
ABSTRACT
Objective To predict breast cancer (BC) and prostate gland cancer (PGC) risk among healthy individuals by analyzing routine laboratory measurements, vital signs and age.
Materials and Methods We analyzed electronic medical records of 20,317 healthy individuals who underwent routine checkups, encompassing more than 600 parameters per visit, and identified those who later developed cancer. We developed a novel ensemble method for risk prediction of multivariate time series data using a random forest model of survival trees for left truncated and right-censored data.
Results Using cross-validation, our method predicted future PGC and BC 6 months before diagnosis, achieving an area under the ROC curve of 0.62±0.05 and 0.6±0.03 respectively, better than standard random forest, Cox-regression model and a single survival tree. Our method can complement existing screening tests such as clinical breast examination and mammography for BC, and help in detection of subjects that were missed by these tests.
Discussion Computational analysis of results of routine checkups of healthy individuals can improve the detection of those at risk of cancer development.
Conclusion Our method may assist in early detection of breast and prostate gland cancer.
BACKGROUND AND SIGNIFICANCE
Early detection of cancer is crucial for providing appropriate care to the patient and can improve both prognosis and survival [1–5]. The current detection strategies use specific screening tests that require substantial resources, e.g., serum Prostate-Specific Antigen (PSA) level for Prostate Gland Cancer (PGC), mammography, an X-ray modality, for detecting early signs of Breast Cancer (BC), and clinical breast examination (CBE), a physical examination to recognize abnormalities in the breast [6]. Other approaches to assess cancer risk use models, e.g. Gail’s model [7,8], BRCAPRO [9], IBIS [10] and BOADICEA [11] for BC risk, and the Prostate Cancer Prevention Trial Risk Calculator (PCPTRC) for PGS risk [12]. Both models use a few clinical parameters and are not based on routine laboratory measurements, and their performance is relatively limited [13].
Machine learning algorithms can improve screening models in two major directions. One approach is utilizing advanced algorithms to improve the performance of the existing tests, for example, deep learning models for analyzing mammography [14–16], machine learning models for optimizing Gail’s model parameters [16], and improving the PGC risk score based on longitudinal PCPTRC results [17]. Another approach aims to develop new cancer risk prediction tools based on historical medical records of patients, collected as part of routine care in Electronic Medical Records (EMR). Such models were suggested for lung cancer [18], colorectal cancer [19], and Acute Myeloid Leukemia [20], among others. Moreover, advanced genetic methods are also employed for screening, mostly using polygenic risk scores [21]. Our objective is to develop new models for both BC and PGC based on EMR data collected from healthy individuals in routine periodic checkups, using techniques from machine learning and survival trees.
Survival trees were first introduced by Gordon and Olsen [22]. The basic concept is to create a decision tree where each node contains a survival curve of the corresponding subgroup of individuals. The node splitting criterion usually aims to maximize the difference in survival between the subgroups of the daughter nodes or the within-node homogeneity. Most survival tree methods addressed right-censored data and time-independent covariates. Incorporating time-varying covariates in survival trees was first introduced in [23] by introducing the ‘pseudo-object’ concept, which we describe later.
Several later methods of constructing survival trees for time-dependent covariates used this concept [24–27] or others [28–30]. Another common approach for analyzing time-dependent covariates is the Cox-regression model [31,32].
Several ensemble methods for survival trees analysis were suggested for time-independent covariates [33,34]. Random survival forests (RSF), introduced by Ishwaran [35] and combined the concepts of Breiman’s random forest [36,37], survival trees and the log-rank test as the splitting criterion. An extension of RSF is the utilization of conditional inference trees, which use hypothesis testing to select the splitting covariates and also as a stopping criterion [38], among other improvements that were examined [39,40].
We considered the problem of predicting survival probability over time. Our objective was to create a model based on subjects’ time-dependent covariates obtained in routine laboratory tests and to predict the fully personalized survival function for each subject based on the last available measurement values. We developed a novel method called TVsuRF (Time-Varying SUrvival Random Forest) for this goal. TVsuRF is the first ensemble method based of survival trees for time-dependent covariates that implements the ‘pseudo-object’ concept. Moreover, our method is the first to use the conditional inference trees in that setting.
