
Abstract
Reverse transcription-polymerase chain reaction (RT-PCR) assays are used to test patients and key workers for infection with the causative SARS-CoV-2 virus. RT-PCR tests are highly specific and the probability of false positives is low, but false negatives can occur if the sample contains insufficient quantities of the virus to be successfully amplified and detected. The amount of virus in a swab is likely to vary between patients, sample location (nasal, throat or sputum) and through time as infection progresses. Here, we analyse publicly available data from patients who received multiple RT-PCR tests and were identified as SARS-CoV-2 positive at least once. We identify that the probability of a positive test decreases with time after symptom onset, with throat samples less likely to yield a positive result relative to nasal samples. Empirically derived distributions of the time between symptom onset and hospitalisation allowed us to comment on the likely false negative rates in cohorts of patients who present for testing at different clinical stages. We further estimate the expected numbers of false negative tests in a group of tested individuals and show how this is affected by the timing of the tests. Finally, we assessed the robustness of these estimates of false negative rates to the probability of false positive tests. This work has implications both for the identification of infected patients and for the discharge of convalescing patients who are potentially still infectious.
Introduction
Currently, most SARS-CoV-2 infected individuals are identified by the successful amplification of virus from throat and/or nasal swabs in the reverse-transcriptase–polymerase-chain-reaction (RT-PCR) assay. These tests are highly specific but there are many reasons why sensitivity is imperfect [1]. Indeed, multiple studies have observed negative RT-PCR results on at least 1 occasion for SARS-CoV-2 infected individuals [1–6]. Such false-negative results have implications for correct diagnosis [7] and subsequent community transmission [8], and thus for control initiatives.
A series of previous studies have described cohorts of tested individuals. Ai et al.[2], for instance, retrospectively considered 1014 infected patients of whom 413 (41%) tested negative by RT-PCR at initial presentation. Xie et al. [1] similarly considered 167 infected patients of whom 5 (3%) tested negative by RT-PCR at initial presentation. Fang et al. [3] found that RT-PCR was only able to identify 36/51 (71%) of SARS-CoV-2 infected patients when using swabs taken 0-6 days after the onset of symptoms, and Luo et al. [9] similarly reported that the initial sensitivity of throat swabs in secondary contacts was 71%. Meanwhile in a study of 213 patients, Yang et al. [4] found lower positive test rates from throat swabs (24%) compared to nasal swabs (57%).
Although these particular studies relate to longitudinal studies of infected patients, the data is not disaggregated per patient. Some authors have however presented sequential test data from individual patients [5,6,10]. Here we use the latter type of data to characterise how the probability of a false-negative test result depends on the number of days between the onset of symptoms and the performance of the test and how this is affected by the site from which swabs are taken. We couple this with data on the observed distribution of days from onset of symptoms to confirmation of infection by RT-PCR [11] and use Bayes Theorem to estimate the number of false-negatives in different cohorts of tested individuals, under the assumption that they are only tested once; and assess the sensitivity of these results to the specificity of the test. Our results have implications for both existing estimates of SARS-CoV-2 prevalence and the likelihood of specific individuals having been infected with the virus or not, where these rely solely on RT-PCR tests.
Methods
Estimating RT-PCR sensitivity
We aimed to determine the false negative rate of RT-PCR tests on SARS-CoV-2 infected patients. Three studies [5,6,10] reported extractable results for longitudinal RT-PCR tests from hospital patients who tested positive for COVID-19 at least once. This provided data on 426 tests across 39 patients in 3 study cohorts. However, only two studies [5,10] reported the swab location (nasal or throat) for each individual test; we therefore restricted our analysis to these data, yielding 298 tests across 30 patients (150 nasal and 148 throat swabs). Data were analysed using binomially-distributed (logit-link) generalised additive mixed models (GAMM) with the package mgcv in the statistical software R [12]. We tested hypotheses that the probability of a positive result will change through time after symptom onset, that different swab locations may have different detection probabilities and that each study may have a different baseline detection probability (due to, for example, differing testing procedures). The effect of the number of days since symptom onset was modelled as a continuous smooth function (cubic regression splines), while swab location and data source were included as two-level categorical variables. Random effects were included in the form of patient-specific smooth functions, modelling between-patient differences in the probability of returning a positive test through time. All of the models we examine included this random effect, as patient samples were pseudo-replicated by design. Models were compared in a stepwise down procedure from the most complex structure using Akaike Information Criterion (AIC). The difference in AIC values (ΔAIC) values were calculated in relation to the lowest AIC value.
