 Liel Cohen1,2†
Liel Cohen1,2† Andrew Fiore-Gartland3†
Andrew Fiore-Gartland3† Adrienne G. Randolph4,5
Adrienne G. Randolph4,5 Angela Panoskaltsis-Mortari6
Angela Panoskaltsis-Mortari6 Sook-San Wong7Jacqui Ralston8Timothy Wood8
Sook-San Wong7Jacqui Ralston8Timothy Wood8 Ruth Seeds8Q. Sue Huang8Richard J. Webby9
Ruth Seeds8Q. Sue Huang8Richard J. Webby9 Paul G. Thomas10
Paul G. Thomas10 Tomer Hertz2,3,11*
Tomer Hertz2,3,11*- 1Department of Industrial Engineering and Management, Ben-Gurion University of the Negev, Be'er-Sheva, Israel
- 2National Institute for Biotechnology in the Negev, Ben-Gurion University of the Negev, Be'er-Sheva, Israel
- 3Vaccine and Infectious Disease Division, Fred Hutchinson Cancer Research Center, Seattle, WA, United States
- 4Department of Anesthesiology, Critical Care and Pain Medicine, Boston Children's Hospital, Boston, MA, United States
- 5Departments of Anaesthesia and Pediatrics, Harvard Medical School, Boston, MA, United States
- 6Department of Pediatrics, Bone Marrow Transplantation, Pulmonary and Critical Care Medicine, University of Minnesota, Minneapolis, MN, United States
- 7State Key Laboratory of Respiratory Diseases, Guangzhou Medical University, Guangzhou, China
- 8Institute for Environmental Science and Research, National Centre for Biosecurity and Infectious Disease, Upper Hutt, New Zealand
- 9Department of Infectious Diseases, St. Jude Children's Research Hospital, Memphis, TN, United States
- 10Department of Immunology, St. Jude Children's Research Hospital, Memphis, TN, United States
- 11Department of Microbiology, Immunology and Genetics, Ben-Gurion University of the Negev, Be'er-Sheva, Israel
Cytokines and chemokines are key signaling molecules of the immune system. Recent technological advances enable measurement of multiplexed cytokine profiles in biological samples. These profiles can then be used to identify potential biomarkers of a variety of clinical phenotypes. However, testing for such associations for each cytokine separately ignores the highly context-dependent covariation in cytokine secretion and decreases statistical power to detect associations due to multiple hypothesis testing. Here we present CytoMod—a novel data-driven approach for analysis of cytokine profiles that uses unsupervised clustering and regression to identify putative functional modules of co-signaling cytokines. Each module represents a biosignature of co-signaling cytokines. We applied this approach to three independent clinical cohorts of subjects naturally infected with influenza in which cytokine profiles and clinical phenotypes were collected. We found that in two out of three cohorts, cytokine modules were significantly associated with clinical phenotypes, and in many cases these associations were stronger than the associations of the individual cytokines within them. By comparing cytokine modules across datasets, we identified cytokine “cores”—specific subsets of co-expressed cytokines that clustered together across the three cohorts. Cytokine cores were also associated with clinical phenotypes. Interestingly, most of these cores were also co-expressed in a cohort of healthy controls, suggesting that in part, patterns of cytokine co-signaling may be generalizable. CytoMod can be readily applied to any cytokine profile dataset regardless of measurement technology, increases the statistical power to detect associations with clinical phenotypes and may help shed light on the complex co-signaling networks of cytokines in both health and infection.
1. Introduction
Cytokines and chemokines are key signaling molecules of the immune system, mediating a complex network of interacting cells that govern the immune response (1, 2). These small proteins secreted by a broad range of cells, regulate host responses to infection, trauma and sepsis and are involved in inflammatory and autoimmune diseases. The role of cytokines in disease as well as the associations between cytokine production levels and the occurrence of diseases and their phenotypes has been extensively studied (3), and many studies have shown that cytokine signaling is context-dependant (4). Cytokine expression and dysregulation have been linked with a variety of diseases such as diabetes (5, 6), Alzheimer's (7), cancer (8–11), heart disease (12, 13), and various viral infections including influenza, EBV, RSV, HIV and dengue (14–18).
Influenza is a respiratory virus that accounts for significant rates of hospitalizations and deaths, especially among very young or old individuals (19). Due to the variety of influenza subtypes and their rapid evolution, influenza causes annual epidemics and occasional catastrophic pandemics (20, 21). Influenza infection in humans can result in asymptomatic to serious illness with symptoms such as fever, myalgia, headache and upper and lower respiratory symptoms. The respiratory tract infection can progress to various acute conditions, e.g., pneumonia and acute respiratory distress syndrome (ARDS) or a “cytokine storm” causing widespread tissue damage (22, 23). In some cases, complications are caused by a secondary bacterial infection such as Staphylococcus aureus.
Cytokine expression in response to influenza infection has been studied using human blood and nasal samples, immune cell cultures and animal models (23, 24). Numerous studies have reported associations of individual cytokines with various influenza phenotypes and outcomes such as hospitalization and death. Each study tested a specific subset of cytokines. From these studies, several prominent cytokines have been repeatedly found to be associated with illness and symptoms including IL-6, TNF-α, IL-10, IL-8, IP-10, IFN-γ, and MCP-1 (23–32). Differences in cytokine expression levels were found between subjects infected with different Influenza strains, as well as different severity and symptoms. For example, the H5N1 strains were found to induce high serum levels of IP-10 and monokine induced by interferon-γ (MIG) (25, 33) and also higher levels of TNF-α and IFN-β compared to H3N2 or H1N1 strains (29). Another study reported hyperactivation of IL-6, IL-8, and MCP-1 in blood of subjects infected with pandemic H1N1 that developed pneumonia and in complicated seasonal influenza, but not in milder pandemic H1N1 infections (28). A significant correlation has been reported between disease severity and the levels of IL-6, IL-10, and IL-15 (32), and in contrast, IL-17 was lower in more severe patients (28, 32).
Despite our partial understanding of cytokine biology there are a variety of therapeutic treatments that target specific cytokines, which are in wide clinical use to treat autoimmune diseases and cancer. There are a variety of licensed monoclonal antibody (Ab) treatments that target cytokines or their receptors. Examples include: anti TNF-α Abs (34, 35), an anti IL-6 receptor Ab (35, 36), anti IL-1 Abs (35), anti IL-10 Abs (37), anti IL-23 Abs (38), and anti Herceptin Abs (39). Most notably, Humira-an anti TNF-α Ab is widely used to treat a variety of autoimmune diseases and was the best selling drug in 2017 (40).
Since cytokines and chemokines (hereafter referred to as cytokines) reflect the local or systemic immune state, they have the potential to serve as indicators of various clinical conditions. Various studies suggested the use of measurements of circulating cytokines as biomarkers in order to aid clinicians in patient prognosis and care (41–46). Furthermore, as the understanding of cytokine biology improves, new treatment strategies emerge to leverage this knowledge (47). Several methodologies have been developed for quantification of secreted cytokines in body fluid samples, including immunoassays such as ELISA and bead-based multiplex immunoassays (48), allowing the collection and analysis of cytokine “profiles”: a broad and unbiased assessment of cytokine levels that typically includes 10–50 cytokines of interest.
While numerous studies have reported associations between cytokine levels and various clinical phenotypes, the analysis of cytokine profiles is often statistically underpowered to detect such associations, due to the large number of cytokines and the requirement for multiplicity adjustment. Furthermore, the relatively high-cost of cytokine profiles limits the sizes of cohorts for which they are measured. A typical cytokine profile dataset can have measurements obtained from tens to hundreds of subjects. These opposing trends make it increasingly important to develop new computational tools for analyzing cytokine profiles that are statistically efficient and provide interpretable results.
One possible solution for preserving statistical power, is to select a small subset of cytokines for a primary analysis with phenotypes, with a secondary/exploratory analysis that includes all remaining cytokines. For example, in previous work on cytokine profiles following influenza natural infection we pre-selected a subset of 11 cytokines for the primary analyses based on published studies (49). Multiplicity adjustment was performed across the 11 cytokines pre-selected in our analysis plan. While this approach identified several significant associations with phenotypes, it failed to detect other significant associations of cytokines that were not selected in the primary set as we demonstrate below. Furthermore, it required pre-existing knowledge for selecting the primary set of cytokines, limiting the ability to discover novel associations.
Another important property of cytokine signaling is its inherent redundancy (2, 50). Many of the same cytokines may be simultaneously secreted by different immune cells, and activation or attenuation of an immune pathway can often be mediated by multiple cytokines. Therefore, cytokine profiles typically exhibit high levels of pairwise correlations among cytokines, across subjects, as previously demonstrated (49, 51). These complexities pose particular challenges in the interpretation and analysis of cytokine data by practitioners.
Motivated by previous work, and the growing abundance of cytokine profile datasets, we developed CytoMod: a novel method for the analysis of cytokine profiles based on identifying cytokine modules. The modular-based approach is partly inspired by similar approaches used for analyzing gene expression data (52–57). Our proposed method aims to increase statistical power to detect associations of cytokines with clinical phenotypes by grouping cytokines into putative functional modules, using a data-driven clustering approach. Cytokines are grouped based on their pairwise correlations using hierarchical clustering. Modules are formed over absolute and adjusted cytokine levels. Associations are then assessed between cytokine modules and phenotypes as opposed to individual cytokines (Figure 1). An earlier version of this method was used to analyze cytokine profiles of influenza infected children that were admitted to the intensive care units (51). Here we extended this method to allow fully automated identification of modules and applied it to three independent clinical cohorts of natural influenza infection in which cytokine profiles were obtained and clinical phenotypes were collected. We found that in two of these cohorts, cytokine modules were significantly associated with clinical phenotypes, and in many cases these associations were stronger than the associations of the individual cytokines within each of the modules. Applying our method to these three independent cytokine profile cohorts we identified specific subsets of cytokines (cytokine “cores”) that clustered together across the three cohorts, and which were also associated with clinical phenotypes. These cytokine cores identify subsets of cytokines that are co-expressed during influenza infection, and most were also observed in healthy individuals. Our method can be readily applied to any cytokine profile dataset, and is publicly available for use using Python code or an interactive Jupyter Notebook.
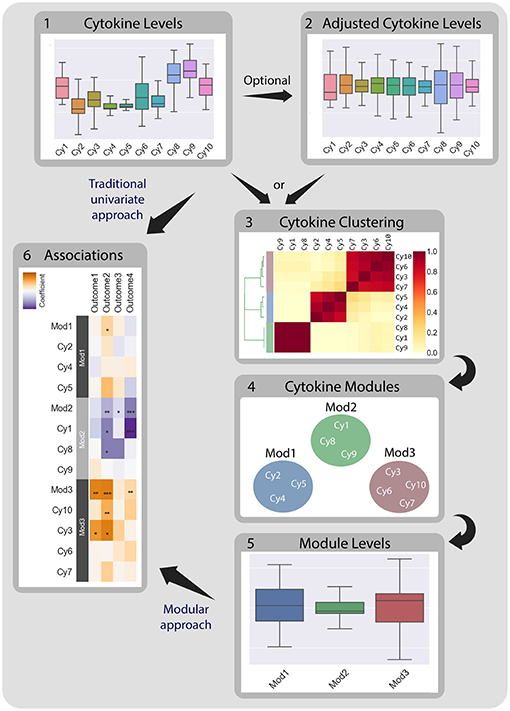
Figure 1. CytoMod—a modular data driven approach to identify cytokine modules and assess their associations with clinical phenotypes. Traditionally, associations between cytokine data (1) and clinical phenotypes (5) are tested directly using univariate models. CytoMod independently uses absolute cytokine profiles (1) or adjusted cytokine profiles (2) to generate cytokine modules (3)-sets of co-signaling cytokines within a given cohort. Modules are generated using unsupervised hierarchical clustering. Associations are then tested between module levels (4) and clinical phenotypes (5). By significantly reducing the number of associations tested CytoMod increases the statistical power to detect associations. By comparing modules across datasets, CytoMod can also identify “cores” of cytokines that consistently co-signal together.
