
Abstract
Objective To investigate the abrogation of COVID-19 case declines from predicted rates in the US in relationship to viral variants and mutations.
Design Epidemiological prediction and time series study of COVID-19 in the US by State.
Setting Community testing and sequencing of COVID-19 in the US.
Participants Time series US COVID-19 case data from the Johns Hopkins University CSSE database. Time series US Variant and Mutation data from the GISAID database.
Main outcome measures Primary outcomes were statistical modeling of US state deviations from epidemiological predictions, percentage of COVID-19 variants, percentage of COVID-19 mutations, and reported SARS-CoV-2 infections.
Results Deviations in epidemiological predictions of COVID-19 case declines in the North Eastern US in March 2021 were highly positively related to percentage of B.1.526 (Iota) lineage (p < 10e − 7) and B.1.526.2 (p < 10 − 8) and the T95I mutation (p < 10e − 9). They were related inversely to B.1.427 and B.1.429 (Epsilon) and there was a trend for association with B.1.1.7 (Alpha) lineage.
Conclusion Deviations from accurate predictive models are useful for investigating potential immune escape of COVID-19 variants at the population level. The B.1.526 and B.1.526.2 lineages likely have a high potential for immune escape and should be designated as variants of concern. The T95I mutation which is present in the B.1.526, B.1.526.2, and B.1.617.2 (Delta) lineages in the US warrants further investigation as a mutation of concern.
Introduction
Since the middle of 2020 many variants of SARS-CoV-2 have emerged. The emergence of these variants has led to second and third waves of COVID-19 cases in many countries including the US, Britain, and India. These variants have claimed numerous lives and are responsible for the overcrowding of hospitals and other healthcare services. Each SARS-CoV-2 variant is characterized by mutations on the genome of SARS-CoV-2. Some of these mutations impart advantages to the variants such as higher transmission rates or escape from immunity from previous COVID-19 infection or vaccination.
Many epidemiological models predicted a decline in COVID-19 cases in the US in February and March of 2021 from a combination of natural immunity and previous infection [1]. Epidemiologists expected that this may be delayed by variants of concern [1]. The B.1.1.7 (Alpha) lineage (UK origin) was amongst the most concerning of the known variants in the US. The B.1.1.7 lineage was found to be 43 to 90% more transmissible compared to the previous variants based on the use of social contact, mobility data, and other demographic indicators of COVID-19 [2]. Consequently, studies point out that the number of cases would be considerably higher compared to what was observed in 2020, without fast-paced vaccine roll-out [1] [2](5,6). The B.1.1.7 variant (UK origin) had a significant decrease in neutralization, specifically among populations aged above 55 [3](9). The B.1.1.7 variant does not appear to raise concerns regarding the vaccine’s efficacy in real world or antibody neutralization studies [4] [5](7,8). The US also had two variants that originated in California-B.1.429 and B.1.427 (Epsilon). These exhibit a 18.6-24% increase in transmission compared to wild-type. B1.427 [6] specifically shows a 3-6 fold reduction in neutralizing titers of vaccinated or convalescent individuals [7]. It can be expected that so long as transmission rates are high, new variants will continue to emerge, and each must be treated as a new threat with the potential to escape prior immunity.
