/20-09/20, 3/20-09/27. The GLM model outperforms the other two models for the remaining six calibration phases in terms of RMSE. The Richards model has substantially higher RMSE (between 10.2-24.9) across all thirteen calibration phases. The sub-epidemic model also outperforms the other two models in terms of MAE, MIS and the 95% PI coverage. The sub-epidemic model shows the lowest values for MIS and the highest 95% PI coverage for nine of the thirteen calibration phases (Table S1). Moreover, the sub-epidemic model outperforms the other two models in eleven calibration phases for MAE. The Richards model shows much higher MIS and lower 95% PI coverage compared to the GLM and sub-epidemic model.

Calibration performance for each of the thirteen sequential calibration phases for GLM (magenta), Richards (red) and sub-epidemic (blue) model for Mexico. High 95% PI coverage and lower mean interval score (MIS), root mean square error (RMSE) and mean absolute error (MAE) indicate better performance.
For the Mexico City, the sub-epidemic model has the lowest RMSE for eleven of the thirteen calibration phases followed by the GLM and Richards model. The MAE is also the lowest for the sub-epidemic model for all thirteen calibration phases, followed by the GLM and Richards growth model. Further, in terms of MIS, the sub-epidemic model outperforms the Richards and GLM model for nine calibration phases whereas the GLM model outperforms the other two models in four calibration phases (3/20-7/04, 3/20-7/11,3/20-7/17, 3/20-8/02). The Richards model has much higher estimates for the MIS compared to the other two models. The 95% PI across all thirteen calibration phases lies between 91.6-99.6% for the sub-epidemic model, followed by the Richards model (85.9-100%) and the GLM model (53.2-100%) (Table S2, Fig 3).

Calibration performance for each of the thirteen sequential calibration phases for GLM (magenta), Richards (red) and sub-epidemic (blue) model for Mexico City. High 95% PI coverage and lower mean interval score (MIS), root mean square error (RMSE) and mean absolute error (MAE) indicate better performance.
Over-all the goodness of fit metrics points toward the sub-epidemic model as the most appropriate model for the Mexico City and Mexico in all four performance metrics except for the RMSE for Mexico, where the estimates of GLM model compete with the sub-epidemic model.
Forecasting performance
The forecasting results for Mexico are presented in Fig 4 and Table S4. For Mexico, the sub-epidemic model consistently outperforms the GLM and Richards growth model for ten out of the thirteen forecasting phases in terms of RMSE and MAE, eight forecasting phases in terms of MIS and nine forecasting phases in terms of the 95% PI coverage. This is followed by the GLM and then the Richards growth model.

Forecasting period performance metrics for each of the thirteen sequential forecasting phases for GLM (magenta), Richards (red) and sub-epidemic (blue) model for Mexico. High 95% PI coverage and lower mean interval score (MIS), root mean square error (RMSE) and mean absolute error (MAE) indicate better performance.
Similarly, for Mexico City, the sub-epidemic model consistently outperforms the GLM and Richards growth model for ten of the thirteen forecasting phases in terms of RMSE, MAE and MIS. Whereas, in terms of 95% PI coverage, the sub-epidemic model outperforms the Richards and GLM model in six forecasting phases, with the Richards model performing better than the GLM model (Fig 5, Table S3).

Forecasting period performance metrics for each of the thirteen sequential forecasting phases for GLM (magenta), Richards (red) and sub-epidemic (blue) model for the Mexico City. High 95% PI coverage and lower mean interval score (MIS), root mean square error (RMSE) and mean absolute error (MAE) indicate better performance.
Comparison of daily death forecasts
The thirteen sequentially generated daily death forecasts from GLM and Richards growth model, for Mexico and Mexico City indicate towards a sustained decline in the number of deaths (S1 Fig, S2 Fig, S3 Fig and S4 Fig). However, the IHME model (actual smoothed death data estimates) shows a decline in the number of deaths for the first six forecasts periods followed by a stable epidemic trajectory for the last seven forecasts, for Mexico City and Mexico. Unlike the GLM and Richards models, the sub-epidemic model is able to reproduce the observed stabilization of daily deaths observed after the first six forecast periods for Mexico and the last three forecasts for Mexico City (S5 Fig, S6 Fig, S7 Fig and S8 Fig)
Comparison of cumulative mortality forecasts
The total number of COVID-19 deaths is an important quantity to measure the progression of an epidemic. Here we present and compare the results of our 30-day ahead cumulative forecasts generated using GLM, Richards and sub-epidemic growth model against the actual reported smoothed death data estimates using the estimates of deaths obtained from the IHME death data reported as of November 11, 2020. Figs 6 and 7 present a comparative assessment of the estimated cumulative death counts derived from our three models along with their comparison with three IHME modeling scenarios; current projection, universal masks and mandates easing; for our thirteen sequentially generated forecasts.