2. Materials and Methods
2.1. Data
We analyzed cytokine profiles of 611 subjects collected from three independent studies (49, 51, 58) of subjects naturally infected with influenza virus as well as healthy controls: (1) PICFLU-a prospective multi-center study of children admitted to intensive care units with severe influenza infection (51); (2) FLU09-a prospective study of children admitted to the emergency room with influenza like-illness and their household members (49); and (3) The Southern Hemisphere Influenza and Vaccine Effectiveness Research and Surveillance (SHIVERS)—a prospective study of influenza infected subjects collected in New Zealand (58). Influenza positive cohorts included 221, 161, and 87 subjects, respectively, which were all tested and found positive for influenza (by DFA, PCR, RT-PCR, or culture). The FLU09 study also included 142 healthy control subjects.
PICFLU - The PICFLU study was a prospective multi-center study of severe influenza infections in children aged 0.06–18.19 years (median 6.97) (51). Blood samples were collected from a total of 221 children diagnosed with influenza critical illness that arrived at intensive care units (ICUs) at 35 hospitals between December 2008 and May 2015. An endotracheal sample was collected from all subjects that were intubated. Samples were provided at enrollment (mostly within 24 h of intensive care unit admission). Almost half of the enrolled subjects received vasoactive agents for septic shock and a similar fraction met criteria for Acute Respiratory Distress Syndrome (ARDS) with the majority having the severe form. Most subjects (n = 175, 79.2%) were influenza type A positive, while the remaining cases (n = 46, 20.8%) were influenza type B positive. Eighty-one subjects (36.6%) had a bacterial coinfection, predominantly with Staphylococcus aureus, Streptococcus pneumoniae and Streptococcus pyogenes. Additional information regarding the design, sampling, and subjects in PICFLU cohort can be found in Table 1.
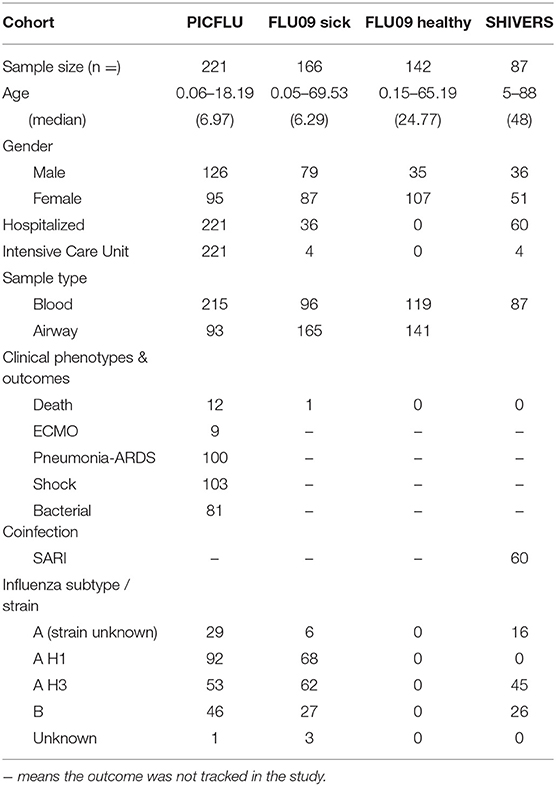
Table 1. Characteristics and clinical information of patients from the analyzed cohorts.
FLU09 - The FLU09 study was a prospective study of children and their household members. It included samples of blood plasma and nasal swab/lavage from influenza infected subjects as well as their asymptomatic Influenza-positive household contacts. Three hundred and three subjects aged 0.05–69.53 years (median 17.23) were enrolled during 2009–2014 and included 142 healthy household members. A preliminary analysis of cytokine profiles (49) included only subjects from 2009 to 2011. Most samples were provided at enrollment and only few were taken within the first week. The cohort included 36 (22.4%) individuals who were hospitalized, four of them (2.5%) were admitted to the ICU. 5 (3.1%) suffered from febrile acute respiratory disease and another single subject (0.006%) had ARDS and died. Three subjects (1.8%) suffered from a bacterial coinfection. Study subjects were asked to rank their symptom severity daily according to a visual analog scale (VAS) until study completion. The symptoms considered were upper respiratory tract (URT) symptoms (sore throat, stuffy/runny nose, sinus fullness/facial pain); lower respiratory tract (LRT) symptoms (cough, shortness of breath, wheezing); systemic symptoms (feverishness, fatigue or malaise, headache, body aches or myalgia, chills, lethargy); gastrointestinal symptoms (nausea, vomiting, diarrhea). The FLU09 study also included 142 healthy control subjects for which cytokine profiles were also measured. These data were analyzed separately in section 3.5. Additional information regarding the design, sampling and subjects in FLU09 cohort can be found in Table 1.
SHIVERS - The Southern Hemisphere Influenza and Vaccine Effectiveness Research and Surveillance (SHIVERS) study included 87 Influenza infected subjects recruited from 16 sentinel general practices and 4 hospitals (58). Subjects were enrolled between 2013 and 2015 (aged 12–78 years, median 44.5). Sixty (68.9%) subjects recruited from hospitals demonstrated symptoms of Severe Acute Respiratory Illness (SARI), defined as “an acute respiratory illness with a history of fever or measured fever of ≥ 38°C, and cough, and onset within the past 10 days, and requiring inpatient hospitalization” (59), while the rest suffered from a milder form of Acute Respiratory Illness (ARI), i.e., do not require hospitalization (59). The majority of the SARI cases were relatively mild. Four subjects (4.59%) were admitted to the ICU. Blood specimens were taken from subjects after their Influenza infection was confirmed and also 2 weeks later. Our analysis only included samples from the acute phase (first timepoint). Subject samples were analyzed for cytokines, chemokines, growth factors and other mediators using bead-based Luminex multiplex assays or ELISA technology. In a preliminary analysis of the cytokine profiles, we detected significant differences between the measurements in year 1 and 2 of the study. These were likely caused by two factors: (1) The sampling strategy was modified between the two study years; and (2) Different labs quantified cytokines in each study year (personal communication, Sook-San Wong). We therefore used year 2 data for generating cytokine modules, but did not include it in our association analyses with clinical phenotypes presented below. Additional information regarding the design, sampling and subjects in SHIVERS cohort can be found in Table 1.
2.2. Adjustment for Mean Cytokine Concentration
To obtain the relative concentration of cytokines with respect to the overall level of cytokine secretion within each subject, cytokine concentrations were adjusted as follows: for a given cytokine, the levels for all subjects were regressed against the mean cytokine concentration. The adjusted cytokine concentrations were defined as the residuals from the regression. Formally, the adjusted values represent the level of unexplained deviation of that cytokine, from the expected cytokine level, given the average cytokine level of the subject. The full adjustment procedure for each Cytokinej is as follows:
1. Compute the mean cytokines level for each subject in the dataset. Construct a vector of the means (with the length of the sample size).
2. Construct a regression model for Cytokinej, such that the vector of the means is used as a predictor for Cytokinej's level in the sample, defined as the response variable:
3. For each sample compute the expected Cytokinej level using the regression model defined in II. Calculate the residue of the regression as:
As shown in Fiore-Gartland et al. (51) and above, adjustment can reveal interesting information about the relative deviation in cytokine levels in different individuals, which cannot be observed when analyzing absolute cytokine concentrations.
We note that the CytoMod adjustment procedure utilizes the values of all cytokines in a given dataset and may therefore be sensitive to the specific cytokines that were measured. To quantify the sensitivity of the adjustment procedure to cytokine selection, we conducted the following analysis: Subsets of cytokines were randomly selected from the original set of 37 cytokines in the PICFLU dataset; their size ranged between 2 and 36 cytokines. For the size of 36 cytokines, 37 subsets of cytokines were drawn, each containing the entire set of cytokines except for a single cytokine that was left out in each. For each subset size between 2 and 35, 50 different subsets of cytokines were randomly drawn. For each subset the adjustment procedure was conducted over the selected subset and the Spearman correlation was computed between the adjusted cytokine values of this subset, and their corresponding adjusted values over the entire set of 37 cytokines. Figure S1 presents the average median correlation across all 50 subsets, where the median was computed for each subset across all cytokines tested. We found that when drawing subsets of more than 10 cytokines, the average correlation to the original adjusted dataset was >0.95. Furthermore, when drawing subsets of 25 cytokines, the average correlation was 0.9899. This suggests that our adjustment method is robust given a sufficiently large set of cytokines.
2.3. Clustering
CytoMod is a modular approach for cytokine analysis that clusters cytokines based on pairwise correlations, to both amplify the signal they share and aid in interpretation by grouping putatively co-signaling molecules. Cytokines are grouped using a hierarchical clustering technique which iteratively pairs cytokines (and groups of cytokines) with similar behavior to generate a series of nested clusters. The clustering hierarchy can be represented by a tree-like graph (dendrogram) in which branches indicate the similarity between the formed subgroups of cytokines. By slicing the tree at a certain level we can obtain a set of distinct clusters. The dendrogram allows to graphically portray the clusters hierarchy and visualize the structure and data distribution in a manner that is intuitive for both computational and non-computational practitioners (55, 56, 60).
In this study, cytokine measurements from each dataset were clustered independently of the others. Measurements of different compartment samples in the same study were clustered independently due to notable differences in signaling patterns as shown in two different studies (49, 51). Importantly, clustering is performed over cytokines and not over subjects, to obtain groups of cytokines with similar expression profiles across subjects. Clusters were formed based on the correlation of adjusted and absolute cytokine levels, separately. Complete-linkage agglomerative hierarchical clustering was used to group cytokines (variables) with the Pearson's correlation coefficient as the distance metric. Complete linkage, which joins subclusters iteratively based on the closest maximum distance between pairs of variables in the subclusters, was used because it tends to form compact clusters. Since the approach suffers from sensitivity to minor perturbations in the data (56), we employed a bootstrap clustering method that was previously applied to gene expression data (61) in order to increase cluster robustness. The bootstrapping includes repetition of the clustering procedure on multiple perturbed subsets of the data, each formed by randomly drawing subject samples (with replacement) from the dataset. We repeated the clustering procedure on subject-level bootstrapped datasets 1,000 times. We recorded the number of times that each pair of cytokines clustered together across these 1,000 runs. The final hierarchical clustering was performed on this matrix of reliability fractions. Conceptually this can be thought of as a bootstrap estimate of cluster membership, simulating the reliability of each pair of cytokines to belong to the same cluster in repeated experiments on perturbed data under the same conditions.
The number of clusters (K) for each dataset was determined using the Tibshirani “gap statistic” heuristic method (62), which computes the marginal decrease in intracluster distance (ICD) for different K values, compared to the expected decrease under a null reference distribution of the data, assumed to be comprised of a single cluster. The estimate of the optimal K is the K for which the ICD falls the farthest below the reference curve while also taking into account the estimated deviation of the sampling distribution and simulation error (denoted by S). K is chosen as the first K that satisfies
In our implementation we chose to test K values between 1 and 11 and generate a reference dataset by shuffling each feature (cytokine) independently of the others with 200 repetitions. For both real and null data distances between cytokines were defined using Pearson's correlation coefficient. For the real dataset bootstrapped clustering was performed as described above. To constrain the number of modules to be smaller than 6, and at least 2, in cases where the estimated best K found was not in these bounds or the condition was not satisfied for all K between 1 and 11, we chose K between 2 and 6 for which
We chose to limit the number of clusters to 6 in order to reduce the formation of small (and possibly singleton) clusters. This threshold also affects the increase in statistical power for detecting associations, since as the number of clusters grows, more hypotheses will be tested and the adjusted p-values will decrease accordingly.
Finally, each cluster was used to calculate module scores for each subject in each dataset. Module scores were computed as the mean value of all cytokines that belong to the module after standardizing cytokine values to mean zero and unit variance.
