
Abstract
Effectively designing and evaluating public health responses to the ongoing COVID-19 pandemic requires accurate estimation of the weekly incidence of COVID-19. Unfortunately, a lack of systematic testing across the United States (US) due to equipment shortages and varying testing strategies has hindered the usefulness of the reported positive COVID-19 case counts. We introduce three complementary approaches to estimate the cumulative incidence of symptomatic COVID-19 during the early outbreak in each state in the US as well as in New York City, using a combination of excess influenza-like illness reports, COVID-19 test statistics, and COVID-19 mortality reports. Instead of relying on an estimate from a single data source or method that may be biased, we provide multiple estimates, each relying on different assumptions and data sources. Across our three approaches, there is a consistent conclusion that estimated state-level COVID-19 symptomatic case counts from March 1 to April 4, 2020 varied from 5 to 50 times greater than the official positive test counts. Nationally, our estimates of COVID-19 symptomatic cases in the US as of April 4 have a likely range of 2.2 to 5.1 million cases, with possibly as high as 8.1 million cases, up to 26 times greater than the cumulative confirmed cases of about 311,000. Extending our method to May 16, 2020, we estimate that cumulative symptomatic incidence ranges from 6.0 to 12.2 million, which compares with 1.5 million positive test counts. Our approaches demonstrate the value of leveraging existing influenza-like-illness surveillance systems during the flu season for measuring the burden of new diseases that share symptoms with influenza-like-illnesses. Our methods may prove useful in assessing the burden of COVID-19 during upcoming flu seasons in the US and other countries with comparable influenza surveillance systems.
1 Introduction
COVID-19 (SARS-CoV-2), is a coronavirus that was first identified in Hubei, China, in December of 2019. On March 11, due to its extensive spread, the World Health Organization (WHO) declared it a pandemic [1]. As of April 8, 2020, COVID-19 had infected people in nearly every country globally and in all 50 states in the United States (US) [2]. This pandemic now poses a substantial public health threat with potentially catastrophic consequences. Reliable estimates of COVID-19 infections, particularly at the start of the outbreak, are critical for appropriate resource allocation, effective public health responses, and improved forecasting of disease burden [3].
A lack of widespread testing due to equipment shortages, varying levels of testing by region over time, and uncertainty around test sensitivity make estimating the point prevalence of COVID-19 difficult [4, 5]. In addition, it has been estimated that 18% [6] to 50% [7, 8] of people infected with COVID-19 do not show symptoms. Even in symptomatic infections, under-reporting can further complicate the accurate characterization of the COVID-19 burden. For example, one study estimated that in China, 86% of cases had not been captured by lab-confirmed tests [9], and it is possible that this percentage is even higher in the US [5]. Finally, it has been suggested that the available information on confirmed COVID-19 cases across geographies may be an indicator of the local testing capacity over time (as opposed to an indicator of the epidemic trajectory). Thus, solely relying on positive test counts to infer the total number of COVID-19 infections and the epidemic trajectory, may not be sensible [10].
The aim of this study is to develop alternative methodologies, each with different sets of inputs and assumptions, to estimate the weekly cumulative symptomatic incidence of COVID-19 in each state in the US. One such approach is to analyze region-specific changes in the number of individuals seeking medical attention with influenza-like illness (ILI), defined as having a fever in addition to a cough or sore throat. The significant overlap in symptoms common to both ILI and COVID-19 suggests that leveraging existing disease monitoring systems, such as ILINet, a sentinel system created and maintained by the United States Centers of Disease Control and Prevention (CDC) [11, 12], may offer a way to estimate the ILI-symptomatic incidence of COVID-19 without needing to rely on COVID-19 testing results. Importantly, regional increases in ILI observed from February to April 2020 in conjunction with stable or decreasing influenza case numbers present a discrepancy (that is, an increase in ILI not explained by an increase in influenza) that can be used to impute COVID-19 ILI-symptomatic cases.
A second and related approach uses ILI data to deconfound COVID-19 testing results from state-level testing capabilities. These two approaches show that existing ILI surveillance systems provide a useful signal for measuring COVID-19 ILI-symptomatic incidence in the US, especially during the early stages of the outbreak. However, they are dependent on reporting from the ILINet system, and thus become less reliable outside of peak flu season and when COVID-19 precautions disrupt routine health care use.
Our third and final approach uses reported COVID-19-attributed deaths to estimate COVID-19 symptomatic incidence (broader than the ILI-symptomatic incidence of the first two methods) and improves upon previously introduced methodologies [13, 14, 15, 16, 17]. COVID-19 deaths may represent a lower-noise estimate of cases than surveillance testing given that patients who have died are sicker, more likely to be hospitalized, and thus more likely to be tested than the general infected population.
While previous work has attempted to quantify COVID-19 incidence in the United States using discrepancies in ILI trends [18, 19], to the best of our knowledge this study is the first to offer a range of estimates at the state level, leveraging a suite of complementary methods based on different assumptions. We believe that this provides a more balanced picture of the uncertainty over COVID-19 (ILI-)symptomatic incidence in each state. While our results are approximations and depend on a variety of (likely time-dependent) estimated factors, we believe that our presented case counts better represent (ILI-)symptomatic incidence than simply relying on laboratory-confirmed COVID-19 tests. Providing such estimates for each state enables the design and implementation of more effective and efficient public health measures to mitigate the effects of the ongoing COVID-19 epidemic outbreak. While the scope of this paper is focused on the United States, the methods introduced here are general enough that they may prove useful to estimate COVID-19 burden in other locations with comparable disease (and death) monitoring systems.
2 Results
We implement four methods based on three complementary approaches to estimate the symptomatic incidence of COVID-19 within the US from March 1 to May 16, 2020. These dates correspond to the early stages of the outbreak (with fewer than 50 confirmed cases in the US), up to the date of the most recent available CDC reports as of May 28th, 2020. The first two methods, labeled div-IDEA and div-Vir, fall under the Divergence approach, which first estimates what the level of ILI activity across the US would have been if the COVID-19 outbreak had not occurred. Each method develops a control time series and uses the unexpected increase in ILI rate over the control to infer the burden of COVID-19. div-IDEA is based on a parametric epidemiological model, the IDEA model [20], fitted to the observed 2019-2020 ILI (prior to the introduction of COVID-19 to the US), while div-Vir is based on the time-evolution of empirical observations of positive virological influenza test statistics. The third method, based on the COVID Scaling approach, leverages healthcare ILI visits and COVID-19 test statistics to directly infer the proportion of ILI due to COVID-19 in the full population. These ILI-based methods by nature estimate ILI symptomatic incidence and may miss symptomatic patients not meeting the ILI symptoms (for the remainder of the paper, we use ‘ILI-symptomatic’ to denote COVID-19 patients with ILI symptoms and ‘symptomatic’ to denote COVID-19 patients with any symptoms). In addition, these methods are accurate only while ILI surveillance systems are operating normally (usually only during the flu season) and only while the outbreak has not yet overwhelmed hospitals. We use the ILI based methods to estimate ILI-symptomatic case counts until April 4th, 2020. The fourth method, based on the mortality MAP (mMAP) approach, uses the time series of COVID-19-attributed deaths in combination with the observed epidemiological characteristics of COVID-19 in hospitalized individuals to infer the latent disease onset time series. This is then scaled up to yield estimates of symptomatic case counts using previously reported fatality ratios and asymptomatic rates. The Methods section provides extensive details on the assumptions and data sources for each of these approaches.
