3.1. Results of the Cluster Analysis of R(t)-Curves
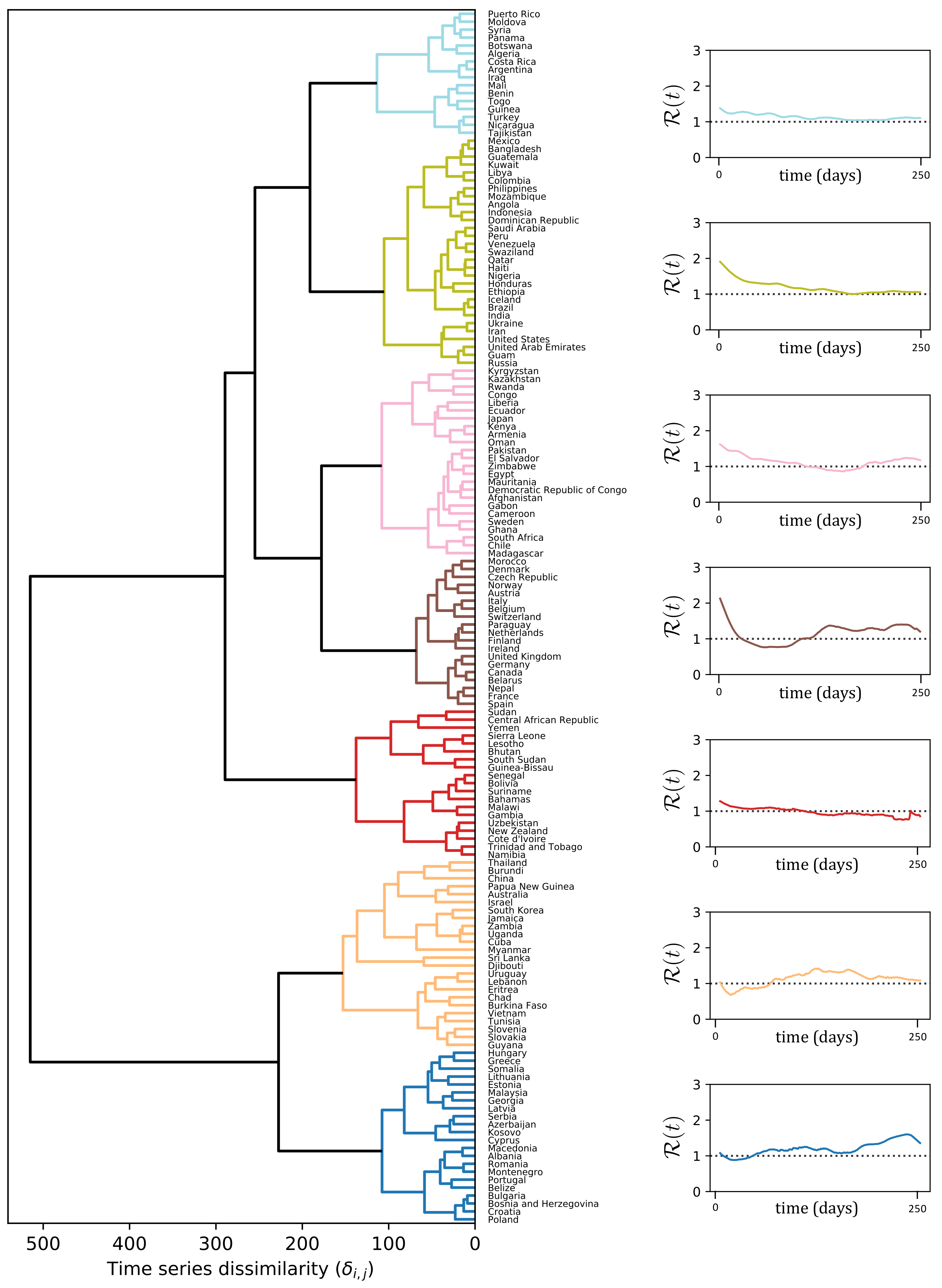
The dendrogram to the left of
Figure 3 depicts the result of the clustering procedure, based on the DTW dissimilarities between the
-curves estimated according to Equation (
9). In particular, the dendrogram illustrates how two leaves
i,
j (i.e., the
-curves of countries
i and
j) are merged together as soon as the threshold
becomes larger than their DTW dissimilarity value
. There is no unique way of selecting an optimal
, but it rather depends on what level of resolution of the clustering partition is amenable for a meaningful exploration of the structure underlying our data. In our case, we selected a
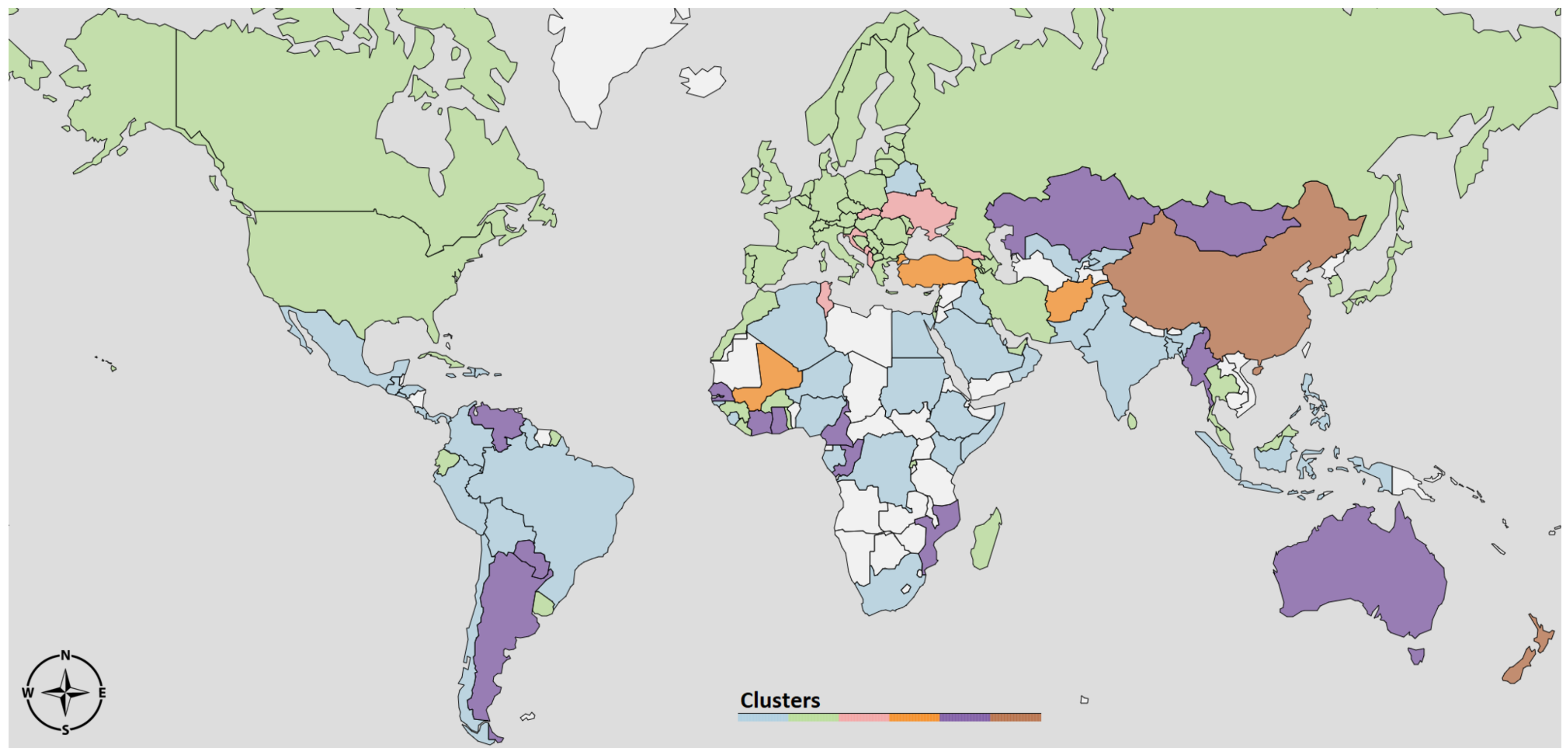
that gave rise to seven clusters, depicted in different colors in
Figure 3. On the right hand side of
Figure 3, we report