2.4. Associations With Clinical Phenotypes
The primary analysis of cytokine modules included tests for associations with the clinical measures of disease severity available for each dataset using regression. All non-binary input and output variables were mean centered and variance scaled to unit variance. Logistic regression was used for all binary response variables and strength of effect was defined by an odds-ratio per unit increase in log-cytokine titer. For continuous response variables we used linear regression and strength of effect was defined using the log-cytokine regression coefficient (beta). Regression models controlled for the effects of variables that were previously used in each of the studies (49, 51, 58), as detailed in section 3.3. P-values for the coefficients describing the associations of cytokines and symptom scores were adjusted for multiple hypothesis tests within each cohort, compartment and adjustment method. P-values for the coefficients between module scores and symptom scores were also adjusted, separately from the cytokine coefficients. We report associations using two types of multiplicity adjustment methods: (1) false-discovery rate (FDR) using the Benjamini Hochberg procedure (63); (2) Family-wise error rate (FWER) using the Bonferroni-Holm method (64). Only associations with FDR-adjusted q ≤ 0.2 are shown. Associations that were significant using the more stringent FWER-adjusted p-value were marked using asterisks in each figure. All of the associations discussed below were FWER significant.
2.5. Defining Cytokine Cores
Cytokine measurements from each dataset were clustered into modules as described in section 2.3. Since airway samples were available only for two out of three studies, clustering comparison was only performed for the blood samples results. Comparison was performed for the absolute and adjusted clusters separately. For each we recorded the number of times each pair of cytokines clustered together in all three blood datasets. Cytokine cores were defined as groups of cytokines that clustered together across all three datasets. It should be noted that these cores may be refined when additional cytokine profile datasets are available.
Cytokine cores associations with phenotypes were calculated as described in section 2.4. A subject's score for each core was calculated based on the mean cytokine concentration of cytokines within the core, after standardizing each cytokine to mean zero and unit variance. P-values for the coefficients describing the associations of cytokines and phenotype scores were adjusted for multiple hypothesis tests within each presented dataset separately. P-values for the regression coefficients calculated for the core scores were adjusted separately than the coefficients calculated for individual cytokines. Individual cytokine p-values were adjusted across all cytokines and not only for the cytokines included in the core cytokine set.
Finally, we calculated pairwise Pearson correlations between cytokine cores within each blood dataset, i.e., PICFLU, SHIVERS, FLU09 and FLU09-healthy. P-values for the correlation coefficients were adjusted for multiple hypothesis tests within each dataset. The correlations were presented alongside each other in order to highlight trends across all datasets.
3. Results
We applied CytoMod to cytokine profiles of three independent cohorts (see section 2.1 for details) of consented subjects naturally infected with influenza virus: (1) PICFLU—a prospective multi-center study of children admitted to intensive care units with severe influenza virus infection (51); (2) FLU09—a prospective study of children presenting to the emergency room with influenza like-illness and their household members (49); and (3) Southern Hemisphere Influenza and Vaccine Effectiveness Research and Surveillance (SHIVERS)—a prospective study of influenza virus infected New Zealanders (58). The cohorts included 221, 161, and 87 subjects, respectively, who all tested positive for influenza. The FLU09 study provided an additional cohort of 142 healthy control volunteers that were not included in the main analyses and were analyzed separately in section 3.5.
To allow a direct comparison between the different cohorts, we limited our analysis to 37 cytokines that were measured from the blood of subjects in all three studies. These cytokines were also used to profile nasal wash from FLU09 subjects and endotracheal aspirates of PICFLU subjects. Cytokine concentrations (pg/mL) and subject ages were log-transformed for all analyses. Cytokine measurements from each study were analyzed independently of the others due to differences in subject characteristics and measurement methods. Measurements from different compartments (e.g., blood, nasal) were also analyzed separately due to notable differences in signaling patterns, as shown previously (49, 51). In total, five datasets were analyzed: FLU09 plasma, FLU09 nasal wash, PICFLU serum, PICFLU endotracheal aspirates and SHIVERS serum. We also analyzed an additional dataset of healthy controls that were sampled in the FLU09 study (49).
3.1. Generating Cytokine Modules
To capture the underlying correlation structure induced by co-signaling cytokines, we developed a clustering-based approach to group cytokines into data-driven modules. Each module, represents a group of cytokines that co-vary across individuals within a given cohort. Modules are therefore defined separately for each cytokine dataset. The similarity between each pair of cytokines is defined by their Pearson correlation coefficient across all subjects, within a cohort. The similarity matrix is computed separately for each compartment, based on previous observations that found relatively low levels of correlations between cytokines across compartments as compared to within compartment similarities (49, 51). We computed the cytokine pairwise similarity matrices for each of the five datasets used in this study as outlined above (Figure 2A and Figures S2A, S3A, S4A, S5A). To define cytokine modules, we used an unsupervised hierarchical clustering algorithm that groups cytokines based on their pairwise similarity. Importantly, the algorithm does not incorporate any information regarding clinical phenotypes (i.e., clusters are not defined based on outcomes). The number of clusters was automatically selected. Specifically, we used complete-linkage agglomerative hierarchical clustering and the number of clusters (K) for each dataset was determined using the Tibshirani “gap statistic” method (62) (Figure 3A and Figures S6A–C), which selects the number of clusters based on the marginal decrease of within-cluster distances (see methods). Since minor perturbations of the data could affect the clusters obtained, a reliability score over each pair of cytokines was defined by computing the fraction of times a pair of cytokines were assigned to the same cluster over 1,000 randomly perturbed datasets (Figure 3B; see section 2.3). The final cytokine modules were defined over this pairwise reliability matrix. Cytokine values within each module were standardized (zero mean and unit variance) to ensure that each was given equal weight within a module. Given a set of cytokine modules, a subject-specific score was computed for every module defined by the mean cytokine concentration of all cytokines in the module, cytokine modules were subsequently used to detect associations between cytokine concentrations and clinical phenotypes.
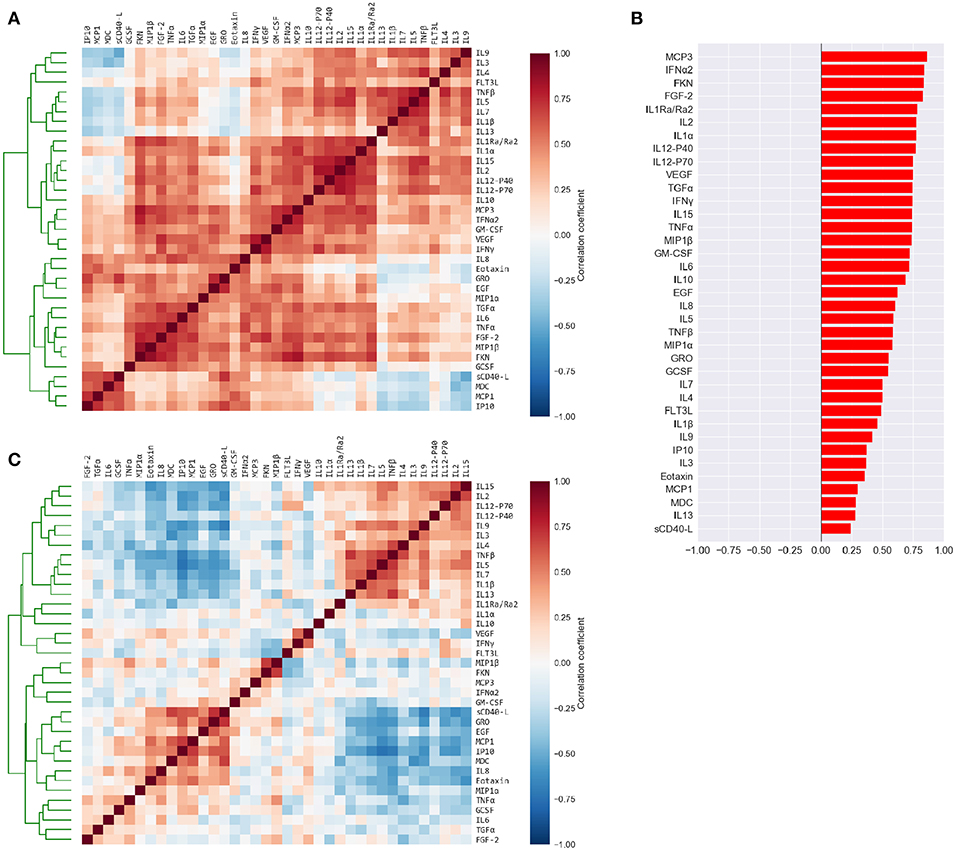
Figure 2. Cytokine levels are highly correlated to each other and to the mean cytokine level of each subject. (A) Pairwise Pearson's correlations among the absolute plasma cytokine levels in the FLU09 cohort. Cytokines were sorted along both axes using hierarchical clustering (complete-linkage). (B) Correlations between cytokine levels and mean cytokine levels for each subject. (C) Pairwise Pearson's correlations between cytokines following adjustment to the mean cytokine level (see Methods for details). Cytokines were sorted along both axes using complete-linkage.
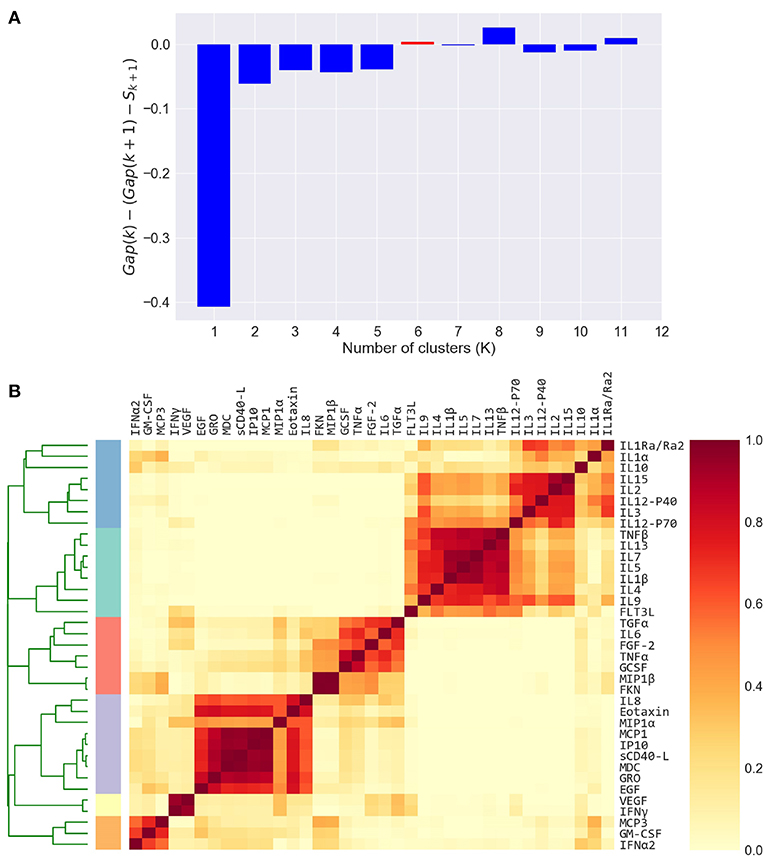
Figure 3. Defining cytokine modules on the FLU09 adjusted plasma cytokine profiles. (A) Automated selection of the optimal number of modules. The Tibshirani gap statistic is used to automatically determine the optimal number of modules. The cytokine profiles are clustered into K = 1 − 11 clusters and the optimal K is selected. The plot shows the δ gap statistic, defined as Gap(K) − (Gap(K + 1) − Sk + 1) for K = 1 − 11. The optimal number of modules (K = 6) is selected by identifying the first value of K for which this measure is positive, while also constraining it to vary between 2 and 6. (B) Heatmap of cytokine modules - Complete linkage clustering over the Pearson pairwise correlation similarity measure is used to cluster cytokines into K modules, where K is decided using the gap statistic. A clustering reliability score is computed over 1, 000 samplings of subjects that are sampled with replacement. The score for each pair of cytokines represents the fraction of times they clustered together across 1, 000 random samples. The reliability score of K = 6 is presented here. The final modules are then constructed by clustering the pairwise reliability scores, and are represented by the colored stripes below the clustering dendrogram.
