
Abstract
Objective Anticipating fetal risk is a major factor in reducing child and maternal mortality and suffering. In this context cardiotocography (CTG) is a low cost, well established procedure that has been around for decades, despite lacking consensus regarding its impact on outcomes.
Machine learning emerged as an option for automatic classification of CTG records, as previous studies showed expert level results, but often came at the price of reduced generalization potential.
With that in mind, the present study sought to improve statistical rigor of evaluation towards real world application.
Materials and Methods In this study, a dataset of 2126 CTG recordings labeled as normal, suspect or pathological by the consensus of three expert obstetricians was used to create a baseline random forest model.
This was followed by creating a lightgbm model tuned using gaussian process regression and post processed using cross validation ensembling.
Performance was assessed using the area under the precision-recall curve (AUPRC) metric over 100 experiment executions, each using a testing set comprised of 30% of data stratified by the class label.
Results The best model was a cross validation ensemble of lightgbm models that yielded 95.82% AUPRC.
Conclusions The model is shown to produce consistent expert level performance at a less than negligible cost. At an estimated 0.78 USD per million predictions the model can generate value in settings with CTG qualified personnel and all the more in their absence.
1. Introduction
Direct information regarding the fetus well-being is not trivially acquired during pregnancy, and key information such as the fetal heart rate (FHR) is crucial for anticipating fetal risks in both antepartum as well as intrapartum. [12]
In this context cardiotocography (CTG) is a well-established, routine procedure that has been used since the end of the 1960s for monitoring the fetal heart rate and uterine contractions (UC) signals during pregnancy and delivery. [12]
The fetal heart rate itself is used for investigating the oxygen supply for the fetus, as hypoxia during labor can lead to death and long-term disabilities. [7]
The interpretation of the CTG signals is supported by guidelines developed by institutions such as International Federation of Gynecology and Obstetrics (FIGO) and the Institute of Child Health and Human Development (NICHD). [3]
While FHR and UC signals are the primary objective of CTG, the guidelines extend the definition of observations to include features that describe these signals, such as acceleration, deceleration, and variability. [16]
Despite the existence of these guidelines, the CTG exam is still prone to subjectivity and there is no universal consensus regarding its interpretation. This subjectivity extends to measuring its outcomes, which 40 or so years after its implementation, still retains significant variance. [2]
CTG is most commonly applied in high-risk pregnancies and is not recommended by the World Health Organization (WHO) for healthy pregnant women undergoing spontaneous labor. [20]
2. Related Work
Studies regarding the impact on outcomes of the CTG exam have considerable variability: sensitivity ranging from 2 to 100% and specificity between 37 and 100% [2].
At the heart of such variance lies the opportunity of improving consistency through the application of a machine-based model, which would remove inter-observer variation.
In the past studies exploring machine learning for automatic CTG classification, authors often favored theoretical performance over practical applications, as decisions such as excluding the suspect class [9] [15] [17], single run experiments [9] [15] [17] [21] and small sized testing sets [9] [17] [21] constrain the potential generalization of any given model.
The present study sought to improve the statistical rigor of previous work done with machine learning applied to CTG in order to bring the results one step closer to real world application.
3. Materials and Methods
3.1 Dataset
The dataset used in this study contains 2126 fetal cardiotocograms represented in 21 features belonging to 3 different classes: normal (n = 1655), suspect (n = 295) and pathological (n = 196). [1]
The class labels were given by the consensus of three expert obstetricians, using FIGO as its guideline for interpretation. [3]
The features were created by SisPorto 2.0 software [1], which applies pattern recognition to digital CTG signals yielding the features described in the table 1 below.
Description of dataset variables. [3]
3.2 Metrics
The primary metric used to measure performance in this study is the area under the precision-recall curve. The reasoning behind this is trifold: the metric is representative of performance amidst class imbalance, the metric allows practical decisions (i.e., favoring recall for screening purposes or precision for resource allocation) as well as being conceptually familiar to professionals that underwent nursery or medical school. The AUPRC can be defined in the equation below [14], where p and r denote precision and recall respectively:
 Secondary metrics were also made available, including accuracy, precision, recall, f1-score and area under the receiver operator characteristic curve (AUROC).
