
Abstract
Background Deep learning (DL) models have shown promise to automate the classification of medical images used for cancer detection. Unfortunately, recent studies have found that DL models are vulnerable to adversarial attacks, which manipulate images with small pixel-level perturbations designed to cause models to misclassify images. There is a need for better understanding of how adversarial attacks impact the predictive ability of DL models in the medical image domain.
Methods We examined adversarial attacks on DL classification models separately trained on three medical imaging modalities commonly used in oncology: computed tomography (CT), mammography, and magnetic resonance imaging (MRI). We investigated how iterative adversarial training could be employed to increase model robustness against three first-order attack methods.
Results On unmodified images, we achieved classification accuracies of 75.4% for CT, 76.4% accuracy for mammogram, and 93.6% for MRI. Under adversarial attack, model accuracy showed a maximum absolute decrease of 49.8% for CT, 52.9% for mammogram, 87.3% for MRI. Adversarial training caused model accuracy on adversarial images to increase by up to 42.9% for CT, 35.7% for mammogram, and 73.2% for MRI.
Conclusion Our results indicated that DL models for oncologic images are highly sensitive to adversarial attacks, as visually imperceptible degrees of perturbation are sufficient to deceive the model the majority of the time. Adversarial training mitigated the effect of adversarial attacks on model performance but was less successful against stronger attacks. Our findings provide a useful basis for designing more robust and accurate medical DL models as well as techniques to defend models from adversarial attack.
Introduction
Deep learning (DL) models have demonstrated increasing utility within the field of oncology and particular promise in analyzing growing amounts of oncologic imaging.1,2 DL models have been validated across a variety of diagnostic imaging modalities including magnetic resonance imaging (MRI), computed tomography (CT), and X-ray images with classification accuracy often rivaling trained clinicians.3–9 As widespread clinical implementation of DL models becomes a more realistic possibility, the safety and efficacy of such models in healthcare is becoming a topic of increasing importance.10–12
One concerning limitation of DL models that may hinder safe clinical implementation is their susceptibility to adversarial attacks. Adversarial attacks on DL models occur when data is manipulated with small pixel-level perturbations specifically designed to cause trained DL models to misclassify images.13–16 The vulnerability of DL models to adversarial attacks stems from the fact that DL models possess less algorithmic stability, resulting in significantly different outputs when given inputs which vary only slightly.17,18 Although images created from adversarial attacks are often visually imperceptible from unmodified images, they have been shown to significantly affect DL model performance.19–21
Previous work concerning adversarial attacks on DL models has largely focused on non-medical images, and the vulnerability of diagnostic images to such attacks is relatively unknown.21,22 In addition, although techniques to defend against adversarial attacks have been proposed for non-medical images, their generalizability on medical imaging tasks is unclear. Given the current financial incentives for healthcare fraud and the recent rises in cyberattacks on hospital systems, adversarial attacks on clinically implemented DL models pose a unique threat to healthcare systems.23–27 This suggests a pressing need to understand both the vulnerability of medical DL models to adversarial attacks and the relative effectiveness of current adversarial defense techniques in the medical setting.
In this study we explored adversarial attacks on DL models trained on three common imaging modalities in clinical oncology. Specifically, we investigated the relative susceptibility of DL models trained on three oncologic imaging modalities to adversarial attacks and the effectiveness of adversarial defense techniques in mitigating DL model performance loss when facing adversarial attacks.
Methodology
Datasets
We examined adversarial attacks on DL classification models separately trained on three medical imaging modalities commonly used in oncology—computed tomography (CT), mammography, and magnetic resonance imaging (MRI). Each DL classification model was trained to identify the presence or absence of malignancy when given an image. Each dataset was split into a training set and a testing set in a 2:1 ratio.
CT imaging data consisted of 2,600 lung nodules from the Lung Image Database Consortium and Image Database Resource Initiative (LIDC-IDRI) collection.28 The dataset contains 1,018 thoracic CT scans collected from 15 clinical sites across the US. Lung nodules used for DL model training were identified by experienced thoracic radiologists. The presence of malignancy was based on associated pathologic reports. For patients without pathologic confirmation, malignancy was based on radiologist consensus.
Mammography imaging data consisted of 1696 lesions from the Curated Breast Imaging Subset of Digital Database for Screening Mammography (CBIS-DDSM).29 The CBIS-DDSM contains mammograms from 1,566 patients at four sites across the US. Mammographic lesions used for DL model training were obtained based on algorithmically derived regions of interest based on clinical metadata. The presence of malignancy was based on verified pathologic reports.
MRI data consisted of brain MRIs from 831 patients from a single institution brain metastases registry.30 The presence or absence of a malignancy was identified on 4,000 brain lesions seen on MRI. Regions of interest were identified by a multi-disciplinary team of radiation oncologists, neurosurgeons, and radiologists. Presence of cancer was identified based on pathologic confirmation or clinical consensus.