Today, screening tests in the healthy population are used to identify individuals with cancer without symptoms, but these tests are costly, labor-intensive, and suffer from low accuracy. Our method aims to utilize existing clinical measurements of healthy individuals to predict the risk of BC and PGC, the most common cancers among females and males, respectively. To the best of our knowledge, this is the first risk score that is based on routine laboratory measurements proposed for these cancer types.
MATERIALS AND METHODS
Dataset
We analyzed data from routine checkups of individuals at the Tel-Aviv Medical Center Inflammation Survey (TAMCIS), Tel-Aviv Sourasky Medical Center, Israel. Participants were men and non-pregnant women with no active current malignant or infectious disease who chose to be tested and signed an informed consent form. In each visit, the subject underwent a comprehensive medical history evaluation, a complete physical examination, blood and urine tests, vital signs measurements, an electrocardiogram, an exercise stress test, and a respiratory function test. Data were summarized in structured EMR. Some individuals had multiple visits during several years. We conducted a retrospective analysis of the TAMICS EMR data collected between November 2001 and February 2017. Our study covered 20,271 adults (age ≥ 18). The study was reviewed and approved by the Institutional Review Board (Approval no. 02-049-Tlv).
Cancer Registry
TAMICS participants who later developed cancer were identified (using their national IDs) in the Israeli National Cancer Registry (INCR), which records all cancer cases in Israel. INCR contains for each case the cancer type (ICD9 code) and diagnosis date, and we used all cancer diagnoses until January 1st 2016. Supplementary Figure 1 shows the number of patients in the cohort with each cancer type. We focused on the two cancer types with the largest number of cases: BC for females and PGC for males. Patients who had a different type of cancer prior to diagnosis of BC or PGC were excluded.
Exclusion & Inclusion Criteria
Inclusion criteria
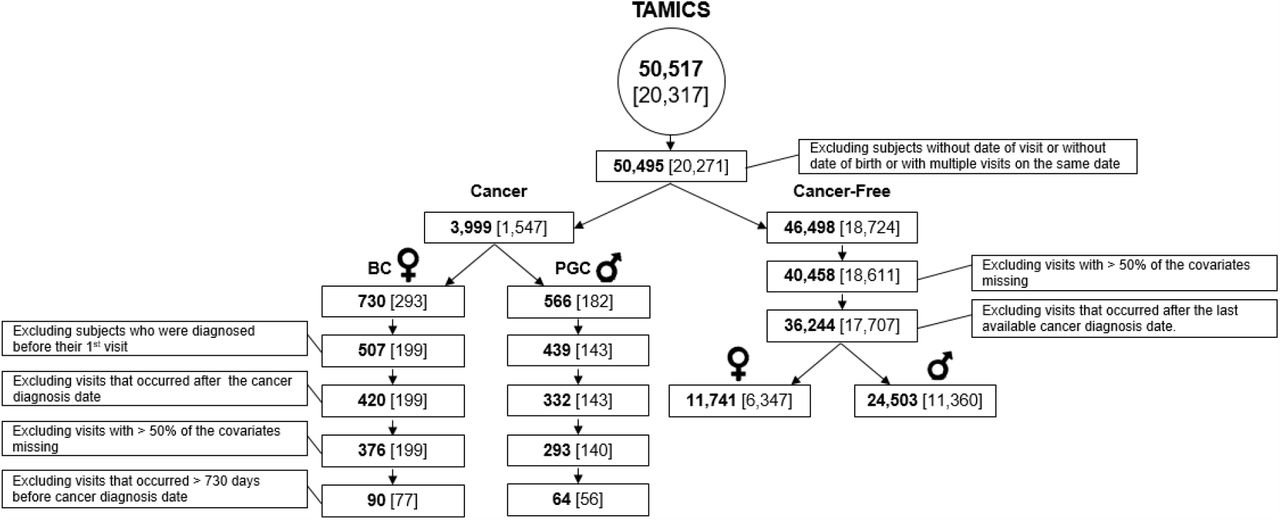
All individuals surveyed in TAMICS who had birth and visit dates documented were included (number of individuals np= 20,271, number of visits nv= 50,497). Of those, individuals with cancer diagnosis according to INCR were identified (np= 1,547, nv=3,999), along with their cancer type (see Figure 1).