averaged over all the countries in the same cluster. To facilitate the interpretation of the results, in
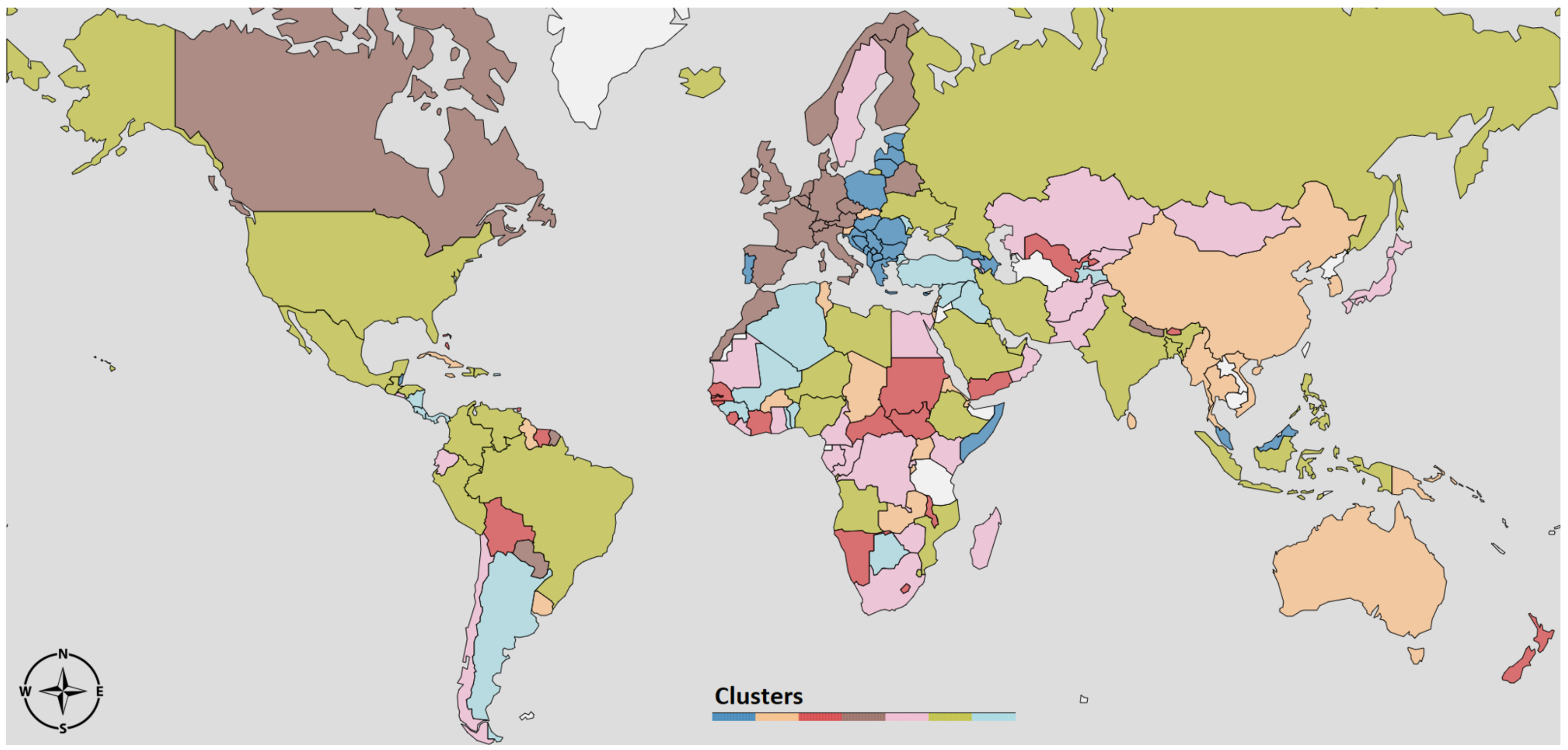
Figure 4 we depict the same clustering partition obtained for
on the political world map.
The 1st cluster (light blue) contains countries mostly from Africa, South America and Middle East. The average
curve of the countries in the light blue cluster (top-right of
Figure 3) shows that the reproduction number is always very low, but consistently above one. A possible explanation is that in those countries communities are more isolated and there are less travels and exchanges between them, making the infection to spread slower.
In 2nd cluster (green) the average curve also stays always above one, but it starts from a higher value . It is important to notice that this cluster includes large