To compare the relative adversarial attack vulnerability of DL models trained on oncologic images compared to non-medical images, two additional DL classification models were trained on established non-medical datasets. The MNIST dataset consists of 70,000 hand written numerical digits.31 The CIFAR-10 datasets includes 60,000 color images of ten non-medical objects.32
Models
For all DL classification models, we used a pre-trained convolutional neural network with the VGG16 architecture.33 DL models were trained using data-augmentation and optimized using stochastic gradient descent. Details regarding model architecture and hyperparameter selection for DL model training are provided in the Supplement.
Adversarial Attack Vulnerability of DL Models
Three commonly employed first-order adversarial attack methods—Fast Gradient Sign Method (FGSM), Basic Iterative Method (BIM), and Projected Gradient Descent (PGD)—were used to generate adversarial images on the medical and non-medical image datasets (Figure 1). Each attack method aims to maximize the DL model’s classification error while minimizing the difference between the adversarial image and original image. All the attacks considered are bounded under a predefined perturbation size ε, which represents the maximum change to pixel values of an image.

Examples of clean images and their adversarial counterparts generated using FGSM, PGD, and BIM attack methods. The percentage displayed represents the probability predicted by the model that the image is of a certain class.
The single step FGSM attack perturbs the original example by a fixed amount along the direction (sign) of the gradient of adversarial loss.16
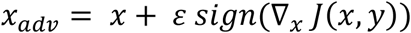
BIM iteratively perturbs the normal example with smaller step size and clips the pixel values of the updated adversarial example after each step into a permitted range.13
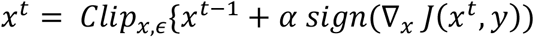
Known as the strongest first-order attack, PGD iteratively perturbs the input with smaller step size and after each iteration, the updated adversarial example is projected onto the ε-ball of x and clipped onto a permitted range.21
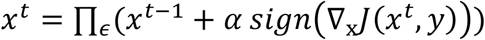
Additional information regarding adversarial attacks methods is provided in the Supplement.
Susceptibility to Adversarial Attacks
We investigated whether adversarial attacks on DL models for medical images were more effective than those on DL models for non-medical images. We measured attack difficulty by determining the smallest perturbation ε required for attacks to generally succeed. Given that larger image perturbations are more likely to be identified, images requiring a large pixel perturbation for attack success are considered less susceptible to adversarial attacks. Conversely, images requiring a small pixel-level perturbation for attack success are more vulnerable to adversarial attacks.
Effectiveness of Adversarial Training Defense
One successful defense mechanism against adversarial attacks is adversarial training, which aims to improve model robustness by integrating adversarial samples into the training stage.21,22 By training on both adversarial and normal images, the DL model learns to classify adversarial samples with higher accuracy compared to models trained on only normal samples. We investigated the effectiveness of an iterative adversarial training approach on the DL models trained on medical images. We measured the effectiveness of adversarial training by comparing model accuracy on adversarial samples of varying perturbation size before and after adversarial training. Details regarding our adversarial training protocol are detailed in the Supplement.
Image Level Adversarial Sensitivity and Model Performance
We examined each individual image’s adversarial sensitivity, as measured by the level of pixel-level perturbation necessary for DL model prediction to change as compared to an unperturbed image. Images requiring smaller perturbation to change DL model predictions would be considered more sensitive to adversarial attacks. We hypothesized that images most sensitive to adversarial attacks were also the images most likely to be misclassified by the DL model. By excluding images most sensitive to adversarial perturbation, we aimed to improve model performance on the remaining dataset. We identified the 20% of images most vulnerable to adversarial attack and excluded them from the test set. We then tested the performance of the original model on the reduced test set.
The proposed networks were implemented in Python 2.7 using TensorFlow v1.15.3 framework.34 Adversarial attacks were created using the Adversarial Robustness Toolbox v1.4.1.35 The code to reproduce the analyses and results is available online at https://github.com/Aneja-Lab-Yale/Aneja-Lab-Public-Adversarial-Imaging.
Results
Adversarial Attack Vulnerability of DL Models
Both medical and non-medical DL models were highly susceptible to adversarial attacks, which resulted in dramatic decreases in model accuracy for all datasets. Prior to applying adversarial attacks, we achieved classification accuracies of 75.4% for CT, 76.4% accuracy for mammogram, 93.6% for MRI, 99.1% for MNIST, and 86.1% for CIFAR-10. Under PGD attack, model accuracy showed a maximum absolute decrease of 49.8% for CT, 52.9% for mammogram, 87.3% for MRI, 99.1% for MNIST, and 77.3% for CIFAR-10 (Figure 2).