2.1 Adjusted Assumptions Represent Most Likely Scenarios
Each of our methods has an adjusted version, which represents our best guess taking into account all information available to us, and an unadjusted version, which uses pre-COVID-19 baseline information. Specifically, the adjusted divergences (div-IDEA and div-Vir) and COVID Scaling methods incorporate an increased probability that an individual with ILI symptoms will seek medical attention after the start of the COVID-19 outbreak based on recent survey data [21, 22]. The adjusted mMAP incorporates newer information from serological testing, indicating a lower fatality ratio (and thus higher estimated symptomatic case count) than expected. In addition, it supplements the confirmed COVID-19 deaths with unusual increases in pneumonia-related deaths across the country that may represent untested COVID-19 cases. In most states, as seen in Fig. 1, the adjusted estimates from each method are more closely clustered than their unadjusted counterparts, increasing our confidence in the adjusted range estimates of COVID-19 cumulative symptomatic incidence (ILI-symptomatic specifically for the ILI based methods).

(On previous page) COVID-19 (ILI-)symptomatic case count estimates compared with reported case counts at the national and state levels (and New York City) from March 1, 2020 to April 4, 2020. Cases are presented on a log scale. Adjusted methods take into account increased visit propensity (div-IDEA, div-Vir, COVID Scaling) and pneumonia-recorded deaths along with a lower estimated case fatality rate (mMAP). In places where the ILI-based methods show no divergence in observed and predicted ILI visits, the estimates of COVID-19 cannot be calculated and are not shown. Note that Florida does not provide ILI data, so only mMAP could be estimated there. Refer to Supplementary Figure 1 for estimates up to May 16, 2020 for the mMAP method.
2.2 Estimated Case Counts Far Surpass Reported Positive Cases
We first computed estimates for the national and state levels using these four methods for the time period between March 1, 2020 and April 4, 2020. The adjusted methods estimate that there had been 2.2 to 5.1 million symptomatic or ILI-symptomatic COVID-19 cases in the US; including unadjusted estimates raises the upper limit to 8.1 million cases. In comparison, around 311,000 positive cases had been officially recorded during that time period. Fig. 1 displays the COVID-19 symptomatic case count estimates from our methods (ILI-symptomatic in particular for the ILI based methods) at the national and state levels (and New York City) compared with the reported case numbers. The results suggest that the estimated true numbers of infected cases are uniformly much higher than those reported. Next, we extended our methods to produce estimates through May 16, 2020 using recent data, displayed in Figure 1 of the supplementary materials. Because of a strong decline in ILINet statistics due to the end of the flu season and unusually low numbers of reporting providers, our Divergence and COVID Scaling approaches report few or no cases after April 4, 2020. Therefore, our recent estimates are computed using just the mMAP method, which estimates between 6.0 and 12.2 million symptomatic cases had occurred as of May 16. In contrast, 1.5 million positive test counts had been reported.
For reference, if one only adjusts the number of reported cases by the (likely) percentage of asymptomatic cases (18% [6] to 50% [7, 8]) and symptomatic cases not seeking medical attention (up to 73% [23]), one would conclude that the actual number of cases is higher, and about four to eight times the number of reported cases; this ratio would also be constant across states. In contrast, our methods frequently estimate 5-fold to 50-fold more symptomatic (for mMAP) or ILI-symptomatic (for Divergence and COVID Scaling) cases than those reported and show significant state-level variability (see Fig 2). The median estimates for the ratios of actual (ILI-)symptomatic cases to reported cases for the adjusted div-IDEA method is 16 (with a 90% interval from 1 to 100), for adjusted div-Vir is 21 (2, 67), for adjusted COVID-Scaling is 16 (3, 72), and for adjusted mMAP is 14 (5, 25). This highlights that models using only confirmed test cases may significantly underestimate the actual COVID-19 cumulative incidence in the United States, which is consistent with what previous studies have shown [9, 19].

Distribution of the state-level ratios of estimated to reported case counts from March 1, 2020 to April 4, 2020. The right-hand plot shows the results of using all methods together: taking the min, median, max of the state-level estimates across methods.
Our methods also provide separate cumulative case estimates for each week within the studied period (mMAP provides daily estimates, but these are aggregated by week for comparison). Fig. 3 highlights the rapid increase in estimated COVID-19 cases over the United States as well as in New York City, Washington, and Louisiana, three locations which experienced early outbreaks. These methods suggest that states under-reported COVID-19 case counts even early in March, likely due to limited testing availability. In New York and Louisiana, the estimates were more similar across methods than in Washington. Since Washington had already experienced an outbreak by February 28 [24], testing shortages may have been more pronounced than in the other states. Our divergence analysis approach does not rely on any COVID-19 testing data and therefore may provide more accurate estimates in Washington.

Cumulative weekly case counts from March 1 to May 16, 2020 for the United States, New York City, Washington, and Louisiana, as estimated by each method and the reported cases. The estimate for each week indicates total cases up to the denoted date. Solid and dotted lines indicate the adjusted and unadjusted estimates, respectively. Refer to the Supplementary Materials for results over all locations.
2.3 State-level Comparisons
Over the period of March 1, 2020 to April 4, 2020, our adjusted methods estimated that between 25 and 40 states had actual (ILI-)symptomatic case counts above 10 times the reported counts, depending on the method (Figs. 1 and 2). Up to 12 states had at least one adjusted estimate above 50 times the reported counts, with three of them above 100 times the reported counts (Nebraska, Oregon, Missouri). Furthermore, our methods suggest that places with low official case counts, such as Alaska, Wyoming, Montana, and North Dakota, experienced significantly more COVID-19 cases than reported. Even places with high official case counts, such as Georgia, Pennsylvania, and Texas, appeared to be significantly under-reporting. As expected, our methods computed high estimates in New York and New Jersey, locations with especially high numbers of confirmed cases. Extending mMAP to May 16, 2020 indicates that up to 37 locations have estimated case counts above five times the reported counts, with four locations over 10 times (Louisiana, Connecticut, Michigan, and New York City).
Using the unadjusted methods, div-IDEA, div-Vir and COVID Scaling yield significantly higher estimates than mMAP (median estimates of 85k, 157k, and 74k compared to 11k and mean estimates of 377k, 430k, and 327k compared to 140k for the locations that have estimates for all methods). However, while using the adjusted methods, the estimates are more similar (median estimates of 37k, 77k, and 101k compared to 29k and mean estimates of 188k, 233k, and 322k compared to 371k), providing support that the adjusted methods are more accurate than the unadjusted ones.
All four methods generally agree on the ordering of states by (ILI-)symptomatic case count (Table 1), with rank correlations of the adjusted methods ranging from 0.57 to 0.97. mMAP has an especially high correlation with the reported case counts, which is likely because official COVID-19 deaths and positive COVID-19 cases represent overlapping pools of patients and are therefore subject to similar biases. The other methods, however, rely on aggregate data from ILINet, which may cover a different set of patients. COVID Scaling also shows a relatively high correlation with the reported cases, which may reflect the use of COVID-19 test statistics in its model.
Pairwise Spearman correlations between adjusted methods and reported case counts from March 1, 2020 to April 4, 2020 across the state level.
The mMAP estimates for New York City (NYC) are high, ranging from 1.1m to 2.3m symptomatic cases and 1.9m to 3.9m symptomatic and asymptomatic cases by April 26 (Figs 1 and 3 just show symptomatic cases). This is higher than the estimated serological incidence of 1.5m by April 28 [25]. One explanation for the high mMAP estimates for NYC is that NYC began reporting probable COVID-19 deaths (as in, not needing a test result) as confirmed deaths [26], resulting in 5,295 (42%) more deaths reported as of April 29 [27]. Another possibility is that the fatality rate was higher in NYC than other places over the time period studied because of hospital over-crowding and limited access to care.