countries, such as India, Brazil, United States and Russia. In these countries, the time series of new cases have a particular profile since they are a combination from widely separated areas where the infection outbreak followed different courses. For instance, in the U.S., the waves in New York and California are almost in opposite phase.
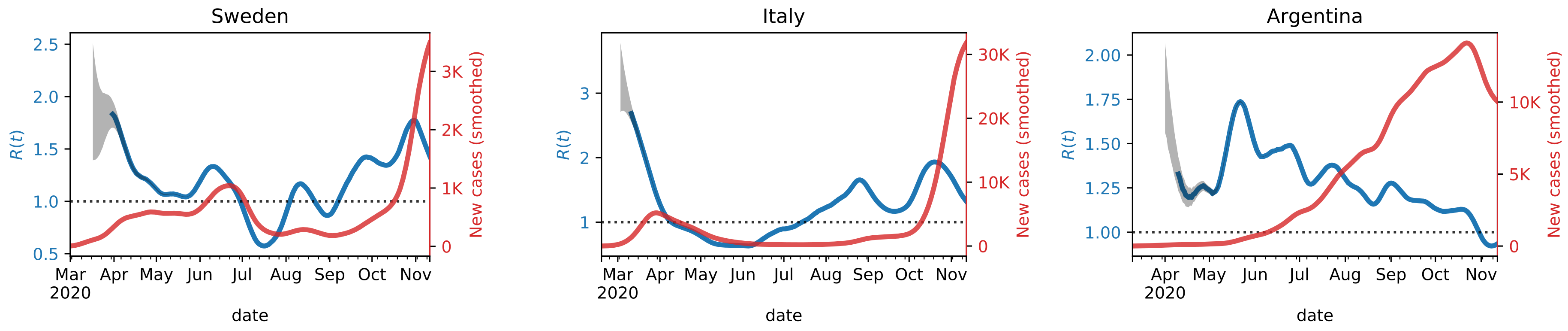
The 3rd cluster (pink) contains countries where the first wave is very long and it took a considerable amount of time to bring the curve below 1. A second wave is slowly emerging in the Northern autumn. An atypical member of this cluster is Sweden, which experienced a second wave in the summer that appeared almost as a continuation of the first wave, and then a strong third wave in the fall that is synchronous with the second wave for the rest of Western Europe (cluster 4).