Classification accuracy of VGG16 model on adversarial examples generated by FGSM, BIM, and PGD attacks with increasing L∞ maximum perturbation size ε. Model performance decreased as ε increased for all datasets and attack types. *Note that the horizontal axis (ε) was scaled to 10−3 for graphs (a) to (c), to 10−1 for (d), and to 10−2 for (e).
Medical DL models appeared significantly more vulnerable to adversarial attacks compared to non-medical DL models. When examining the minimum perturbation size necessary for majority of attacks to be effective, a smaller ε was required for attacks to be successful on DL models for medical images compared to DL models for non-medical images. For example, under PGD attack with a perturbation size of 0.004, model accuracy was 25.6% for CT, 23.9% for mammogram, 6.36% for MRI, 99.0% for MNIST, and 71.9% for CIFAR-10 (Table 1). For the medical datasets, strong attacks (PGD and BIM) succeeded most of the time with tiny perturbations (ε < 0.004), while the non-medical datasets required much larger perturbations (ε > 0.07 for MNIST, ε > 0.01 for CIFAR-10) for attacks to be majority effective.
Effects of adversarial attacks of varying perturbation sizes on model classification accuracy. Adversarial samples were created by FGSM, BIM, and PGD with increasing L∞ maximum perturbation size ε. Models for medical datasets (CT, mammogram, and MRI) required smaller attack perturbation sizes than models for non-medical datasets (MNIST, CIFAR-10) for attacks to be generally effective.
Measuring Effectiveness of Adversarial Training
By reducing the rate of misclassification on adversarial samples, adversarial training led to increased robustness of DL models against adversarial attacks. After adversarial training was applied to our original VGG16 model, classification accuracy on adversarial examples increased for all datasets (Figure 3). Adversarial training caused absolute accuracy of the model on adversarial images to increase by up to 42.9% for CT, 35.7% for mammogram, and 73.2% for MRI. As perturbation size is increased for attacks used to generate adversarial test images, adversarial training becomes less effective at improving model performance.

Comparison of model classification accuracy before and after adversarial training on adversarial samples crafted by FGSM, BIM, and PGD with increasing L∞ maximum perturbation size ε. Adversarial training significantly increased model accuracy for all classification tasks and attack types. *Note that the horizontal axis (ε) was scaled to 10−3 for graphs (a) to (c), to 10−1 for (d), and to 10−2 for (e).
Image Level Adversarial Sensitivity and Model Performance
By using image level adversarial sensitivity as a metric to identify images most at risk for misclassification, we were able to improve overall DL model performance for all classification tasks. Test images were excluded if a PGD attack with perturbation size less than a certain threshold was sufficient to change the model prediction on the image. Excluding the images most susceptible to adversarial attack from the test set increased the model’s absolute accuracy by 5.9% for CT, 3.7% for mammogram, and 5.2% for MRI (Table 2).
Classification accuracy (%) of VGG16 model on the original test set and the test set excluding the 20% of test images most susceptible to adversarial attack. Images were excluded if PGD attack with perturbation size less than a certain threshold was sufficient to change the model prediction on the image. That threshold perturbation size was 0.0003 for CT, 0.00025 for mammogram, and 0.0006 for MRI.
Discussion
To our knowledge, our study is the first to investigate both the adversarial vulnerability of DL models for multiple imaging modalities in clinical oncology and the use of an iterative adversarial training approach to defend such models against first-order adversarial attacks. As the role of diagnostic imaging increases throughout clinical oncology, deep learning has shown to be incredibly powerful for medical image analysis tasks and represent a cost-effective tool to supplement human decision-making.36–38 However, vulnerability to adversarial attacks remains a potential barrier to fulfilling the promise of DL models in oncology. It is crucial to understand how adversarial images can be crafted to deceive DL models in the medical domain and whether proposed defenses against adversarial attacks from the non-medical domain represent a viable solution. In this study, we found that DL models for medical images are more vulnerable to adversarial attacks compared to DL models for non-medical images. Specifically, attacks on medical images require much smaller perturbation sizes to generally succeed compared to attacks on non-medical images. Furthermore, we found that adversarial training methods commonly used on non-medical imaging datasets mitigate the effects of adversarial attacks on DL models for oncological images. Finally, we showed that identifying images most susceptible to adversarial attacks maybe helpful in improving overall performance of DL models on medical images.
Several recent works have found that state-of-the-art DL architectures like Inception and UNet perform poorly on medical imaging analysis tasks when placed under adversarial attack.10,15,39–42 Our work extends the findings of previous studies by showing that DL models for oncologic images across various imaging modalities (CT, mammography, MRI) exhibit extreme vulnerability to adversarial attack, with small perturbations (< 0.004) being associated with sharp drops in model performance. We also show that DL models exhibited different levels of sensitivity to adversarial attack across different imaging modalities. Furthermore, while most studies used only one fixed perturbation size for adversarial attack, we varied perturbation size along a broad range to examine the relationship between model performance and attack strength.