3 Discussion
We present four methods based on three distinct approaches to estimate the COVID-19 (ILI-)symptomatic incidence across the United States. The methods are complementary, in that they rely on different assumptions and use diverse datasets. Despite their clear differences, these methods estimate that the likely COVID-19 cumulative (ILI-)symptomatic incidence varies from 5 to 50 times higher, at the state level, than what has been reported so far in the U.S. By providing ranges of estimates, both within and across models, our suite of methods offers a robust picture of the uncertainty in state-level COVID-19 case counts. When making public health decisions to respond to COVID-19, it is important to account for the uncertainty in estimates of symptomatic incidence; the multiple estimates presented here provide a better picture of this than single point estimates.
While our methods estimate the number of COVID-19 cases at symptom onset, it is possible that the ILI-based approaches might lag a few days behind because of the delay between symptom onset and ILI visit dates. Our methods are also not designed to estimate pre-symptomatic patients. Both of these factors could indicate potentially higher true incidence than estimated by our methods. We note that our estimates are specifically for symptomatic cases, while a high proportion of COVID-19 cases are believed to be asymptomatic [6, 7]. To estimate total cases, our counts can be adjusted by the proportion of symptomatic cases. For example, if 50% of cases are asymptomatic, this could indicate a total cumulative incidence of up to 24 million as of May 16, 2020.
Our approaches could be expanded to include other data sources and methods to estimate incidence, such as Google searches [28, 29, 30], electronic health record data [31], clinician’s searches [32], and/or mobile health data [33]. Accurate and appropriately-sampled serological testing would provide the most accurate estimate of incidence and would be useful for public health measures, especially when attempting to relax current shelter-in-place recommendations. In addition, appropriately-designed studies based on serological testing could be used to evaluate the reliability of the methods presented in this study. This could inform prevalence estimation methods for COVID-19 in other countries as well as for future pandemics. The ILI-based methods presented in this study demonstrate the potential of existing and well-established ILI surveillance systems to monitor future pandemics that, like COVID-19, present similar symptoms to ILI. This is especially promising given the WHO initiative launched in 2019 to expand influenza surveillance globally [34]. Incorporating estimates from influenza and COVID-19 forecasting and participatory surveillance systems may prove useful in future studies as well [35, 36, 37, 38, 39, 40].
Limitations
Since the Divergence and COVID Scaling approaches are estimated using ILINet statistics, their symptomatic incidence estimates are dependent on the ILI definition of a fever and cough or sore throat. Thus, they may miss a percentage of COVID-19 patients that are symptomatic without meeting the ILI definition. With this limitation, the reported estimates may serve as an approximate lower bound. Given a clearer understanding of COVID-19 symptoms, our Divergence and COVID Scaling estimates could be adjusted upward by the proportion of symptomatic to ILI-symptomatic patients.
The uncertainty and bias of each individual method should be considered carefully. The Divergence methods suffer from the same challenges faced when attempting to scale CDC-measured ILI activity to the entire population [41]. In particular, scaling to case counts in a population requires estimates for p(visit), the probability that a person seeks medical attention for any reason, and p(visit | ILI) which captures health care seeking behavior given that a person is experiencing ILI; these estimates are likely to change over time, especially during the course of a pandemic. Moreover, the weekly symptomatic incidence estimates from this method decrease towards the end of March, perhaps caused by a change in health care seeking behavior after the declaration of a national emergency on March 13, 2020 and the widespread implementation of shelter-in-place mitigation strategies. It is also important to note that ILI based methods are expected to be accurate only while ILI surveillance systems are operating normally (reporting tends to decrease outside of the flu season) and only while the outbreak has not yet overwhelmed hospitals and doctors. As a result, we use ILI based methods to estimate COVID-19 symptomatic incidence only early in the outbreak. Figure 4 shows the underlying influenza surveillance data for the last five seasons. We note a sharp decrease in the total number of reported patients in late March 2020 even though the number of providers did not decrease more than is usually expected. This suggests that the ILINet signal may no longer be reliable until regular reporting patterns return. In late April the number of positive influenza tests neared zero while the total number of influenza tests has not (yet) decreased more than usual, suggesting that COVID-19 is causing a larger than usual number of negative influenza tests.

The underlying influenza surveillance data for the last five seasons. The top subplot shows the ILINet total number of patients and participating providers. The bottom subplot shows the total reported numbers of influenza tests conducted and positive influenza tests.
COVID Scaling relies on the assumption that COVID-19 positive test proportions uniformly represent the pool of all ILI patients and that shortages in testing do not bias the positive proportion upward or downward. Finally, mMAP is limited by assumptions of the symptomatic case fatality rate, the distribution of time from case onset to death, and accurate reporting of COVID-19 deaths (or in the case of adjusted mMAP, that excess pneumonia deaths capture all unreported COVID-19 deaths). It is possible that many deaths caused by COVID-19 are not being officially counted as COVID-19 deaths because of a lack of testing (and that accounting for increased pneumonia deaths does not fully capture this) [42]. In New York City, for example, probable COVID-19 deaths (as in, not needing a test result) are being reported as COVID-19 deaths and accounted for a 42% increase in cumulative COVID-19 death counts as of April 29, 2020 [27]. Under-reporting of deaths may explain why mMAP sometimes yields lower case estimates than Divergence and COVID Scaling even though its symptomatic case definition is more inclusive. A high-level summary of the three methods, their estimation strategy, and their assumptions are provided in Table 2.
Comparing the three approaches to estimate COVID-19 cases in the US.
4 Conclusions
We have presented three complementary approaches for estimating the true COVID-19 cumulative (ILI-)symptomatic incidence in the United States from March 1 to May 16, 2020 at the national, state, and city (New York City) levels. The approaches rely on different datasets and modeling assumptions in order to balance the inherent biases of each individual method. While the case count estimates from these methods vary, there is general agreement among them that the actual state-level symptomatic case counts up to April 4, 2020 were likely 5 to 50 times greater than what was reported. Up to May 16, 2020, most states likely had 5 to 10 times more cases than reported, with a total estimated range of 6.0 million to 12.2 million cases over the United States.
A more accurate picture of the burden of COVID-19 is actionable knowledge that will help guide and focus public health responses. Inevitably, as social distancing measures are relaxed, there will be a resurgence in cases. If the true case counts are near the upper bound of our estimated counts, then a substantial proportion (up to 4%) of the US population may have already been infected. Factoring in asymptomatic cases could increase the proportion up to 8%. In such a scenario, the population in some locations may be closer to herd immunity than previously anticipated, and we may expect that subsequent waves of infection will eventually decrease in magnitude. On the other hand, it is evident that the large majority of the population has not yet been exposed to COVID-19, and therefore effective, informed public health responses to future upsurges in cases will be essential in the upcoming months.
5 Data and Methods
CDC ILI and Virology
The CDC US Outpatient Influenza-like Illness Surveillance Network (ILINet) monitors the level of ILI circulating in the US at any given time by gathering information from physicians’ reports about patients seeking medical attention for ILI symptoms. ILI is defined as having a fever (temperature of 37.8+ Celsius) and a cough or a sore throat. ILINet provides public health officials with an estimate of ILI activity in the population but has a known availability delay of 7 to 14 days. National level ILI activity is obtained by combining state-specific data weighted by state population [12]. Additionally, the CDC reports information from the WHO and the National Respiratory and Enteric Virus Surveillance System (NREVSS) on laboratory test results for influenza types A and B. The data is available from the CDC FluView dashboard [11]. We omit Florida from our analysis as ILINet data is not available for Florida.