The 4th cluster (brown) mostly contains Western European countries, characterized by a strong first wave that was brought down quickly and a second wave that begun in the fall. The average curve is characterized by strong variability: it starts from a very high value and goes quickly below 1, to raise again quickly in the summer.
As with the 1st cluster, the 5th cluster (red) contains South American, African countries, and New Zealand. However, a key difference from 1st cluster is that in this case the curve goes and remains below 1 during the Northern fall and autumn.
Finally, clusters 6 and 7 differ from the others by exhibiting initial
close to, or even lower than, one. For some countries in Cluster 6 this is an artifact of the averaging over all the countries in the cluster which includes some countries such as China, Australia, and South Korea, which started out with quite high
, but brought it down very rapidly through strong interventions [
11]. The common characteristic feature for the cluster is an
above 1 during the Northern summer, but a reduction in the fall, which is the opposite of what was observed in Western Europe and Canada. Cluster 7, on the other hand, contains most East-European countries, where the reproduction number was very low during the spring, but increased rapidly after the summer.
3.2. Exploring the Parameter Space of the Oscillator Model
The data for the incidence rate
in the world’s countries show a wavy pattern consisting of one to three maxima during the first year of the pandemic evolution. However, the duration, relative strength, and separation between the waves vary substantially among countries and regions of the world. The total cumulative number of confirmed cases and deaths per million inhabitants can also vary by an order of magnitude or more among countries comparable to economic development, culture, and the healthcare system. Rypdal and Rypdal [
12] demonstrated this for the first wave of the pandemic in a sample of 73 countries and discussed the significant differences in death toll between the two neighboring countries, Sweden and Norway. At the time of writing this paper, we are four months further into the pandemic. The picture has changed dramatically, with secondary and tertiary waves developing in many countries.
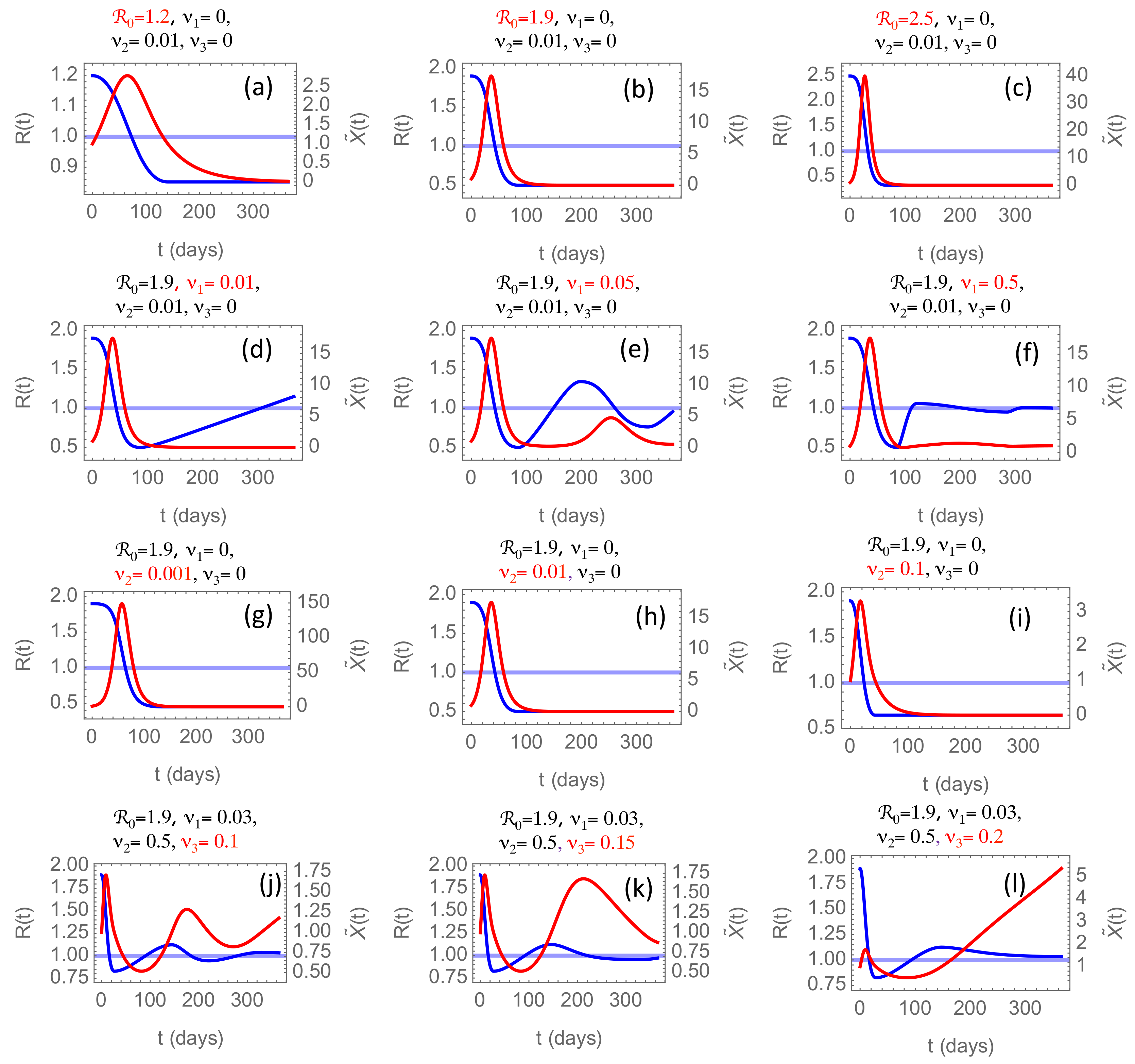
In
Figure 5, we have summarized some of the conclusions drawn from numerical solutions of the model proposed in
Section 2.4, obtained by varying the model parameters. In all simulations, we have chosen the time origin
to be the first time the incidence rate
crosses the threshold value
. Hence,
for all simulations. The incidence rate measured on the right-hand axis in the figures is measured in units of the threshold
.
3.2.1. The Effect of the Initial Reproduction Number
In the first row of panels,
Figure 5a–c, we consider the effect of changing the initial reproduction number
. From the reconstructed
-curves, we observe that
varies considerably among countries and regions. Low values just above
are common in developing countries in South America, sub-Sahara Africa, and India. Several factors may contribute to this; lower mobility of people, a younger population, and a warmer climate. For these countries, we typically observe a slower rise and decay of the first wave, and the wave is generally weaker than in industrialized countries where