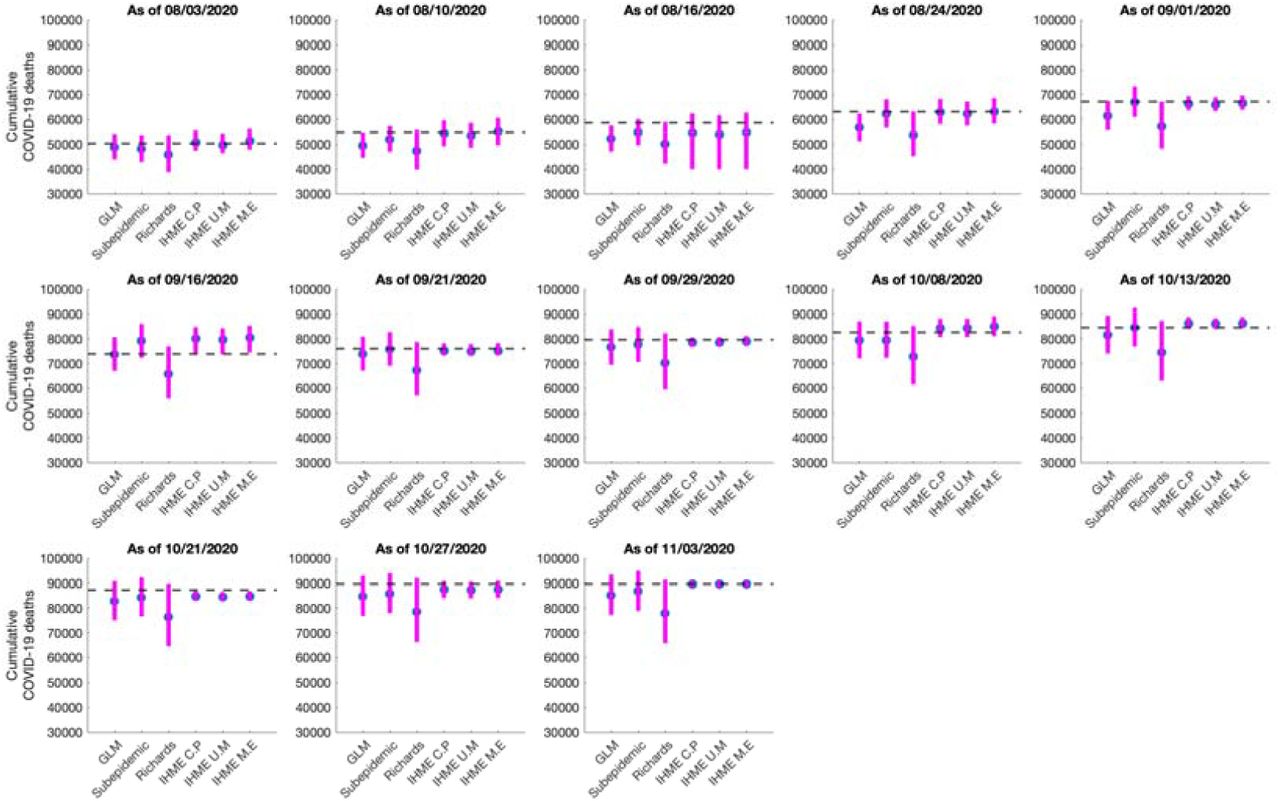
Systematic comparison of the six models (GLM, Richards, sub-epidemic model, IHME current projections (IHME C.P), IHME universal masks (IHME U.M) and IHME mandates easing (IHME M.E)) to predict the cumulative COVID-19 deaths for Mexico in the thirteen sequential forecasts. The blue circles represent the mean deaths and the magenta vertical line indicates the 95% PI around the mean death count. The horizontal dashed line represents the actual death count reported by that date in the November 11, 2020 IHME estimates files.

Systematic comparison of the six (GLM, Richards, sub-epidemic model, IHME current projections (IHME C.P), IHME universal masks (IHME U.M) and IHME mandates easing (IHME M.E))to predict the cumulative COVID-19 deaths for the Mexico City in the thirteen sequential forecasts. The blue circles represent the mean deaths and the magenta vertical line indicates the 95% PI around the mean death count. The horizontal dashed line represents the actual death count reported by that date in the November 11, 2020 IHME estimates files.
Mexico
The 30 day ahead forecast results for the thirteen sequentially generated forecasts for Mexico utilizing GLM, Richards model, sub-epidemic growth model and IHME model are presented in S9 Fig, S10 Fig, S11 Fig and S12 Fig. The cumulative death comparison is given in Fig 6. For the first, second, third and thirteenth generated forecasts the GLM, sub-epidemic model and the Richards model tend to underestimate the true deaths counts (∼50,255, ∼54,857, ∼58,604, 89,730 deaths), whereas the three IHME forecasting scenarios closely estimate the actual death counts. For the fourth, fifth and seventh generated forecast the sub-epidemic model and the IHME scenarios most closely approximate the actual death counts ∼63,078, ∼67,075, ∼76,054 deaths respectively). For the sixth generated forecast the GLM model closely approximates the actual death count (∼73,911 deaths) whereas for the tenth generated forecast the sub-epidemic model closely approximates the actual deaths (∼84,471 deaths). For the eighth, ninth, eleventh and twelfth generated forecast GLM, Richards and sub-epidemic model tend to under-predict the actual death counts with IHME model estimates closely approximating the actual death counts (Table 2).