COVID-19 Case and Death Counts
The US case and death counts are taken from the New York Times repository, which compiles daily reports of counts at the state and county levels across the US [43]. For the mMAP validation in the supplementary materials, the case and death counts from other countries are taken from the John’s Hopkins University COVID-19 dashboard [44]. Counts are taken up until May 28, 2020.
COVID-19 Testing Counts
In addition, daily time series containing positive and negative COVID-19 test results within each state were obtained from the COVID Tracking Project [45].
US Demographic Data
The age-stratified, state-level population numbers are taken from 2018 estimates from the US census [46].
5.1 Approach 1: Divergence
Viewing COVID-19 as an intervention, this approach aims to construct control time series representing the counterfactual 2019-2020 influenza season without the effect of COVID-19. While inspired by the synthetic control literature [47, 48], we are forced to construct our own controls since COVID-19 has had an effect in every state. We formulate a control as having the following two properties:
The control produces a reliable estimate of ILI activity, where ILI refers to the symptomatic definition of having a fever in addition to a cough or sore throat.
The control is not affected by the COVID-19 intervention (that is, the model of ILI conditional on any relevant predictors is independent of COVID-19).
We construct two such controls, one model-based and one data-driven.
5.1.1 Method 1: Incidence Decay and Exponential Adjustment Model
The Incidence Decay and Exponential Adjustment (IDEA) model [20] is a single equation epidemiological model that estimates disease incidence over time early in an outbreak while accounting for control activities and behaviours. The model is as follows:
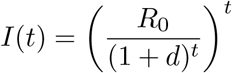 where I(t) is the incident case count at serial interval time step t. R0 is the basic reproduction number, and d is a discount factor modeling reductions in the effective reproduction number with time due to public health interventions, changes in public behavior, environmental factors, and the depletion of susceptible hosts. The IDEA model has been shown to be identical to Farr’s law for epidemic forecasting and can be expressed in terms of a susceptible-infectious-removed (SIR) compartmental model with improving control [49].
where I(t) is the incident case count at serial interval time step t. R0 is the basic reproduction number, and d is a discount factor modeling reductions in the effective reproduction number with time due to public health interventions, changes in public behavior, environmental factors, and the depletion of susceptible hosts. The IDEA model has been shown to be identical to Farr’s law for epidemic forecasting and can be expressed in terms of a susceptible-infectious-removed (SIR) compartmental model with improving control [49].
We fit the IDEA model to ILI case counts from the start of the 2019-2020 influenza season to the last week of February 2020. The start of the 2019-2020 influenza season is defined in a location specific manner as the first occurrence of two consecutive weeks with ILI activity above 2%. Model fitting is done using non-linear least squares with the Trust Region Reflective algorithm as the optimizer. Next, the model is used to predict what ILI would have been had the COVID-19 pandemic not occurred. In other words, we use the IDEA model ILI estimates as the counterfactual when assessing the impact of the COVID-19 intervention. When fitting the IDEA model, we use a serial interval of half a week, consistent with the serial interval estimates from [50] for influenza. We note that serial interval estimates from [51] for COVID-19 as well as from [52] for SARS-CoV-1 are longer than that of influenza, but that is not an issue as we use IDEA to model ILI.
5.1.2 Method 2: Virology
As an alternative control to the IDEA model, we also present an estimator of ILI activity using influenza virology results. As suggested by [18], there has been a divergence in March between CDC measured ILI activity and the fraction of ILI specimens that are influenza positive. Clinical virology time series were obtained from the CDC virologic surveillance system consisting of over 300 laboratories participating in virologic surveillance for influenza through either the US WHO Collaborating Laboratories System or NREVSS [12]. Total number of tests, total influenza positive tests, and percent positive tests are our variables of interest.
None of the three time series satisfy both properties of a valid control, as defined in 5.1, since total number of tests is directly susceptible to increase when ILI caused by COVID-19 is added. Similarly, percent positive flu tests may decrease when COVID-19 is present. On the other hand, total positive flu tests satisfies property 2, but is not a reliable indicator of ILI activity (property 1) on its own because it is highly dependent on the quantity of tests administered.
We propose a modification that satisfies the properties. Let 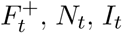 denote positive flu tests, total specimens tested, and ILI visit counts respectively. In addition, let Ft be the true underlying flu counts. For any week t we assume the following relation:
denote positive flu tests, total specimens tested, and ILI visit counts respectively. In addition, let Ft be the true underlying flu counts. For any week t we assume the following relation:
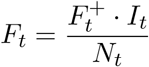
There are two interpretations of this quantity: 1) It extrapolates the positive test percentage 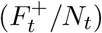 to all ILI patients (It), a quantity known in the mechanistic modeling literature as ILI+ [53]. 2) Test frequency is a confounder in the relationship between the number of positive tests (F+) and total flu (Ft). Adjusting for test frequency closes the indirect pathway between Ft and
to all ILI patients (It), a quantity known in the mechanistic modeling literature as ILI+ [53]. 2) Test frequency is a confounder in the relationship between the number of positive tests (F+) and total flu (Ft). Adjusting for test frequency closes the indirect pathway between Ft and 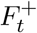 [54]. In the Supplementary Material, we demonstrate over a series of examples that this estimator behaves as desired. Each estimate of Ft is then scaled to population ILI cases using least squares regression over pre-COVID-19 ILI counts.
[54]. In the Supplementary Material, we demonstrate over a series of examples that this estimator behaves as desired. Each estimate of Ft is then scaled to population ILI cases using least squares regression over pre-COVID-19 ILI counts.
In other words, we first use virology data to estimate Ft (actual flu cases causing ILI) as percent ILI visits times percent positive for flu. Then, modeling ILI visits (It) as an affine function of Ft in a normal (without COVID-19) situation, we use 2019 pre-COVID-19 data to map Ft to It. This allows us to estimate the divergence after the COVID-19 intervention occurs.
5.1.3 ILI Case Count Estimation
In order to fit the IDEA and virology models, we estimate the ILI case count in the population from the CDC’s reported percent ILI activity, which measures the fraction of medical visits that were ILI related.
In a similar fashion to the approach of [41], we can use Bayes’ rule to map percent ILI activity to an estimate of the actual population-wide ILI case count. Let p(ILI) be the probability of any person having an influenza-like illness during a given week, p(ILI | visit) be the probability that a person seeking medical attention has an influenza-like illness, p(visit) be the probability that a person seeks medical attention for any reason, and p(visit | ILI) the probability that a person with an influenza-like illness seeks medical attention. Bayes’ rule gives us
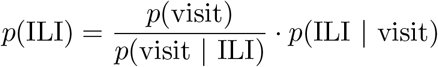
p(ILI | visit) is the CDC’s reported percent ILI activity, for p(visit) we use the estimate from [41] of a weekly doctor visitation rate of 7.8% of the US population, and for p(visit | ILI) we use a base estimate of 27%, consistent with the findings from [23]. Once p(ILI) is calculated, we multiply p(ILI) by the population size to get a case count estimate within the population.
5.1.4 Visit Propensity Adjustment
We note that health care seeking behavior varies by region of the United States as shown in [23]. To better model these regional behavior differences, we adjust p(visit | ILI), the probability that a person with an influenza-like illness seeks medical attention, using regional baselines for the 2019-2020 influenza season [12].
Additionally, because our method estimates the increase in ILI visits due to the impact of COVID-19, we must distinguish an increase due to COVID-19 cases from an underlying increase in medical visit propensity in people with ILI symptoms. Due to the widespread alarm over the spread of COVID-19, it would not be unreasonable to expect a potential increase in ILI medical visits even in the hypothetical absence of true COVID-19 cases.