varies in the range 2.0–2.5. In
Figure 5a–c, we have changed
, keeping
,
,
constant. By choosing
, and
we consider countries that respond slowly to an incidence rate below the threshold and show little fatigue, which may be characteristic for developing countries for which
Figure 5a may be relevant. In these panels, the choice
is somewhat arbitrary but yields a rather stretched-out and low-amplitude first wave typical for those countries. For higher
, the first wave is higher in amplitude and shorter, like what we have seen in China. Here
signify that the relaxation rate and fatigue have been sufficiently low to prevent
from increasing after it has stabilized below 1. The maximum incidence rate
in panels (b) and (c) is high; in the range 15–40. In panel (i), where the parameters are the same as in (b) except for
being ten times higher, shows
, which, as we will see later, is representative for China.
3.2.2. The Effect of the Relaxation Rate
In the second row, we vary the relaxation rate while keeping the strike-down rate fixed at . The result is that as drops below the threshold after about 45 days, starts to rise and grow well beyond 1. How fast this happens, depends on . In the phase when , will also start growing, and when it crosses the threshold , the strike-down sets in again, and we enter a new cycle. With the first cycle takes almost 500 days, while it takes considerably less time in most countries, suggesting a higher . In panel (e) we increase by a factor 5 and observe then two cycles within the first year, and in panel (f) another increment by a factor 10 almost eliminates the next waves. This faster relaxation to the equilibrium when the relaxation rate is high may appear counter-intuitive. After all, it leads to a rapid increase of once has dropped below the threshold. However, the faster rise of also leads to a faster rise of X beyond the threshold and to a faster strike-down of back towards 1, i.e., to faster damping of the oscillation. This observation suggests that the strong second wave of the epidemic evolving in Europe in the fall of 2020 is not caused by the relaxation of social interventions during the summer but is caused by something else.
3.2.3. The Effect of the Intervention Rate
A suspected candidate could be the intervention rate , which is varied in the third row, panels (g)–(i). However, we observe that the main effect of increasing is to decrease the amplitude of the oscillation in in inverse proportion to . In this row, we have kept , resulting in relaxation to a time-asymptotic () equilibrium , . This is in contrast to the second row (), where this equilibrium is , . These two equilibria correspond to fundamentally different strategies to combat the epidemic. The one without the relaxation mechanism () corresponds to the strike-down strategy, where the goal is to eliminate the pathogen without obtaining herd immunity in the population. The one with , allowing relaxation of interventions when the incidence rate dips below the threshold, will end up with a constant incidence rate at the threshold value and thus a linearly increasing cumulative number of infected until this growth is non-linearly saturated by herd immunity.