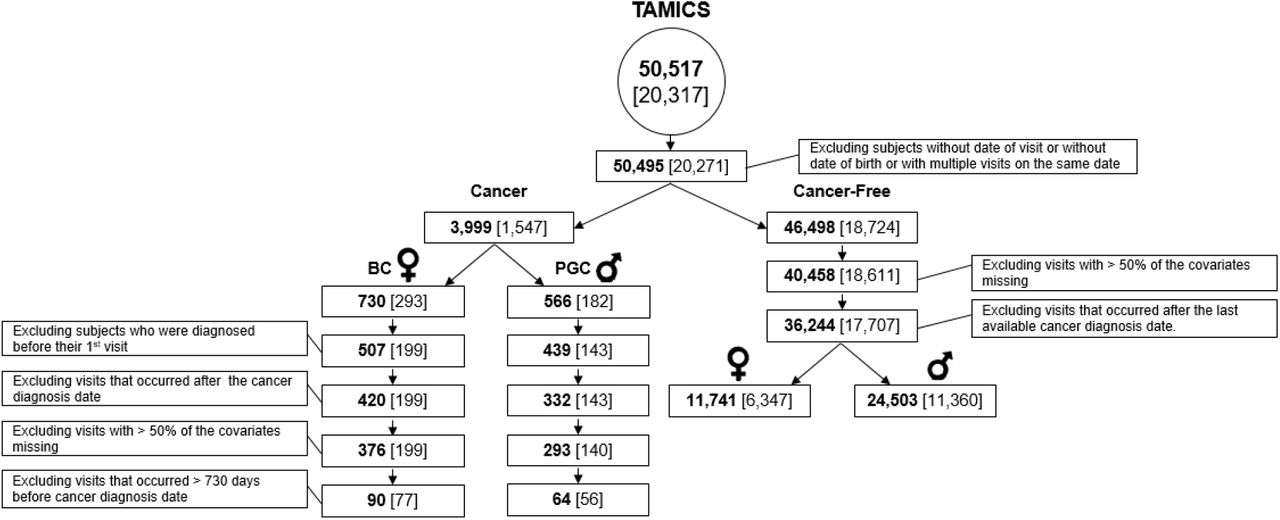
The bold number is the number of TAMICS visits; the number of individuals appears in parentheses.
Cases
Females whose cancer type was BC (np= 293, nv=730) or males whose cancer type was PGC (np= 182, nv=566).
Controls
Individuals who did not have any cancer diagnosis (np= 18,724, nv= 46,498).
Exclusion criteria
Our analysis was based on data from single visits, so exclusion was done per individual and visit.
Cases
Individuals whose cancer diagnosis date was before their first TAMICS visit (BC: np= 94, nv=223, PGC: np= 39, nv=127). Visits that occurred after the cancer diagnosis date (BC: nv=87, PGC: nv=107). Visits where more than 50% of the covariates were missing (BC: nv=44, PGC: nv=39). Visits that occurred > 730 days before the cancer diagnosis date (BC: np= 122, nv=286, PGC: np= 84, nv=229).
Controls
Visits where more than 50% of the covariates were missing (np= 113 individuals and nv=6,040 visits excluded). Visits that occurred after the last day of reports in INCR (np= 934, nv=4,214). We split the cancer-free group into male (np= 11,360, nv=24,503), and female (np= 6,347, nv=11,741) subgroups.
Data Extraction and Feature Choices
We used only features that were available for more than 80% of the individuals. The missing values were imputed using Predictive-Mean-Matching on age [41] using the mice package [42].
For BC risk prediction we used 20 covariates (Table 1) that include demographic parameters such as age and BMI, along with Complete Blood Count (CBC), since BC is a systemic disease that affects the immune system and its progression is expected to be reflected in the CBC results. For PGC risk prediction, we added 28 covariates that include the Basic Metabolic Panel (BMP), Lipids, Vital Signs, and more. (Table 2)
Values are mean ± SD. MW: p-value of the Mann–Whitney test, T-test: p-value of the Student t-test. All p-values were Bonferroni corrected for multiple hypotheses. Baso – basophils; EOS – eosinophils; Hmt – hematocrit, Hgb-hemoglobin; Lym – lymphocytes; MCH-mean corpuscular hemoglobin; MCHC-mean corpuscular hemoglobin concentration; MCV - mean corpuscular volume; Mono-monocytes; MPV-mean platelet volume; Neu – neutrophils; RBC – red blood cells; PLT – platelets; RDW - red cell distribution width; WBC – white blood Cells; BMI - body mass index
Values are mean ± SD. MW: p-value of the Mann–Whitney test, T-test: p-value of the Student t-test. P-values are Bonferroni corrected for multiple hypotheses. DBP – diastolic blood pressure; SBP – systolic blood pressure; Temp – body temperature; BUN - blood urea nitrogen ; GGT - gamma-glutamyl transferase; ALP - alkaline phosphatase; LDH – lactate dehydrogenase; Urine SG-urine specific gravity; Urine PH – PH stick for urine test.
