
Abstract
Background Exponential-like infection growths leading to peaks (which could be the inflection points or turning points) are usually the hallmarks of infectious disease outbreaks including coronaviruses. To predict the inflection points, i.e., inflection time (Tmax) & maximal infection number (Imax) of the novel coronavirus (COVID-19), we adopted a trial and error strategy and explored a series of approaches from simple logistic modeling (that has an asymptomatic line) to sophisticated tipping point detection techniques for detecting phase transitions but failed to obtain satisfactory results.
Method Inspired by its success in diversity-time relationship (DTR), we apply the PLEC (power law with exponential cutoff) model for detecting the inflection points of COVID-19 outbreaks. The model was previously used to extend the classic species-time relationship (STR) for general DTR (Ma 2018), and it has two “secondary” parameters (computed from its 3 parameters including power law scaling parameter w, taper-off parameter d to overwhelm virtually exponential growth ultimately, and a parameter c related to initial infections): one that was originally used for estimating the potential or ‘dark’ biodiversity is proposed to estimate the maximal infection number (Imax) and another is proposed to determine the corresponding inflection time point (Tmax).
Results We successfully estimated the inflection points [Imax, Tmax] for most provinces (≈85%) in China with error rates <5% in both Imax and Tmax. We also discussed the constraints and limitations of the proposed approach, including (i) sensitive to disruptive jumps, (ii) requiring sufficiently long datasets, and (iii) limited to unimodal outbreaks.
Introduction
In spite of the obviously extreme importance and extensive research efforts, predicting the inflection points, formally known as the tipping points or turning points in much of the existing literature, turned out to be notoriously difficult. The enormous complexity associated with tipping points and critical transitions make accurate predictive modeling nearly impossible. Existing theories suggest that early warning signals (EWS) may be developed based on the phenomenon that recovery rates from small disturbances should tend to zero when approaching a tipping point (Scheffer et al. 2009, 2015), and some laboratory experiments and field survey have demonstrated the so-called “critical slow down” (CSD) phenomenon (e.g., Veraart et al. 2012, Dakos et al. 2015).
In theory, it has been suggested that even without fully mechanistic understanding of the underlying critical transitions, it is still possible to infer generic features or early warning signals (EWS) of approaching a tipping point from time series or spatial pattern data. Theory proposes that at bifurcation points (i.e., tipping points), the stability of an equilibrium changes and the dominant real eigenvalue becomes zero. Consequently, the recovery rate from disturbance should go zero when approaching such bifurcation, or the return time (measure of resilience) should be infinity (Veraart et al. 2012). In practice, the recovery rate from disturbance may be an indicator of the distance to a tipping point, and its manifestation, the CSD offer important early EWS for approaching a tipping point.
Investigating the inflection points of infectious disease outbreaks including the ongoing coronaviruses pandemic falls under the domain of tipping points and critical transitions (Veraart et al. 2012, Dakos et al. 2015, Scheffer et al. 2009, 2015). However, in a pre-experiment analysis of the existing datasets of COVID-19 infections, we failed to detect any tipping points (inflection points). We conjecture that the failure may have to do with the insufficiently long duration of data collections. We then also tried some simple epidemiological modeling approaches such as simple logistic model (e.g., Ma et al. 2009) but still failed to achieve satisfactory results.
Inspired by the exponential-like growth of infections leading to peaks, which seems to be a hallmark of many infectious disease outbreaks including COVID-19 and SARS (Rivers et al. 2019, Li et al. 2020, Thompson 2020, Ma 2020), we try the PLEC (power law with exponential cutoff) model for detecting the inflection points in the time series data of COVID-19. The PLEC model (function) starts with power function increase (near exponential growth usually) and it has an exponential decay term that acts as taper-off parameter to eventually overwhelm the power law behavior at very large value of independent variable. The PLEC model was previously used to describe the classic species-area relationship (SAR) in biogeography (Plotkin et al. 2000, Ulrich & Buszko 2003), and later used for extending the classic SAR and STR (species-time relationship) to general diversity-area relationship (DAR) and diversity-time relationship (DTR) (Ma 2018a, 2018b, 2019). Furthermore, Ma (2018a, 2018b, 2019) derived the formula to estimate the maximal accrual diversity (MAD) in space (area), time, and/or spatiotemporal settings, which may also be used to estimate potential diversity (also known as “dark” diversity). The potential or dark diversity refers to the biodiversity that take into accounts the contribution of species that are absent locally but potentially present in regional species pool. This situation of potential species migration from regional (metacommunity) to local community is not unlike the COVID-19 infections via dispersal (migration) such as travelers of virus-infected individuals. We postulate that the PLEC model can be useful for modeling the infection-time relationship (ITR)—the relationship between the cumulative number of infections and time points (e.g., day 1, 2,……,N). If the PLEC model successfully fits to the ITR datasets, we further postulate that the maximal accrual diversity or potential diversity and corresponding time point may be translated into an approach for estimating the maximal infection number (Imax) of an outbreak and the corresponding time point (when Imax is reached) as estimate of inflection time point (Tmax). Together the pair of {Imax, Tmax} is defined as the inflection point of a disease outbreak in this study. We further devised schemes to test the performance of the PLEC model in predicting (estimating) the inflection points of COVID-19 outbreaks.