Cumulative mortality estimates for each forecasting period of the COVID-19 pandemic in Mexico (2020).
In summary, the Richards growth model consistently under-estimates the actual death count compared to the GLM, sub-epidemic and three IHME model scenarios. The GLM model also provides lower estimates of the mean death counts compared to the sub-epidemic and three IHME model scenarios, but higher mean death estimates than the Richards model. The 95% PI for the Richards model is substantially wider than the other two models. Moreover, the three IHME model scenarios predict approximately similar cumulative death counts across the thirteen generated forecasts, hence indicating that they do not differ substantially.
Mexico City
The 30 day ahead forecast results for thirteen sequentially generated forecasts for the Mexico City utilizing GLM, Richards model, sub-epidemic growth model and IHME model are presented in S13 Fig, S14 Fig, S15 Fig and S16 Fig. The cumulative death comparison is given in Fig 7 and Table 3. For the fourth and fifth generated forecast all models under-predict the true death counts (11,326, 11,769 deaths respectively). For the first and second generated forecast the sub-epidemic model and the IHME scenarios closely approximate the actual death count (∼10,081, ∼10,496 deaths). For the third and sixth generated forecast GLM and Richards model underestimate the actual death count (∼10,859, ∼12,615 deaths respectively) whereas the sub-epidemic model over predicts the death count for the third forecast and under-predicts the death count for the sixth forecast. The three IHME model scenarios seem to predict the actual death counts closely. From the seventh-thirteenth generated forecasts, all models under-predict the actual death counts.
Cumulative mortality estimates for each forecasting period of the COVID-19 pandemic in Mexico City (2020).
In general, the Richards growth model has much wider 95% PI coverage compared to the other models. The mean cumulative death count estimates for the GLM and Richards model closely approximate each other for the cumulative forecasts. However, the actual mean death counts lie within the 95% PI of the GLM and sub-epidemic model for all the thirteen forecasts. The three IHME model scenarios predict approximately similar cumulative death counts across the thirteen generated forecasts with much narrow 95% PI’s.
Reproduction number
Estimate of reproduction number, R from genomic data analysis
The majority of analyzed Mexican SARS-CoV-2 sequences (69 out of 83) have been sampled in March and April, 2020. These sequences are spread along the whole global SARS-CoV-2 phylogeny (Fig 8) and split into multiple clusters. This indicates multiple introductions of SARS-CoV-2 to the country during the initial pandemic stage (February 27-May 29, 2020). For the largest cluster of size 42, the reproduction number was estimated at R = 1.3 (95% HPD interval [1.1,1.5]).

Global neighbor-joining tree for SARS-CoV-2 genomic data from February 27-May 29, 2020. Sequences sampled in Mexico are highlighted in red.
Estimate of reproduction number, Rt from case incidence data
The reproduction number from the case incidence data (February 27-May 29, 2020) using GGM was estimated at Rt ∼1.1(95% CI:1.1,1.1), in accordance with the estimate of Rt obtained from the genomic data analysis. The growth rate parameter, r, was estimated at 1.2 (95% CI: 1.1, 1.4) and the deceleration of growth parameter, p, was estimated at 0.7 (95% CI: 0.68,0.71), indicating early sub-exponential growth dynamics of the epidemic (Fig 9).

Upper panel: Reproduction number with 95% CI estimated using the GGM model. The estimated reproduction number of the COVID-19 epidemic in Mexico as of May 29, 2020, 2020 is 1.1 (95% CI: 1.1, 1.1). The growth rate parameter, r, is estimated at 1.2(95%CI: 1.1, 1.4) and the deceleration of growth parameter, p, is estimated at 0.7 (95%CI:0.68, 0.71).
Lower panel: The lower panel shows the GGM fit to the case incidence data for the first 90 days.
Estimate of instantaneous reproduction number, Rt
The instantaneous reproduction number for Mexico remained consistently above 1.0 until the end of May 2020, after which the reproduction number has fluctuated around 1.0 with the estimate of Rt ∼0.93 (95% CrI: 0.91, 0.94) as of September 27, 2020. For Mexico City, the reproduction number remained above 1.0 until the end of June after which it has fluctuated around 1.0 with the estimate of Rt ∼0.96 (95% CrI: 0.93, 0.99) as of September 27, 2020 (Fig 10).