Methods
Preliminaries
Consider a dataset of N subjects, where for each of them data from one or more visits were recorded. Subject i had Mi visits at times  . The d covariates measured at time
. The d covariates measured at time 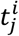 are denoted by the vector
are denoted by the vector 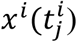 (For simplicity, we assume that all covariates were recorded in every visit). Note that covariates can be either time-dependent or time-independent (static). Hence,
(For simplicity, we assume that all covariates were recorded in every visit). Note that covariates can be either time-dependent or time-independent (static). Hence, 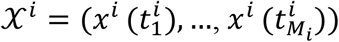 summarizes the longitudinal data of subject i The last time point subject i was at risk, which can be either failure or censoring time, is
summarizes the longitudinal data of subject i The last time point subject i was at risk, which can be either failure or censoring time, is 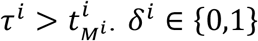 denotes if the subject experienced a censoring (δi = 0) or failure event (δi = 1) at time τi. Hence, the full data can be summarized by the set of triplets
denotes if the subject experienced a censoring (δi = 0) or failure event (δi = 1) at time τi. Hence, the full data can be summarized by the set of triplets 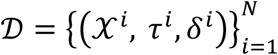 (Supplementary Figure 2A). xi(t) denotes the data of subject i that were measured until time t, i.e.,
(Supplementary Figure 2A). xi(t) denotes the data of subject i that were measured until time t, i.e., 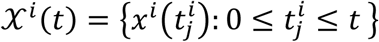 . We assume time homogeneity so that w.l.o.g. we can shift times per subject to set
. We assume time homogeneity so that w.l.o.g. we can shift times per subject to set 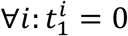 , i.e., all first visits were at time 0 (Supplementary Figure 2B). We also assume that the age of the subject at each visit is one of the covariates.
, i.e., all first visits were at time 0 (Supplementary Figure 2B). We also assume that the age of the subject at each visit is one of the covariates.
Our model aims to estimate the probability for being free of the failure event (the cancer diagnosis) at least until time t based on the patient’s covariates at the latest visit before that time. That is, let  . We wish to estimate the survival function:
. We wish to estimate the survival function:
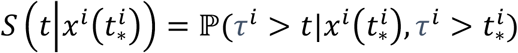
In order to model the time-dependent covariates, we transform the data following [23]. We split the data of each subject into disjoint intervals 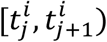 and we assume that the covariates xi(tj) are constant in the interval (Supplementary Figure 2C). In that manner, we consider tj as the left-truncation time. If
and we assume that the covariates xi(tj) are constant in the interval (Supplementary Figure 2C). In that manner, we consider tj as the left-truncation time. If 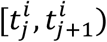 is not the last interval of subject i then we view time
is not the last interval of subject i then we view time 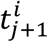 as censoring time. We denote the pseudo-object of the jth interval of subject i as
as censoring time. We denote the pseudo-object of the jth interval of subject i as  where:
where:
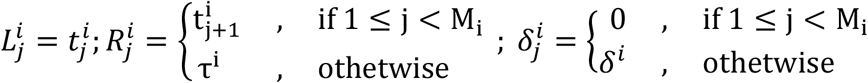
Hence, the transformation is:

Each pseudo-interval is therefore possibly left-truncated and/or censored. The standard Kaplan-Meier (KM) estimator of the survival function can now be generalized for left truncation right-censored (LTRC) data [43], as follows. Assume that there were D failure events and they occurred at distinct times t1 < ⋯ < tD. We denote by Yj the number of pseudo-objects at risk at time 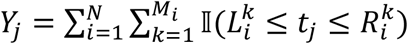 i.e., the number of individuals who entered the study before time tj and did not experience a failure or censoring event until tj. dj is defined as the number of patients that experienced a failure event at time tj and due to our prior assumption dj = 1. The KM estimator is defined as a step function with jumps at observed failure times:
i.e., the number of individuals who entered the study before time tj and did not experience a failure or censoring event until tj. dj is defined as the number of patients that experienced a failure event at time tj and due to our prior assumption dj = 1. The KM estimator is defined as a step function with jumps at observed failure times:
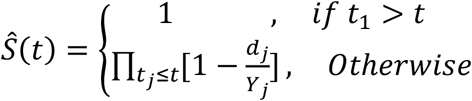
The survival probability will be calculated in a step ahead prediction manner - we calculate the probability of a patient in time t to experience failure in the next time window Δt given its covariates at time t, namely ℙ (τi < t + Δt, δi = 1|τi > t, xi(t)).