Other variants of concern, which included the P.1 and P.2 (Zeta) lineages (Brazilian origin) and the B.1.351 (Beta, S. African origin) were not in the US in significant enough numbers to pose an immediate threat. Although, the B.1.351 variant has shown potential for immune escape and therefore can reduce the efficiency of vaccines [3](9).
Despite the CDC and other epidemiological models predicting case declines in late 2020 and early 2021, the US saw continued cases in the winter and spring of 2021 in the US with New York City as the epicenter (fig 1A, 5). In addition, a new variant arising from the Washington Heights area of New York was identified([8]).
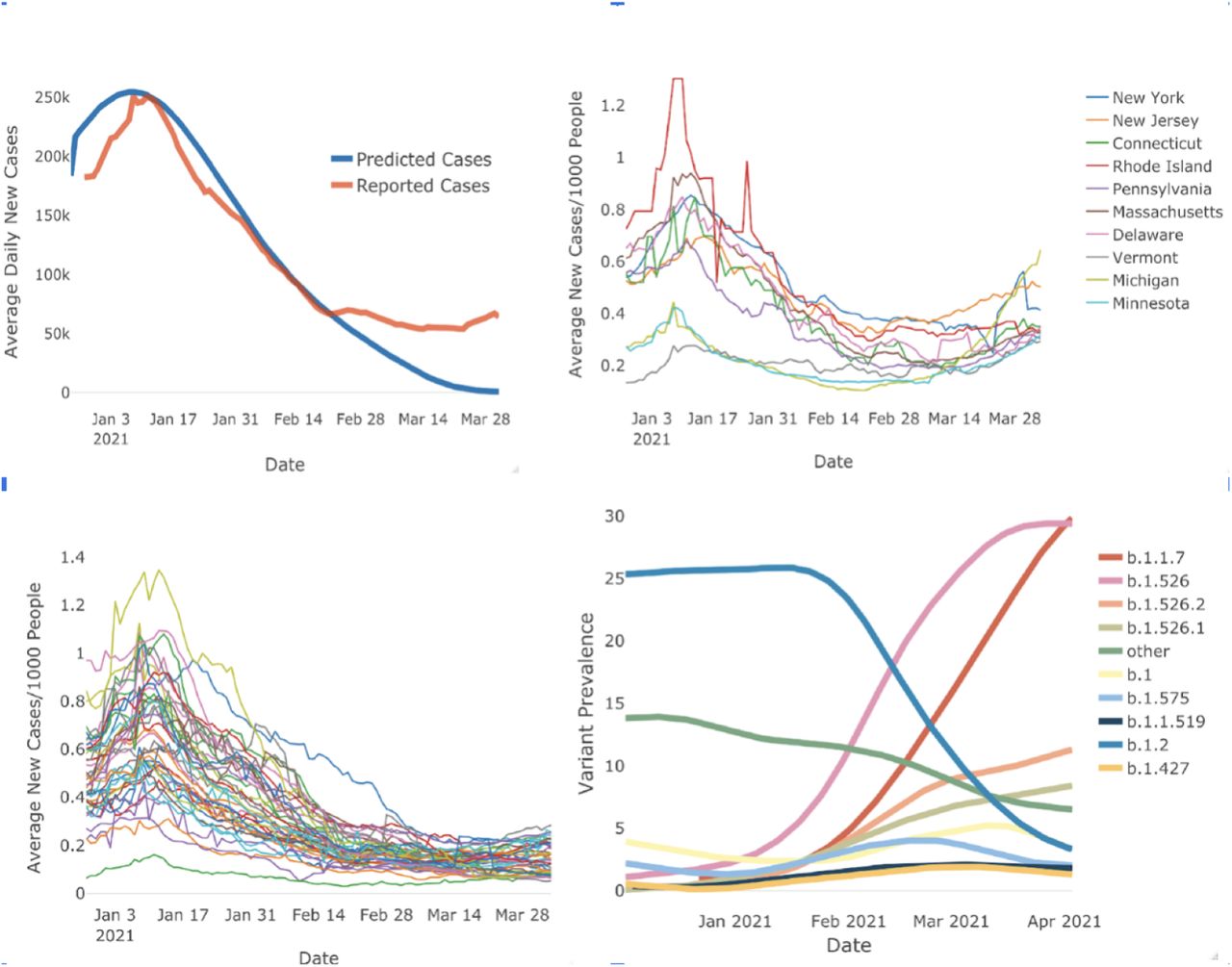
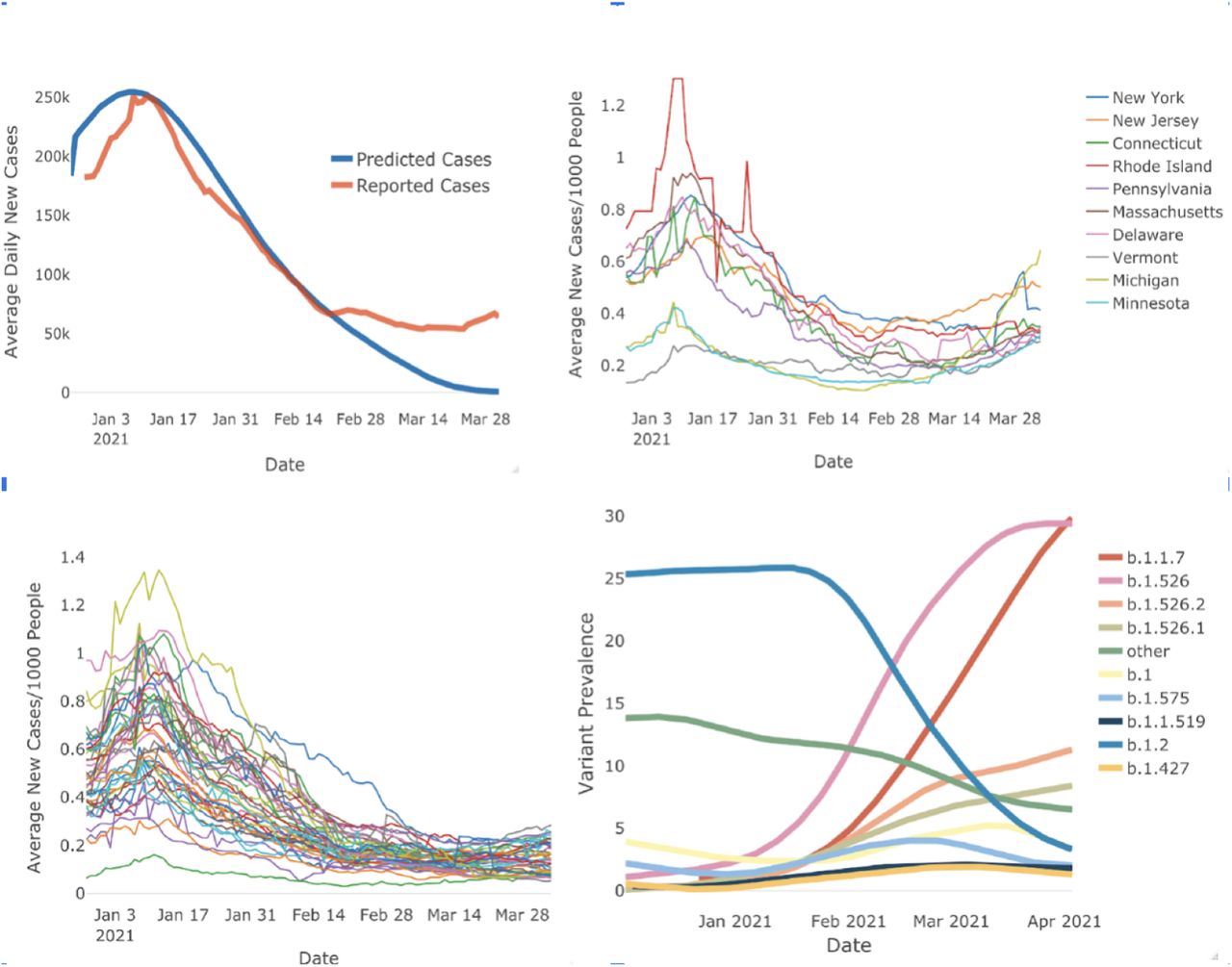
Rise of new B.1.1.7 and b.1.526 variants in Northeast US coincides with a rise in COVID-19 cases. Panel A (Top left) shows the SIR Model for predicting daily COVID-19 cases. The blue curve represents the model, the orange curve represents the observed case numbers. The model follows the observed case numbers closely however diverges around end of February. Panel B (Top left) shows daily case numbers per 1000 people for the states in the Northeastern US. daily case numbers fall around mid-February but start increasing by the month end. This trend is absent in the rest of the US States as shown in Panel c (Bottom Left). Panel D (Bottom right) Shows the time series of variant prevalence in New York State. Over January and February, B.2 which is the original COVID-19 strain decreases in prevalence but we observe that B.1.1.7 and B.1.526 increase in prevalence.
We demonstrate that the predicted drop in cases in the US in February and March of 2021 was delayed predominantly by infections in the North Eastern US by variants that originated in New York City, B.1.526 and B.1.526.2 [9]. We first explore the relationship between the number of COVID-19 cases and prevalence of various variants and mutations. We show that there is a positive correlation between the number of cases and the prevalence of the B.1.526 family of variants. The prevalence of mutations that define the variant B.1.526 also shows a positive correlation with the number of cases over time.
Methods
0.1 Data resources
The COVID-19 variants data was sourced from the API of Outbreak.info [10]. Outbreak.info aggregates data across scientific sources, though the API, daily surveillance reports about lineages and mutations, countries, states, and counties from GISAID Initiative [11] were extracted for analysis. In an effort to include the maximum number of lineages, the data [12] period included January 1st, 2021, through March 31th, 2021. COVID-19 cases and deaths come from dashboard Coronavirus Visual Dashboard operated by the Johns Hopkins University Center for Systems Science and Engineering (JHU CSSE) [12]. The state population origins from census data of the United States Census Bureau in 2019 [13].