Material and Methods
The PLEC model (Power Law with Exponential Cutoff)
A hallmark of coronaviruses outbreaks seems to be exponential or near exponential growth of infections, and the peak time and amplitude or the outbreak inflection points of the virus are of obvious importance both theoretically and practically. We address this problem with a trial-and-error strategy. We first conjectured that simple logistic growth model could be a possible solution since its asymptotic limit (K) might be used to approximate the inflection points (Ma et al. 2009). We also tried sophisticated mathematical approaches for detecting tipping points (Dai et al. 2012, 2013, Sundstrom et al. 2017). However, the applications of both logistic growth model and tipping point approaches failed to generate satisfactory results.
In the present report, we adopt the PLEC (power law with exponential cutoff) model for estimating the inflection points of coronavirus infections. The PLEC model is of the following form:

The model was initially used by Plotkin et al (2000) and Ulrich & Buszko (2003) for modeling the classic species-area relationship (SAR). Ma (2018a, 2018b, 2019) introduced it for more general diversity-area relationship (DAR), diversity-time relationship (DTR) and diversity-time-area (DTAR) relationship. Another extension to the model was the derivation of two parameters by Ma (2018a, 2018b, 2019): the maximal accrual diversity and corresponding time or space points. The maximal accrual diversity can be used to estimate the so-termed potential diversity (also known as “dark” diversity), which takes into accounts of the species that are absent locally (in local communities) but present regionally (in metacommunities) (Ma 2019, Li & Ma 2019).
In the present report, we use the PLEC (power law with exponential cutoff) model (eqn. 1) for modeling the growth of COVID-19 infections. With eqn. (1), T is the time or days (starting from a specified date), and I is the number of cumulative infections, c, d, and w are three parameters to be estimated from the observed data. Ma (2018a) derived the maximum of eqn. (1) by solving the following equation:
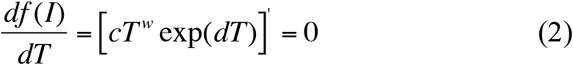 which leads to:
which leads to:
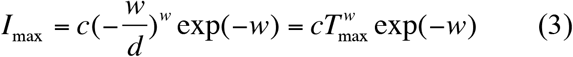
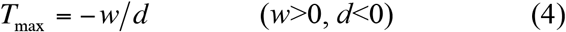
Theoretically, eqns. (3) & (4) can be utilized to estimate the maximal infection number (Imax) and corresponding inflection time point (Tmax) at which Imax occurs.
Parameter d is of particular interests: exp(dT) in eqn. (1) is the exponential decay term that acts as taper-off parameter to eventually overwhelm the power law behavior (exponential or near exponential growth) at very large value of T. For eqn. (1) to achieve maximum of realistic biomedical meaning (Tmax>0) or (w>0 & d<0) are necessary conditions.
The biological interpretation of parameter w & c can best be observed by assuming d→0. When d=0, the PLEC defaults to classic power-law model,
 or its log-transformed linear model:
or its log-transformed linear model:
 in which w is the slope of the log-linear model or the derivative of I(T), i.e., the change (growth) rate of infections over time, and c is the initial infection number. Since the taper-off effects of parameter d is usually rather weak before the infection peaks, it is reasonable to consider w as an approximation of the infection growth rate, and c as an approximation of the initial infection number.
in which w is the slope of the log-linear model or the derivative of I(T), i.e., the change (growth) rate of infections over time, and c is the initial infection number. Since the taper-off effects of parameter d is usually rather weak before the infection peaks, it is reasonable to consider w as an approximation of the infection growth rate, and c as an approximation of the initial infection number.