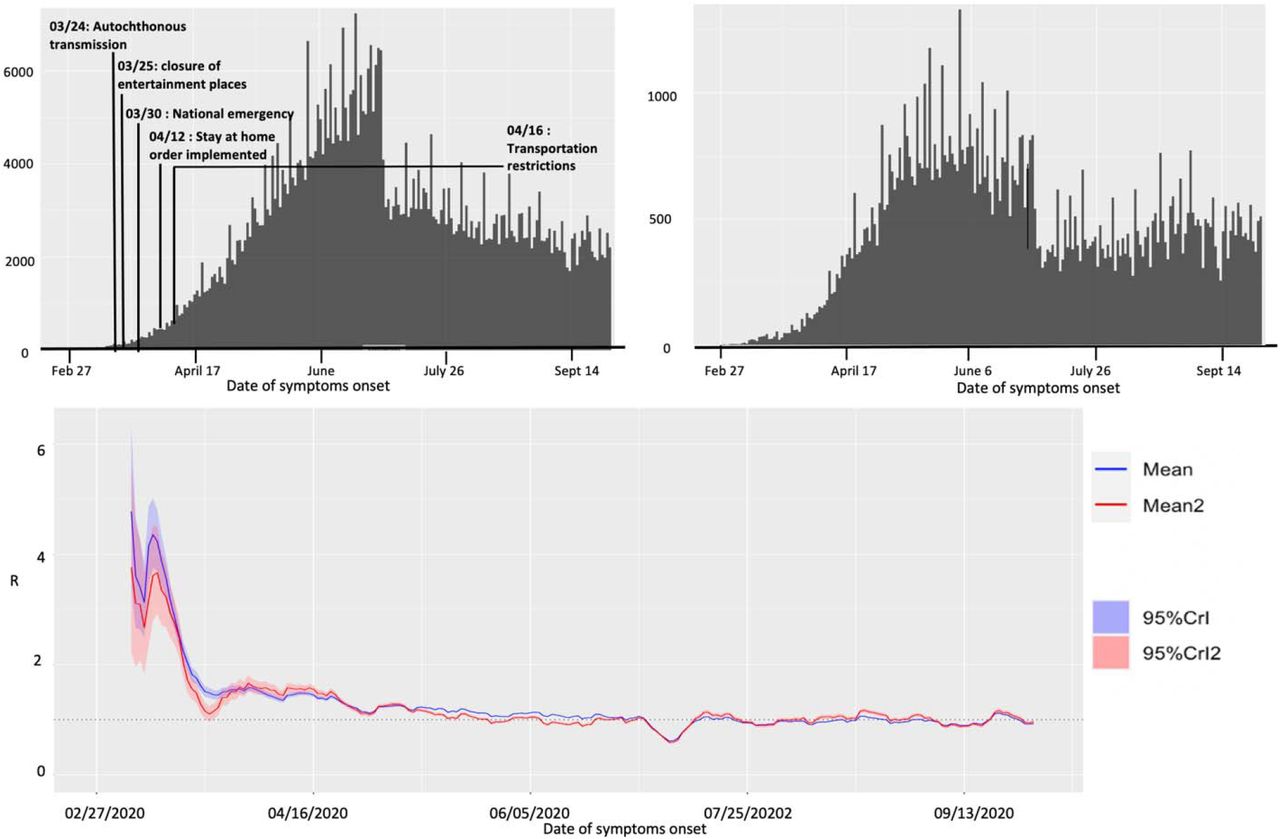
Upper panel: Epidemiological curve (by the dates of symptom onset) for Mexico (left panel) and Mexico City (right panel) as of September 27, 2020.
Lower panel: Instantaneous reproduction number with 95% credible intervals for the COVID-19 epidemic in Mexico as of September 27, 2020. The red solid line represents the mean reproduction number for Mexico and the red shaded area represents the 95% credible interval around it. The blue solid line represents the mean reproduction number for the Mexico City and the blue shaded region represents the 95% credible interval around it.