For this reason, we also explore increasing p(visit | ILI) from 27% to 35% to measure the possible effect of a change in health care seeking behavior due to COVID-19 media attention and panic. The increase of p(visit | ILI) to 35% is consistent with health care seeking behavior surveys done after the start of COVID-19 [21, 22]. The Divergence and COVID Scaling methods have adjusted versions which incorporate this shift as well as unadjusted versions that keep the baseline 27% propensity.
5.1.5 Estimating COVID-19 Case Counts
The ultimate goal is to estimate the true burden of COVID-19. The IDEA and virology predicted ILI case counts can be used to estimate CDC ILI had COVID-19 not occurred. In other words, the IDEA and virology predicted ILI can be used as counterfactuals when measuring the impact of COVID-19 on CDC measured ILI. The difference between the observed CDC measured ILI and the counterfactual (IDEA predicted ILI or virology predicted ILI) for a given week is then the estimate of COVID-19 ILI-symptomatic case counts for that week. Fig. 5 shows example observed CDC measured ILI, IDEA model predicted ILI, and virology predicted ILI. The supplementary materials contain similar plots to Fig. 5 for all locations. For this method as well as the following two, we start estimating COVID-19 case counts the week starting on March 1, 2020. We note that while the IDEA and virology ILI predictions tend to track CDC ILI well earlier in the flu season, after COVID-19 started to impact the United States there is a clear divergence between predictions and observed CDC ILI, with CDC ILI increasing while the counterfactual estimates decrease.

COVID-19 is treated as an intervention, and we measure COVID-19 impact on observed CDC ILI, using IDEA model predicted ILI and virology predicted ILI as counterfactuals. The difference between the higher observed CDC ILI and the lower IDEA model predicted ILI and virology predicted ILI is the measured impact of COVID-19. The impact directly maps to an estimate of COVID-19 ILI-symptomatic case counts. Virology predicted ILI is omitted when virology data is not available. We note that this method is meaningful only at the beginning of the outbreak (March 2020), while ILI surveillance systems are still fully operational and before they are impacted by COVID-19. The disappearance of the divergence does not mean that the outbreak is over, but rather that the ILI signal is no longer reliable.
This method is expected to be accurate only while ILI surveillance systems are operating normally (reporting tends to decrease outside of the flu season) and only while the outbreak has not yet overwhelmed hospitals and doctors. As a result, we use ILI based methods to estimate COVID-19 symptomatic incidence only early in the outbreak, until April 4th. The disappearance of the divergence does not mean that the outbreak is over, but rather that the ILI signal is no longer reliable.
5.2 Approach 2: COVID Scaling
This approach infers the COVID-19 fraction of the total ILI by extrapolating testing results obtained from the COVID Tracking Project [45], following the same reasoning as the Virology Divergence method. That is,
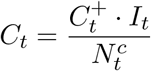 where
where 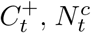 , It denote positive COVID-19 tests, total COVID-19 specimens, and ILI visit counts respectively.
, It denote positive COVID-19 tests, total COVID-19 specimens, and ILI visit counts respectively.
State-level testing results were aggregated to the weekly level and positive test percentages were computed using the positive and negative counts, disregarding pending tests. Positive test counts were adjusted for potential false negatives. There are varying estimates for the false negative rate for the RT-PCR used in COVID-19 tests, with some reports suggesting rates as high as 25-30% [55, 56]. We apply a 15% false negative rate in our analysis; repeating our analysis using a range of values from 5% to 25% yielded little difference in our estimates. On the other hand, COVID-19 testing is highly specific, so we assume no false positives. Then, the number of false negatives (FN) can be computed from the recorded (true) positives (TP) and the false negative rate (fnr) as
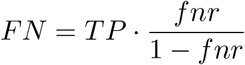
Because COVID-19 testing is sparse in many states, there are issues with zero or low sample sizes, as well as testing backlogs. Rather than taking the empirical positive test percentage 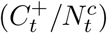 , we first smoothed the test statistics over time by aggregating results over a 2-week slid-ing window. This has a Bayesian interpretation of combining each week’s observed statistics with the prior of the previous week, weighted by relative specimen count. For convenience,
, we first smoothed the test statistics over time by aggregating results over a 2-week slid-ing window. This has a Bayesian interpretation of combining each week’s observed statistics with the prior of the previous week, weighted by relative specimen count. For convenience, 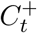 and
and 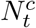 henceforth refer to these respective quantities. We also applied the same process to the ILI information to reduce noise and so that the data are comparable. This helped but did not address all issues with case backlog, so we further smoothed the COVID-19 estimates using a Bayesian spatial model:
henceforth refer to these respective quantities. We also applied the same process to the ILI information to reduce noise and so that the data are comparable. This helped but did not address all issues with case backlog, so we further smoothed the COVID-19 estimates using a Bayesian spatial model:
Denote pjt as the probability that a given ILI patient in state j and week t has COVID-19. Under the condition that testing is applied uniformly, the COVID-19 status of patient i from state j in week t is
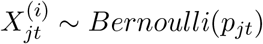
Assuming COVID-19 status is independent in each ILI patient, conditional on the state prevalence, the state testing results follow a Binomial distribution. We apply a spatial prior based on first-order conditional dependence:
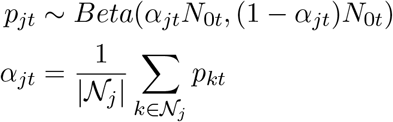 where 𝒩j are the neighbors of state j. The strength of the prior was specified by setting N0t to be the number of total tests at the 5th quantile among all states in each week. Finally, we compute αjt by replacing each pkt by their empirical estimates. Using the Beta-Binomial conjugacy we derive closed-form posterior mean estimates for pjt:
where 𝒩j are the neighbors of state j. The strength of the prior was specified by setting N0t to be the number of total tests at the 5th quantile among all states in each week. Finally, we compute αjt by replacing each pkt by their empirical estimates. Using the Beta-Binomial conjugacy we derive closed-form posterior mean estimates for pjt:
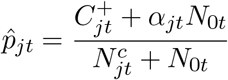
As described previously, the weekly, state-level reported percent ILI were then multiplied by 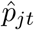 to get an estimate of the percent of medical visits that could be attributed to COVID-19. These values were subsequently scaled to the whole population using the same Bayes’ rule method as described in ILI Case Count Estimation (4.2.3).
to get an estimate of the percent of medical visits that could be attributed to COVID-19. These values were subsequently scaled to the whole population using the same Bayes’ rule method as described in ILI Case Count Estimation (4.2.3).
5.3 Approach 3: Mapping Mortality to COVID-19 Cases
Other studies have introduced methods to infer COVID-19 cases from COVID-19 deaths using (semi-)mechanistic disease models [15] or statistical curve-fitting based on assumptions of epidemic progression [16], but, to the best of our knowledge, no methods have been proposed to directly infer COVID-19 cases without either of these assumptions.