Secondary metrics were also made available, including accuracy, precision, recall, f1-score and area under the receiver operator characteristic curve (AUROC).
AUPRC was chosen in favor of AUROC as the ROC curve can be misleading in the face of class imbalance, as few examples of the minority class diminish the trustworthiness of the measured performance [5].
Logloss was used as a loss function for training classifiers as well as the minimization criteria during hyperparameter optimization.
3.3 Evaluation Method
In order to ensure the reliability of proposed techniques, all experiments were repeated 100 times (n = 100) and the reported metrics represent the median of experiment runs.
In every experiment run, the testing set was composed by 30% of data using the target classes as stratification criteria.
During hyperparameter optimization, models were trained under k-fold cross validation using k = 4 on training data.
3.4 Machine Learning Models and Hyperparameter Optimization
In order to establish the baseline performance level, a RandomForest model [6] was conceived. The reasoning behind this choice is due to the low variance coupled with good bias levels as well as the synergy between this framework and the final candidate, a LightGBM model [13].
Tree-based algorithms rely on similar assumptions and representations, therefore its performance can be consistently compared whilst not incurring any extra overhead for preprocessing.
The parameters for the baseline model were not tuned, rather, they were chosen for the main purpose of lower variance, as to establish a consistent baseline for performance while also minimizing bias whenever possible.
The table 2 reports the parameters and constants used in the baseline model.
Baseline random forest model parameters.
LightGBM parameters obtained through bayesian optimization.
After the baseline model, a lightgbm model was conceived through bayesian optimization using a gaussian process regression mapping the logloss of the model (calculated on k-fold cross validation with k = 4) to the parameters in the search space.
The optimization procedure had 30 random starts followed by 70 rounds of refinement leading to a lightgbm classifier with the following parameters:
3.5 Post Processing
Following the results of hyperparameter optimization, the resulting LightGBM model was subjected to k-fold cross validation ensembling (CVE) wherein the model is trained multiple times (k = 4) on different subsets of the training set and its final predictions are subsequently averaged. This process managed to reduce both bias and variance, as shown in the next section.
4. Results
The results are summarized in table 6 and charts 1 and 2 depict the performance of the best model. A more detailed table of experiment results per model is available on annex 1, 2 and 3.