3.2. High Correlation Among Cytokines Motivated Adjustment for Mean Concentration
The high positive correlation among the majority of cytokines in each compartment (or dataset) was also reflected in the significant positive correlations between each cytokine and the mean cytokine level within each subject (51) (Figure 2B and Figures S2B, S3B, S4B, S5B). Thus, subjects with a high concentration of one cytokine were relatively likely to have high concentrations of most of the other cytokines. We hypothesized that overall levels of immune activation (e.g., absolute number of immune cells in the blood) drive absolute cytokine concentrations. A high level of immune activation could therefore obscure cytokines expressed at relatively low levels. Furthermore, the absolute cytokine concentration could also be affected by technical artifacts such as sampling variability introduced by sample collection methods. Therefore, we developed an approach for adjusting cytokine measurements for the mean level within each sample using regression (detailed in section 2.2). An adjusted cytokine measurement reflects the level of unexplained deviation of that cytokine in a specific sample, from the expected cytokine level according to its association with the mean estimated across all samples. Correlations among cytokines after the adjustment can be substantially different, revealing associations that were previously obscured by the strong correlation with the mean (Figure 2C and Figures S2C, S3C, S4C, S5C). Therefore, following our previous work modules were constructed and analyzed using both absolute and adjusted cytokine concentrations separately for each dataset (51).
3.3. Modules Based on Absolute Cytokine Levels Were Associated With Influenza Clinical Phenotypes in Two Cohorts
For each study, we evaluated the association between each absolute cytokine module and the relevant clinical phenotypes recorded in the study, using linear or logistic regression models (detailed in section 2.4). Regression models controlled for the effects of age and other variables, as previously chosen for each of the three cohorts (49, 51, 58). For purposes of comparison, we also evaluated the association of each absolute individual cytokine with the phenotypes. P-values for the coefficients describing the associations of modules and cytokines with clinical phenotypes were adjusted for multiple hypothesis tests within each figure presented (i.e., across cytokines or cytokine modules, but within cohort, compartment and absolute/adjusted module set). The P-values for the module and cytokine coefficients were adjusted independently. Family-wise error rate (FWER)-adjusted p-values using the Bonferroni-Holm method (64) were calculated and are presented in each figure using asterisks. Only associations with a false-discovery rate (FDR)-adjusted q ≤ 0.2 are shown [using the Benjamini' Hochberg procedure (63)]. However, only associations with FWER-p ≤ 0.05 were considered statistically significant.
FLU09 - The associations with clinical phenotypes in influenza-positive FLU09 absolute datasets were calculated using linear regression adjusted for age (Figures 4A,C and Tables S1, S3). Modules and cytokines were tested for associations with several clinical phenotype groups recorded in the study (detailed in section 2.1): upper respiratory tract (Upper RT) symptoms, lower respiratory tract (Lower RT) symptoms, systemic symptoms, gastrointestinal symptoms, total symptoms and (log) viral-load (log-VL). Significant positive associations were observed with the absolute plasma modules. For example, absolute Blood Sample 3 module (BS3) was positively associated with total and systemic symptoms, and absolute BS4 was associated with lower RT symptoms (regression coefficients of 0.529, 0.605, 0.322, and FWER p-values of 0.0035, 0.0037, 0.0304, respectively). Individual cytokines within these modules were also significantly associated as follows: BS3 cytokines EGF, GRO and IP-10 positively associated with total symptoms and IP-10 also associated with systemic symptoms; the BS4 cytokine Fractalkine (FKN) was positively associated with lower RT symptoms. While most of the regression coefficients of these cytokines were slightly higher than those of their modules, the statistical significance of the absolute associations after FWER adjustment was stronger for the modules than the individual cytokines in 4 of 5 (significant) cases; only the significance of the Fractalkine association was stronger than that of the BS4 module to which it belongs. In addition, IL-10 was significantly associated with both upper and lower RT, while the BS2 module to which it belonged was not significantly associated with any symptoms. This increase in statistical significance is directly attributable to the reduction in the number of statistical tests across which multiplicity adjustment is applied. In the absolute-module set analysis of the nasal wash samples, the majority of cytokines clustered together into one module (NW2), perhaps due to high immune activation at the site of infection. Absolute NW2 was significantly positively associated with upper RT symptoms (regression coefficient 0.46, FWER p = 0.029), however, NW2 cytokine IL-6 had a stronger significant positive association with the same phenotypes. It should be noted that all of the previously reported cytokine associations with symptom scores identified using data from years 1 to 2 of the FLU09 study (using an FDR threshold of 0.2) (49), were re-confirmed in our current analysis using the complete cohort from years 1 to 5 (Figure S9), and additional associations were found in the current analysis.
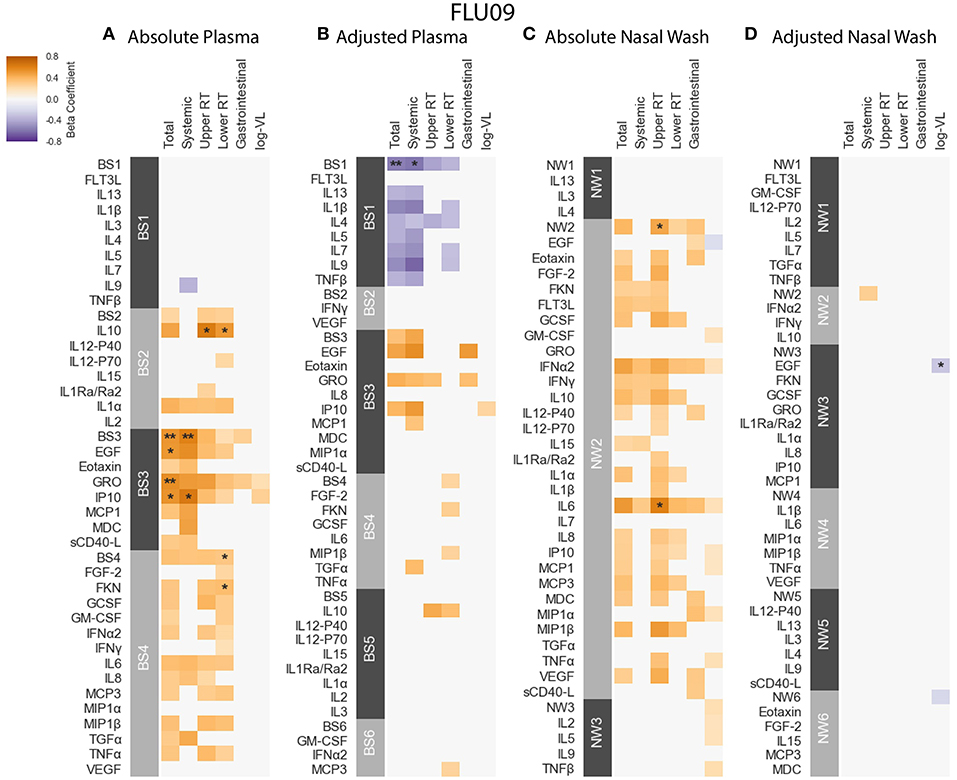
Figure 4. FLU09 cytokine associations with clinical phenotypes. Associations were identified using linear regression controlling for patients age using both absolute and adjusted plasma samples (A,B), and absolute and adjusted nasal wash samples (C,D). Modules of covarying cytokines were constructed separately for absolute and adjusted cytokine measurements from plasma or nasal wash samples. We then tested associations with several clincal phenotypes described in section 2.1: upper respiratory tract (URT) symptoms, lower respiratory tract (LRT) symptoms, systemic symptoms, gastrointestinal symptoms and log viral load (VL). Each cytokine or module is indicated along the rows, grouped by their assigned module. Heatmap color indicates the direction and magnitude of the regression coefficient between cytokine or module level with a given clinical phenotype. Only associations with false-discovery rate (FDR)-adjusted q-value ≤ 0.2 are colored. Asterisks indicate family-wise error rate (FWER)-adjusted p-values with ***, **, and * indicating p ≤ 0.0005, 0.005, and 0.05, respectively.
PICFLU - Positive significant correlations were also observed in the absolute PICFLU serum associations with clinical phenotypes portrayed in Figure 5A and Table S5. These associations, calculated using logistic regression, were adjusted for age and bacterial coinfection (see section 2.1 for details). The absolute BS3 module was positively associated with both shock and ECMO or death (odds ratio 2.75, 2.04, FWER p-values 0.00002, 0.0286, respectively). The BS3 cytokines IL-6 and IP-10 had an association with shock, while IL-8 and MCP-1 had an association with both shock and pneumonia-ARDS. The BS3 association with ECMO or death was significant while none of the individual cytokines in the module were significantly associated. The strength of the association with shock for all individual BS3 cytokines was weaker than for the module as a whole. On the contrary, absolute IL-8 and MCP-1 had a significant association with pneumonia-ARDS, while the absolute BS3 module did not. The PICFLU absolute endotracheal samples did not have any significant associations with outcomes (FWER-p > 0.05; Figure S7A and Table S7).
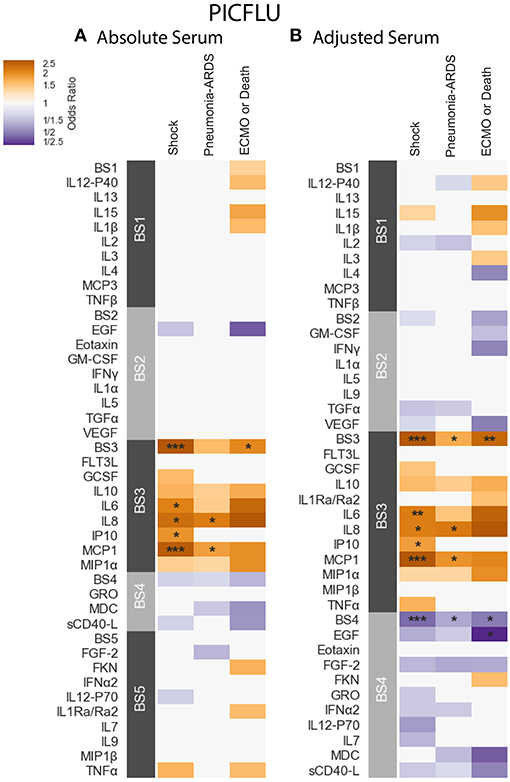
Figure 5. PICFLU serum cytokine associations with clinical phenotypes identified using logistic regression while controlling for patients age and bacterial coinfection. Modules constructed of covarying cytokines [absolute (A) and adjusted (B) measurements separately] from serum samples, were tested for associations with the clinical phenotypes described in section 2.1: shock, pneumonia-ARDS and ECMO or death. Each cytokine or module is indicated along the rows, grouped by their assigned module. Heatmap color indicates the direction and magnitude of the regression coefficient between cytokine or module level with a given clinical phenotype with and without the complication. Only associations with false-discovery rate (FDR)-adjusted q ≤ 0.2 are colored. Asterisks indicate family-wise error rate (FWER)-adjusted p-values with ***, **, and * indicating p ≤ 0.0005, 0.005, and 0.05, respectively.
SHIVERS - Due to differences in sampling strategy during the first and second years of the study, associations with phenotype were calculated only for subjects from the first year of the SHIVERS study (n = 52). Logistic Regression models included adjustment for age, ethnicity and sampling time. No significant associations were detected among absolute individual serum cytokines, with severe acute respiratory illness (SARI) (Figure S8A and Table S9). However, we note that univariate associations previously reported for this cohort (58), which were not adjusted for multiplicity testing across cytokines, were in overall agreement with the cytokine associations reported here for FLU09. In particular, EGF, GRO, sCD40-L and MCP-1, all clustered together in SHIVERS to absolute module BS3 and positively correlated with SARI in the SHIVERS previous analysis. In our current analysis of FLU09 these cytokines belong to the absolute BS3 module, which was positively associated with total and systemic symptom scores. In addition, Fractalkine, VEGF, TNF-α and GCSF belong to the BS4 absolute module in FLU09 which was positively associated with lower respiratory tract symptom scores (LRT). They were also previously reported to be positively associated with SARI in SHIVERS. In particular, Fractalkine was also significantly associated with LRT scores In FLU09 and had an odds-ratio of 16.52 for SARI in SHIVERS (58).
3.4. Adjustment for Mean Cytokine Level Reveals Negative Associations Between Modules and Clinical Phenotypes
While none of the absolute concentrations of cytokines or their modules were negatively associated with clinical phenotypes, we found several significant negative associations using cytokines and cytokine modules that had been adjusted for the mean cytokine concentration. Interestingly, some, but not all of the significant positive associations that were identified using absolute cytokine concentrations were also significant after adjustment for the mean.