3.2.4. The Effect of the Fatigue Rate
The effect of a non-zero fatigue rate is to bring the effective strike-down rate to zero as
. The solution of the system Equations (
13) and (
14) as
is that
and
. Of course, this blow-up is prevented by herd immunity, which will reduce the effective
to zero when most of the population has been infected. The effect of increasing immunity in the population is not included in Equation (
11), and hence the model makes sense only as long as the majority of the population is still susceptible to the disease. Nevertheless, the last row in
Figure 5 shows that increasing intervention fatigue represented by non-zero
may increase the second and later waves’ amplitude and duration. For sufficiently large
the second wave’s amplitude and duration can become greater than the first. The situations shown in panels (k) and (l) are observed in European countries and are caused by
0.1–0.2. One partial explanation of the second wave’s higher amplitude than the first, as observed in many countries, is a considerably higher testing rate. The testing rate, however, cannot explain the considerably longer duration of the second wave. This prolonged duration shows up both in the observed data and in this model, when the fatigue rate is increased.
3.3. Results from Fitting the Oscillator Model to Data for Selected Countries
In this section, we discuss the results obtained by fitting the proposed oscillator model fitted to the observed incidence data in the different World countries. Once again, we exploit cluster analysis to investigate the differences in values of the three fitted parameters , , and for each country.