A simple method to statistically fit the PLEC model [eqn. (1)] is to transform it into a log-linear equation as follows:
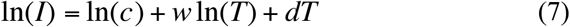
For eqn. (7), simple linear regression can be used to fit the model and hence obtain the PLEC parameters. Nevertheless, the simple linear regression may not provide satisfactory fitting to the original PLEC model [eqn. (1)], especially when the number of data points for fitting the model is small or moderate. For this reason, we use the nonlinear optimization method to fit the PLEC model [(eqn.1)] directly, rather than fitting the log-linear transformed equation [eqn. (7)] indirectly. We used nonlinear optimization method, specifically the R function “nlsLM” from R package “minpack.lm” (https://www.rdocumentation.org/packages/minpack.lm/versions/1.2-1/topics/nlsLM) (Bates & Watts 1988). Since only Tmax>0 (negative time is meaningless to count infections) is a necessary condition for the PLEC model to be biometrically sound, we add a constraint d<0 for the non-linear fitting of PLEC model.
It is particularly worthy of noticing that the dependent variable (I) of PLEC, almost unavoidably, declines after the inflection point (maximum) due to the taper-off parameter (d). Nevertheless, this should not be an issue in the case of this study, since our purpose is to detect the inflection point (Tmax) as well as the corresponding maximum (Imax). In other words, the declining piece of PLEC curve after the inflection point is “irrelevant” for our purpose. Of course, this also implies that our model is only applicable to unimodal (single peak) outbreak.
The COVID-19 infection datasets and criteria for evaluating the PLEC model
We collected the daily infections datasets of COVID-19 in 34 Chinese provinces and the world from the public domain. In addition, we collected the datasets of 17 cities of Hubei province of China. The infection data between Jan 19th and Feb 29th were collected for building the predictive PLEC model, and the infection data at two time points (March 6th and 12th) as the test data points to evaluate the performance of the PLEC model in determining the inflection points. The public websites used to get the data include: https://news.qq.com/zt2020/page/feiyan.htm#/ and https://news.ifeng.com/c/special/7tPlDSzDgVk.
We test the performance of the proposed PLEC model with two schemes. First, we evaluate the “congruency” of Tmax (inflection time point) with the reality by comparing the actually observed infection number at the date of Tmax with the estimated Imax. To determine the congruence, we calculate an interval [Imax−Imaxx0.05; Imax+Imaxx0.05] for each PLEC model. If the actually observed infection numbers falls within the interval, the estimation of Tmax is considered as valid. It is noted that this is not a classic confidence interval, which requires the calculation of standard deviation of samples and cannot be obtained in the case of COVID-19 infections. Instead, this “homegrown” interval we computed is simply a range of Imax with 5% fluctuation, which we believe is a reasonable scheme for estimating the validity of the Tmax estimations.
Second, to evaluate the validity of Imax estimations, we used the observed infection number on the day of Tmax, March 6th and March 12th, respectively, as reference values to evaluate the performance of the PLEC model, using the following formula to calculate the error rate:

Alternatively, the precision P(%) of the PLEC model is simply computed as the complement of E(%), i.e., P(%)=1–E(%).
Results
We fitted the PLEC model with the nonlinear optimization method (i.e., the R-function ‘nlsLM’ introduced in the previous “The Model” section) to each of the 17 cities in Hubei province, each of the 34 provinces of China, as well as the whole China and worldwide infections datasets. The results were displayed in Table 1 (the PLEC model-fitting results) and Table 2 (test of the model performance). Since the model mostly failed to make meaningful predictions of the infections outside China, we postpone the worldwide results to the “Discussion” section and here we focus on the results fitted to the datasets in China.
The ITR-PLEC (Infection Time Relationship—Power Law with Exponential Cutoff) model, fitted with nonlinear optimization for daily cumulative COVID-19 infections*
Evaluate the error rates of the inflection-point estimations based on the infection-time relationship (ITR) with PLEC (power-law function with exponential cutoff) model
Listed in Table 1 included the PLEC parameters (w, d, c) and the p-values [w(p), d(p), c(p)] from estimating the corresponding parameters. These p-values measure the significance levels for estimating these parameters: a p-value<0.05 indicating that the goodness-of-fitting to the model is statistically satisfactory from the perspective of the particular parameter. R2 (R-squared) is of limited reference value for non-linear fitting problem, but it also confirmed the goodness-of-fitting as illustrated by the p-values for individual parameters. Obviously, the most important items in Table 1 are the Imax and corresponding Tmax, the maximal infection number (eqn. 3) and the corresponding inflection time point (eqn. 4), respectively.