Survival tree construction
We now describe the construction of the survival tree for pseudo-objects data. For simplicity, we will just call them objects. (Figure 2A). Suppose we have the set of samples along with their covariates as described above, and we wish to use the survival information to build a decision tree. We use the framework of conditional inference trees [38], a class of decision trees that employs a statistical hypothesis test based on permutations in order to select optimal variables and their thresholds. This process is different from common decision tree construction (see Supplementary Material 3), which usually selects the variable that maximizes an information measure (e.g. Gini or entropy).

An illustration of the different parts of our model construction. [A] For each subject we transformed its data into pseudo objects and change the time axis to time from first visit. [B] An illustration of single survival tree construction [C] Generating 500 survival trees. [D] The trees are combined into a single unified model. Risk score calculation per each sample is based on averaged survival curve.
A covariate and a threshold value at a node split the node’s samples into two subsets, and each subset induces a survival curve. To compare the survival curves of the two subsets we use Pan’s permutations based hypothesis test [44], as suggested also in [27]. In every node, we test all possible covariates and thresholds, and the one that produces the split with the lowest p-value is selected. Notice that pseudo-objects created from the same subject can end in distinct sub-nodes.
The hypothesis test is based on creating an influence function that maps an object’s quadruplet (Li, Ri, δi, xi) into a scalar Ui which represents the contribution of sample i to the test statistic. We assume that (li, ri) is the interval in which the true event lies, and denote its contribution to the statistic:
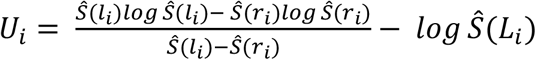
One can show that for failure event at time t (δi = 1)
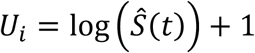 and for a right-censored observation at time t (δi = 0), assuming Ŝ(∞) = 0
and for a right-censored observation at time t (δi = 0), assuming Ŝ(∞) = 0
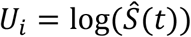
Now let U1, …, UN be the scores of the samples corresponding to the parent node, and suppose n samples reside in the left child and N − n in the right. Write X = ∑left Uj. There are  ways of choosing n out of the N scores and if k of these have a sum ≤ X, then assuming all partitions are equi-probable, the probability of obtaining a score of X is
ways of choosing n out of the N scores and if k of these have a sum ≤ X, then assuming all partitions are equi-probable, the probability of obtaining a score of X is  . We estimate it using 1000 permutations.
. We estimate it using 1000 permutations.
The survival function Ŝl(t) for node l is the Kaplan-Meier curve for the samples corresponding to that node. Let Cl be the set on indices of samples in node l, then:
 where dl(ti) is the number of failure events that occurred at time ti in node l and Yl(ti) is the total number of objects at risk just before ti in node l. (Figure 2B, Figure 3)
where dl(ti) is the number of failure events that occurred at time ti in node l and Yl(ti) is the total number of objects at risk just before ti in node l. (Figure 2B, Figure 3)

Algorithm 1: BuildTree Algorithm; Algorithm 2: TVsuRF Algorithm.