Results
Our most complex model included a smooth effect of day as well as swab type and study specific intercepts, along with the random effect of the patient. The model without swab location was not supported (AIC 323.43, ΔAIC = 7.82), nor the model excluding the effect of days since symptom onset (397.48, ΔAIC = 68.24). However, the model without a study-specific effect was supported (AIC = 316.29, ΔAIC = 0.68), suggesting that the baseline probability of detection was consistent between each study cohort. The final model structure with the most support contained the fixed effect of swab location, the effect of time since symptom onset and the random effect of patient (AIC = 315.61). The full model output is given in the supplementary information.
Swabs taken from the throat immediately upon symptom onset were predicted to be 6.39% less likely to yield a positive result than a nasal swab (logit-scale effect size -0.83 CI [-1.39, -0.27]). The probability of a positive test decreases with the number of days past symptom onset; for a nasal swab, the percentage chance of a positive test declines from 94.39% [86.88, 97.73] on day 0 to 67.15% [53.05, 78.85] by day 10. By day 31, there is only a 2.38% [0.60, 9.13] chance of a positive result (numbers for throat swabs: 88% [75.18, 94.62], 47.11% [32.91, 61.64] and 1.05% [0.24, 4.44] for day 0, 10 and 31 respectively). The model fit is shown in Figure 1.

Model fit of a binomially-distributed GAMM to longitudinal RT-PCR test data. Tick marks denote positive (top) and negative (bottom) tests (jittered on the x-axis for visual purposes). The black line shows the model fit and blue ribbons the 95% confidence intervals on the fixed effects. The left-hand panel gives results for nasal swabs and the right throat swabs.
Visualising the impact of time to test on false-negative test probabilities
As shown above, the probability of a false-negative test result depends on the number of days since symptom onset. This means that simple reports of positive and negative test counts among individuals who are only tested once will underestimate the true number of positive tests in that group. We can illustrate the potential impact this has on average false-negative test rates by supposing that the time from onset of symptoms to testing follows a gamma-distribution.
Figure 2 explores how varying the shape and rate of this distribution affects the average false-negative rate among this group, and highlights that in scenarios where infected individuals are typically tested late we anticipate the false-negative rate to be 4 times larger than when patients are typically tested early. We also show how the probability of incorrectly identifying an individual as uninfected due to a false-negative test considerably reduces if all negative tests are repeated 24 hours later. Note that the realised error rate (the actual proportion of false negative tests) will be proportional to the underlying prevalence of infection; only if everyone in the group is infected would the probability of a false negative equal the proportion of negative tests (as there will be no true negatives from uninfected individuals).

Surfaces showing the aggregate probability of false negative tests (denoted by colour) in Gamma-distributed cohorts of people being tested for COVID-19. The x-axis shows the mode of the Gamma distribution and the y-axis the standard deviation. The left-hand panel shows the error rate for one test, while the second panel shows the error rate for two tests taken 24 hours apart. Illustrative distributions are drawn in the corresponding corners of the first panel (these are the same in the second panel). Each point on the surface is a result of a unique parameterisation of the distribution, with sub-plots A-D showing illustrative examples at the 4 extremes. A gives a scenario where most patients are tested early but with a “long-tail” of patients taking a long time to be tested. B shows a scenario where patients are mainly tested later, with a similarly long tail. Scenarios C and D represent scenarios where patients are consistently tested early or late (with very thin tails).
Estimating the number of false-negatives in a cohort of tested individuals
We further demonstrate how the results of Figure 2 might affect testing outcomes in practice. Results from Bi et al. [11] suggests that the probability of an infected individual getting a positive RT-PCR test of SARS-CoV-2 after a given number of days since the onset of symptoms follows a gamma distribution with shape 2.12 and rate 0.39 (see Figure 3 and Table S2 in [11]). We can use this together with our results and apply Bayes Theorem to recover the distribution of the time from onset of symptoms to getting tested (see Supplementary Methods), which ends up as a distribution with a heavier tail because the false-negative test probability increases with time.

Comparison of the discretised distribution of time to confirmation among symptomatic individuals from [9] and the distribution of time to test that we estimate, combining this with our estimate of the false-negative test probability from nasal swabs, assuming false-positive tests are impossible (see Supplementary Methods).