Mortality Map (mMAP) uses, under a Bayesian framework, reported deaths to predict previous true case counts, similar to prior work on influenza [17]. mMAP accounts for right-censoring (i.e. COVID-19 cases that are not resolved yet) by adapting previously used methods [13]. A study of clinical cases in Wuhan found that the time in days from symptom onset to death roughly follows a log-normal distribution with mean 20.2 and standard deviation 11.6 [57]. It also found the mean time from hospitalization to death to be 13.2 days, similar to the estimate of 13.7 from a large cohort study in California [58], suggesting that the timing of disease progression is similar in the United States. Using this distribution, a time series of reported deaths, D, and the age-adjusted symptomatic case fatality rate (sCFR), we estimate the distribution of symptomatic cases C, defined at the usual time of symptom onset, using an iterative Bayesian approach. We use Bayes’ rule to define the probability that there was a case on day t given a death on day τ
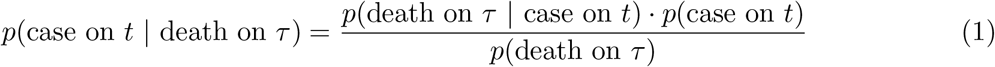
Let 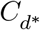 denote the predicted distribution of when D are classified as cases (i.e. are hospitalized), Cd denote the predicted distribution of when D and future deaths are classified as cases (so adjusted for right-censoring), and tmax denote the most recent date with deaths reported. Let p(death on τ | case on t) = p(T = (τ − t)) denote the log-normal probability. mMAP performs the following steps:
denote the predicted distribution of when D are classified as cases (i.e. are hospitalized), Cd denote the predicted distribution of when D and future deaths are classified as cases (so adjusted for right-censoring), and tmax denote the most recent date with deaths reported. Let p(death on τ | case on t) = p(T = (τ − t)) denote the log-normal probability. mMAP performs the following steps:
Initialize the prior probability of a case on day t, p0(case on t), as uniform.
Repeat the following for each iteration i:
Calculate
 .
where the denominator is equivalent to p(death on τ) in (1).
.
where the denominator is equivalent to p(death on τ) in (1).We estimate that the proportion p(T ≤(tmax − t)) of
have died by tmax and use this to adjust for right censoring.
Update prior probabilities
Repeat until
, where ϵ is a pre-specified tolerance level.
Cd(t) represents the number of cases on day t that will lead to death. We scale this to estimate the number of all symptomatic cases by dividing by the sCFR.
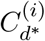
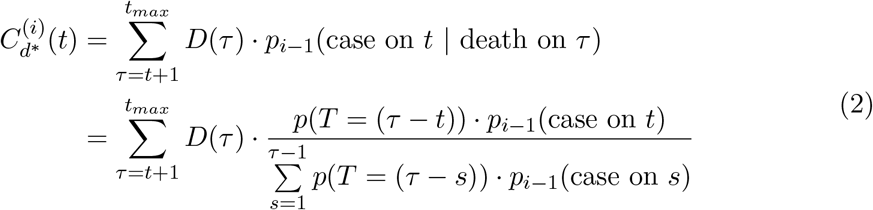
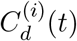
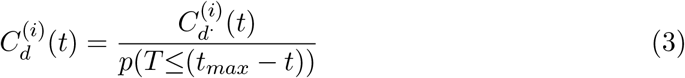
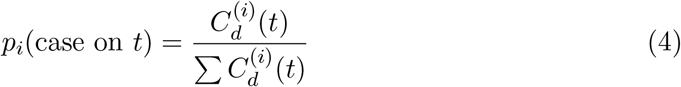
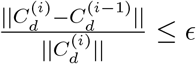

mMAP has connections to expectation-maximization, though further theoretical work is needed to establish the connection. We found that mMAP performs significantly better than using inde-pendent maximum-likelihood based estimates [i.e. solving 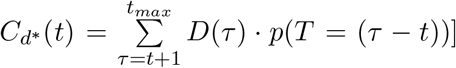 Supplementary section 4.2 demonstrates that mMAP successfully predicts cases in simulated and true scenarios using data from six countries. As well, supplementary section 4.1 demonstrates that if mMAP converges, which it does for every US state, Cd fully explains deaths under the assumed probability distribution (6), and that this satisfies the calculation of the fatality rate as presented in [13].
Supplementary section 4.2 demonstrates that mMAP successfully predicts cases in simulated and true scenarios using data from six countries. As well, supplementary section 4.1 demonstrates that if mMAP converges, which it does for every US state, Cd fully explains deaths under the assumed probability distribution (6), and that this satisfies the calculation of the fatality rate as presented in [13].
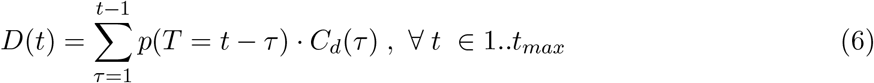
Alternatively, if one were interested in estimating the incidence of all cases – symptomatic and asymptomatic – Cd(t) would need to be divided by the infection fatality ratio (IFR) in step 3 (equation 5). For the sake of comparison with the ILI-based methods in this study, we chose to use sCFR in the denominator in equation 5 to estimate the incidence of just the symptomatic cases. The national sCFR values used are 1.8% and 0.92% for the adjusted method. These values were found by adjusting the IFR estimates (1.1% and 0.55%) with an assumed 40% asymptomatic rate (estimates of the percentage of asymptomatic cases range from 18% [6] to 50% [7, 8]). The first IFR value comes from an analysis of individual case data in China and repatriated Chinese citizens in January and February to estimate the fatality ratio for all — symptomatic and asymptomatic — infections [59]. The second value comes from four serological studies: (1) a study in Germany estimated the IFR to be 0.37% counting deaths up to the day of serological measurement [60]; (2) a study in Switzerland estimated the IFR to be 0.8% counting deaths up to 7-10 days after serological measurement [61, 62]; (3) a study in New York State estimated the IFR to be 0.8% counting deaths up to the first day of serological measurement [25]; and (4) a study in Denmark found that the IFR for people under 70 was around half of what has been reported (0.08% compared to previous reports of 0.14% for people under 60), counting deaths up to the day of serological measurement [63]. While there is a bias towards under-predicting IFR because of the delay of time until death, there is also a bias towards over-predicting IFR due to lower serology test sensitivity for recently acquired infections (18-44% sensitivity for the first five days after symptom onset compared to 82-100% sensitivity 20 days after symptom onset) [64]. Given the results from these four studies, we believe it is reasonable that the IFR could be 0.55%, half of the IFR found in [59], and thus that the sCFR could be 0.92%. The sCFR estimates for each state are adjusted using the age-stratified fatality rate [65] and the population age structure provided by the US census [46].
5.3.1 Accounting for Unreported COVID-19 Deaths
While mMAP assumes all COVID-19 deaths are reported, some deaths will be unreported because of limited testing and false negative results [66, 67]. Previous research on the H1N1 epidemic estimated that the ratio of lab-confirmed deaths to actual deaths caused by the disease was 1:7 nationally [68] and 1:15 globally [69]. While the actual rate of under-reporting is unknown, we include an adjustment, mMAPadj, that uses an estimate of unreported COVID-19 deaths based on reports of excess pneumonia deaths, as has been done in previous studies [66]. mMAPadj assumes that excess pneumonia deaths in March 2020 were due to COVID-19.
The CDC reports weekly pneumonia deaths, DP (w), expected weekly pneumonia deaths based on a model of historical trends, 𝔼[DP (w)], and deaths that are classified as pneumonia and COVID-19, DP∩COV (w) [70, 71]. We estimate that the number of un-classified COVID-19 deaths each week,
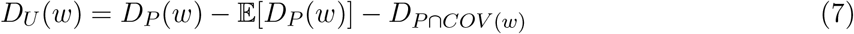
This results in 355, 438, 605, and 540 nationwide excess deaths for the four weeks from March 1 to March 28, which is the most recent data at the time of writing this paper. To account for missing data in recent weeks, We assume that the weekly number of excess deaths remains constant after March 21, i.e. that there were 540 excess deaths the weeks of March 29 - April 4 and April 5 - April 11. Since the expected pneumonia deaths are not available at the state level, excess deaths are calculated nationally and then attributed to each state s in proportion to the number of pneumonia deaths in that state. Then, the weekly excess deaths are evenly distributed across each day of the week.