FLU09 - as seen in Figure 4B, the adjusted BS1 module containing FLT3L, IL-13, IL-1β, IL-4, IL-5, IL-7, IL-9, and TNF-β was found to be significantly negatively associated with total and systemic symptoms (regression coefficients –0.557, –0.582, FWER p-values 0.0011, 0.008, respectively, as detailed in Table S2). Individual cytokines in this module were predominantly negatively associated with symptom scores, some with FDR ≤ 0.2, however, none of these associations were significant after FWER adjustment. The adjusted nasal wash modules did not have any significant positive associations with symptom scores (Figure 4D and Table S4). A single significant negative association was found between adjusted EGF concentrations and viral load (regression coefficient -0.281, FWER-p = 0.0157).
PICFLU - The adjusted BS4 module containing EGF, Eotaxin, FGF-2, Fractalkine (FKN), GRO, IFN-α2, IL-12-P70, IL-7, MDC, and sCD40-L was negatively associated with shock, pneumonia-ARDS and ECMO or death (odds ratio 0.463, 0.598, 0.494, FWER-p = 0.0002, 0.0155, 0.0283, respectively; Table S6). The adjusted concentration of EGF (member of BS4) was also found to be negatively associated with ECMO or death (OR = 0.211, FWER-p 0.043), albeit more weakly that of the BS4 module. No other individual adjusted cytokines were found to be negatively associated with clinical phenotypes. The adjusted BS3 module, which contained a similar group of cytokines to that of the absolute BS3 module, had positive associations with shock, pneumonia-ARDS and ECMO or death (odds ratio 3.01, 1.75, 2.46, FWER p-values 0.000002, 0.0095, 0.0042, respectively). The BS3 adjusted cytokines IL-6 and IP-10 were associated with shock, while IL-8 and MCP-1 were associated with both shock and pneumonia-ARDS. As with the absolute cytokine analysis, adjusted BS3 was associated with ECMO or death, while none of its constituents were associated on their own. The significance of all adjusted BS3 member cytokines with shock was weaker than the module's; the significance of the adjusted IL-8 association with pneumonia-ARDS was also weaker than that of BS3. However, the significance of the association of adjusted MCP-1 with pneumonia-ARDS was stronger than that of its module BS3.
SHIVERS - While no significant associations were detected among adjusted individual serum cytokines, we found that the adjusted BS6 module was positively associated with severe acute respiratory illness (SARI) (Figure S8B and Table S10). Furthermore, IL-4, IL-13, and TNF-β were part of the adjusted BS1 module of SHIVERS and were also in the adjusted BS1 module of FLU09 that was negatively associated with total and systemic symptom scores, as well as negatively associated with SARI in the previous report on SHIVERS (58).
3.5. Subsets of Cytokine Clusters Were Similar Across Datasets
We next asked whether cytokine modules were consistent across datasets, i.e., were there cytokine “cores”—clusters of cytokines that were consistently correlated during influenza infection. Since airway samples were available only for two out of three cohorts, this analysis was only performed using blood sample (serum or plasma) modules. To identify cytokine cores, we tallied the number of times that each pair of cytokines clustered together across the three blood datasets (Figures 6A,B). Cytokine cores were defined as groups of cytokines that clustered together in all three datasets. Cytokine cores were defined separately for the absolute and adjusted cytokine modules (Table 2). There is overall agreement between the absolute and adjusted cytokine cores. The most striking difference is the division of IP-10, MCP-1, IL-8, and MIP-1α into two different subsets.
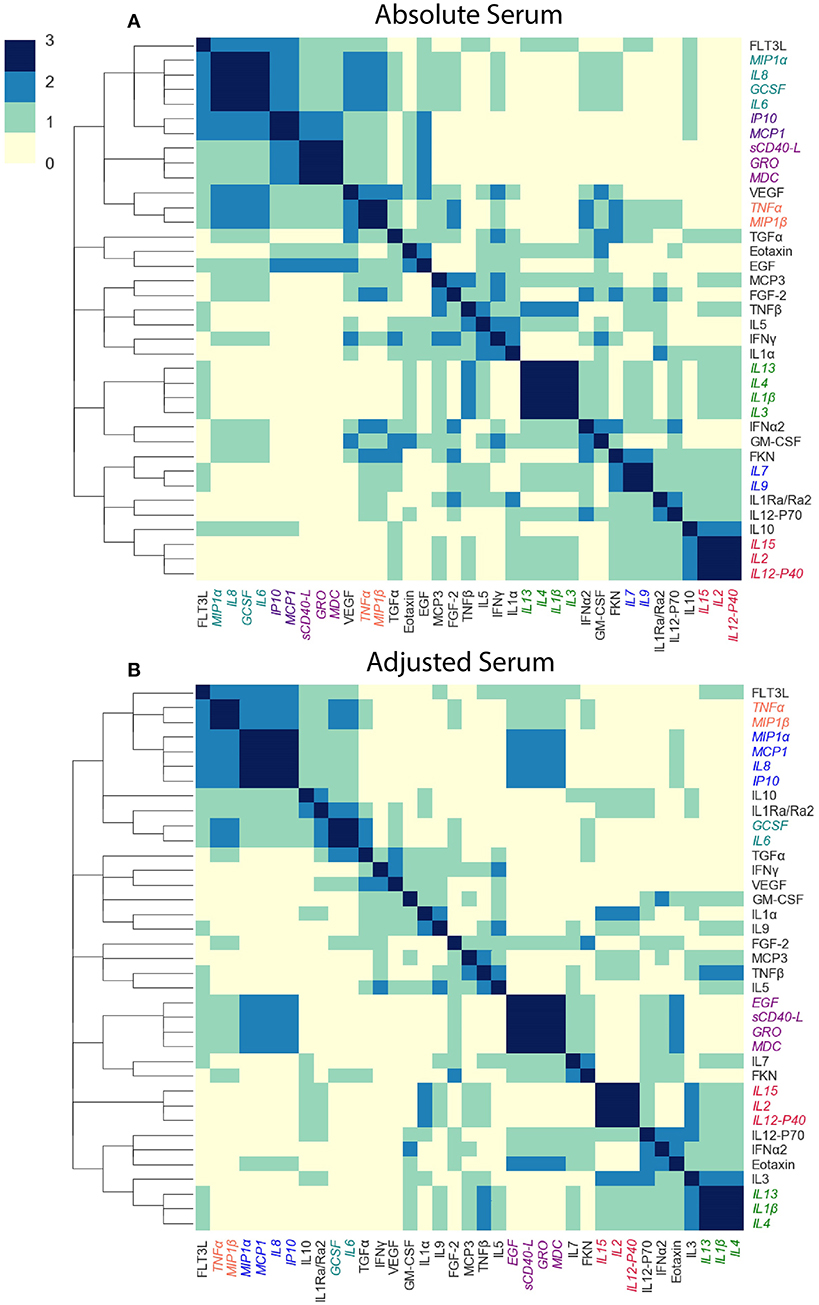
Figure 6. Defining cytokine cores. By leveraging information across cytokine profile datasets, we can identify cytokine cores—subsets of cytokines that consistently co-signal across all three blood datasets used in this study. Heatmaps of the number of times each pair of cytokines clustered together in all three cohorts, for adjusted (A) and absolute (B) blood sample data independently. Cytokine names are colored by cytokine cores.
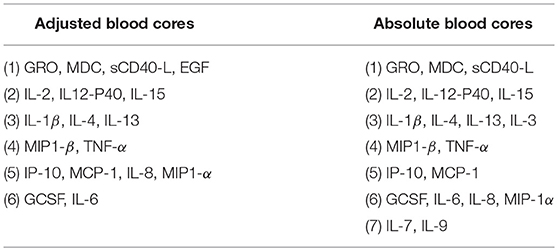
Table 2. Cytokine cores identified in absolute and adjusted blood samples independently.
To determine whether the cytokine cores were unique to influenza infected subjects, we constructed modules of adjusted and absolute plasma samples provided by 142 healthy volunteers in the FLU09 study. We found that overall, cytokine cores were consistent across influenza-infected and healthy controls with two exceptions: in the absolute cores, GCSF did not cluster together with other core-6 cytokines and cores-4 and -6 were not identified in the adjusted modules of healthy controls.
3.6. Core Modules Were Also Associated With Clinical Phenotypes
Each absolute or adjusted core was composed of cytokines that clustered together into the same module in all three cohorts (Tables 3, 4). For example, adjusted core-2 was composed of IL-12-P40, IL-15 and IL-2, which were members of PICFLU adjusted BS1, FLU09 adjusted BS5 and also SHIVERS adjusted BS5. We noted that most adjusted and some of the absolute cores (Figure 6) were composed of cytokines that were members of modules that exhibited strong associations with clinical phenotypes. For example, adjusted core-1 contained GRO, MDC, sCD40-L, and EGF, members of the PICFLU adjusted module BS4 (Figure 5B), which was negatively correlated with poor clinical phenotypes. Surprisingly, they were also members of the adjusted module BS3 from FLU09 (Figure 4B), which in contrast had mostly positive associations (significant only in the absolute measurements). Adjusted core-3 contained IL-1β, IL-4, and IL-13 that were part of the FLU09 adjusted module BS1, which was negatively associated with several symptom scores. Adjusted core-5 contained IP-10, MCP-1, IL-8, and MIP-1α that were part of FLU09 adjusted BS3 mentioned above, and also of adjusted PICFLU module BS3 which had significant positive associations with all phenotypes. Absolute core-5 and absolute core-6 cytokines were part of FLU09 and PICFLU absolute modules that had significant positive associations with phenotypes (Figures 4A, 5A).
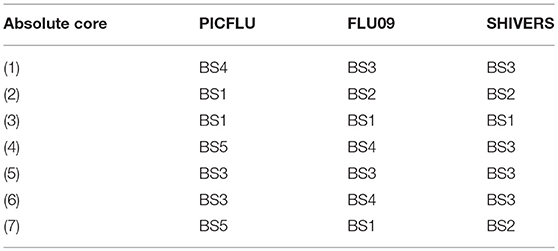
Table 3. Modules that construct the absolute cytokine cores by dataset.
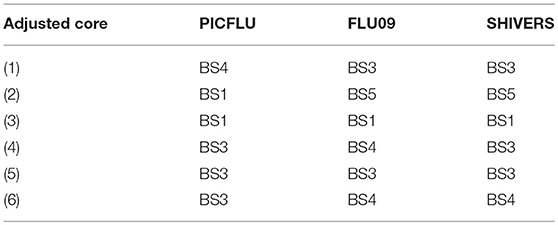
Table 4. Modules that construct the adjusted cytokine cores by dataset.
We then tested for associations between the cytokine cores and clinical phenotypes, using the same methodology described above. A subject's score for each core was calculated based on the mean cytokine concentration of cytokines within the core, after standardizing each cytokine to mean zero and unit variance. Figure 7 portrays the associations to clinical outcomes and symptoms for absolute and adjusted blood cytokines of influenza-positive FLU09 and PICFLU subjects, respectively. P-values for the coefficients describing the associations of cytokines and symptom scores were adjusted for multiple hypothesis tests within each presented dataset separately. P-values for the regression coefficients calculated for the core scores were adjusted independently of the coefficients calculated for individual cytokines. Individual cytokine p-values were adjusted across all cytokines and not only for the cytokines included in the core cytokine set.