If we assume further that this distribution is generally representative and does not vary over the course of the epidemic, then we can use it to estimate how many infected individuals are incorrectly identified as uninfected among a group of symptomatic tested individuals who are only tested once. We can further explore how the false-positive rate affects these estimates and illustrate this using the numbers of tests performed and positive test results from the UK and South Korea as of 20th March 2020 (UK: 5.1% positive [3277 / 64621 positive tests]; SK: 2.7% [8652 / 316664 positive tests] [13]). It is important to stress that this exercise is illustrative rather than assertive: we are trying to show how accounting for the false-negative and false-positive test probabilities affects the estimate of the number of infected individuals among those one has tested, and are making some pretty broad assumptions to do this (e.g. all individuals only tested once; that the distribution to test is as we have estimated; that all those tested are symptomatic) any or all of which is likely to be violated in these datasets. Therefore, we are not making country-specific predictions but are rather presenting a sensitivity of scale for the overall impact of accounting for the false-negative and false-positive test probabilities.
Keeping this in mind, Figure 4 shows that when the false-positive test probability is very small then the estimated number of infections among those tested is increased by around 30%, but this estimate decreases linearly as the false-positive test probability increases. In fact, for some critical (yet small) value for the false-positive test probability, the estimated number of infections becomes smaller than the number of positive tests: we end up with more false-positives than false-negatives. Moreover, the false positive test probability has a bigger impact on the ‘South Korean’ data because a smaller percentage of the original tests were positive (this follows directly from the underlying derivations - see Supplementary Methods).

(A) Impact of the false-positive and false-negative test probability on the estimated total number of infected individuals among those tested in South Korea (red) and the UK (blue); dashed line corresponds to number of positive tests conducted as of 20th March 2020. (B) Similar, but now showing the percentage change from the number of positive tests to the estimated number of cases. Note that in both cases the x-axis refers to a percentage i.e. 1 = 1%, not 100%.
Overall this illustrates 3 important things: that for a zero or very small false-positive test probability, the true number of infected individuals among those tested will be substantially larger than the number of positive tests; that increasing false-positive test probabilities start decrease these estimates until they eventually go negative (even for quite small values of the false-positive test probability); and that such decreases are more severe in situations where the apparent prevalence among those tested is lower.
Discussion
On its own, testing throat and nasal swabs by RT-PCR is not guaranteed to yield a positive result for SARS-CoV-2 infection and this probability decreases with time since the onset of symptoms. In other words, the longer the time from the onset of symptoms until a suspected case is tested, the more likely a false-negative result. Repeat testing of suspected but RT-PCR negative infections drastically decreases the chances of failing to identify infected individuals by this method, but may not always be feasible.
Meanwhile, failing to account for the possibility of false-negative tests potentially biases upwards many of the existing estimates for case and infection fatality risks of SARS-CoV-2 e.g. where they rely on perfect sensitivity among international travellers [14,15].
On the other hand, we also show how even small false-positive test probabilities can have an opposite impact on any assessment of the “true” number of infections in a tested cohort and hence bias case and infection fatality risk estimates in the opposite direction. Better understanding of the false-positive test probability and accounting for precisely when and how individuals have been tested would therefore improve the quality of any estimates that rely on the number of positive tests in a cohort of tested individuals.
Our results have important implications for SARS-CoV-2 testing strategies. Presently, RT-PCR testing regimes vary significantly between countries, determined both by policy decisions and testing capacity. Some opt (or, rather, are able to) test large portions of the population, including those who are asymptomatic or self-isolating with mild symptoms. In countries such as South Korea, where testing has been thorough, the distribution of test timing will be crucial; if many of those tested were infected some time ago but only had mild or asymptomatic infections (and therefore did not present for treatment), they will be more likely to return a false negative result. In countries that do not currently have mass testing, there are calls for testing to be expanded to the population at large with the aim of determining how many people have, or have recently had, infection. While RT-PCR testing of key workers will be of great importance (particularly those working with vulnerable groups), our results suggest that there may be some benefit to testing indiscriminately; conducting a single test on someone who had symptoms 10 days ago will have a nearly 33% false negative rate (using a nasal swab; 52.89% for a throat swab). As a means of determining population level exposure to SARS-CoV-2, serological tests are far more likely to provide an accurate profile.