Table 1 shows that PLEC fitted to virtually all datasets satisfactorily in terms of the p-values except for a few negligible parameter cases (p-value>0.05 in 4 out of 52). It should be noted that the 4 parameter cases that failed to pass significance tests only means that the parameter values may have too high standard error (variability) and the failure does not necessarily mean that the model structure failed. Therefore, the model could still be used for estimating Tmax and Imax, as long as the tests with actual observations are satisfactory, as explained below. Fig 1 shows an example of fitting the PLEC model based on the total infections in China from January 12th to February 29th.
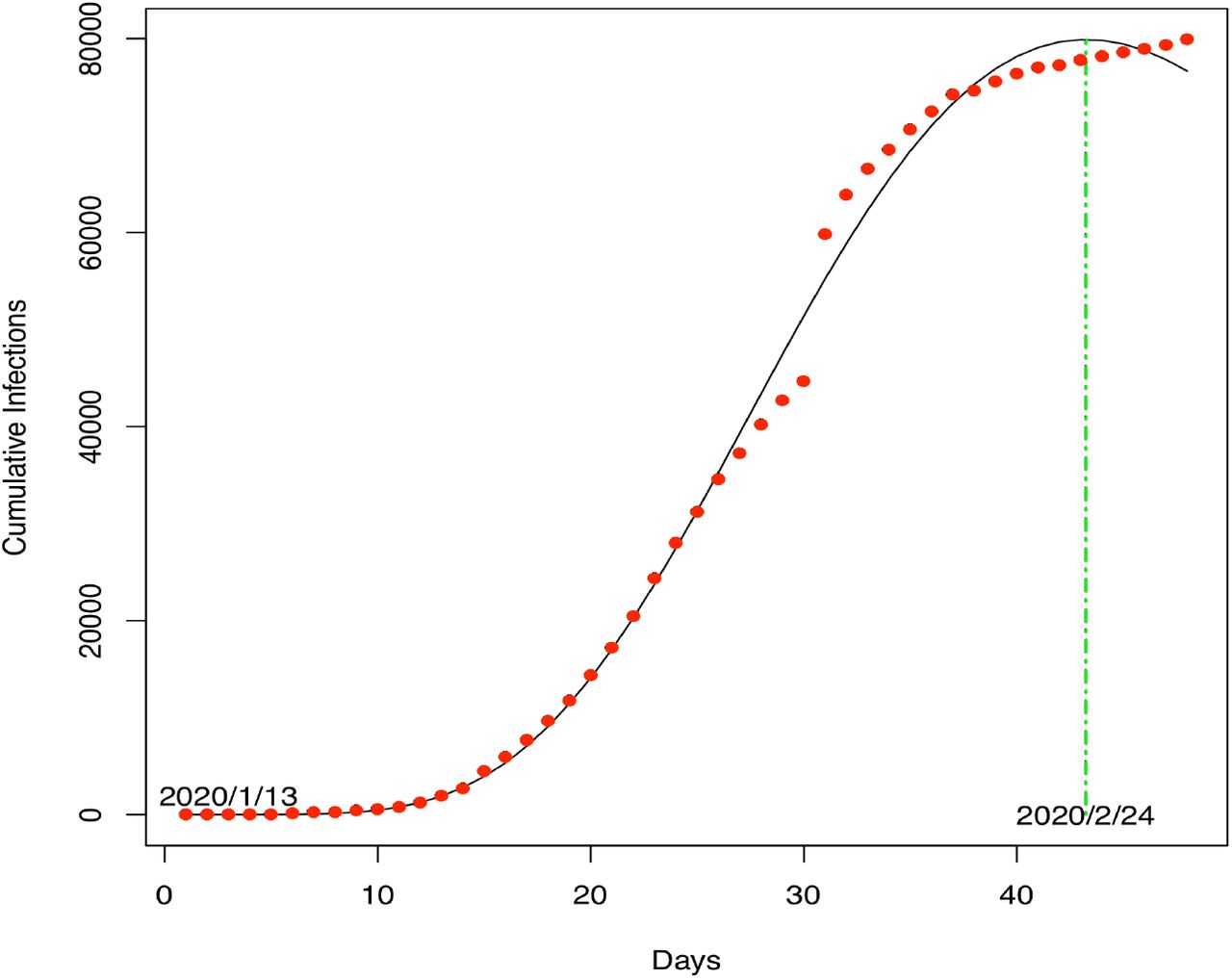
The PLEC model fitted to the COVID-19 infections in China (X-axis: Day 1=January 13th 2020): the dots represent for observed infection numbers and the curve for the PLEC model.