0.2 Data Pre-processing
0.2.1 COVID-19 Variants and Mutation data
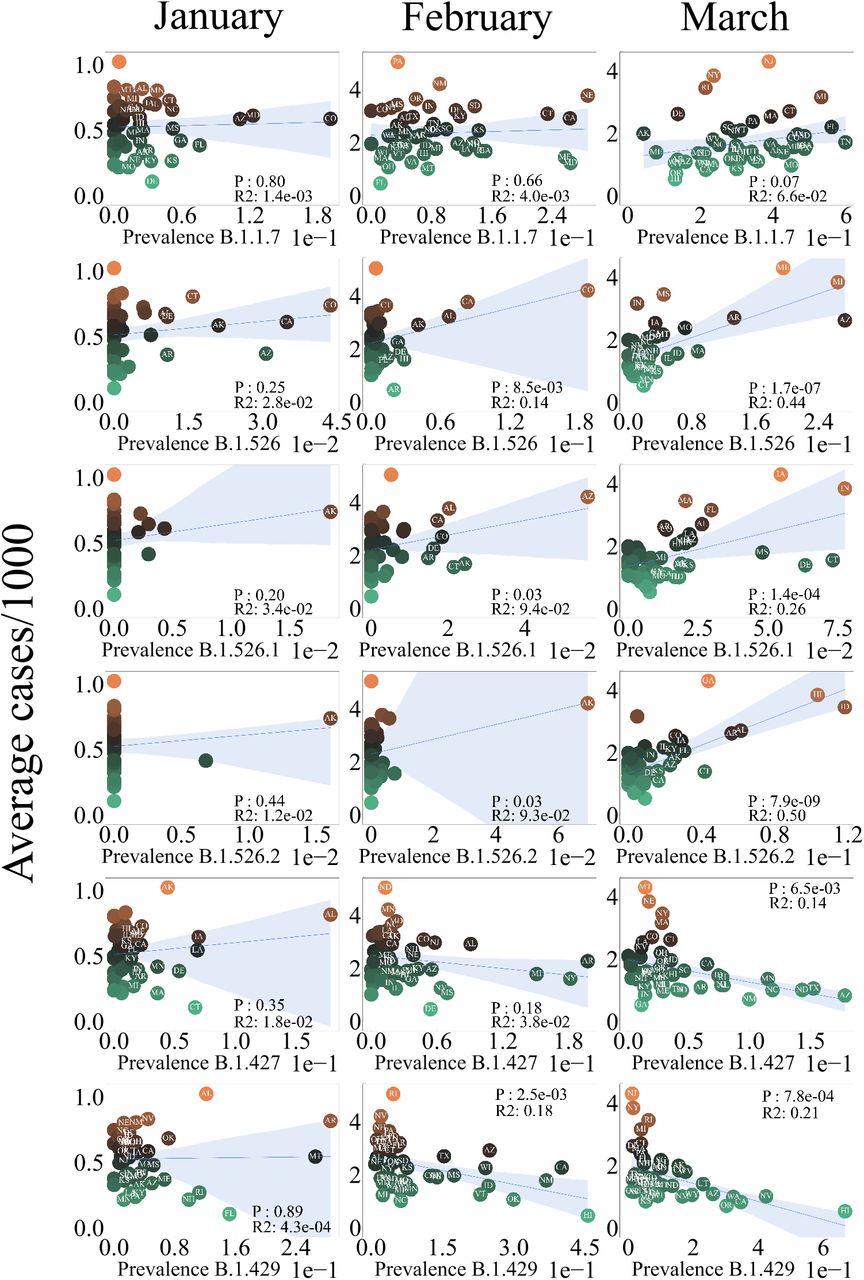
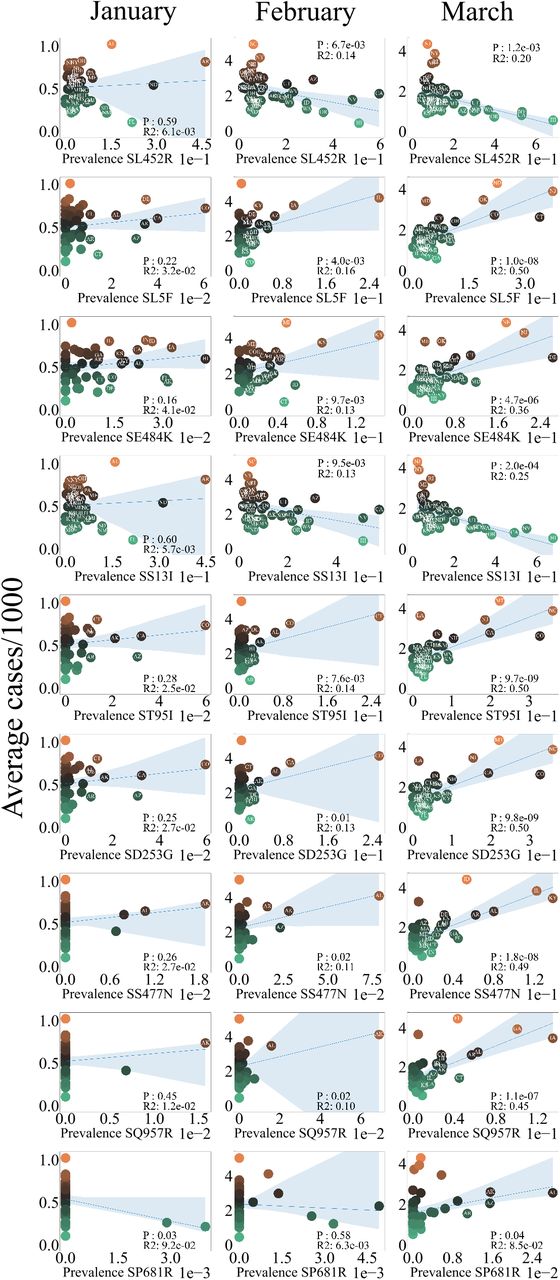
Each data point in figure 2 and figure 3 represents the average number of cases per thousand people plotted against the prevalence of a variant/mutation for a single state. Everything stated below applies to both the variant data in fig 2 and mutation data in fig 3. Prevalence is defined as the number of cases of a variant COVID-19 divided by the number of recorded COVID-19 cases on a day. The outbreak.info API provides a prevalence measure for each day hence the prevalence was averaged across all days in a month. Prevalence data for each month was collected for all states then averaged for each state over a month. Gaussian smoothing with a window of 7 days applied to the time series of the variant data. The Gaussian smoothing reduced the effect of noise due to spikes in the time series data. Varying the window for Gaussian smoothing from 3 to 10 days did not significantly alter the results. These spikes represent cumulative variant case number data dumps on specific days hence they were a source of noise while averaging prevalence over a single month.