In almost all countries, tests will be conducted on patients presenting with symptoms at a hospital in order to streamline treatment and prevent further infection. We do not suggest that the problem of false negatives is under appreciated by medical professionals; it is presently recognised by both the guidelines from the World Health Organisation (WHO) [16] and the European Centre for Disease Control (ECDC)[17] that a single negative test is insufficient to rule out infection, with discharge criteria stating that a patient should only be released if two repeat tests return negative results. Early in the outbreak, doctors used CT to look for evidence of SARS-CoV-2 in symptomatic patients who returned a negative result, minimising the risk of false negatives. We also note that RT-PCR tests will return positive results even if the virus is inert - only by culturing the sample is it possible to verify that a patient is truly infectious 16s]. Residual virus genetic material will not pose a risk when releasing convalescing patients after false negative tests.
In conclusion, we demonstrate how the sensitivity of the RT-PCR assay for detecting SARS-CoV-2 infection depends on the time from the onset of symptoms in symptomatic individuals, and show how nasal swabs appear more sensitive than throat swabs. In the absence of other testing procedures, this has implications for clinical decisions about treatment, and decisions about who needs to be quarantined or can be released safely into the community. We also illustrate how, assuming that the false positive test probability is negligible, the count of positive tests underestimates the count of infected individuals in a group of tested individuals, which in turn has implications for estimates of case and infection fatality risks in the wider population. However, if the false-positive test probability is non-zero, then values as low as 0.5% - 1% could mean that the true prevalence among those tested is lower than suggested by the naive count of positive tests.
Limitations
First, more data exists than we have been able to analyse. Many of the studies cited here (& others - e.g. [18]) have more longitudinal data from more patients but which is not currently publicly available, or not disaggregated by swab type. Inclusion of this data would provide superior estimates, in particular if it is disaggregated into tests done from different samples via different routes in the same patient. Moreover, explicit reporting of dates when tests are performed in all patients (& not just those who test positive) would be especially useful to any subsequent similar analyses for SARS-CoV-2 or other emerging viruses.
Second, we have attempted to account for possible differences among labs performing RT-PCR tests and although we do not find any evidence here in favour of this being relevant, nor is there enough evidence to rule it out based on this alone. There may also be variation in terms of the gene that is targeted by RT-PCR, which we have also not been able to consider. Although we hope our results are broadly representative, they may not capture the full extent of variation as test protocol and testing laboratory vary.
Third, we have attempted to account for possible differences among patients in their sensitivity to the test. In reality, one might expect this to be related to either the underlying severity of the infection or, at least, viral load, neither of which we have been able to assess with the available data. Furthermore, the data here all comes from symptomatic patients and it could be that the test is less sensitive in asymptomatic individuals, not least because there is no onset of symptoms and it is therefore unclear from which baseline test sensitivity should be measured. On the other hand, a recent Italian study offered evidence that, among those testing positive, viral loads were equivalent in symptomatic and asymptomatic individuals [19]. This does not show, however, that viral loads are the same in both groups, but that they are equivalent conditional on a positive test, which is what we might expect if the probability of a positive test is indeed linked to viral load. If this is true, then it could be that many asymptomatically infected individuals are asymptomatic because their immune system managed to check viral replication early on in their infection and viral loads sufficient to result in a positive test were not achieved. If true, however, this might be difficult to square with the apparent transmission potential of asymptomatic individuals [20]. Better understanding of the sensitivity of the test in asymptomatic individuals is of paramount importance.
Fourth, when estimating the true number of positives in a cohort of tested individuals we have to additionally assume that the distribution of the time to test is the same as we infer from our results here and the distribution of time to confirmation in Guangdong (Bi et al. [11]). Even if this distribution is broadly representative from country to country, it may not be consistent over time. For example, as testing capacity gets stretched, the time to test may increase and so too the probability of a consequent false-negative. These particular results should therefore be taken as indicative rather than authoritative. Furthermore, these results only relate to the cohort of tested individuals rather than the population at large: they say nothing about the prevalence of the virus among those not tested. That said, individual hospitals, testing centres or studies will know the timings of their tests and can use this in conjunction with this paper to assess how likely any one test is to represent a false-negative.
Data Availability
All the data used in this manuscript was already in the public domain.