On the whole model level, the datasets of Tibet (Xizang) and Taiwan failed to fit the PLEC model. The failure for Tibet dataset is expected since there was only one infection case and fitting a model is neither necessary nor possible; hence it was excluded from the performance evaluation. The failure to fit the infection data of Taiwan is unknown, and we instead included it in the performance evaluation as failed estimations.
Table 2 listed the results from evaluating the validity of Tmax (the left side) and Imax (the right side). Regarding Tmax, the PLEC model correctly estimated the occurrences of inflection time points in 88% (15 out of 17 cities) in Hubei province, and 85% (29 out of 34 provinces) at the national level in China. Regarding Imax, the success rates for the 17 cities in Hubei provinces were 88%, 100%, & 100% respectively, in terms of the observed infection numbers at the dates of Tmax, March 6th and March 12th, respectively. Regarding Imax for the 34 provinces in China, the success rates were 85%, 85%, & 82% respectively, in terms of the observed infection numbers at the dates of Tmax, March 6th and March 12th, respectively.
In summary, the test results suggest that the proposed PLEC model successfully estimated the inflection points in terms of both {Tmax & Imax}, i.e., the inflection time points and maximal infection numbers, in more than 80% tested cases (ranged between 82%-100%). Note that the date range we used to build PLEC models was between January 19 and February 29th, rather than the full date range available, and the datasets of the remaining dates were used for evaluating the performance of PLEC models.
Figs 2 shows both the observed and estimated maximal infection numbers {Imax} for each of the 34 provinces of China, as well as the total national number (the last pair of bars). Fig 4 shows the corresponding inflection time points {Tmax} of each province displayed in Fig 2. Fig 3 shows the observed and estimated maximal infection numbers {Imax} for each of the 17 cities of Hubei province of China, as well as the total provincial number (the last pair of bars). Fig 5 shows the corresponding inflection time points {Tmax} of each city.

Comparisons of the observed and estimated infection time points (Imax) for the 34 provinces of China; the rightmost bar represents for the inflection time point (Imax) of the whole China

Comparisons of the observed and estimated infection time points (Imax) for the 17 cities of Hubei Province, China.

The estimated inflection time point (Tmax) of COVID-19 infections for 34 provinces of China; the rightmost bar represents for the inflection time point (Tmax) of the whole China.

Estimated inflection time point (Tmax) of COVID-19 infections for the 17 cities of Hubei Province, China
Discussion
In this section, by analyzing the failures of PLEC case by case, we try to uncover the model’s limitations. We first examine the failure exposed in previous Tables 1 & 2.
In Tables 1 & 2, the PLEC model for Shandong province performed badly with error rates about 11% was apparently due to the sudden discovery of approximately 200 cases in a local prison on a single day (Feb 20), which was approximately 1/5 of the total number in the province. The model for Gansu province also performed badly with error rates of 36%, apparently due to 33 inputs from the overseas between March 4th and 8th, approximately 1/3 of the total number in the province. These individual cases suggest that the PLEC modeling can be sensitive to certain disruptive increases, in particular, to the increases that occupy disproportionally large proportion of the total numbers. This may be considered as the first limitation of the PLEC model. On the positive side, excluding the inaccuracies from these disruptive increases as well as the individual cases of Taiwan and Tibet, the PLEC model actually performed exceptionally well, reaching success rates mostly exceeding 95%.