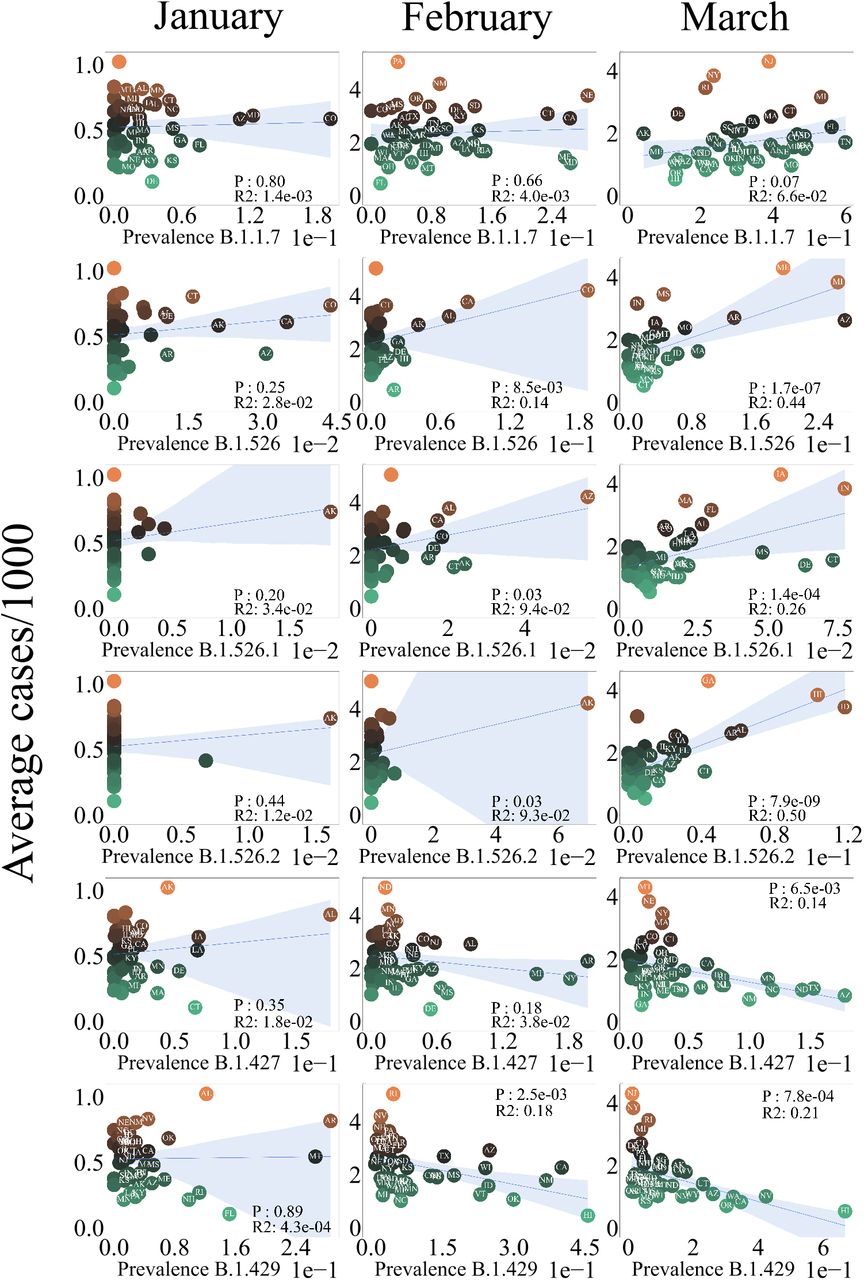
OLS Regression analysis of average number of cases per thousand vs COVID-19 lineage prevalence. Right column represents regression analysis for January, center for February and left for March. States that have a prevalence of larger than 0.01 are labeled. The shaded blue region represents the error in the slope of the fit. The color each each data points represents the scale of the average number of cases.

OLS Regression analysis of average number of cases per thousand vs COVID-19 Mutations. All mutations that are significant over January, February and March are plotted.
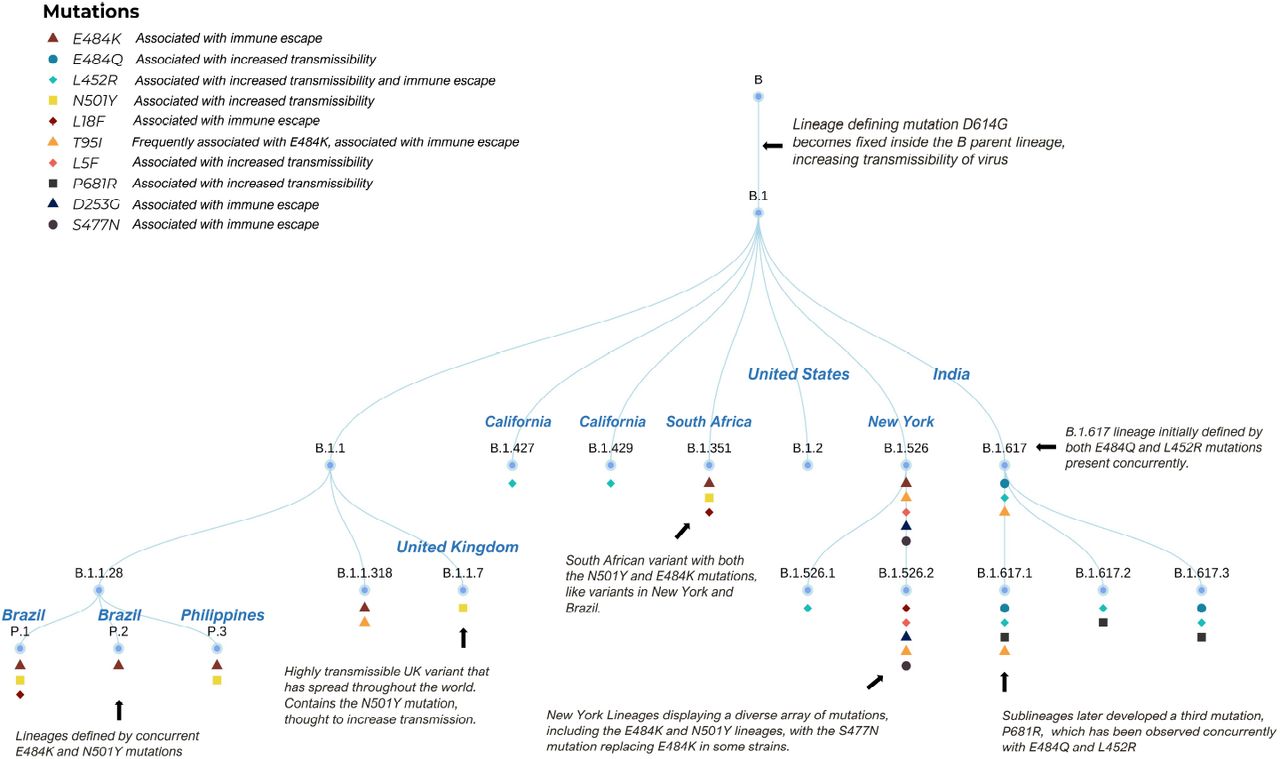
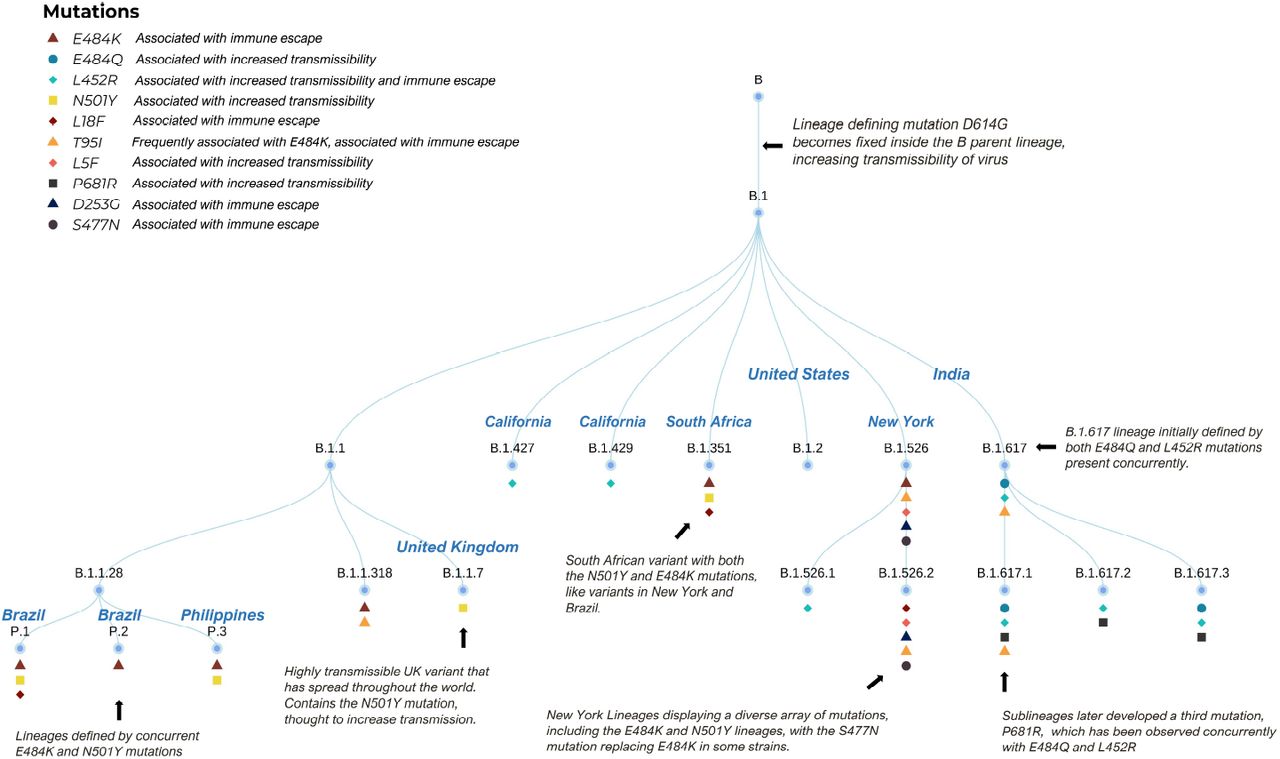
A Dendrogram outlining the relationship between COVID-19 lineages. The top right inset lists the definitions of each symbol.