Performance of CVE LightGBM
{kind=link}
{kind=link}
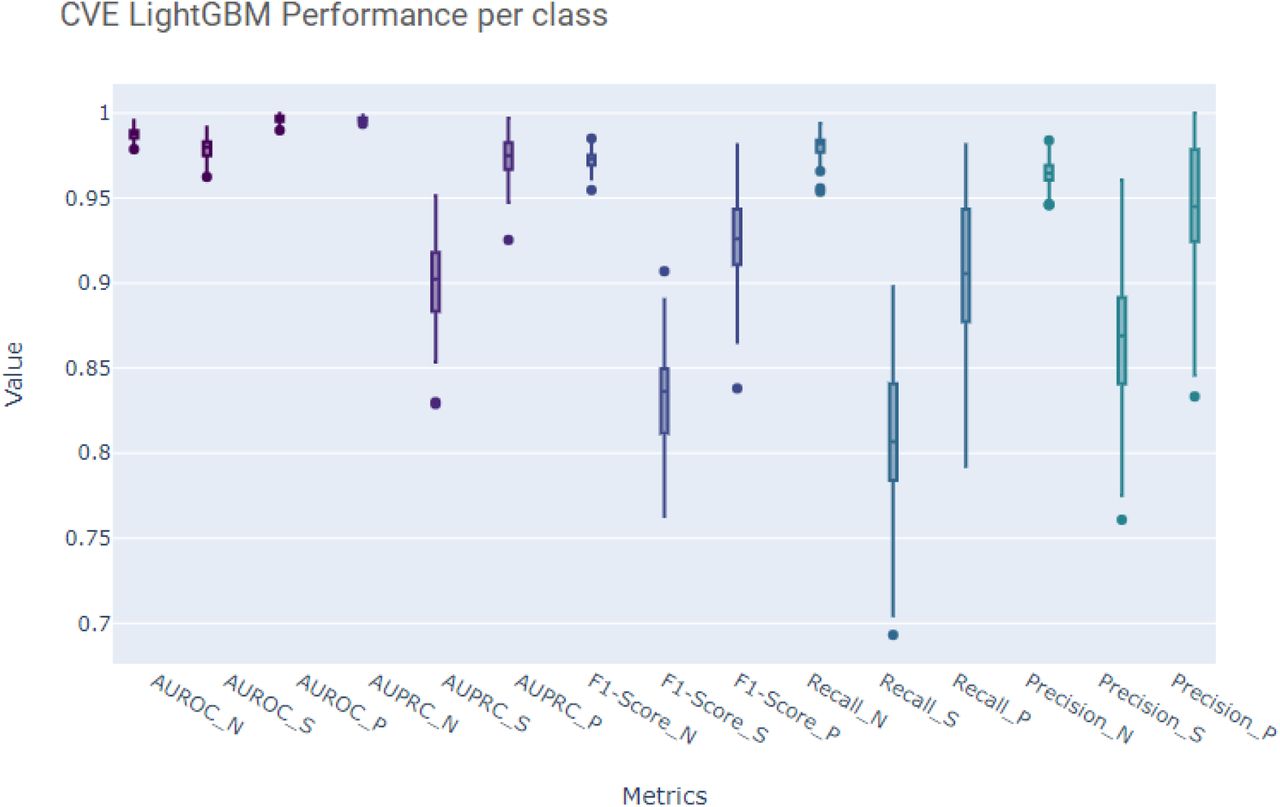
Performance of CVE LightGBM measured by class Note: N denotes normal, S denotes suspect and P, pathological.
As part of the results, a cost estimate for the model was made in order to further support real world deployment and healthcare value assessment.
From an estimate of 140 million yearly births [19] worldwide, roughly translating to 12 million births/month, and 300 milliseconds execution time, the lightgbm model would cost 0.78 USD for every million predictions or 9.33 USD per month for covering all births in that given period.
5. Discussion
The suspect class was shown to be the most difficult to predict, likely due to the fact that there are less observations when compared to the normal class as well as being the in-between of the other classes as well.
While it would certainly increase the computational overhead, using the raw signal could yield better results, as theoretically the bayes optimal error is diminished when using aggregations like it was done by SisPorto 2.0.
The cost estimate does not factor indirect costs that are facility specific, such as IT, data infrastructure required to support the model, and it drastically overestimates the amount of predictions required, as not all labor occurrences would need a CTG exam to begin with.
In order to further approach this model to a real-world setting, we recommend exploring the effects of manufacturer, age and ethnic group [4] in order to ensure that the model retains performance levels amidst populational and hardware variance.
6. Conclusion
The models created in the course of this study showed good and consistent levels of performance. Lightgbm with bayesian optimization proved very useful in pushing the baseline, as did cross validation ensemble which introduced a small but welcome performance gain.
As the impact on outcomes of CTG remains unclear, a machine model could improve measurements by reducing subjectivity.
The low-cost structure combined with the fact that CTG is a widespread procedure makes it a great candidate for real world experimentation.
The cost overhead added by the AI model is easily overshadowed by the potential efficiency gains in domains with CTG qualified professionals and even more so for resource poor environments where the exam would be otherwise unavailable.
Data Availability
The dataset used in this study is publicly available.
9. Annex
Random Forest baseline experiment results
LightGBM experiment results
Cross validation ensemble LightGBM experiment results
7. Acknowledgements
We would like to thank Biraja Machado, Edson Amaro, Adriano Pereira and Wellington Lucena for the inspiration and support. We also express our gratitude to Kaggle for providing free computational resources.