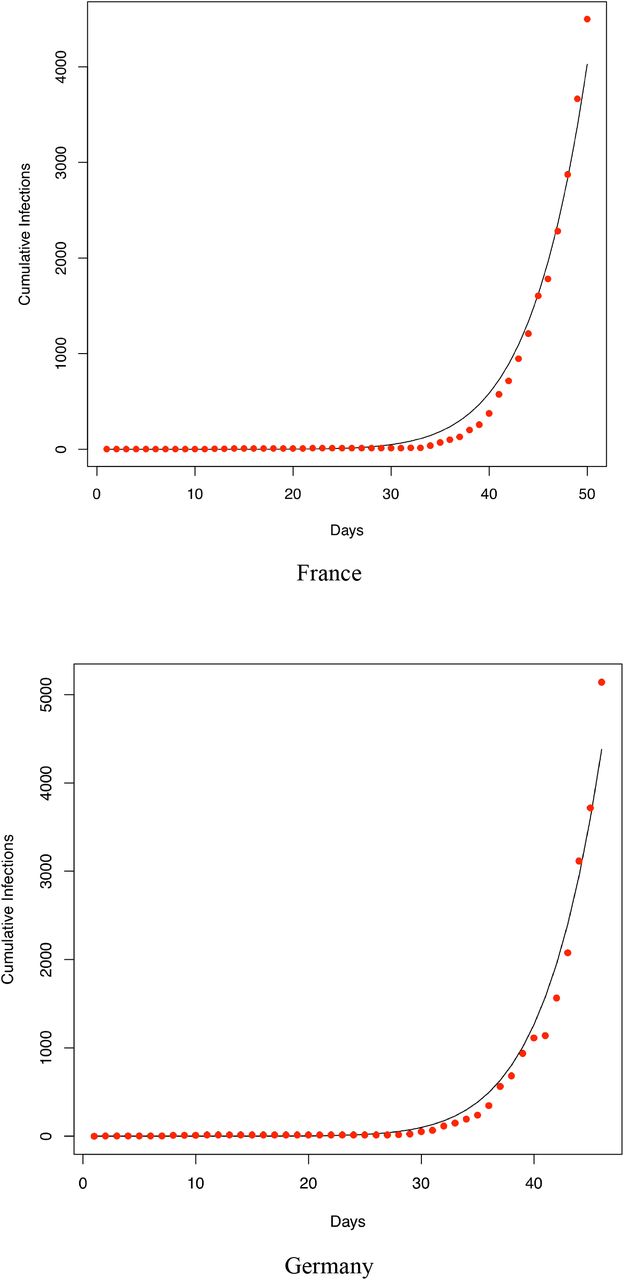
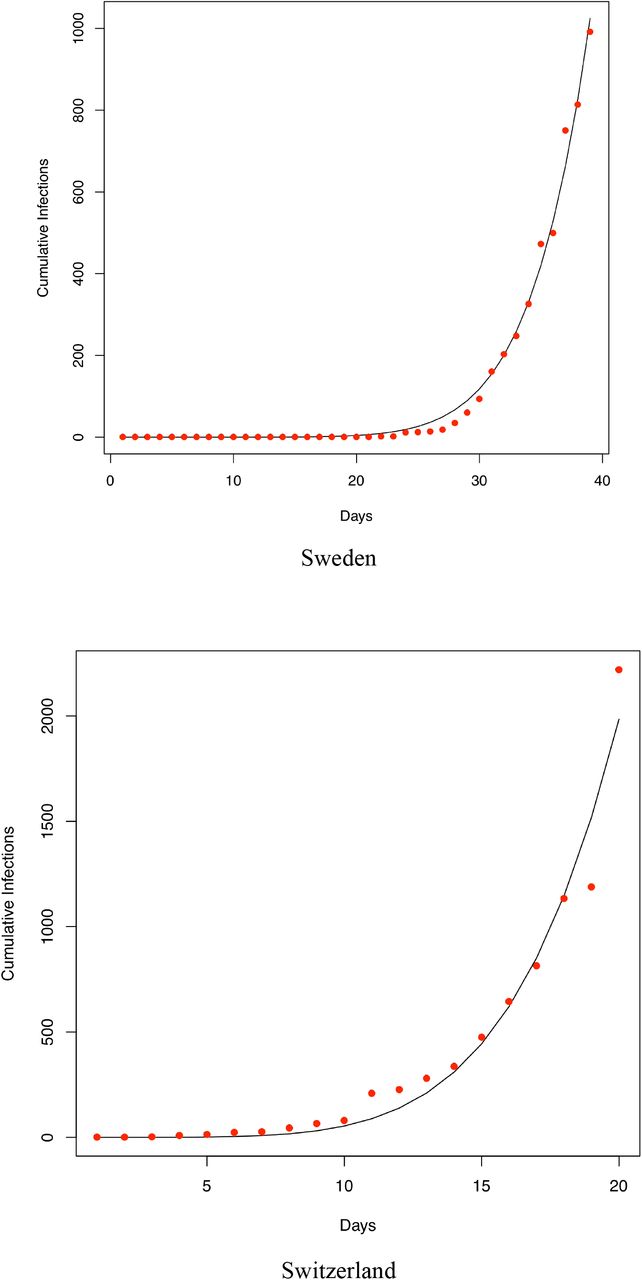
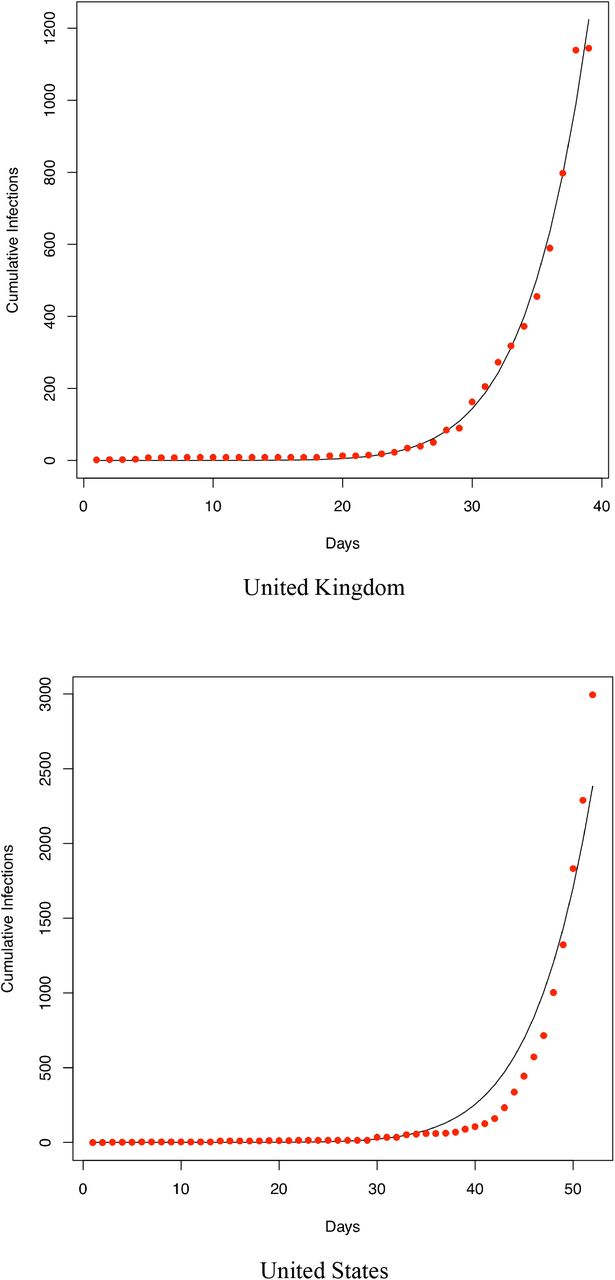
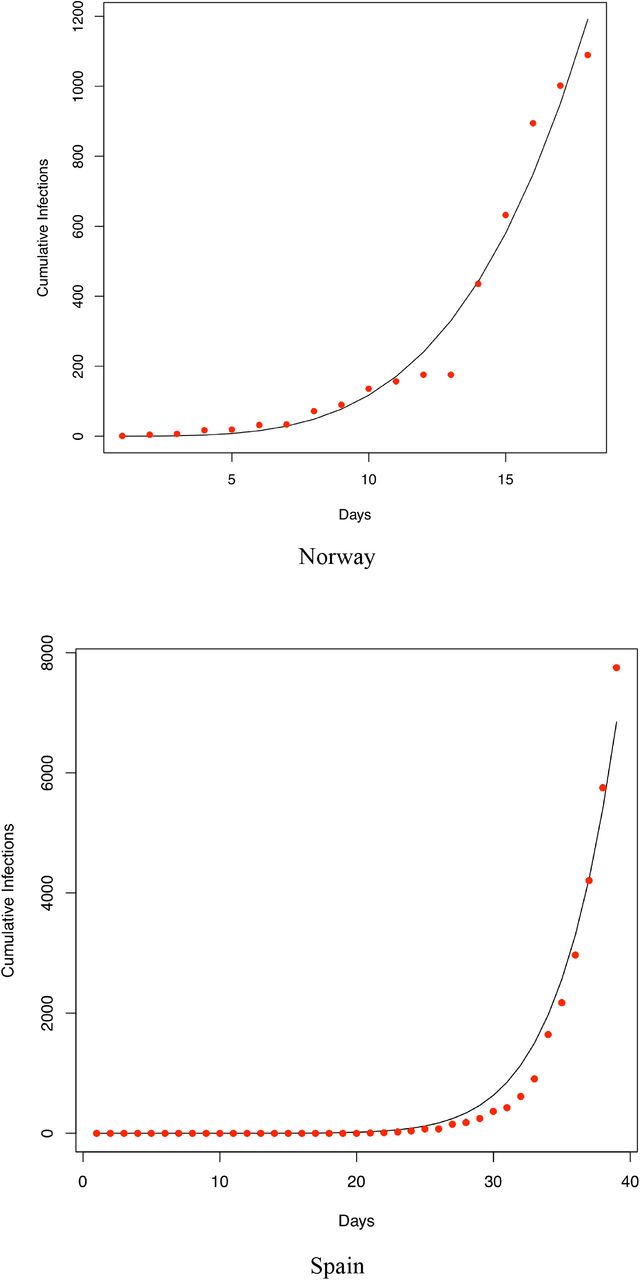
We also fitted the PLEC model to the infection datasets of at least 14 countries (top 14 in terms of the infection numbers until March 15th) as well as the worldwide total infection number, and total worldwide infection number excluding China. Overall, in a majority of the cases, the PLEC model failed to obtain satisfactory predictions for the inflection points measured in {Tmax, Imax}. To save page space, portions of the modeling results were supplied in Fig S1 of the OSI (Online Supplementary Information). From those failures, we conjecture that the failures are most likely due to the reality that in most of those countries (regions), the infections are still in the exponential growth stages. This, of course, suggests another possible limitation of the PLEC model, namely, the PLEC model may require a sufficiently long period of data points to successfully reveal the inflection points. Like all mathematical models, PLEC model is no silver bullet. Without seeing a sign of inflection point, it may not be possible for the PLEC model to reveal its existence.
Still a third limitation of the PLEC model is that it may only detect a single inflection point for a dataset. In other words, it is only applicable for detecting the inflection point for unimodal curve, as explained in the material and methods section. In