The ordinate is scaled close to 1 by dividing the number of COVID-19 cases per day by the population of the state divided by a thousand. The order of magnitude of COVID-19 cases had decreased almost by an order of magnitude post the second wave of cases in December 2020 hence scaling the cases per day by state population per thousand negated the disparity between the most and least populous states. Python’s Pandas [14] package is used to process the data.
0.2.2 Variants Map
For each state and each month, the top three frequent lineages were selected as the candidates for relative importance analysis based on the cumulative lineages cases. To standardize the COVID-19 cases and deaths, the COVID-19 case ratio was calculated by the COVID-19 cases of each state divided by the state population, and COVID-19 fatality ratio was presented by COVID-19 deaths of each state divided by the state COVID-19 cases.
0.3 Analysis Methods
0.3.1 Hybrid Regression-SIR Model
We use linear regression to estimate initial susceptible/infectious/recovered (SIR) parameters. We solve SIR differential equations for the next day for each region, then re-estimate the SIR parameters with that day’s output and the lag-adjusted non-pharmaceutical interventions (NPIs). We then iterate each day until reaching the end date. Total US cases are calculated from the sum of the cases for each state. Holidays are adjusted for by addition to beta.
The algorithm has seven basic steps:
Linear regression including NPIs from Oxford database to estimate the initial SIR parameter, β (infection-producing contacts per unit time).
Adjust the parameters to account for asymptomatic cases based on CDC seroprevalence estimates [15].
Employ a separate SIR model using the β estimated in step one for the next day for each US state.
Feed the new β extracted from each SIR model into a linear regression model that incorporates the NPIs from one week prior (accounting for 14-day lag time from NPI to case reporting) to produce an NPI-adjusted β.
Repeat steps 2-4 each day, feeding in the previous days predicted NPI-adjusted β until reaching the end date.
For major holidays, input variables are adjusted up by adding the equivalent of three extra cases per 100,000 people per county, with delays to account for event-to-reporting lag time.
The total US cases are summed from the US state cases.
The mathematical description of the ordinary differential equations (ODE) implemented are:
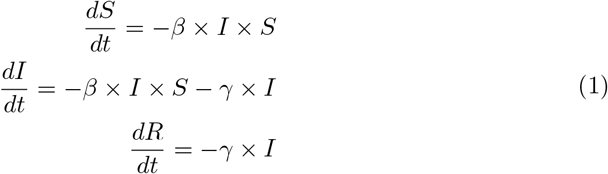
While SIR modeling is useful for accurate predictions, it is not sufficient, as it fails to consider that the reproductive number, R0 is not a constant and will vary by country, region, and over time, as conditions and interventions change. This dynamic R0 is often described as Re(Reffective). Additionally, the number of susceptible, infectious, and recovered individuals also vary by region. Testing capacity and the relationship of reported cases to actual cases also varies by region. Finally, initial infection dates are regionally-specific, as SARS-CoV-2 originated in China, spread to other parts of Asia, then to Europe, to the Americas and so on. Together, these regional-specificities require that each region must be predicted separately with its own SIR model.
0.3.2 Regression Analysis
Regression Analysis OLS regression of the number of cases per thousand was performed on the prevalence for numerous variants and mutations as shown in 2 and fig 3. The python package statsmodels [12](12) was used to perform the analysis. The p-values and R2 for each regression is provided in the inset of each figure.
0.3.3 Relative Importance Analysis
Relative importance analysis is a useful technique to determine the relative importance of predictors when independent variables are correlated to each other. In our case, we hope to know how the most influential lineage changed regarding COVID-19 infections and deaths in each state. A relative importance analysis was performed using the “relaimpo” package in R [13]. Each predictor was fitted with a simple linear regression model to compare the R2-values, these uni-variate R2-values indicate what each predictor alone can explain the response. The importance ranking was determined by the uni-variate R2-values-values, the larger is the uni-variate R2-values, the more important is the predictor. Besides the R2-values, we also used the p-value of coefficient (p < 0.05) in each model to filter insignificant predictors before we rank the importance. Therefore, it is possible that no candidate is significant in the models. In this way, we can determine which lineage is the most influential regarding new COVID-19 cases or deaths for each state and each month. All statistical analyses were conducted using R version 4.0.1 (2020-06-06), and figures were produced using the ggplot2 package [16].
1 Results
The classical susceptible/infectious/recovered (SIR) model is a versatile tool to predict the spread of infectious diseases. SIR models coupled differential equations which are solved to forecast dynamics disease spread. As with any set of differential equations, SIR models require a set of initial conditions for numerically solving them.
We built an SIR model to predict the number of cases in the United States. We used US Center for Disease Control (CDC) antibody data to adjust for under-testing and under-reporting. We also adjusted for Holiday travel and event related spikes by systematically increasing beta. Figure 1A shows the observed number of cases and the predicted number of cases according to the SIR model.
Our model was highly accurate for predicting eight weeks out, with a MAE of 10%. This is half the error rate of any model or ensemble on the CDC dashboard and was able to predict for twice as far out (data not shown).
In late-February 2021, cases abruptly deviated from the predicted trajectory (Fig 1A). Most active US cases starting at that time were clustered in the North Eastern US on a gradient decreasing from New York City (Fig 1C). When we evaluated case deviations by State, we found that cases only deviated from predictions in these North Eastern US states (Fig 1B). Other states were almost uniformly following the trajectory predicted by our mathematical model (Fig 1C).
1.1 Variant Analysis
We investigated which variants were predominant in the states that deviated from our model and found that B.1.526 and B.1.526.2 became the predominant variants in New York and neighboring New Jersey in mid-February (Fig 1D), the same time that cases began to deviate from our predictions (Fig 1A).