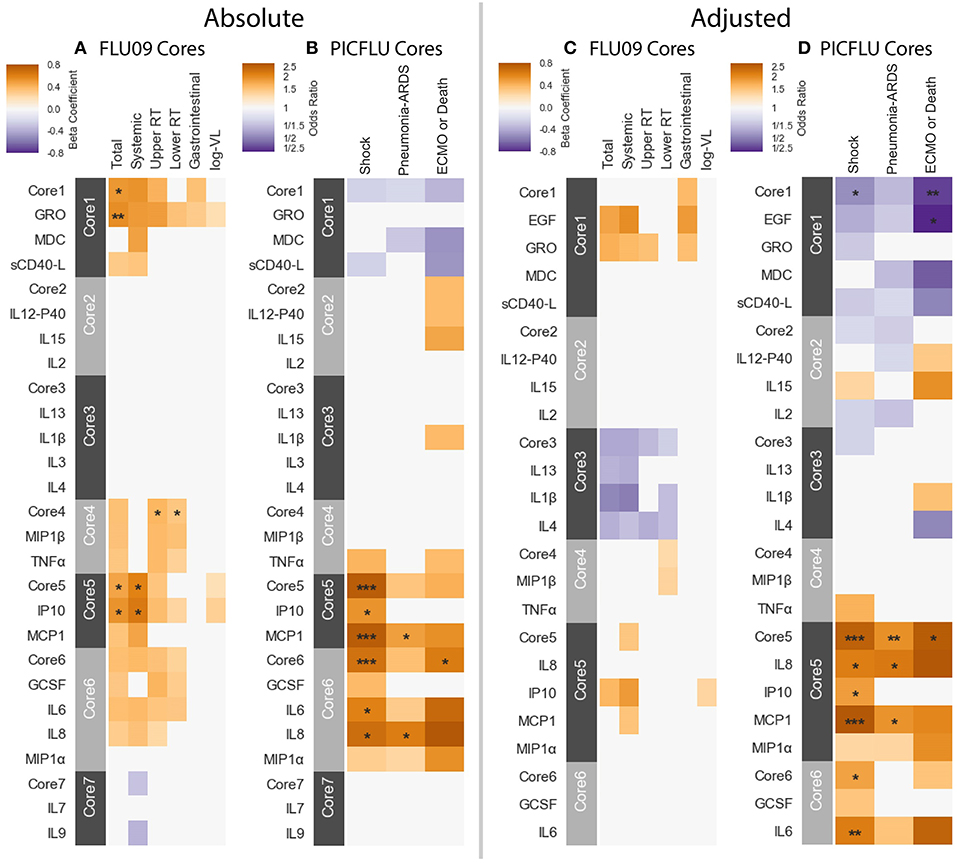
Figure 7. Cores constructed from groups of covarying cytokines (absolute and adjusted measurements separately) as detailed in section 3.5. Associations between cytokine cores and clinical phenotypes are shown for FLU09 (A,C) and PICFLU (B,D) for both raw and adjusted cytokine levels. Blood cytokine cores associations with phenotypes were estimated using regression while also controlling for other variables as described in section 3.3. Each cytokine or core is indicated along the rows. Heatmap color indicates the direction and magnitude of the regression coefficient. For each individual cytokine FDR and FWER adjustments are shown are controlled over all 37 cytokines. Only associations with false-discovery rate (FDR)-adjusted q ≤ 0.2 are colored. Asterisks indicate family-wise error rate (FWER)-adjusted p-values with ***, **, and * indicating p ≤ 0.0005, 0.005, and 0.05, respectively.
FLU09 - None of the adjusted plasma FLU09 cores were significantly associated with clinical symptoms, but trends were in agreement with the module associations (Figure 7 and Tables S11, S12). However, absolute cores were associated with symptoms: absolute core-1 was associated with total symptoms; core-4 was associated with lower and upper RT symptoms; and core-5 was associated with total and systemic symptoms. Each core's corresponding module was similarly associated with symptoms: BS3 which contained absolute core-1 and core-5 cytokines was associated with total and systemic symptoms; BS4 which contained absolute core-4 cytokines was associated with lower RT symptoms but not with upper RT symptoms (while core-4 itself was associated with both).
PICFLU - Significant associations were found with both absolute and adjusted cores (Figure 7 and Tables S13, S14). Absolute core-5 was positively associated with shock, absolute core-6 was positively correlated with shock and ECMO or death. Absolute core-5 and core-6 cytokines were members of absolute module BS3, which was also positively associated with shock and ECMO or death. Three adjusted cores, originating in two different modules, were associated with outcomes: adjusted core-1 was negatively associated with shock and ECMO or death, adjusted core-5 was positively associated with shock, pneumonia-ARDS and ECMO or death, and adjusted core-6 was positively associated with shock. Adjusted BS4 which contained adjusted core-1 cytokines was associated with all outcomes, while core-1 was negatively, but not significantly associated with pneumonia-ARDS after FWER adjustment. Adjusted BS3 which contained adjusted core-5 and -6 cytokines was positively associated with all outcomes.
SHIVERS - In the SHIVERS cohort, neither the absolute or adjusted cores were significantly associated with the SARI phenotype. The lack of association may be due in part to the small sample size in the first year of the study (n = 52).
3.7. Correlations Among Core Modulations Were Consistent Across Cohorts
We computed correlations between cores within each of the blood cytokine profile datasets, including the FLU09 healthy controls (see section 2.5 for details). Overall we found mostly positive significant correlations between absolute cores that were consistent across all datasets, with a few notable exceptions: cores-1 and -7 and cores-3 and -4 (Figure 8A).
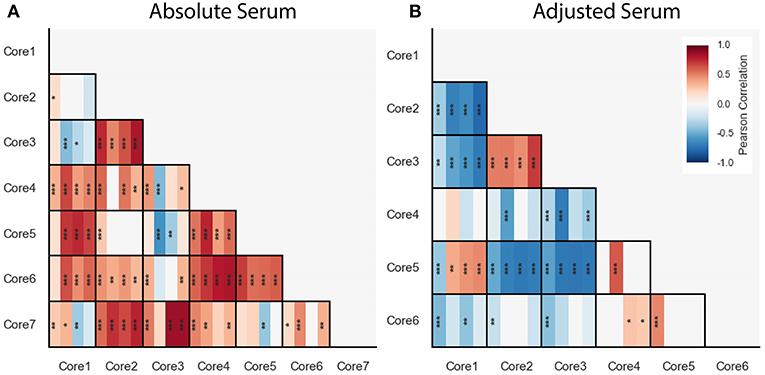
Figure 8. Pairwise Pearson correlations between absolute (A) and adjusted (B) blood cytokine cores within each dataset, presented with vertical stripes from left to right: PICFLU, SHIVERS, FLU09, and FLU09-healthy. Heatmap color indicates the correlation coefficient. P-values for the coefficients were adjusted for multiple hypothesis tests within each dataset separately. Only associations with false-discovery rate (FDR)-adjusted q ≤ 0.2 are colored. Asterisks indicate family-wise error rate (FWER)-adjusted p-values with ***, **, and * indicating p ≤ 0.0005, 0.005, and 0.05, respectively.
We also computed pairwise correlations for the adjusted cores (Figure 8B). Similarly to the absolute cores, overall correlations between cores were consistent across datasets except for one pair of cores (core-1 and core-5).
4. Discussion
Here we presented CytoMod—a data driven approach for analyzing cytokine profiles and their association with clinical phenotypes. Our approach leverages the inherent redundancy of cytokines to form modules—clusters of cytokines whose signals correlate across a cohort of individuals. CytoMod is an unsupervised method—i.e., it does not use any information about clinical phenotypes or outcomes to identify cytokine modules. Using cytokine modules increases the statistical power to detect associations with clinical phenotypes, by amplifying the signal within a module relative to the noise, as well as reducing the number of tests subject to multiplicity adjustment. It also allows for the identification of data-specific co-signaling cytokines, which may provide clues about the underlying immunological pathways. A preliminary version of CytoMod was applied in the analysis of the PICFLU cohort (51). Importantly, the method presented here includes automated selection of the number of modules using the gap-statistic heuristic. Indeed, when applied to the PICFLU cohort, it identified different numbers of modules than those analyzed in our previous work.
To our knowledge CytoMod is the first method for the analysis of cytokine profiles and clinical phenotypes that utilizes modules identified within cytokine expression data. In the age of multi-omics approaches, novel strategies for the integration of multiplex data with clinical outcome information can assist in the identification of complex pathological alterations of physiological networks. CytoMod only requires a dataset of cytokine measurements and (optionally) clinical phenotypes. Importantly, it does not assume that modules necessarily capture biological function.
CytoMod is based on unsupervised clustering which can help uncover inherent structures within a given dataset. Our work is related to previous work on methods for cluster analysis of variables (65–67), which groups together variables which are strongly related to each other and hold similar information. CytoMod can also be viewed as a dimensionality reduction method for cytokine profiles. There are a variety of other methods for dimensionality reduction that have been widely used for visualization and analysis of biological data. These include methods such as Principal Components Analysis (PCA) (68, 69), Linear Discriminant Analysis (LDA) (70), Factor Analysis (71) and t-sne (72). Most of these methods project the samples into a low-dimensional space by creating new features from linear combinations of the original features. In this new space the original coordinates (or features/cytokines) are not retained, thereby reducing the ability to draw biological interpretation. In contrast, our modules retain interpretability by grouping together individual cytokines that are co-expressed and can be further studied to allow gaining new insights into the underlying biological processes that generate these structures.
We applied CytoMod to three independent cohorts of influenza-infected subjects. The analyses of SHIVERS and FLU09 datasets presented here included previously unpublished data from additional study years, as well as data from healthy volunteers. To allow comparisons between the cohorts, we limited the number of cytokines analyzed to a subset of 37 cytokines that were quantified in all three cohorts. We found that in two of these cohorts, modules were significantly associated with clinical phenotypes, and in most cases the associations were stronger than those of individual cytokines within the module. Specifically, we found that across all modules in these two datasets, the association of the module with outcomes was more significant than that of an individual cytokine in 14 out of 22 cases in which the cytokine's association was significant. Furthermore, in 6 cases, a module had a significant association with a phenotype while non of its cytokines had any significant association.
In our previous analysis of FLU09, we analyzed only 11 pre-selected cytokines using data from years 1 to 2. In our current manuscript, we analyzed data from the entire study (years 1–5). We identified novel associations between modules and clinical phenotypes. Specifically, the adjusted BS1 module containing FLT3L, IL-13, IL-1β, IL-4, IL-5, IL-7, IL-9, and TNF-β was found to be significantly negatively associated with total and systemic symptoms. Out of these cytokines, only IL-1β was included in the previous analysis. In addition, we found novel associations of the absolute EGF, GRO, FKN levels that were not previously reported. In the analysis of the PICFLU study, which only included children admitted to the ICU with influenza infection, we found that the serum module BS3 is significantly associated with Shock and ECMO/death outcomes. Interestingly, this module contains IL-6, IL-8, and MCP-1, which have been previously reported to be hyperactivated in subjects with severe influenza infection (28). No significant associations with clinical phenotypes were detected in the SHIVERS cohort, though this may be due in part to its small sample size (n = 52), and sampling variability (58) which further limits the ability to detect associations. Interestingly, we note that univariate associations previously reported for this cohort (58), which were not adjusted for multiplicity testing across cytokines, were in overall agreement with the module associations reported here for FLU09 and in some cases with the cytokine cores.
We focused here on analyzing cytokine associations with outcomes that were significant following a stringent FWER adjustment procedure. In fact, all of the previously reported FDR-adjusted FLU09 associations based on data from years 1–2 (49) were also significant using FDR-adjustment on the complete years 1–5 dataset, and three of them were also FWER significant (when adjusted across all 37 cytokines analyzed here). These findings suggest that many of the associations with FDR q-values ≤ 0.2 may also be worth further exploration (Figure S9). The fact that many individual cytokines within FWER significant modules have associations with clinical phenotypes with the less stringent FDR q-value threshold of 0.2, while only a few of them have FWER significant associations, demonstrates the increase in statistical power provided by the modular cytokine approach. The CytoMod method considers both absolute and adjusted cytokine levels, since immune cells may be sensitive both to absolute and relative cytokine concentrations (73–75). While some positive associations with clinical phenotypes were observed using both the absolute and adjusted cytokines and modules, we found that significant negative associations with clinical phenotypes were found only with the adjusted modules. This is likely due to the fact that adjustment to the overall cytokine expression level may uncover differences in cytokine levels that are expressed at relatively low levels. Specifically, we found that the adjusted BS1 module in FLU09 was negatively associated with total and systemic symptoms, and that the adjusted BS4 module in PICFLU was negatively associated with the clinical phenotypes of shock, pneumonia-ARDS and ECMO-death. Interestingly, some of the BS4 cytokines were positively associated to FLU09 symptom scores when considering the less stringent FDR q-value ≤ 0.2. These results highlight the importance of analyzing both absolute and adjusted cytokine levels.