Spatial analysis
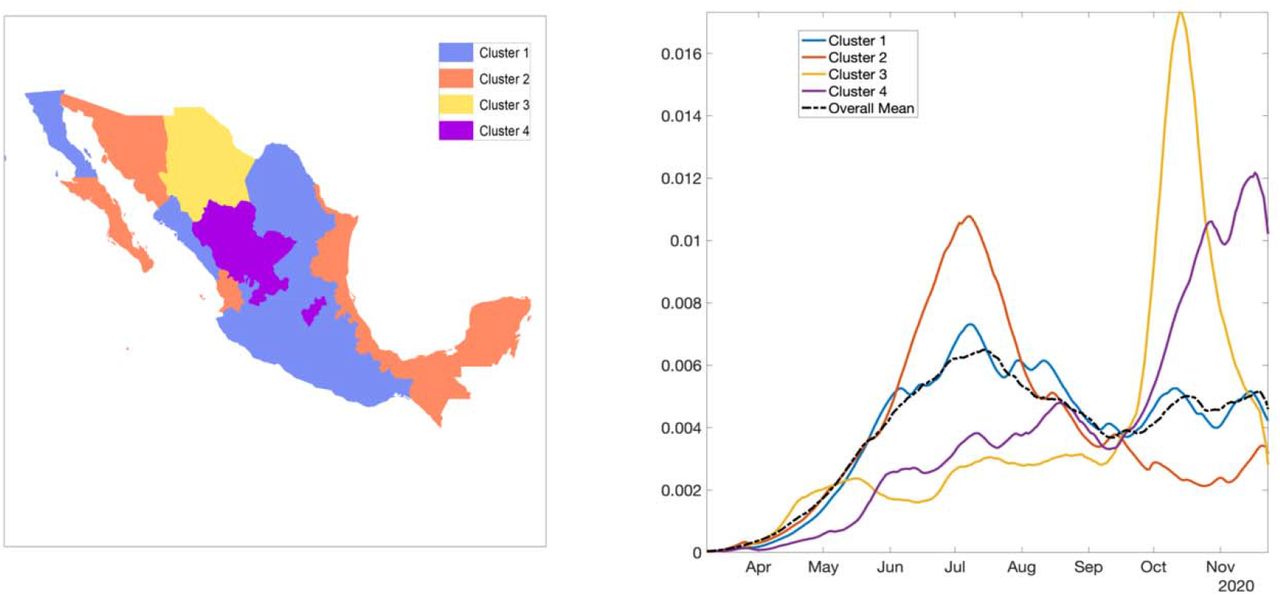
Fig S17 shows the result from pre-processing COVID-19 data into growth rate functions. The results of clustering are shown in Fig S18 as a dendrogram plot and the states color coded based on their cluster membership within the map of Mexico (Fig 11; left panel). The four predominant clusters we identified include the following states:

Clusters of states by their growth rates. Cluster 1 in blue, cluster 2 in orange, cluster 3 in yellow, and cluster 4 in purple. The right panel shows the average growth rate curves for each cluster (solid curves) and their overall average (black broken curve).
Cluster 1: Baja California, Coahuila, Colima, Mexico City, Guanajuato, Guerrero, Hidalgo, Jalisco, Mexico, Michoacán, Morelos, Nuevo Leon, Oaxaca, Puebla, San Luis Potosi, Sinaloa, and Tlaxcala
Cluster 2: Baja California Sur, Campeche, Chiapas, Nayarit, Quintana Roo, Sonora, Tabasco, Tamaulipas, Veracruz, and Yucatan
Cluster 3: Chihuahua
Cluster 4: Aguascalientes, Durango, Queretaro, and Zacatecas
Fig 11(right panel) shows the average shape of growth rate curves in each cluster and the overall average. Fig S19 shows mean growth rate curves and one standard-deviation bands around it, in each cluster. Since cluster 3 included only one state, average growth rate of cluster 1, cluster 2, and cluster 4 are shown. The average growth patterns in the three categories are very distinct and clearly visible. For cluster 1, the rate rises rapidly from April to July and then shows small fluctuations. For cluster 2, there is rapid increase in growth rate from April to July followed by a rapid decline. Chihuahua in cluster 3 shows a slow growth rate until September followed by a rapid rise until mid-September which then declines rapidly. For cluster 4, the rate rises slowly, from April to September, and then shows a rapid rise (Fig S20).
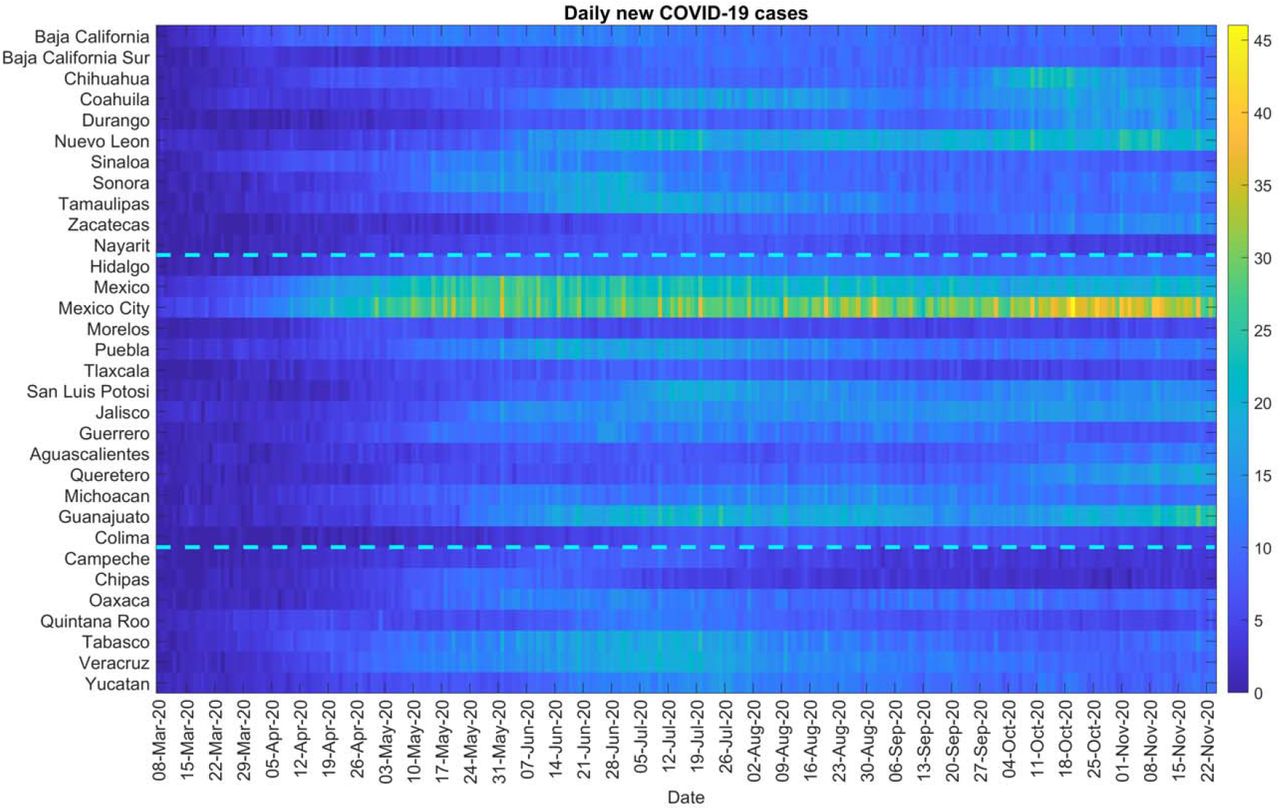
From the colormap (Fig 12) we can see that the cases were concentrated from the beginning in the central region in Mexico and Mexico City. Daily cases have been square root transformed to reduce variability in the amplitude of the time series while dashed lines separate the Northern, Central, and Southern regions. Fig S20 shows the timeseries graph of daily COVID-19 new cases by the date for all states, Northern states, Central states, and the Southern states. As observed for both Northern and Central regions including the national level, the epidemic peaked in mid-July followed by a decline at around mid-September, which then started rising again. Southern states exhibit a stable decline. Fig S21 shows the total number of COVID-19 cases at state level as of December 5, 2020.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Color scale image of daily COVID-19 cases by region.
Some of the areas with a higher concentration of COVID-19 cases are: Mexico City, Mexico state, Guanajuato in the central region and, Nuevo Leon in the Northern region.
Twitter data analysis