To assess which lineages are influencing the changing case numbers in the US in January, February, and March of 2021, we performed linear regression and relative importance analysis. The variants B.1.526, B.1.526.1, and B.1.526.2 (NYC origins) had the most significant positive relationships to case numbers, p < 2e−7 and p < 8e−9, respectively for March Fig 2. These variants transition from being non-significant in January and February to being significant in March (Fig 2). B.1.526.1 was also significant (p < 2e−4)(2). We also observed that B.1.427 and B.1.429 lineages (California origin) had a significant(p < 3e − 3 and p < 8e − 4) but inverse relationship to the number of cases as seen in (2). These lineages are associated with smaller case numbers consistent with the rapidly declining cases in California and the Pacific Northwest (1C). Surprisingly, the prevalence of the B.1.1.7 variant (UK origin) did not show significance with rising case numbers (Fig 2). B.1.1.7 did, however, associate with new COVID-19 cases and deaths in the greatest number of states in March.
We examined most prevalent variants in various US states by relative importance analysis in figures 7,8,9, where 7 shows which variants dominated in January of 2021, 8 shows which variants dominated in February of 2021, and 9 shows which variants dominarted in March of 2021. While B.1.526 rose in the prevalence over time it did not become an influential variant of concern till March of 2021. B.1.1.7 and B.2 variants and the original COVID-19 lineage dominate the map of number of cases in February and March.

Heatmap for all US: Each cell in the heatmap represents the ratio of mutation-lineage case counts and lineage case counts. Data from January to the end of March has been used to generate the heatmaps. The Mutation-lineage count represents how many cases for a lineage contained a mutation. This ratio will always be less than 1 since the total number of mutation-lineage cases will be less than the total number of lineage cases. The darker shades in the heatmap represent higher counts of a mutation for a specific lineage.

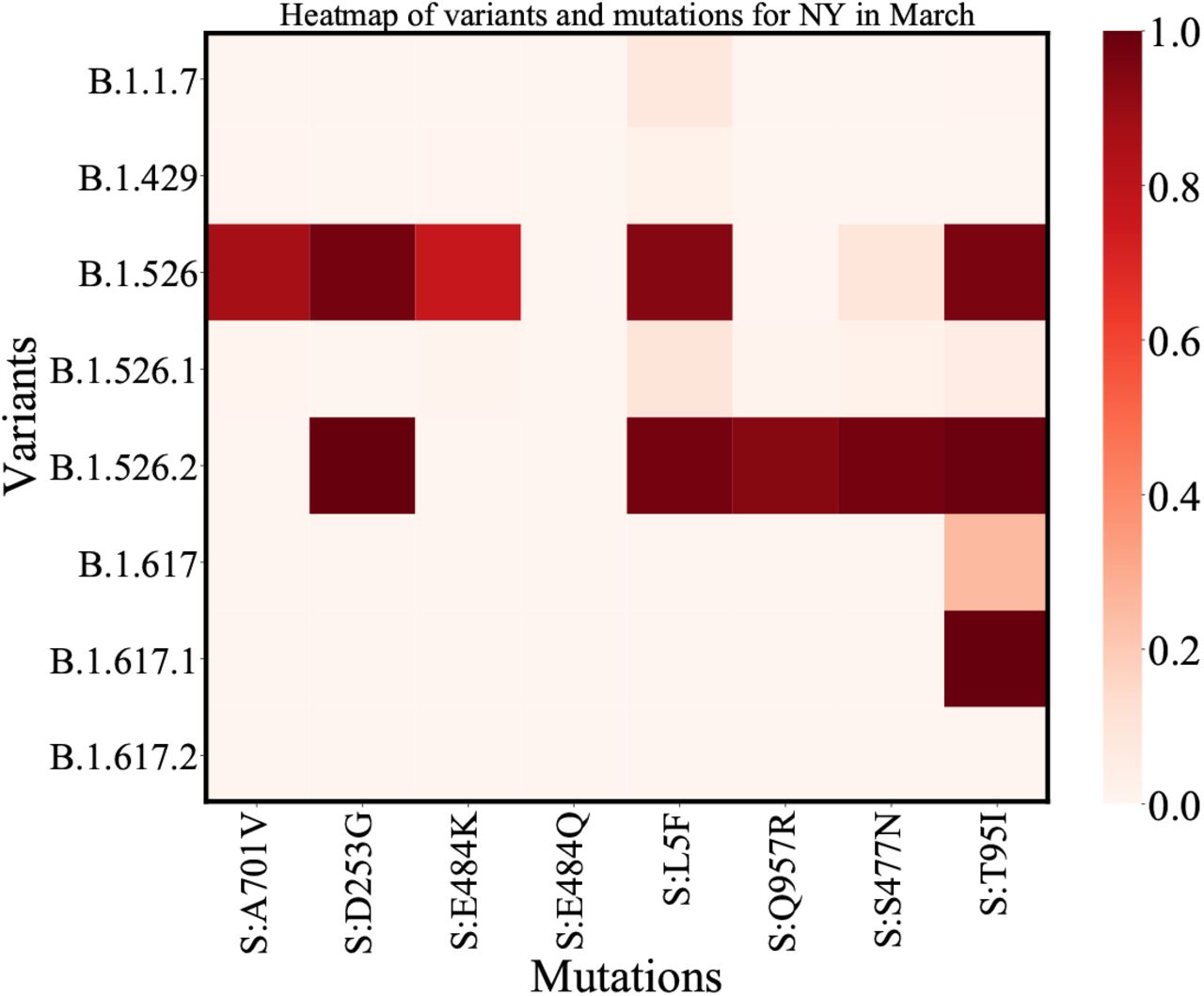
Heatmap for NY: Similar to the heatmap for all of US the darker regions represent higher mutation-lineage counts.

A map representing the most influence variants for the month of January. The circles represent cases in segments of 10000 as mentioned in the bottom left of the figure. The colors represent different variants. No single variant has emerged as an influential variant. The west coast has B.1.519 as the dominant variant and B.1.1.7 has its presence in six states. The None represents B.1 which is the original strain

A map representing the most influential variants for the month of February. The circles represent cases in segments of 10000 as mentioned in the bottom left of the figure. The colors represent different variants. B.1.1.7 has spread to 10 States, B.1.427 has spreadf to three states in the western half of the US. B.1.526 emerges as the dominant variant in Delware

A map representing the most influential variants for the month of March. The circles represent cases in segments of 10000 as mentioned in the bottom left of the figure. The colors represent different variants. B.1.1.7 is the most influential variant in 21 states. B.1.2 is found in ten states. B.1.526 family of states are the most influential in three states in the North east - New York, New Jersey and DC
1.2 Mutation Analysis
These results led us to question how individual mutations affect the number of COVID-19 cases. We found that SL5F, SE848K, T951I, SD253G, SS477N, SQ957R and SP681R mutations showed a significant positively correlated relationship to the number of cases per 1000 (3). These mutations are a subset of the SARS-CoV-2 spike protein mutations that we explored, the p-value and R2 value for all the mutations we explore are presented in table 2. All mutations that were found to be positively correlated are associated with the B.1.526 family of variants (5), originating in New York. Interestingly, the much discussed SE848K “eek” mutation was not found in the B.1.526.2 or B.1.526.1 lineages but only in the parent variant B.1.526 as shown in figure 5. The mutations, SL452R and SS13I are also significant but were negatively correlated. These mutations are part of the B.1.427 and B.1.429 variants.