the case of coronaviruses, this may not be an issue given that the SARS outbreak was also unimodal. In case of multiple-peak recurrence or seasonal outbreaks, it should be possible to divide multi-modal curve into multiple unimodal curves. Therefore, this limitation should be much less serious than it appears.
Given the above-discussed limitations of the PLEC model, we also applied the tipping point detection technique based on Fisher information (Sundstrom et al. 2017) for determining the inflection points, but failed to detecting any inflection (tipping) points in the datasets of COVID-19 infections. As shown in Table S1, virtually all Fisher Information (FI) values at every time window of the time series of COVID-19 equal 4, which indicates no existence of tipping points. This additional exploratory analysis not only revealed the difficulty of the problem for detecting the inflection points, but also suggested the value of PLEC model given that it successfully estimated the inflection points in terms of both {Tmax & Imax} on the city, provincial and national scales in China. To some extent, the failures of PLEC model at large scales of country should mostly due to the limitation of currently available datasets, rather than the model per se.
Finally, we would like to mention one potentially very important point regarding the prediction of inflection points, but is beyond the scope of this study, that is, the potentially critical influences of public-health intervention/prevention measures on the occurrences of inflection points. Such a study may only be possible after the COVID-19 worldwide pandemic is over in our opinion.
Data Availability
All data analyzed are available in public domain and the source links are provided in the manuscript.
Online Supplementary Information (OSI) for
Ma (2020) A Simple Mathematical Model for Estimating the Inflection Points of COVID-19 Outbreaks




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Fitting the PLEC (power law with exponential cutoff) model to the COVID-19 infections of 14 countries worldwide (which were selected based on the number of infections until Feb 15th). The datasets were collected between January 20th and March 15th)
The Fisher Information (FI) metric for detecting tipping points: computed for each time windows [based on the COVID-19 infection datasets of Wuhan, Hubei (between Jan 11 to Feb 29), China and World (between Jan 13 to Feb 29), and the rest of the provinces (between Jan 19 to Feb 29)]
Acknowledgements and Disclaims
I am indebted to the data collection and computational support from Lianwei Li and Wendy Li of the Computational Biology and Medical Ecology Lab, the Chinese Academy of Sciences. I am responsible for all the interpretations of the results, including possible errors. However, I am not responsible for any direct or indirect inferences from this article, including those from partial quotes of the text, figures and/or tables.
References