The epicurve for Mexico is overlaid with the curve of tweets indicating stay at home orders in Mexico as shown in S22 Fig. The engagement of people in Mexico with the #quedateencasa hashtag (stay-at-home order hashtag) has been gradually declining as the number of cases have continued to increase or remain at a steady pace, showing the frustration of public on the relaxation of lock downs. Mostly the non-government public health experts are calling for more lockdowns or social distancing measures but are not being heard by the authorities. It could also imply that the population is not following the government’s stay at home orders and hence we continue to observe the cases. S22 Fig shows that the highest number of tweets were made in the earlier part of the epidemic, with the number of tweets decreasing as of June 2020. In contrast, the number of cases by onset dates peaked around mid-June. The correlation coefficient between the epicurve of cases by dates of onset and the curve of tweets representing the stay-at-home orders was estimated at R=-0.001 from March 12-November 11, 2020.
Discussion
The results of our GLM model fit to the death data for all the thirteen calibration phases and GGM fit to the case incidence data indicate sub-exponential growth dynamics of COVID-19 epidemic in the Mexico and Mexico City with the parameter p estimated between (p∼0.6-0.8). Moreover, the early estimates of R indicate towards sustained disease transmission in the country with Rt estimated at 0.9 as of September 27, 2020. As the virus transmission continues in Mexico, the twitter analysis implies the relaxation of lockdowns, with not much decline in the mobility patterns observed over the last few weeks as evident from the Apple’s mobility trends. Moreover, the systematic comparison of our models across thirteen sequential forecasts deem sub-epidemic model as the most appropriate model for mortality forecasting. The sub-epidemic model is also able to reproduce the stabilization in the trajectory of mortality forecasts as observed by the most recent IHME forecasts.
The sub-exponential growth pattern of the COVID-19 epidemic in Mexico can be attributed to a myriad of factors including non-homogenous mixing, spatial structure, population mobility, behavior changes and interventions [83]. These results are also consistent with the sub-exponential growth patterns of COVID-19 outbreaks observed in Mexico [84] and Chile [85]. Along with the sub-exponential growth dynamics, the reproduction number estimated from the genomic sequence analysis and the case incidence data (Rt ∼ 1.1-1.2) indicate towards sustained transmission of SARS-CoV-2 in Mexico during the early transmission phase of the virus (February 27-May 29, 2020), with similar estimates of reproduction number retrieved from another study in Mexico [86] and Chile for the same time period [87]. These estimates of Rt are similar to those derived for other Latin American countries including Peru, Chile and Brazil that have observed similar outbreaks of COVID-19 in the surrounding regions [85, 88]. The early estimate of Rt obtained from the Cori et al. method also coincides with the early estimates of Rt obtained from the case incidence data and the genomic data (Rt ∼1). The instantaneous reproduction number estimated from our study shows that Rt is slightly above 1 since the end of March, without a significant increase. This is in accordance with the estimates of Rt obtained from another study conducted in Mexico [89].