This time, rather than computing the dissimilarity as the distance between the time series of country i and j, we let where is a three-dimensional vector containing the parameters , , and fit on the country i. Such a cluster analysis allows visualizing the structure of the parameter space, where each data point represent a country. The log-transform in the computation of the dissimilarity allows better disentangling cluttered data points and to reduce the influence of outliers.
Figure 6 reports the partition obtained by thresholding the dendrogram of the hierarchical clustering at
. We notice that some countries are not assigned to any cluster (depicted in white in the World map). The reason is the failure in converging of the optimization routine used to fit the model parameters, likely due to limited amount or irregularity of observed incidence data.
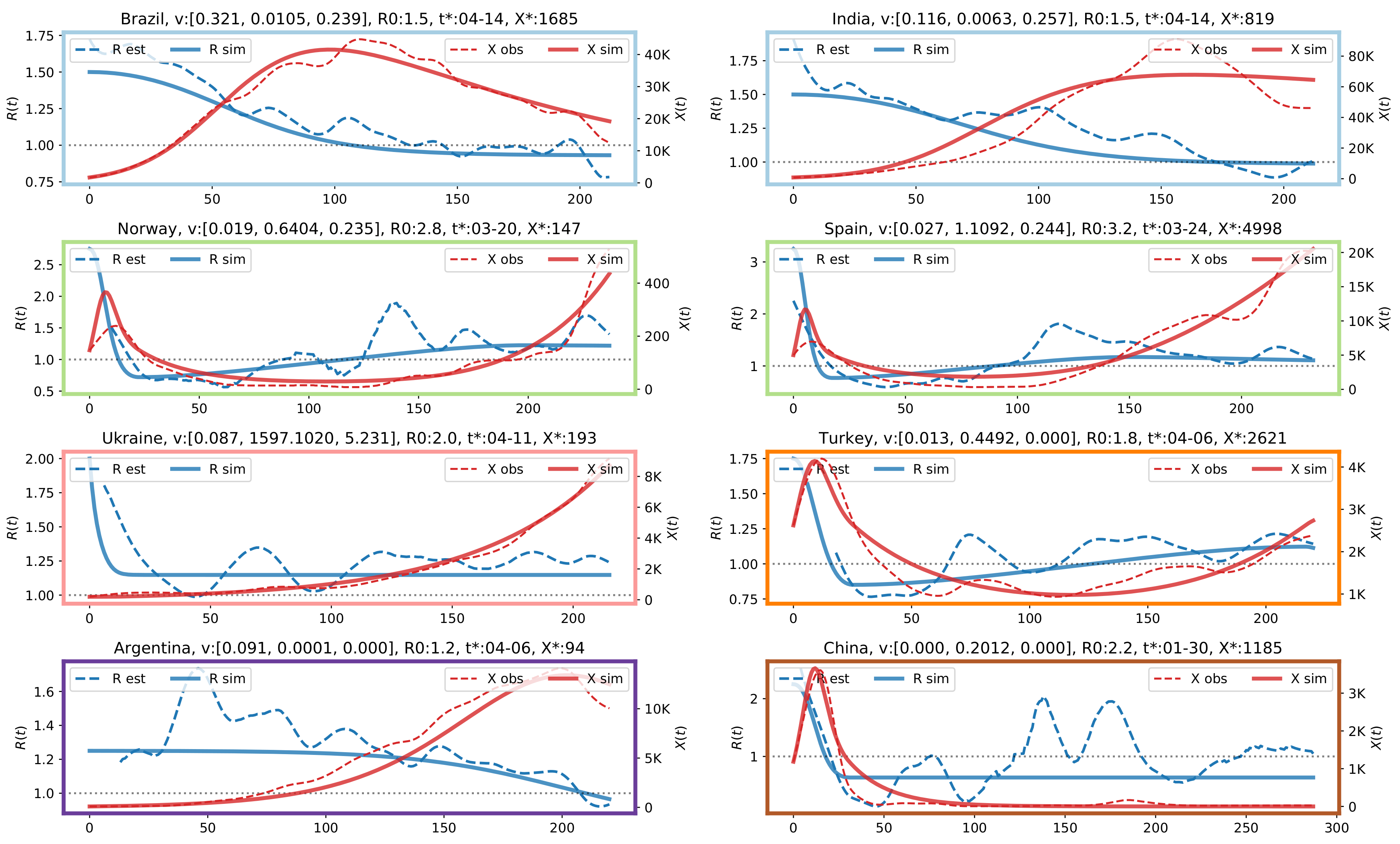
The partition contains six clusters and the largest ones are the azure and green clusters, containing mostly northern and southern countries, respectively. In
Figure 7 we analyze in detail representative countries from each cluster, using for the graph borders the same color coding of
Figure 6. Each graph in
Figure 7 depicts the reported daily new cases (dashed red line), the daily new cases simulated by the oscillator model (solid red line), the
curve estimated using Equation (
9) (dashed blue line), and the
curve simulated by the proposed close model (solid blue line). On the top of each graph, we report for each country the fitted values of
,
,
, the initial
, and the date
that identifies
. On the horizontal axis, 0 corresponds to
, the left vertical axis indicates the value of the reproduction number, the right vertical axis indicates the number of new daily cases. In the
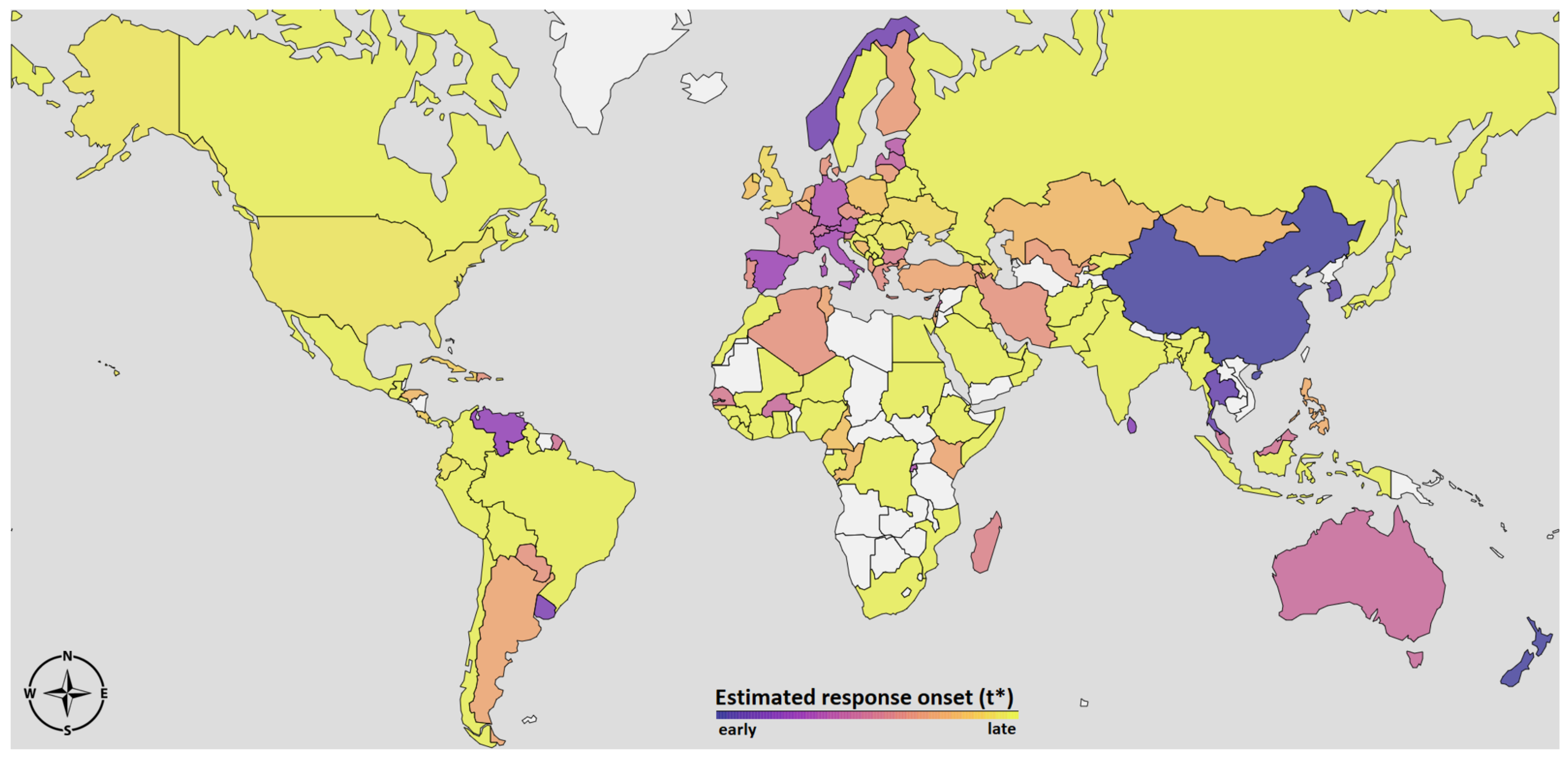
Appendix A, we report a visualization of
in the different World countries, which can be interpreted as an estimate of the onset of the social responses.