Ensemble model
We create M = 500 survival trees. In each tree, at each internal node, we select at random 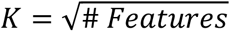 of the features and split the node according to the feature and threshold giving the least p-value for difference in survival, if that difference is significant (Figure 3). The predicted survival curve for a new subject ω is based on the data in all the leaves that ω ended in all the trees. Let
of the features and split the node according to the feature and threshold giving the least p-value for difference in survival, if that difference is significant (Figure 3). The predicted survival curve for a new subject ω is based on the data in all the leaves that ω ended in all the trees. Let  represent the set of indices of the subjects that are in the ith leaf of the kth tree and let
represent the set of indices of the subjects that are in the ith leaf of the kth tree and let  be the multiset of all the subjects in these leaves. If di(ti) is the number of failure events in CF at time ti and Yi(ti) is the number of objects in CF in risk at time ti, then the survival function of ω is (Figure 2C):
be the multiset of all the subjects in these leaves. If di(ti) is the number of failure events in CF at time ti and Yi(ti) is the number of objects in CF in risk at time ti, then the survival function of ω is (Figure 2C):
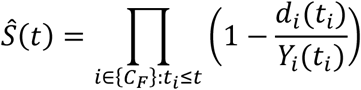
Our model constructs a Kaplan-Meier curve per each subject, producing a continuous risk score (RS) over time.
Variable importance
We assessed the importance of each covariate in our model in two ways. In the first, we counted the fraction of internal nodes in all the trees that were associated with the covariate (i.e. the covariate was used to split these nodes). We call this fraction Vprop; higher Vprop indicates more importance. In the second approach, for each object, we replaced the values of the covariate by random values sampled independently from its original distribution, while keeping the other covariates in their true values, and recomputed the performance with the new data. The difference in the AUROC between the original and the modified data was computed and averaged over ten random assignments per each covariate on every fold of the 4-fold cross-validation [35]. We repeated this process 20 times and defined VIMP as the mean difference obtained. Again, higher VIMP indicates more importance.
Comparison to BC screening tests
For a subset of the TAMICS females, we had data concerning BC screening. Mammography was available for 6,526 woman and Clinical Breast Exam (CBE) was available for 17,958. We excluded women with mutated BRCA genes, those who refused to conduct a CBE, lacked ID, had more than one record per visit or were diagnosed with another type of cancer (see Supplementary Figure 4 for study design).
The result of the mammography was provided in free text written by the physician and transformed by us into binary labels (normal / abnormal) by natural language processing of the physician’s notes (see Supplementary Material 5 for details). The CBE result was available as free text written by a physician and four binary values that represent an abnormal finding in the left/right breast or axilla. We considered the CBE result abnormal if one of the binary values was positive. In case that no values were reported, a breast cancer surgeon reviewed the physician’s text and decided if there was a positive finding.
We compared the recommendations that were done by these screening tests for BC to our predictions, in order to evaluate the added value of our approach. We binned the risk scores into deciles and the average risk score was calculated for each subject.
Evaluation Approach
We used TVsuRF and several other models to predict BC and PGC risk on our cohorts. If a subject’s covariates were measured at time t, we aimed to predict cancer at time t + Δt, for values of Δt ranging between 183 and 730 days. Since there might be a delay between the cancer diagnosis time and the time it was reported to the cancer registry, we added ϵ =31 days to Δt. The risk for patient i is thus:
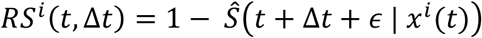
To evaluate the performance of this score for classification, we calculated the area under the receiver operator characteristic curve (AUROC), where the positive class is the set of individuals that were diagnosed with cancer during the next Δt + ϵ days as suggested in
[45] (but excluding patients censored in [t, t + Δt + ϵ]). We also estimated the area under the precision-recall (AUPR) curve.
We performed 20 iterations of 4-fold cross-validation, where in each iteration the partition of patients into folds was done at random. For each of the above measures, we calculated the average and standard deviation.
We compared our method to three others: (1) Cox regression model adapted to time-varying covariates [31,32], (2) single LTRC survival tree as in [27](denoted LTRCIT), and (3) RF model [36]. Since RF is a classification model, training for prediction was done separately for each time interval Δt, and the class of a subject was positive if the diagnosis of cancer occurred during the next Δt + ϵ days, and negative otherwise. We used 500 trees, and the ‘Gini’ index as a splitting rule, with the rest of the parameters at the default values in the ranger package [46] (Figure 2D).