P-value and R2 values for COVID-19-variants.
P-value and R2 values for COVID-19-mutations. We studied the correlation between the prevalence of multiple Spike mutations and number of cases and results presented in figure 3 is for a small subset of mutations.
We also found that less than 30 cases of B.1.617 were present in the US during this time period and that both B.1.526 and B.1.526.2 variants share the T95I mutation with B.1.617. This observation is even more pronounced if we look at the heat map of mutations and variants for New York (6) where we observe the presence of ST95I in all family of B.1.526 variants.
1.3 The Variant Family tree
All strains of SARS-CoV-2 that we refer to as “variants” emerged from strain B.1. To better visualize this, we provide a dendrogram as shown in (4). The dendrogram documents variants in three geographical regions the US, UK and India. These regions have seen either an uptick in cases, as with India and the UK or a stalling in decline of COVID-19 cases (as in the the US). Specific mutations shared by certain strains of SARS-CoV-2 influence their virulence.
2 Discussion
The deviation in the number of cases in our epidemiological model shows the influence of variants on COVID-19 case numbers. Our results (figure 1C) show that B.1.526 had been rising in prevalence and led to the stall in fall of COVID-19 cases.
The increasing prevalence of B.1.526 may have been at least partially responsible for cases increases in many Northeastern states during February and March of 2021. This is demonstrated by the relationship between case counts and prevalence for B.1.526, B.1.526.1, and B.1.526.2, as discussed in results above.
Further support for this conclusion emerges from the growth of B.1.526 in New York and New Jersey as demonstrated in our relative importance analysis. By March, B.1.526 was the most variant causing the most deaths in New York, New Jersey and Connecticut, although B.1.1.7 was the dominant strain in the US overall.
Conversely, variants B.1.427 and B.1.429 had high prevalence prevalence in the Southern and Western part of the United States. The spread of these variants in these region is attributed to their geographical origin. Both these variants, as far as is known, originated in California. States like Nevada, Oregon and Arizona have significant number of cases of these variants.
Its also interesting to note that the variant B.1.427 does emerge as a dominant strain in the California, Wyoming and Arizona in February but is replaced by B.1.1.7 and the original COVID-19 strain in March. This observation fit with observation that B.1.427 has a negative correlation with the number of cases.
The relationship between mutation prevalence and number of cases follows a similar trend to the variant prevalence. Most of the mutations that become significant over time are associated with the B.1.526 family of variants.
These results have a broader implication beyond these variants. As new SARS-CoV-2 variants emerge, it remains possible that these new variants will escape immunity generated by infection with a prior variant, or acquired through vaccinations, defying the predictions of pandemic models, and leading to increased case-counts in regions with high expected immunity. Using regional deviations from highly accurate predictions can rapidly identify regions with variants that are escaping immunity.
2.1 Comparison with other works
The CDC observed both the emergence of B.1.526 in November 2020 [17] and that there was a sharp increase in the number of cases in New York by April 5th. This timeline is similar to other we have observed where by Mid-February B.1.526 prevalence had reached 30% prevalence by April 2020. The timeline is corroborated by Lasek-Nesselquist et al [8] as well who show detailed maps of the spread of B.1.526. They also mention that this variant has the E484K, S477N and D253G all of which are correlated with increase in number of COVID-19 in the US.
The CDC does mention that while B.152.6 does not cause more severe COVID-19 symptoms it could be more transmissible than other variants. This could explain its spread into other states and also its immune escape. As far as we know, we have not seen any other study document the relationship between the prevalence of COVID-19 variants and number of cases.
2.2 Limitations of the Study
The data used in this study are cross-sectional. Ideally we would be able to test whether the B.1.526 lineages were reinfecting the same person after being infected with the original strains. Additionally it would be ideal to have data on vaccination status and type of vaccine in the people infected with viral lineages longitudinally. Unfortunately, these data do not exist or are not accessible. We strongly encourage testing and reporting of this data by hospital systems so that we can more clearly understand the role of the variants on breakthrough cases. Another limitation of the study is delays in reporting sequencing data to databases. Accurate lineage data is available only with a three week delay. This means that we are delayed in understanding important information for policy planning and hospital staffing.
Our relative importance analysis while useful in understanding the most dominant lineages will fail to capture variants with rising prevalence or variants that dominate regionally. When a specific variant causes a large number of cases over a country it tends to be the focus of study. However the most dominant variant may not the most dangerous one, geographically located variants like B.1.526 are a cause for concern since they may escape notice due their limited presence.
2.3 Future Directions
In the future we hope to access longitudinal data to more directly assess the effect of lineages and their mutations on breakthrough cases and reinfection. These mutations need further study on their impact, particularly T95I. Lastly, we will soon hopefully be vaccinated to high enough degrees in more countries to take a global approach to looking at mutations, lineages, and vaccination. We also hope to map the biological significance of mutations to epidemiological outcomes. Currently there is limited understanding on what are the macro-effects of mutations hence this presents a challenge in accurately modelling the evolving pandemic.
2.4 Conclusion
Our article shows that the stalling of decline in COVID-19 cases in the US can be at least partially attributed to the rise of a geographically limited yet prevalent variant B.1.526. We come to this conclusion by studying the rise in prevalence of multiple variants and find that the B.1526 family of variants shows a positive correlation between the prevalence of the variants and the number the of cases per state. We initially observed a deviation using SIR modeling of the average number of cases in the first half 2021. This modeling showed that the number of predicted and actual cases differed from end of February of 2021. To better understand this deviation, we explored relationship between different variant prevalence and the average number of cases per state. We observed the positive correlations between the B.1.526 variant and the number of cases. This correlation between developed over the course of three months, January, February and March of 2021. We support this conclusion by also preforming relative importance analysis and showing that in many of the North-Eastern states B.1.526 family of variants are the most influential variants.
We have also explored the relationship between mutations and variant prevalence and found that the mutations present in the variants B.1.1.526 family of variants and B.1.1.7 seems to show a positive correlation with the number of cases in each state.
Newer variants will emerge as time progresses. Our hope is that the observations and analysis may help in understand how newer variants emerge from specific regions of the US and lead to more cases. Understanding which variants and mutational profiles are most concerning rapidly can aid in effectively designing policy for the global COVID-19 pandemic.
Data Availability
All data produced in the present study are available upon reasonable request to the authors.
Acknowledgments
We thank just about everybody.
Appendix
3 Appendix

Influential variants causing deaths for the month of January. Each US State is presented as a hexagon. The circles represent cases in segments of 10000. The colors represent different variants. The none strain is Most of the deaths can be attributed to the original B.1 strain and the B.2 variant.