The first row show results for two countries assigned to the first cluster, Brazil and India. Interestingly, Brazil and India were assigned to the same cluster (the one depicted in green in
Figure 3 and
Figure 4) also in the previous partition based on the time series dissimilarity of the reconstructed
. The initial reproduction number in these countries is low,
for both countries, and the strike-down parameter is also low,
, leading to a strong and long first wave, which is not yet completely over in November 2020. The fatigue rate of
also contributes to increasing the amplitude and the long-lasting downward slope of the first wave.
The second row show the typical pattern observed in Western countries, where a rather short first wave accompanied by a rapid drop in
due to the almost universal lockdown in March 2020. Then, there is a rather slow relaxation of the interventions throughout the summer, finally leading to
stabilizing in the range 1.2–1.5. The inevitable result is the rise of a second wave, growing stronger and longer than the first, as shown in
Figure 5k,l. In mid-November, interventions again had started to inhibit the growth, but they were weaker than in the spring, as reflected by the fatigue rates in the range
0.2–0.3. Indeed, the predictions of the oscillator model with the estimated rates is that the second wave will blow up in the spring of 2021 to levels where herd immunity will limit the growth. This is before vaccines are likely to play an important rôle, so a more probable scenario is that governments will reverse the fatigue trend and invalidate the model as a prediction for the future. Tendencies in this direction is observed in Europe at the time of writing. Differently from the partition described by the dendrogram in
Figure 3 and by the map in
Figure 4, most European countries are now assigned to the same cluster, along with US and Russia.
The 5th panel depicts the results for Ukraine, which has been selected as representative for the pink cluster. The most characterizing feature is that the reproduction number is not too high, but is never brought below one, resulting in a slow, but steady increment in the new daily cases. The extremely high , combined with a correspondingly high , reflects that the model in this case has problems describing the initial evolution of . The effective intervention rate is negligible after a few days, so effectively grows exponentially without interventions with a growth determined by .
The 6th panel depicts Turkey as representative of the orange cluster. The second wave for Turkey is not created by a finite fatigue rate, since
; it is created by a finite relaxation rate
. Importantly, this relaxation rate cannot create a second wave that is stronger than the first, it only gives rise to a damped oscillation that ends up in the equilibrium
,
. The model-fitted
in Turkey grows slowly greater than 1, and a second wave in
develops. This wave has an amplitude approximately the same as the first, but lasts longer (not shown in the figure), similar to what is shown in
Figure 5k.
Argentina belongs to the purple cluster and the results are reported in the 7th panel. It shows a low initial reproduction number, but still larger than 1, which gives a slow growth of the epidemic, and a low intervention parameter that leaves at this level for a long time before it slowly forced below 1. As a result, the country ends up with a slow and strong first wave that has not reached its peak by November 2020.
Finally, the last panel describes the situation in China, which is a representative of the brown cluster. We notice that parameters estimated for China are comparable to those in
Figure 5i. The peak incidence rate
for China is about three times the threshold incidence
, similar to what is observed in
Figure 5i. For China, the evolution of
is initially rather similar to that of Turkey, and the shape of the
-curve is also rather similar. However, in the Chinese case, the model-fitted
converges to a fixed value
, and
to 0 after a few months. This rise is the result of fundamental differences in the estimated model parameters:
is zero for China but non-zero for Turkey. It may look confusing that
for China estimated from the observed incidence rate (the dashed blue curve), deviates from the theoretical curve and is above 1 during long periods. This is because in China, after the first wave, the incidence rate was so low that it is impossible to estimate
accurately. Indeed, the confidence interval in the estimate of
is very large, but we have not bothered to report it because it would clutter up the figures.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