In addition, we compared our method to a random survival forest (RSF) model that predicts a survival curve per sample. Since RSF was originally designed for handling time-independent covariates, we adapted it to our setting.
RESULTS
Breast Cancer
Dataset
Our cohort contained data on 6,424 women with a total of 11,831 visits to TAMICS. Out of those, 77 were diagnosed with breast cancer and had one or more visits less than 730 days before the diagnosis date (90 visits in total). These constituted the positive (BC) group. The covariates that were included in the model were CBC (18 parameters), age and BMI. The statistics of these values are summarized in Table 1.
Women in the positive group were significantly older on average than in the BC-free group and had significantly lower levels of mean corpuscular hemoglobin concertation (MCHC). To reduce the effect of age on our model, we created an age-matched cohort (‘Matched BC-Free’) using the approach of [47] (3,635 subjects, 5,884 visits). When comparing the BC and the Matched BC-free group (Table 1) none of the parameters was significantly different between the groups.
Prediction accuracy
The performance of each of the methods tested, for different time ranges, is summarized in Figures 4A and 4B. We also marked the AUROC of Gail’s breast cancer risk estimation for 5 years horizon as reported in [13]. TVsuRF had the highest AUPR on every time interval, and the highest AUROC on all intervals except one (though differences were not statistically significant) for 730 days, where Gail’s score was best. We also tested two versions of RSF and our model was better for time windows until 273 days in terms of AUPR and AUROC. (Supplementary Figure 6).

[A] Performance (AUROC mean±SD) of five prediction models for different time intervals. The grey dashed line represents the (time-independent) AUROC reported for Gail’s Risk factor model [13]. [B] AUPR. The numbers below the x-axis labels are the average number of BC patients that were available across the cross-validation folds for each time interval. [C] Variable importance for model prediction in a 183-day window. Points indicate the different variables. The y-axis presents VIMP, the decrease in AUROC following random assignment of values to the variable. The x-axis plots Vprop, the variable’s inclusion frequency in the trees of the model. For both measures higher values indicate more importance. The color of a point represents the category of the parameter. Features of low importance (Vprop <0.05 and VIMP<0.5) are not shown.
Variable importance
Figure 4C summarizes the importance of variables in TVsuRF BC risk prediction model for a time window of 183 days. The variables mean corpuscular volume (MCV), monocytes (MONO), mean platelet volume (MPV), mean corpuscular hemoglobin concentration (MCHC) and age were most important in the TVsuRF model. The importance of immune system-related covariates such as MONO might correlate to the fact BC is an inflammatory and systemic disease.
Comparison to mammography and CBE
For every woman who underwent mammography or CBE in her checkup visits, we compared the results of the 730-day predictor, computed using data only from her latest visit. CBE had 29.1% sensitivity and 93.7% specificity, while TVsuRF had 12.5% sensitivity for the same specificity. Mammography sensitivity and specificity were 58.3% and 66.1%, and TVsuRF had 41.7% sensitivity for similar specificity. (Note that the results are not directly comparable, as mammography and CBE identify current malignancy and TVsuRF computes future disease risk.) The results in Supplementary Figure 7 show the three predictions for women that were subsequently diagnosed with BC. Remarkably, the three women with the highest risk score estimated by our model were not detected by CBE, and one of them tested negative in mammography as well. In contrast, some of the women had lower risk scores but were detected by other screening tests.
Prostate Gland Cancer
Dataset
This cohort consisted of 11,416 males who made a total of 24,567 visits to TAMICS. Out of them 56 were subsequently diagnosed with PGC and had 64 visits less than 730 days before the PGC diagnosis. We call this group the PGC subset. The covariates included in the model were CBC (20 parameters), basic metabolic panel data (BMP, 16 parameters), lipids (4 parameters), vital signs (5 parameters), urine tests (2 parameters), troponin, age and BMI. The characteristics of the covariates are summarized in Table 2. Since PGC individuals were significantly older than the PGC-free individuals, to reduce the effect of age on our model, we created an age-matched cohort (‘Matched PGC-Free’) of 3,320 subjects (6,083 visits) using the approach of [47] (Table 2). None of the covariates showed significant difference between the PGC and the Matched PGC-Free groups.