In general, Mexico has seen a sustained SARS-CoV-2 transmission and an increase or a sustained steady number of cases despite the social distancing interventions including the stay-at-home orders that were declared on April 12, 2020 and eased around June 2020. As our twitter data analysis also shows, the number of cases by onset dates was negatively correlated to the stay-at-home orders, indicating population’s frustration towards the stay-at-home orders and reopening the country resulting in pandemic fatigue. Hence, people might have stopped following the government’s preventive orders to stay at home. Mexico has been one of the countries where the stay-at-home orders have been least respected, with an average reduction in mobility in Mexico reported to be ∼35.4% compared to 71% in Brazil, and 86% in Argentina and Colombia [90]. The intensity of these orders have affected the population disproportionately, with some proportion of the population showing aggression towards quarantine and stay-at-home orders [32]. We can also appreciate the variable spatial-temporal dynamics of the COVID-19 epidemic in Mexico. Our classification of epidemic pattern at the state level in Mexico shows distinct variation of growth rates across states. For instance, cluster 1 including Baja California, Colima and Mexico City has stable growth at a higher rate and cluster 4 including Aguascalientes, Durango, Queretaro, and Zacatecas shows a rising pattern in the growth rate (Figure 11). This information can be used by the states in guiding their decision regarding the public health measures. For example, states in cluster 1 and 4 may need strict public health measures to contain the epidemic.
We compared the performance of our three models for short-term real-time forecasting the COVID-19 death estimates in Mexico and Mexico City. As in Fig 2-5 the sub-epidemic model can be declared the most appropriate model as it exhibits the most desirable performance metrics across majority of the calibration and forecasting phases. This model has the capacity to accommodate more complex trajectories suggesting a longer epidemic wave and can better adjust to the early signs of changes in transmission of the disease, while other models (GLM and Richards) are less reactive. This model can also be utilized as a potential forecasting tool for other cities in Mexico and compared with other models. Moreover, shorter forecasts (5,10 days) could be also be conducted with the sub-epidemic model using the consecutive calibration phases to further reduce the error metrics [48].
Overall, the sequential forecasts based on the daily smoothed death estimates for Mexico from the two models (GLM, Richards) suggest a decline in over-all deaths (S1 Fig and S2 Fig) consistent with the sustained decline in COVID-19 associated case fatalities since mid-August as reported by the Mexican government officially [91]. However, this decline in COVID-19 deaths can be attributed to the inaccurate reporting of deaths in the surveillance system or downplay of fatalities by the government. For instance, the reported excess deaths as of September 26, 2020 are estimated to be 193170, with 139151 attributable to COVID-19 [92]. While the official tally of COVID-19 deaths in Mexico is only exceeded by USA and Brazil, its roughly approximated with that of India, a country whose population is ten times larger than Mexico [93]. As observed earlier, the easing of the social distancing interventions and lifting of lockdowns in Mexico in the month of June led to a surge of the COVID-19 associated deaths [94]. In June, the government of Mexico also inaccurately forecasted a potential decline in the number of COVID-19 deaths to occur in September [95]. Therefore, the forecasting trends need to be interpreted cautiously in order to inform policies. The IHME model also shows a decline in COVID-19 deaths in Mexico from mid-August-September, which have stabilized since then for the last six forecast periods (S5 Fig). The sub-epidemic model also indicates a stabilization of the deaths for the last seven forecast periods (S6 Fig) consistent with the results of the IHME model.
Similarly, for Mexico City, the sequential forecasts obtained from the GLM and Richards model fit to the daily death data estimates indicate a decline in the overall deaths (S3 Fig, S4 Fig). The IHME and sub-epidemic models on the other hand indicate a stabilized trajectory of deaths for the last three forecast periods (S7 Fig and S8 Fig) (suggesting that the actual death counts might not be decreasing in Mexico City) as seen with Mexico. Based on the death data, the observed decline or stability in death predictions could likely reflects the false slowing down of the epidemic in Mexico City [94]. Moreover, insufficient testing can also result in an inaccurate trajectory of the COVID-19 death curve [96].
The cumulative comparison of deaths in Mexico and Mexico City indicates that in general, the Richards model has under-performed in predicting the actual death counts with much wider uncertainty around the mean death estimates. The Richards model has also failed to capture the early sub-exponential dynamics of the death curve. The cumulative death counts obtained from the flexible sub-epidemic model closely approximate the cumulative death counts obtained from the three IHME modeling scenarios. Whereas the GLM slightly under predicts the cumulative death counts (Fig 6, Fig 7). On the other hand the COVID-19 predictions model projects 87,151 deaths (95% PI:84,414, 91,883) for Mexico as of October 27, 2020 (last forecasting phase), an estimate that closely approximates the estimates obtained from the GLM model (between 77,258-93,454 deaths) [97].