By analyzing three independent cohorts of subjects naturally infected with influenza, we were able to identify cytokine “cores”—subsets of cytokines that consistently clustered together across datasets. Cores were extracted from the modules directly and were identified without using any information about clinical outcomes or subject demographics. Interestingly, the majority of these cores clustered together in the set of 142 healthy controls from the FLU09 study, suggesting that these cores may represent sets of co-signaling cytokines. Some of these cores include cytokines that have been reported to have similar roles: For example: (1) adjusted core-3 which includes IL-1β, IL-4, and IL-13 contribute to epithelial repair mechanisms (4); (2) IP-10, MCP-1, IL-8, and MIP-1α which belong to adjusted core-5 are chemokines that are key inflammatory mediators (1); (3) IL-2, IL-15, and IL-12-p40 in adjusted and absolute core-2 are involved in T-cell activation (76, 77).
While we found that the cytokine cores were significantly associated with clinical phenotypes, the associations of the cytokine modules that were defined separately for each dataset were overall stronger. This is not surprising for two reasons: (1) using the strict definition of cores used here (co-clustering in all 3 datasets), cores are typically smaller than data-driven modules and are more sensitive to measurement noise; (2) Data driven modules of a specific cohort may also be affected by other covariates which may be specific to that cohort, and are not captured by the cytokine “cores” which are created using multiple datasets.
We analyzed correlations between cytokine cores, and compared these across datasets in both the absolute and adjusted datasets. We found that overall, the correlations between different cytokine cores were consistent across the three datasets, as well as in a cohort of healthy controls. However, we found one notable exception: adjusted core-1 and core-5 were negatively associated only in the PICFLU dataset. This is also reflected in the fact that core-1 (EGF, GRO, MDC, and sCD40-L) was weakly positively associated with outcome in a cohort of mild influenza infection (FLU09) and was negatively associated with outcome of severe influenza infection (PICFLU).
The existence of cytokine cores, and their association with clinical phenotypes despite a variety of differences between the cohorts suggest that these cores may represent stable underlying cytokine modules that consistently co-signal during influenza infection, and in some cases also in a healthy state. Cytokine cores may relate to specific functions and underlying biological processes that govern the complex cytokine signaling network. Nonetheless, defining robust cytokine cores requires large scale analysis of multiple cytokine datasets. As additional cytokine profile datasets are generated and made publicly available, cores can be dynamically re-defined, including defining “softer” probabilistic cores based on frequency of co-occurrence across many datasets and conditions. Identification of consistent cytokine subsets may provide a basis for the selection of biomarkers and the development of targeted immune assays, as part of a novel approach for developing future point-of-care diagnostic tests based on cytokine measurements that may be used for many different infections.
CytoMod groups cytokines into modules so that each cytokine belongs to a single module. We hypothesize that similar to genes, each cytokine may play several functional roles under different immune contexts. This would be best captured by “soft” modules, in which each cytokine may belong to more than one module. Once a sufficiently large number of cytokine datasets are analyzed such softer modules may be identified and annotated, similar to annotations of gene modules (52, 57). Our analysis of three datasets should be viewed as a first step in this direction.
CytoMod can be applied to any cytokine profile dataset and does not make any assumptions regarding the specific technology that was used to quantify cytokines. Furthermore, the modular approach allows identification of co-signaling cytokines across study years, even if the specific kit used to quantify cytokines was changed during the study, or other changes to the study were implemented. This is due to the fact that correlations are computed between cytokines across study subjects. Indeed despite significant differences between the cytokine measurements in years 1 and 2 of the SHIVERS study, we used both years to generate cytokine modules for this dataset.
In summary, using a modular approach to analyze cytokine profile datasets provides two major advantages: (1) It increases statistical power to detect associations with clinical phenotypes; and (2) By comparing modules obtained from different independently sampled datasets, we can identify cytokine cores - sets of consistently co-signaling cytokines. By aggregating cytokine information across datasets, this approach may help identify inherent, and condition-specific groupings of cytokines, providing the basis for future mechanistic molecular studies. A Python implementation code of CytoMod can be found at https://github.com/liel-cohen/CytoMod as well as in an interactive Jupyter Notebook available at https://nbviewer.jupyter.org/github/liel-cohen/CytoMod/blob/master/cytomod_notebook.ipynb.
Data Availability
All datasets generated for this study are included in the Supplementary Files.
Author Contributions
AF-G, LC, and TH developed the computational method. AF-G and LC analyzed data. TH designed the study. AR, AP-M, S-SW, JR, TW, RS, QH, RW, and PT enrolled the clinical cohorts, and generated data. LC and TH wrote the paper. AF-G, AR, S-SW, and PT commented and edited the paper.
Funding
PICFLU was funded by the National Institutes of Health (NIH AI084011 to AR) and the Centers for Disease Control and Prevention (CDC). The SHIVERS work was supported by the Centers for Disease Control and Prevention (CDC), Department of Health and Human Services (cooperative agreement 1U01IP000480-01 between the Institute for Environmental Science and Research and the CDC's National Center for Immunization and Respiratory Diseases Influenza Division). The FLU09 study was supported in part by the National Institute of Allergy and Infectious Diseases, the National Institutes of Health, under contract number HHSN266200700005C and ALSAC.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fimmu.2019.01338/full#supplementary-material
References
1. Miller MD, Krangel MS. Biology and biochemistry of the chemokines: a family of chemotactic and inflammatory cytokines. Crit Rev Immunol. (1992) 12:17–46.
2. Kishimoto T, Taga T, Akira S. Cytokine signal transduction. Cell. (1994) 76:253–62. doi: 10.1016/0092-8674(94)90333-6
3. Bidwell J, Keen L, Gallagher G, Kimberly R, Huizinga T, McDermott M, et al. Cytokine gene polymorphism in human disease: on-line databases. Genes Immunity. (1999) 1:3. doi: 10.1038/sj.gene.6363645
4. Crosby LM, Waters CM. Epithelial repair mechanisms in the lung. Am J Physiol Lung Cell Mol Physiol. (2010) 298:L715–31. doi: 10.1152/ajplung.00361.2009
5. Goldberg RB. Cytokine and cytokine-like inflammation markers, endothelial dysfunction, and imbalanced coagulation in development of diabetes and its complications. J Clin Endocrinol Metab. (2009) 94:3171–82. doi: 10.1210/jc.2008-2534
6. Jagannathan-Bogdan M, McDonnell ME, Shin H, Rehman Q, Hasturk H, Apovian CM, et al. Elevated proinflammatory cytokine production by a skewed T cell compartment requires monocytes and promotes inflammation in type 2 diabetes. J Immunol. (2011) 186:1162–72. doi: 10.4049/jimmunol.1002615
7. Swardfager W, Lanctôt K, Rothenburg L, Wong A, Cappell J, Herrmann N. A meta-analysis of cytokines in Alzheimer's disease. Biol Psychiatry. (2010) 68:930–41. doi: 10.1016/j.biopsych.2010.06.012
8. Lin WW, Karin M. A cytokine-mediated link between innate immunity, inflammation, and cancer. J Clin Invest. (2007) 117:1175–83. doi: 10.1172/JCI31537
9. Lippitz BE. Cytokine patterns in patients with cancer: a systematic review. Lancet Oncol. (2013) 14:e218–28. doi: 10.1016/S1470-2045(12)70582-X
10. Mantovani A, Allavena P, Sica A, Balkwill F. Cancer-related inflammation. Nature. (2008) 454:436. doi: 10.1038/nature07205
11. Lazennec G, Richmond A. Chemokines and chemokine receptors: new insights into cancer-related inflammation. Trends Mol Med. (2010) 16:133–44. doi: 10.1016/j.molmed.2010.01.003
12. Deswal A, Petersen NJ, Feldman AM, Young JB, White BG, Mann DL. Cytokines and cytokine receptors in advanced heart failure: an analysis of the cytokine database from the Vesnarinone trial (VEST). Circulation. (2001) 103:2055–9. doi: 10.1161/01.CIR.103.16.2055
13. Mann DL. Innate immunity and the failing heart: the cytokine hypothesis revisited. Circ Res. (2015) 116:1254–68. doi: 10.1161/CIRCRESAHA.116.302317
14. Ohga S, Nomura A, Takada H, Hara T. Immunological aspects of Epstein–Barr virus infection. Crit Rev Oncol Hematol. (2002) 44:203–15. doi: 10.1016/S1040-8428(02)00112-9
15. Legg JP, Hussain IR, Warner JA, Johnston SL, Warner JO. Type 1 and type 2 cytokine imbalance in acute respiratory syncytial virus bronchiolitis. Am J Respirat Crit Care Med. (2003) 168:633–9. doi: 10.1164/rccm.200210-1148OC
16. Srikiatkhachorn A, Green S. Markers of dengue disease severity. In: Rothman AL, Editor. Dengue Virus. Berlin; Heidelberg: Springer (2010). p. 67–82. doi: 10.1007/978-3-642-02215-9_6
17. Roberts L, Passmore JAS, Williamson C, Little F, Bebell LM, Mlisana K, et al. Plasma cytokine levels during acute HIV-1 infection predict HIV disease progression. AIDS (London, England). (2010) 24:819. doi: 10.1097/QAD.0b013e3283367836
18. Stacey AR, Norris PJ, Qin L, Haygreen EA, Taylor E, Heitman J, et al. Induction of a striking systemic cytokine cascade prior to peak viremia in acute human immunodeficiency virus type 1 infection, in contrast to more modest and delayed responses in acute hepatitis B and C virus infections. J Virol. (2009) 83:3719–33. doi: 10.1128/JVI.01844-08
19. Thompson WW, Shay DK, Weintraub E, Brammer L, Bridges CB, Cox NJ, et al. Influenza-associated hospitalizations in the United States. JAMA. (2004) 292:1333–40. doi: 10.1001/jama.292.11.1333
20. Webster RG, Bean WJ, Gorman OT, Chambers TM, Kawaoka Y. Evolution and ecology of influenza A viruses. Microbiol Rev. (1992) 56:152–79.
21. Taubenberger JK, Morens DM. 1918 Influenza: the mother of all pandemics. Emerg Infect Dis. (2006) 12:15. doi: 10.3201/eid1209.05-0979
22. Broaddus VC, Mason RC, Ernst JD, King TE, Lazarus SC, Murray JF, et al. Murray and Nadel's Textbook of Respiratory Medicine. Philadelphia, PA: Elsevier Health Sciences (2015).