Supplementary Material
Estimating the false-negative error rate in cohorts of tested individuals
Using the GAMM model, we estimated the aggregate false negative rate for hypothetical cohorts of tested patients. To do this, we considered a range of Gamma distributions as parameterised by the mode and standard deviation. These distributions were used to describe the time between the onset of symptoms and patients being tested. The shape (S) and rate (R) parameters were written as functions of the mode (M) and standard deviation (σ) [21]:
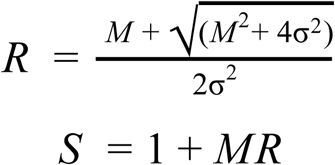
We explored arrival time distributions with modes ranging from 0.1 to 5 days and standard deviations ranging from 0.5 to 5. We discretised the arrival time distribution (Γ(x)) to give the proportion of patients in a cohort being tested on a given day. These fractions were then multiplied by the estimated probability of a false negative predicted by the GAMM function (f(x)) for a single nasal swab on that day; summing these together gives the aggregate false negative rate (P(Neg|Inf)) for cohorts tested according to this particular arrival time distribution. To get the probability of 2 false-negatives 1 day apart, we simply took the product f(x).f(x+1) and used this in place of f(x).
Estimating the time to test
Let
τi correspond to being tested on day i
Ψ correspond to having a positive test result
η correspond to being infected
Then
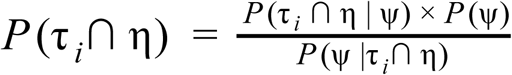
Now if we assume the test has perfect sensitivity then P (τi ∩ η | Ψ) ≡ P (τi |Ψ) since all individuals with positive tests must be infected, and so we estimate this for each day using the distribution of time to positive test results for symptomatic individuals from Bi et al. [11] (a gamma distribution with shape 2.12 and rate 0.39). We discretise this distribution (such that [0, 0.5) corresponds to 0 days from symptom onset, [0.5, 1.5) corresponds to 1 day after symptom onset etc) and truncate it to 31 days, which is the maximum number of days from symptom onset present in the data we analyse. This truncation has no practical impact because > 99.99% of the density of this particular gamma distribution is accounted for at this point.
Meanwhile P (Ψ |τi ∩ η) is the probability of a positive test result for infected individuals given the day of the test, which is exactly what we estimate in this study. Of course, P (Ψ) is unknown. This gives us P (i ∩) but as we are assuming that individuals are tested only once then τi ∩τj = {∅} for i ≠ j which means that we can easily retrieve:
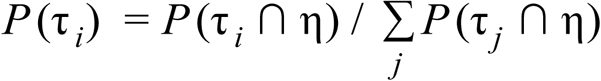 and then the unknown P () appears in every term on the RHS and so vanishes.
and then the unknown P () appears in every term on the RHS and so vanishes.
Estimating the true prevalence in a cohort of tested individuals
Supposing that all tests were performed the same number of days after symptom onset; let’s define:
α as the (unknown) true prevalence among those tested
β as the false-positive rate i.e. P(positive test | uninfected)
γ as the false-negative rate for tests done on that day i.e. P(negative test | infected)
T is the total number of tests done on that day, of which a fraction q are positive
Then the true prevalence among those tested for infection is equal to the sum of (a) P(infected|positive test) multiplied by the number of positive tests and (b) P(infected| negative test) multiplied by the number of negative tests (i.e sum of the true positives and false negatives). These conditional probabilities can be separately rearranged via Bayes Theorem and then added together to give:
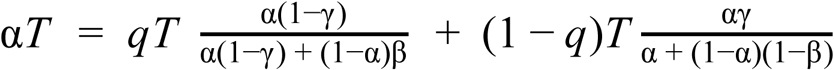
If we rearrange this as a quadratic in alpha then we discover it has 2 roots:
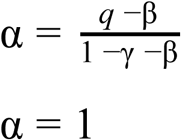
And so the first root allows us to estimate the true prevalence among the test cohort, while accounting for the false-negative test probability for those tested on that day.
In reality, however, individuals are tested on different days on which the false negative test probability depends, which makes it much harder to estimate α in this way. One way it can be done is to use the distribution for time to test to calculate the average false-negative test probability across all tests conducted, again assuming that all tests are done by nasal swab - here this gives a false-negative test probability of 23.1%. If we do this, then we can still apply the same equations as above and explore how accounting for the false-negative and false-positive test probabilities affects the consequent estimates of the true prevalence among those tested, which we illustrate for some different scenarios. Importantly, this only tells us about prevalence in the test cohort and not in the wider population i.e. this does nothing to correct for not finding and not testing mild/asymptomatic cases.
Summary model output
This is a representation of the fitted values in the final model for test sensitivity as returned by mgcv::summary in R:





{kind=link}
{kind=link}
{kind=link}
{kind=link}