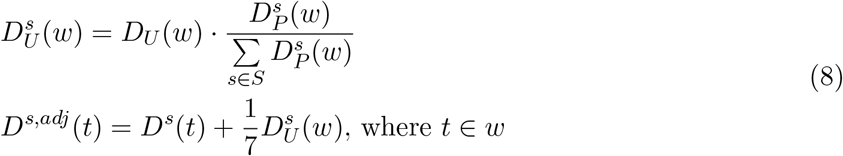
5.4 Aggregation of Estimates
The divergence-based methods predict national COVID-19 symptomatic incidence directly using national ILI data. mMAP predicts national symptomatic incidence using national death data, while COVID Scaling estimates national symptomatic incidence by aggregating the case estimates from each state.
The Divergence and COVID Scaling methods provide separate case estimates for each week within the studied period, which are summed to the total cumulative case estimates. mMAP provides daily estimates which are further aggregated by week.
Data Availability
All data is publicly available.
https://www.census.gov/data/tables/time-series/demo/popest/2010s-state-detail.html
https://gis.cdc.gov/grasp/fluview/fluportaldashboard.html
Contributions, Conflicts of Interest, and Funding
FL, AN, and NL contributed equally to a literature search, figures, study design, data collection, data analysis, data interpretation, and writing. MS contributed to the literature search, study design, data interpretation, and writing. ML contributed to the literature search, data interpretation, and writing.
No conflicts of interest.
MS is partially supported by the National Institute of General Medical Sciences of the National Institutes of Health under Award Number R01GM130668. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Supplementary Materials
Updated mMAP Estimates to May 16, 2020

COVID-19 symptomatic case count estimates from mMAP compared with reported case counts at the national and state levels (and New York City) from March 1, 2020 to May 16, 2020. Cases are presented on a log scale. Adjusted mMAP take into account pneumonia-recorded deaths along with 0.92% estimated sCFR.
Divergence by Location
Figures 2 and 3 show the Divergence method model fits for all available locations. COVID-19 is treated as an intervention, and we measure the impact of COVID-19 on observed CDC ILI, using predictions of ILI from the IDEA model and the virology model as counterfactuals. The impact of COVID-19 is calculated as the difference between the higher observed CDC ILI and the lower IDEA model predicted ILI and virology predicted ILI. The impact directly maps to an estimate of COVID-19 ILI-symptomatic case counts. Virology-predicted ILI is omitted when virology data is not available. We note that model fit quality varies by location. CDC reported ILI activity is plotted in blue, IDEA model predicted ILI is plotted in orange, and virology predicted ILI is plotted in green. We note that this method is meaningful only at the beginning of the outbreak (March 2020), while ILI surveillance systems are still fully operational and before they are impacted by COVID-19. The disappearance of the divergence does not mean that the outbreak is over, but rather that the ILI signal is no longer reliable.

Divergence model fits for first half of locations.

Divergence model fits for second half of locations.
Time Series Plots for All Methods
Figures 4 and 5 show the cumulative estimated counts for each week over the entire study period of March 1, 2020 to May 16, 2020, compared with cumulative reported counts, in each location in the United States. The solid and dotted lines indicate adjusted and unadjusted methods, respectively. Due to the seasonal nature of ILI information, estimates from all methods besides mMAP are limited to April 4, 2020.

Cumulative case time series for first half of locations.

Cumulative case time series for second half of locations.
Virology-based Estimation

Causal DAG affecting flu positive results.
Both the virology-based Divergence model and the COVID Scaling method rely on the extrapolation of positive testing data to the actual symptomatic incidence of the disease. The causal diagram shown in Fig. 6 shows that an individual’s flu test result depends on whether they have the disease, but also whether they receive a test in the first place (by going through the ILI visit path). More broadly, the relationship between test positive results and true disease counts are influenced by testing availability. We approximate the availability using the total administered tests divided by ILI cases. Identical reasoning applies for analysis of COVID-19 cases, as done in the COVID Scaling method.
We formulate a valid control as having the following two properties:
The control produces a reliable estimate of ILI activity.
The control is not affected by the COVID-19 intervention (that is, the model of ILI conditional on any relevant predictors is independent of COVID-19).
In Table 1, we show that the total positive tests divided by the availability satisfies both properties and successfully estimates the true flu counts (in the perfectly distributed case) even when a surge of COVID-19 cases is added.
Series of examples showing that the proposed estimator predicts flu cases correctly even when potential COVID-19 is added.
Mortality-MAP Analysis
5.1 Proof of Case Recovery Given Convergence
In this section we will prove that if mMAP converges, which it does for every location in this analysis, the cases predicted by mMAP, Cd, fully recover deaths. That is that
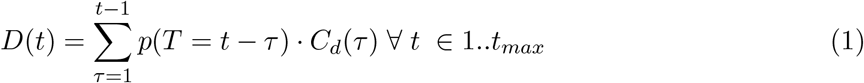
First, note that
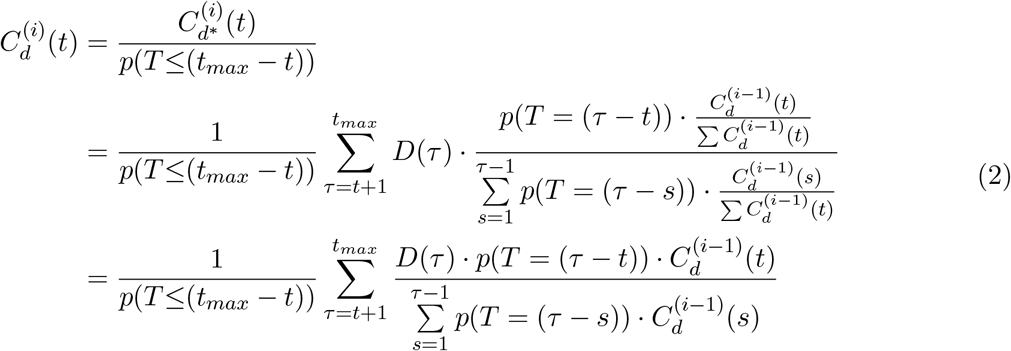
Assuming mortality-MAP converges,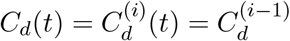 , so
, so
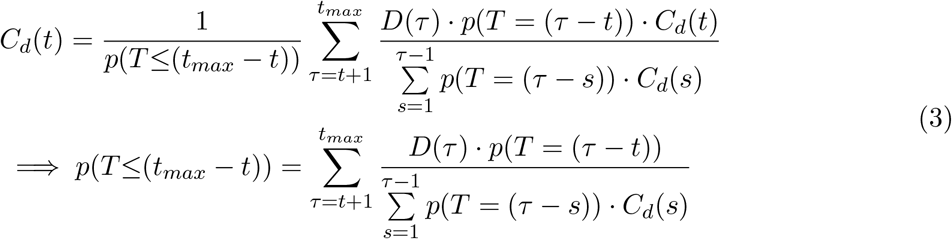
(1) can be shown by induction. First, we will show that it holds for t = tmax − 1 and then show that if it is true for ti+1 then it must be true for ti.