Prediction accuracy
Figures 5A and 5B show the results of five prediction methods, using the same comparison metrics as in the BC section. Our model had the highest AUROC in prediction window of 0-183 days and similar performance for intermediate size time windows. For windows of 547 days and longer, RF had the highest AUROC. In terms of AUPR, our model performed best in until 547 days and the advantage was significant in the windows of up to 273 days. When testing variants of RSF, TVsuRF had better performance on the prediction windows of 0-183 days, but less for longer time windows. (Supplementary Figure 8).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
[A] Performance (AUROC mean±SD) of five prediction models for different time windows. The grey dashed line represents the (time-independent) AUROC previously reported for the PCPTRC model. [B] AUPR. The numbers below the x-axis labels are the average number of individuals with PGC that were available across the cross-validation folds for each time interval. [C] Variable importance for model prediction in a 183 day window. Points indicate the different variables. Axis definitions are as in Figure 6. The color of a point represents the variable’s category. Features of low importance (Vprop <0.025 and VIMP<1.5) are not shown.
Variable importance
Figure 5C summarizes the importance of the variables used by TVsuRF in PGC risk prediction, for the 183-day window. The covariates alkaline phosphatase (ALP), low-density lipoprotein (LDL), age, calcium, and glucose had the largest impact on the model. Most of the lipids that were measured - LDL, high-density lipoprotein (HDL), cholesterol and triglycerides - had high importance risk according to at least one criterion, in agreement with previous reports [48].
DISSCUSSION
In this article, we introduced a method for survival prediction based on time-varying covariates utilizing an ensemble of survival trees, and applied it for predicting future emergence of breast and prostate cancer. Our method outperformed traditional prediction methods in breast cancer and for short term prediction also in prostate cancer. While traditional survival analysis methods use prior assumptions concerning the distribution of the data [49], our method relies only on the proportional-hazard assumption.
Our work has several limitations. First, we do not directly address the issue of size imbalance between the negative (here, the majority) and positive classes. That could affect the splitting criteria and produce nodes with a small number of samples or nodes without failure events, especially in datasets with high-dimensional feature space. Methods such as synthetic minority sampling might address this point [50]. Second, since our dataset did not record the existing clinical models for cancer risk (Gail’s model for BC, and PCRTRC model for PGC), we could not compare performance to them on individual patients in our cohort. Incorporating them as additional features in our models may improve prediction. Third, the small number of visits per patient did not allow us to incorporate into the model time-related features, as suggested, e.g., in [19,51] engineered features that capture interactions [52], or to model per-patient random effects across pseudo-intervals. Other model extensions such as competing risks (e.g. death) and accounting for cardiovascular background were not possible for lack of data. Moreover, the limited cohort size made it difficult to evaluate the calibration of our model.
Future work should examine different imputation methods, as those might affect the performance of classifiers when modeling EMR data [53], and investigate sequential models that incorporate the full history in predicting the personalized survival curve [54]. In addition, ‘out-of-bag’ approaches may improve the evaluation of the prediction, as previously suggested [55]. Moreover, the robustness of the approach is yet to be demonstrated on EMR data from other medical centers. Predictions for additional types of cancers should also be tested, given sufficient data. Finally, a prospective clinical study would provide a more accurate evaluation of the performance.
CONCLUSIONS
Our models demonstrate the potential of using common laboratory tests of healthy individuals to assess cancer risk. They can serve as additional screening tests and complement the existing BC screening methods.
Data Availability
Data cannot be shared for ethical/privacy reasons.
COMPETING INTERESTS
None.
FUNDING
Supported in part by Israel Science Foundation (ISF) grant No. 1339/18 (RS); ISF grant No. 3165/19, within the Israel Precision Medicine Partnership program (RS); grant 2016694 from the US - Israel Binational Science Foundation (BSF), and the US National Science Foundation (NSF) (RS); ELROV grant (S.S.T). D.C. was supported, in part, by fellowships from the Edmond J. Safra Center for Bioinformatics at Tel Aviv University and from Google.
DATA AVAILABILITY
Data cannot be shared for ethical/privacy reasons.
ACKNOWLEDGEMENT
None.
REFRENCES
- [1].↵
- [2].
- [3].
- [4].
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].
- [26].
- [27].↵
- [28].↵
- [29].
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵