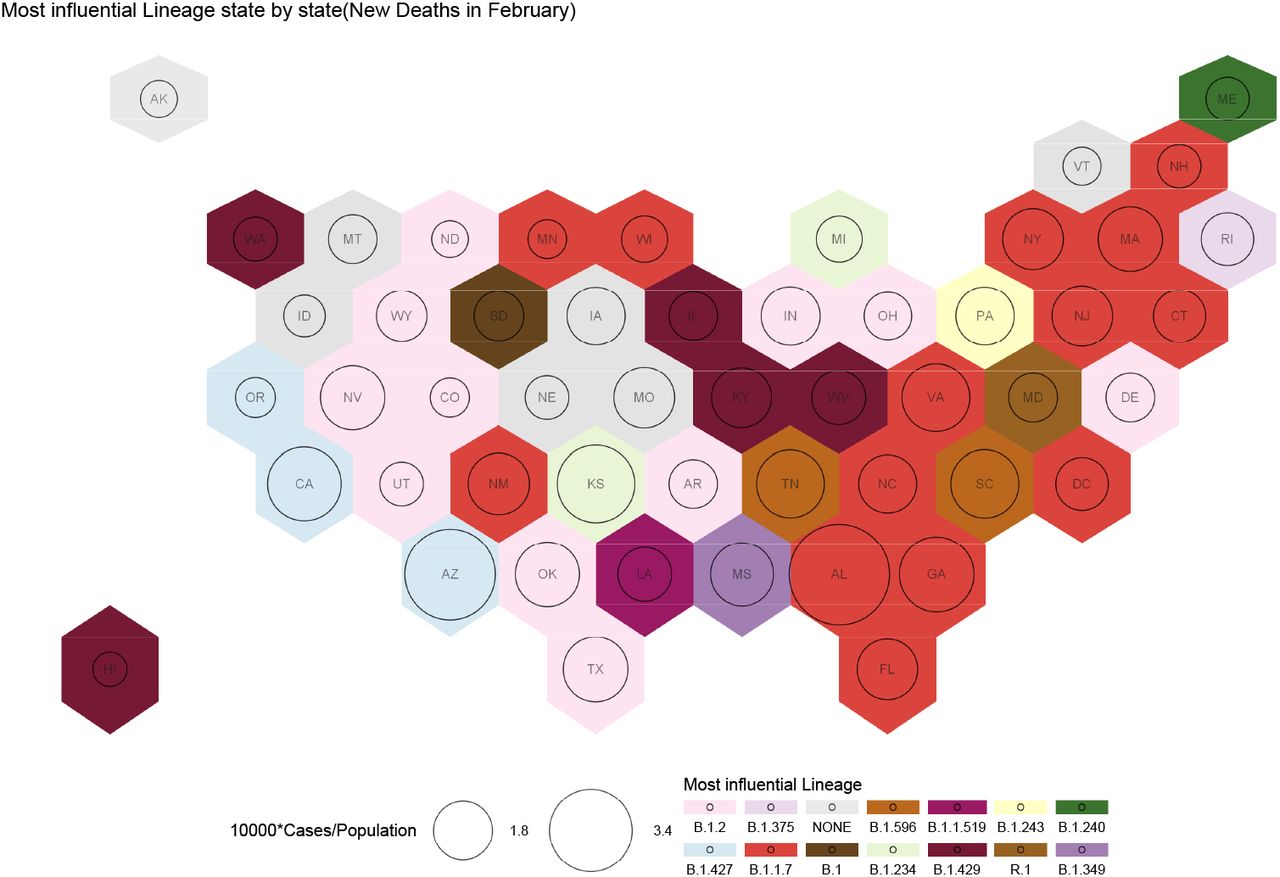
Influential variants causing deaths for the month of February. Each US State is presented as a hexagon. The circles represent cases in segments of 10000. The colors represent different variants. The deaths in the east coast is dominated by B.1.1.7 and in the west coast by B.1.427. B.2 is also responsible for deaths in the many of the mid-western states.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
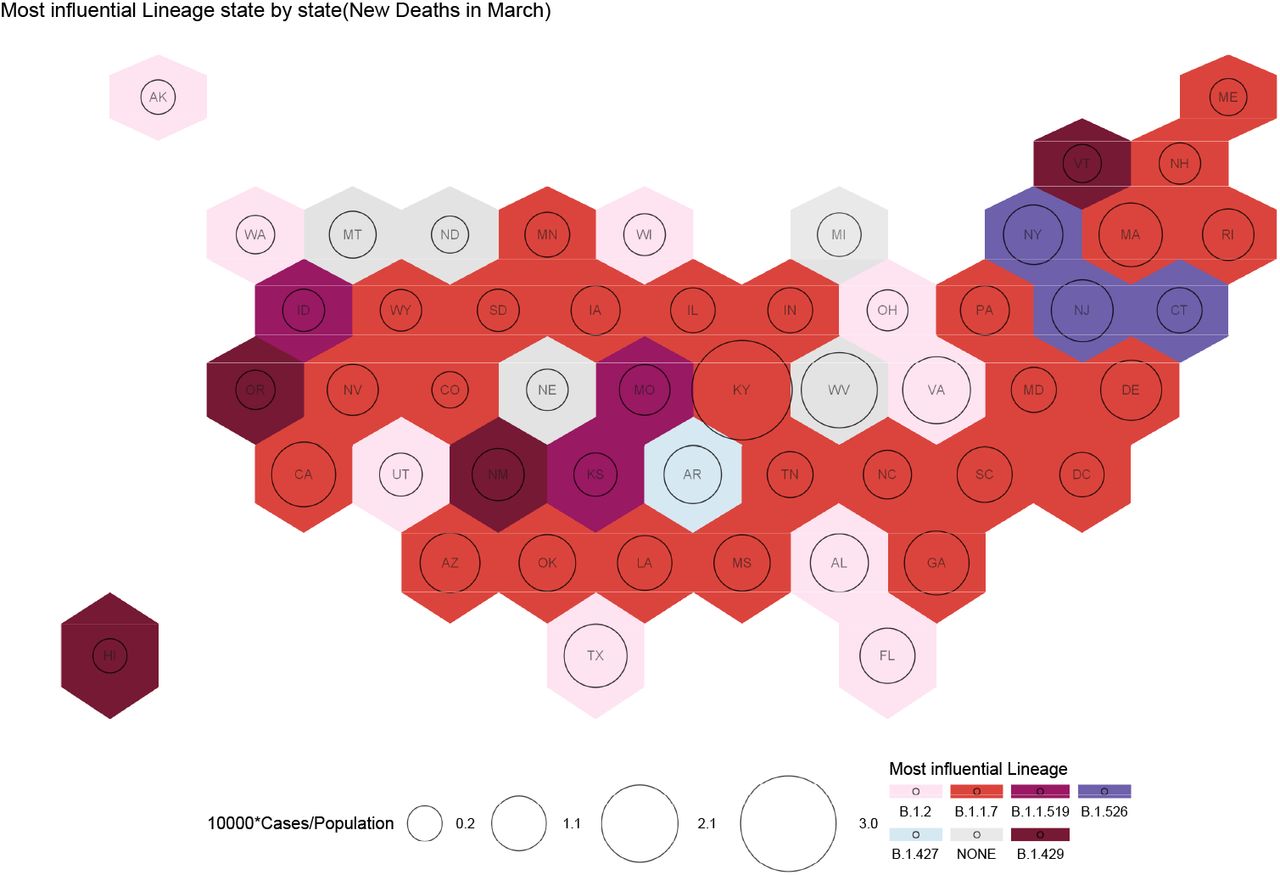
Influential variants causing deaths for the month of February. Each US State is presented as a hexagon. The circles represent cases in segments of 10000. The colors represent different variants. Most of the deaths by March are due to B.1.1.7. The B.1.526 family of variants cause the most number of deaths in the three states - New York, New Jersey and Connecticut. B.2 is responsible for deaths in 8 states spread out across the country