Setting t = tmax − 1, from (3) we see that
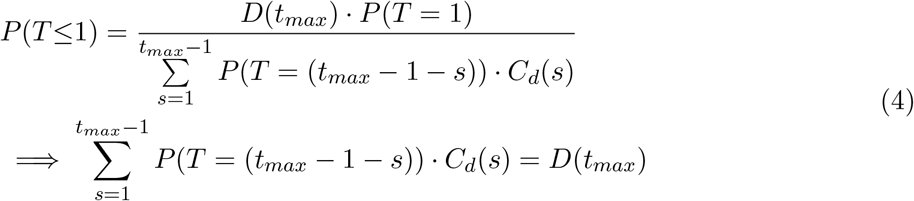 since P (0) = 0, P (T = 1) = P (T ≤1). Thus, (1) holds for t = tmax − 1. Now, assume (1) is true for all t > ti. From (3),
since P (0) = 0, P (T = 1) = P (T ≤1). Thus, (1) holds for t = tmax − 1. Now, assume (1) is true for all t > ti. From (3),
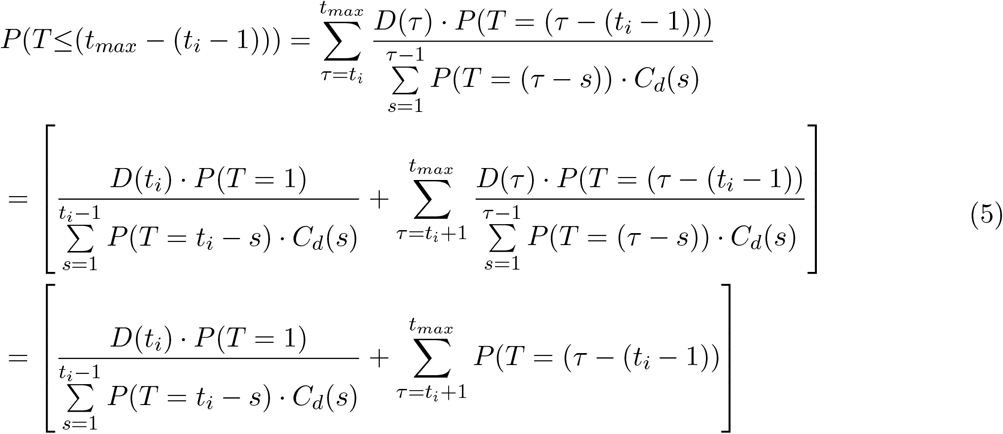
In the final step, D(τ) and the denominator cancel out because (1) is true for all t > ti. Subtracting probabilities from both sides we end up with.
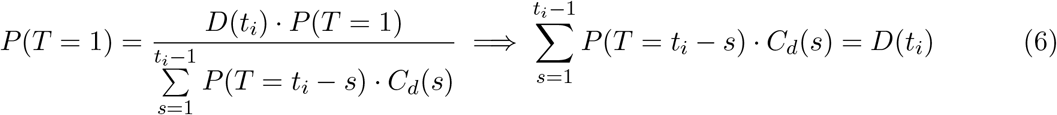
Therefore, (1) is true for ti and by induction is true for all t < tmax. Note that Cd is not a unique solution to the equation; since there are more potential days of cases than reported deaths this system is not full rank and there are infinite solutions (if Cd is allowed to be continuous). This result shows that at least the current estimate of Cd sensibly predicts the reported deaths. The next section demonstrates that this estimate of Cd does seem to be accurate for simulated and empirical data.
5.2 Satisfying Case Fatality Ratio Calculation
The authors of [1] propose an unbiased estimator of the case fatality rate as the following. In this study we are using the symptomatic case fatality ratio (sCFR), so here we define C as the total symptomatic infections.
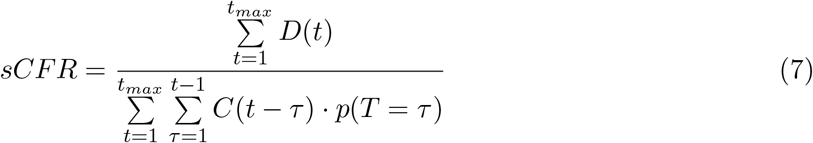
Note that the notation from the paper referenced is adapted to match the notation here, and that here P(T=0) so the summation limits are adjusted. We can show that the results from (1) satisfy this calculation of sCFR by showing that from our estimates of C, the RHS above equals the LHS. Note that in our formulation of C, Cd = sCFR · C, since Cd is the time series of cases that end up in death, and C is the time series of all symptomatic cases.
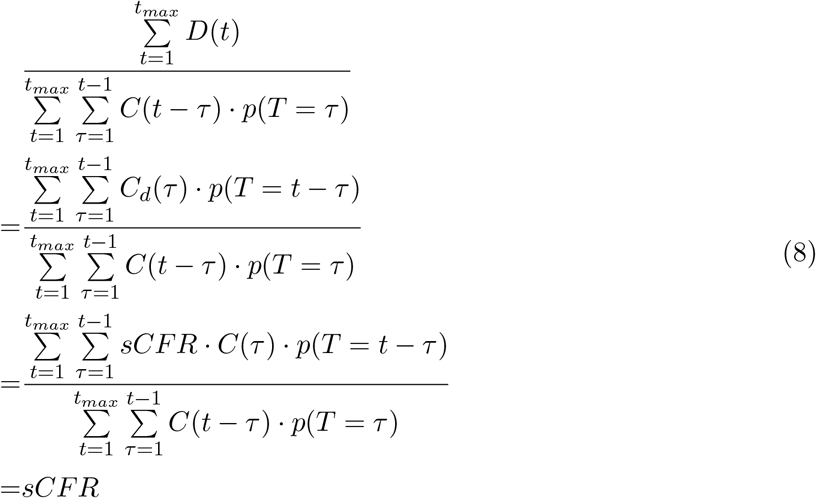
To see that the numerator and denominator cancel out, substitute j = t − τ into the denominator. This demonstrates that our method converges to solutions that match previously researched formulations. Dependent on assumptions of accurate death reporting, the sCFR, and distribution of time from symptom onset to death, this method can accurately predict the unobserved symptomatic case time series.
5.3 Simulated and Empirical Validation
To validate mMAP, it was analyzed using simulated and real death data until June 7 from six countries: United States, China, Italy, Spain, Germany, and South Korea. Figure 7 compares mMAP predicted cases with reported cases. To visually scale the reported cases, the following equation is used:
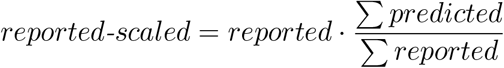
While the scales differ, the trends of predicted cases generally follow the trends of reported cases, especially in Italy, Germany, and South Korea. In the United States, Italy, and Spain, the differences could be a result of increasing case detection around the start of April; as testing increases, we would expect to see more of a relative increase in reported cases than in reported deaths (because we would likely be picking up more of the less severe cases), which would cause the reported cases to increase more steeply than mMAP predictions.
In figure 8, the deaths for each country are simulated from the reported cases. Deaths are stochastically simulated from the reported cases using the log-normal distribution from symptom onset to death and an sCFR of 0.01. From the simulated deaths, mMAP predicts the original cases. As demonstrated by the proof in section 2.1, mMAP recovers cases on convergence (note it does not completely recover cases here because of the randomness of the simulation).
Both plots offer validation that mMAP can successfully predict the trend of the reported cases. However, these plots do not demonstrate if the scale of mMAP predictions are on target, as this is influenced by the under-reporting of deaths and the sCFR.

mMAP predictions compared to reported cases.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Simulated mMAP predictions compared to reported cases.
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].↵
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].↵
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].↵
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵
- [65].↵
- [66].↵
- [67].↵
- [68].↵
- [69].↵
- [70].↵
- [71].↵
References
- [1].↵