The three models (GLM, Richards, sub-epidemic model) used in this study generally provide good fits to the mortality curve, based on the residuals, with the Richards model unable to capture the early sub-exponential dynamics of the death curve. Moreover, these phenomenological models are particularly valuable for providing rapid predictions of the epidemic trajectory in complex scenarios that can be used for real-time preparedness since these models do not require specific disease transmission processes to account for the interventions. Since these models do not explicitly account for behavioral changes, the results should be interpreted with caution. Importantly, since the death curves employed in this study are reported according to the date of reporting, they are likely influenced by variation in the testing rates and related factors including the case fatality rates. Further, delays in reporting of deaths due to the magnitude of the epidemic could also influence our predictions. Moreover, using the reporting date is not ideal, due to the time difference between the death date and the reporting date of death, which at a given moment can give a false impression of the ongoing circumstances.
This paper is not exempt from limitations. First, the IHME (current projections, mandated mask, and worst-case scenario) model utilized has been revised multiple times over the course of the pandemic and differs substantially in methodology, assumptions, range of predictions and quantities estimated. Second, the IHME has been irregular in publishing the downloadable estimates online for some periods. Third, we model the death estimates by date of reporting rather than by the date of death. Lastly, the unpredictable social component of the epidemic on ground is also a limiting factor for the study as we do not know the ground truth death pattern when the forecasts are generated.
In conclusion, the reproduction number has been fluctuating around ∼1.0 from end of July-end of September 2020, indicating sustained virus transmission in the region, as the country has seen much lower mobility reduction and mixed reactions towards the stay-at-home orders. Moreover, the spatial analysis indicates that states like Mexico, Michoacán, Morelos, Nuevo Leon, Baja California need much strict public health measures to contain the epidemic. The GLM and sub-epidemic model applied to mortality data in Mexico provide reasonable estimates for short-term projections in near real-time. While the GLM and Richards models predict that the COVID-19 outbreak in Mexico and Mexico City may be on a sustained decline, the sub-epidemic model and IHME model predict a stabilization of daily deaths. However, our forecasts need to be interpreted with caution given the dynamic implementation and lifting of the social distancing measures.
Data Availability
Data for short term forecasts is available from the IHME downloadable estimates Data for mobility trends is available from the Apple mobility trends Genomic data is available from the GSAID repository Case incidence data is available from the Ministry of Health, Mexico
Author Contributions
Conceptualization, G.C. and A.T.; methodology, G.C, A.T.; validation, G.C.; formal analysis, A.T., G.C.; investigation, A.T. S.D., J.M.B., P.S.; resources, G.C., A.T. J.M.B., B.E. A.B, P.S; data curation, A.T.; writing—original draft preparation, A.T., G.C.; writing, review and editing, A.T., G.C., J.M.B., P.S., S.D., C.C.G, B.E., N.G.B., R.A.S, A.K, R.L, A.S, H.G., N.G.C., A.I.B., M.E.J; visualization, A.T., G.C.; supervision, G.C.; project administration, G.C.; funding acquisition, G.C. All authors have read and agreed to the published version of the manuscript.
Funding
G.C. is partially supported from NSF grants 1610429 and 1633381 and R01 GM 130900.
Conflicts of Interest
The authors declare no conflict of interest.
Acknowledgements
We thank the 2CI fellowship from Georgia State University.
References
- 1.↵
- 2.↵
- 3.↵
- 4.
- 5.↵
- 6.↵
- 7.↵
- 8.↵
- 9.↵
- 10.↵
- 11.↵
- 12.↵
- 13.↵
- 14.↵
- 15.↵
- 16.↵
- 17.
- 18.↵
- 19.↵
- 20.↵
- 21.↵
- 22.↵
- 23.↵
- 24.↵
- 25.↵
- 26.↵
- 27.↵
- 28.↵
- 29.↵
- 30.↵
- 31.↵
- 32.↵
- 33.↵
- 34.↵
- 35.↵
- 36.↵
- 37.↵
- 38.↵
- 39.↵
- 40.↵
- 41.↵
- 42.↵
- 43.↵
- 44.↵
- 45.↵
- 46.↵
- 47.↵
- 48.↵
- 49.↵
- 50.↵
- 51.↵
- 52.↵
- 53.↵
- 54.↵
- 55.↵
- 56.
- 57.↵
- 58.↵
- 59.↵
- 60.↵
- 61.↵
- 62.
- 63.↵
- 64.↵
- 65.↵
- 66.↵
- 67.
- 68.↵
- 69.↵
- 70.↵
- 71.↵
- 72.↵
- 73.↵
- 74.↵
- 75.↵
- 76.↵
- 77.↵
- 78.↵
- 79.↵
- 80.↵
- 81.↵
- 82.↵
- 83.↵
- 84.↵
- 85.↵
- 86.↵
- 87.↵
- 88.↵
- 89.↵
- 90.↵
- 91.↵
- 92.↵
- 93.↵
- 94.↵
- 95.↵
- 96.↵
- 97.↵