23. Xi-zhi JG, Thomas PG. New fronts emerge in the influenza cytokine storm. In: Teijaro J, Editor. Seminars in Immunopathology. Vol. 39. Berlin; Heidelberg: Springer (2017). p. 541–50. doi: 10.1007/s00281-017-0636-y
24. Van Reeth K. Cytokines in the pathogenesis of influenza. Vet Microbiol. (2000) 74:109–16. doi: 10.1016/S0378-1135(00)00171-1
25. Chan M, Cheung C, Chui W, Tsao S, Nicholls J, Chan Y, et al. Proinflammatory cytokine responses induced by influenza A (H5N1) viruses in primary human alveolar and bronchial epithelial cells. Respirat Res. (2005) 6:135. doi: 10.1186/1465-9921-6-135
26. Szretter KJ, Gangappa S, Lu X, Smith C, Shieh WJ, Zaki SR, et al. Role of host cytokine responses in the pathogenesis of avian H5N1 influenza viruses in mice. J virol. (2007) 81:2736–44. doi: 10.1128/JVI.02336-06
27. Kaiser L, Fritz RS, Straus SE, Gubareva L, Hayden FG. Symptom pathogenesis during acute influenza: interleukin-6 and other cytokine responses. J Med Virol. (2001) 64:262–8. doi: 10.1002/jmv.1045
28. Lee N, Wong CK, Chan PK, Chan MC, Wong RY, Lun SW, et al. Cytokine response patterns in severe pandemic 2009 H1N1 and seasonal influenza among hospitalized adults. PLoS ONE. (2011) 6:e26050. doi: 10.1371/journal.pone.0026050
29. Cheung C, Poon L, Lau A, Luk W, Lau Y, Shortridge K, et al. Induction of proinflammatory cytokines in human macrophages by influenza A (H5N1) viruses: a mechanism for the unusual severity of human disease? Lancet. (2002) 360:1831–7. doi: 10.1016/S0140-6736(02)11772-7
30. Fritz RS, Hayden FG, Calfee DP, Cass LM, Peng AW, Alvord WG, et al. Nasal cytokine and chemokine responses in experimental influenza A virus infection: results of a placebo-controlled trial of intravenous zanamivir treatment. J Infect Dis. (1999) 180:586–93. doi: 10.1086/314938
31. Hayden FG, Fritz R, Lobo MC, Alvord W, Strober W, Straus SE. Local and systemic cytokine responses during experimental human influenza A virus infection. Relation to symptom formation and host defense. J Clin Invest. (1998) 101:643–9. doi: 10.1172/JCI1355
32. To KK, Hung IF, Li IW, Lee KL, Koo CK, Yan WW, et al. Delayed clearance of viral load and marked cytokine activation in severe cases of pandemic H1N1 2009 influenza virus infection. Clin Infect Dis. (2010) 50:850–9. doi: 10.1086/650581
33. Peiris J, Yu W, Leung C, Cheung C, Ng W, Nicholls Ja, et al. Re-emergence of fatal human influenza A subtype H5N1 disease. Lancet. (2004) 363:617–9. doi: 10.1016/S0140-6736(04)15595-5
34. Feldmann M, Maini RN. Anti-TNFα therapy of rheumatoid arthritis: what have we learned? Ann Rev Immunol. (2001) 19:163–96. doi: 10.1146/annurev.immunol.19.1.163
35. Siebert S, Tsoukas A, Robertson J, McInnes I. Cytokines as therapeutic targets in rheumatoid arthritis and other inflammatory diseases. Pharmacolo Rev. (2015) 67:280–309. doi: 10.1124/pr.114.009639
36. Trikha M, Corringham R, Klein B, Rossi JF. Targeted anti-interleukin-6 monoclonal antibody therapy for cancer: a review of the rationale and clinical evidence. Clin Cancer Res. (2003) 9:4653–65.
37. Llorente L, Richaud-Patin Y, García-Padilla C, Claret E, Jakez-Ocampo J, Cardiel MH, et al. Clinical and biologic effects of anti–interleukin-10 monoclonal antibody administration in systemic lupus erythematosus. Arthr Rheumat. (2000) 43:1790–800. doi: 10.1002/1529-0131(200008)43:8<1790::AID-ANR15>3.0.CO;2-2
38. Campa M, Mansouri B, Warren R, Menter A. A review of biologic therapies targeting IL-23 and IL-17 for use in moderate-to-severe plaque psoriasis. Dermatol Therapy. (2016) 6:1–12. doi: 10.1007/s13555-015-0092-3
39. Nahta R, Esteva FJ. Herceptin: mechanisms of action and resistance. Cancer Lett. (2006) 232:123–38. doi: 10.1016/j.canlet.2005.01.041
40. Urquhart L. Market watch: top drugs and companies by sales in 2017. Nat Rev Drug Disc. (2018) 17:232. doi: 10.1038/nrd.2018.42
41. Chun HY, Chung JW, Kim HA, Yun JM, Jeon JY, Ye YM, et al. Cytokine IL-6 and IL-10 as biomarkers in systemic lupus erythematosus. J Clin Immunol. (2007) 27:461–6. doi: 10.1007/s10875-007-9104-0
42. Maier B, Lefering R, Lehnert M, Laurer HL, Steudel WI, Neugebauer EA, et al. Early versus late onset of multiple organ failure is associated with differing patterns of plasma cytokine biomarker expression and outcome after severe trauma. Shock. (2007) 28:668–74. doi: 10.1097/shk.0b013e318123e64e
43. Choi JW, Liu H, Shin DH, Yu GI, Hwang JS, Kim ES, et al. Proteomic and cytokine plasma biomarkers for predicting progression from colorectal adenoma to carcinoma in human patients. Proteomics. (2013) 13:2361–74. doi: 10.1002/pmic.201200550
44. Volpin G, Cohen M, Assaf M, Meir T, Katz R, Pollack S. Cytokine levels (IL-4, IL-6, IL-8 and TGFβ) as potential biomarkers of systemic inflammatory response in trauma patients. Int Orthopaed. (2014) 38:1303–9. doi: 10.1007/s00264-013-2261-2
45. Petersen JW, Felker GM. Inflammatory biomarkers in heart failure. Congest Heart Fail. (2006) 12:324–8. doi: 10.1111/j.1527-5299.2006.05595.x
46. Vistnes M, Christensen G, Omland T. Multiple cytokine biomarkers in heart failure. Expert Rev Mol Diagn. (2010) 10:147–57. doi: 10.1586/erm.10.3
47. Vilček J, Feldmann M. Historical review: cytokines as therapeutics and targets of therapeutics. Trends Pharmacol Sci. (2004) 25:201–9. doi: 10.1016/j.tips.2004.02.011
48. de Jager W, Bourcier K, Rijkers GT, Prakken BJ, Seyfert-Margolis V. Prerequisites for cytokine measurements in clinical trials with multiplex immunoassays. BMC Immunol. (2009) 10:52. doi: 10.1186/1471-2172-10-52
49. Oshansky CM, Gartland AJ, Wong SS, Jeevan T, Wang D, Roddam PL, et al. Mucosal immune responses predict clinical outcomes during influenza infection independently of age and viral load. Am J Respirat Crit Care Med. (2014) 189:449–62. doi: 10.1164/rccm.201309-1616OC
50. Mantovani A. The chemokine system: redundancy for robust outputs. Immunol Today. (1999) 20:254–7. doi: 10.1016/S0167-5699(99)01469-3
51. Fiore-Gartland A, Panoskaltsis-Mortari A, Agan AA, Mistry AJ, Thomas PG, Matthay MA, et al. Cytokine Profiles of Severe Influenza Virus-Related complications in Children. Front Immunol. (2017) 8:1423. doi: 10.3389/fimmu.2017.01423
52. Eisen MB, Spellman PT, Brown PO, Botstein D. Cluster analysis and display of genome-wide expression patterns. Proc Natl Acad Sci USA. (1998) 95:14863–8. doi: 10.1073/pnas.95.25.14863
53. Chaussabel D, Quinn C, Shen J, Patel P, Glaser C, Baldwin N, et al. A modular analysis framework for blood genomics studies: application to systemic lupus erythematosus. Immunity. (2008) 29:150–64. doi: 10.1016/j.immuni.2008.05.012
54. Chaussabel D, Baldwin N. Democratizing systems immunology with modular transcriptional repertoire analyses. Nat Rev Immunol. (2014) 14:271. doi: 10.1038/nri3642
55. D'haeseleer P. How does gene expression clustering work? Nat Biotechnol. (2005) 23:1499. doi: 10.1038/nbt1205-1499
56. Jiang D, Tang C, Zhang A. Cluster analysis for gene expression data: a survey. IEEE Trans Knowl Data Eng. (2004) 16:1370–86. doi: 10.1109/TKDE.2004.68
57. Saelens W, Cannoodt R, Saeys Y. A comprehensive evaluation of module detection methods for gene expression data. Nat Commun. (2018) 9:1090. doi: 10.1038/s41467-018-03424-4
58. Wong SS, Oshansky CM, Guo XZJ, Ralston J, Wood T, Seeds R, et al. Severe influenza is characterized by prolonged immune activation: results from the SHIVERS Cohort Study. J Infect Dis. (2017) 217:245–56. doi: 10.1093/infdis/jix571
59. Organization WH. Global Epidemiological Surveillance Standards for Influenza 2014. p. 14. Available online at: http://www.who.int/influenza/resources/documents/WHO_Epidemiological_Influenza_Surveillance_Standards_2014.pdf
60. Seo J, Shneiderman B. Interactively exploring hierarchical clustering results [gene identification]. Computer. (2002) 35:80–6. doi: 10.1109/MC.2002.1016905
61. Dudoit S, Fridlyand J. Bagging to improve the accuracy of a clustering procedure. Bioinformatics. (2003) 19:1090–9. doi: 10.1093/bioinformatics/btg038
62. Tibshirani R, Walther G, Hastie T. Estimating the number of clusters in a data set via the gap statistic. J R Stat Soc B. (2001) 63:411–23. doi: 10.1111/1467-9868.00293
63. Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc B. (1995) 57:289–300. doi: 10.1111/j.2517-6161.1995.tb02031.x
64. Holm S. A simple sequentially rejective multiple test procedure. Scandin J Stat. (1979) 6:65–70.
65. Krier C, François D, Rossi F, Verleysen M. Feature clustering and mutual information for the selection of variables in spectral data. In: ESANN (Bruges) (2007). p. 157–62.
66. Vigneau E, Qannari E. Clustering of variables around latent components. Commun Stat Simul Comput. (2003) 32:1131–50. doi: 10.1081/SAC-120023882
67. Chavent M, Kuentz V, Liquet B, Saracco L. ClustOfVar: an R package for the clustering of variables. arXiv [preprint] arXiv:11120295 (2011). doi: 10.18637/jss.v050.i13
68. Hotelling H. Analysis of a complex of statistical variables into principal components. J Educ Psychol. (1933) 24:417. doi: 10.1037/h0071325
69. Pearson K. On lines and planes of closest fit to systems of points in space. Lond Edinburgh Dublin Philos Mag J Sci. (1901) 2:559–72. doi: 10.1080/14786440109462720
70. Rao CR. The utilization of multiple measurements in problems of biological classification. J R Stat Soc B. (1948) 10:159–203. doi: 10.1111/j.2517-6161.1948.tb00008.x
71. Bartholomew DJ. The foundations of factor analysis. Biometrika. (1984) 71:221–32. doi: 10.1093/biomet/71.2.221
73. Dodoo D, Omer FM, Todd J, Akanmori BD, Koram KA, Riley EM. Absolute levels and ratios of proinflammatory and anti-inflammatory cytokine production in vitro predict clinical immunity to Plasmodium falciparum malaria. J Infect Dis. (2002) 185:971–79. doi: 10.1086/339408
74. Kilic T, Ural D, Ural E, Yumuk Z, Agacdiken A, Sahin T, et al. Relation between proinflammatory to anti-inflammatory cytokine ratios and long-term prognosis in patients with non-ST elevation acute coronary syndrome. Heart. (2006) 92:1041–6. doi: 10.1136/hrt.2005.080382
75. Biswas S, Ghoshal PK, Mandal SC, Mandal N. Relation of anti- to pro-inflammatory cytokine ratios with acute myocardial infarction. Korean J Intern Med. (2010) 25:44–50. doi: 10.3904/kjim.2010.25.1.44
76. Cornish GH, Sinclair LV, Cantrell DA. Differential regulation of T-cell growth by IL-2 and IL-15. Blood. (2006) 108:600–8. doi: 10.1182/blood-2005-12-4827
Keywords: innate immunology, cytokines, chemokines, influenza, biomarker
Citation: Cohen L, Fiore-Gartland A, Randolph AG, Panoskaltsis-Mortari A, Wong S-S, Ralston J, Wood T, Seeds R, Huang QS, Webby RJ, Thomas PG and Hertz T (2019) A Modular Cytokine Analysis Method Reveals Novel Associations With Clinical Phenotypes and Identifies Sets of Co-signaling Cytokines Across Influenza Natural Infection Cohorts and Healthy Controls. Front. Immunol. 10:1338. doi: 10.3389/fimmu.2019.01338
Received: 13 February 2019; Accepted: 28 May 2019;
Published: 18 June 2019.
Edited by:
Benny Chain, University College London, United KingdomReviewed by:
Yaron E. Antebi, California Institute of Technology, United StatesAntonio Riva, Foundation for Liver Research, United Kingdom
Mahdad Noursadeghi, University College London, United Kingdom
Copyright © 2019 Cohen, Fiore-Gartland, Randolph, Panoskaltsis-Mortari, Wong, Ralston, Wood, Seeds, Huang, Webby, Thomas and Hertz. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tomer Hertz, thertz@bgu.ac.il
†Joint first co-authors