In addition, our results corroborate previous work which showed that DL models for medical images are more vulnerable to adversarial attack than DL models for non-medical images (based on the minimum perturbation size necessary for attacks to generally succeed).15,43 By using MNIST and CIFAR-10 as a control and applying the same attack settings to DL models for all datasets, we determined that DL models for medical images were much more susceptible to adversarial attacks than DL models for non-medical images. One reason for this behavior could be that medical images are highly standardized and small adversarial perturbations dramatically distort their distribution in the latent feature space.44,45 Another factor could be the overparameterization of DL models for medical image analysis, as sharp loss landscapes around medical images lead to higher adversarial vulnerability.15
In the past, adversarial training on medical DL models have shown mixed results. In some studies, adversarial training improved DL model robustness for multiple medical imaging modalities like lung CT and retinal OCT.44,46,47 On the other hand, Hirano et al. found that adversarial training generally did not increase model robustness for classifying dermoscopy, OCT, and chest X-ray images.48 The difference in effectiveness of adversarial training can be attributed to the different adversarial training protocols used (e.g. single-step vs. multi-step, attack(s) used to generate training samples). It’s important to note that even in studies where adversarial training showed success in improving model robustness, the results were still not close to ideal, as some misclassification occurs even after adversarial training. This is expected as adversarial training, while capable of improving model accuracy on adversarial examples, has limits in effectiveness against strong attacks even on non-medical image datasets.21
Our work applied an iterative adversarial training approach to DL models for lung CTs, mammograms, and brain MRIs, demonstrating substantial improvement in model robustness for all imaging modalities. The effectiveness of adversarial training was highly dependent on the hyperparameters of adversarial training, especially the perturbation size for attack. While too-small perturbation sizes limit the increase in model robustness post-adversarial training, increasing the perturbation size beyond a certain threshold prevents the model from learning during training, causing poor model performance on both clean and adversarial samples. Our work demonstrated how the performance of the DL model post-adversarial training is inversely proportional to the perturbation size of the adversarial samples on which the model is evaluated. While adversarial training is effective in defending against weaker attacks with smaller perturbation magnitudes, it showed less success with strong attacks. While adversarial training proved successful at improving model performance on adversarial examples, our results were still far from satisfactory. One contributing factor is that medical images have fundamentally differently properties than non-medical images.15,44 Thus, adversarial defenses well-suited for non-medical images may not be generalizable to medical images.
We also showed that image level adversarial sensitivity, defined by the level of adversarial perturbation necessary to change image class predicted by model, is a useful metric for identifying normal images most at-risk for misclassification even under no attack. This has potentially useful clinical implications as we can improve the accuracy of the DL model by excluding such at-risk images from the rest of the dataset and providing them to a radiologist rather than the DL model for examination.
There are several limitations to our study which may bias our findings. First, we only used two-class medical imaging classification tasks. Thus, our findings might not generalize to multi-class or regression problems using medical images. Given that many medical diagnostic problems involve a small number of classes, our findings are likely still widely applicable to a large portion of medical imaging classification tasks. Also of note is the fact that we focused on first-order adversarial attacks rather than higher-order attacks, which have been shown to be more resistant against adversarial training.49 While the most commonly used adversarial attacks are first-order attacks, there is still need for additional research on how to defend DL models for medical images against higher-order attacks. A final limitation is that we used traditional supervised adversarial training to improve model robustness, while other nuanced methods like semi-supervised adversarial training and unsupervised adversarial training exist.44,50,51 While we demonstrated that supervised adversarial training is an effective method to improve model performance on adversarial examples, an interesting direction for future work would be to compare the utility of supervised adversarial training with that of semi-supervised or unsupervised adversarial training on DL models for medical images.
Conclusion
In this work, we explored the issue of adversarial attacks on DL models used for medical image analysis in clinical oncology. The paper first examined the sensitivity of DL models to adversarial attacks across increasing perturbation magnitudes for different medical and non-medical imaging datasets, demonstrating that DL models for medical images are more susceptible to attacks than DL models for non-medical images. We then showed that adversarial training effectively improved model robustness against adversarial attack. Finally, we saw that adversarial sensitivity of individual images could be used as a metric to improve model performance. By shedding light on the behavior of adversarial attacks on medical DL systems in oncology, the findings from this paper can help facilitate the development of more secure medical imaging DL models and techniques to circumvent adversarial attacks.
Data Availability
All data is available from the authors upon reasonable request.
Supplementary Material
Adversarial Attack Methods
Equations and parameters for FGSM, PGD, and BIM attack methods. The number of perturbation steps for BIM and PGD are both set to 10, and the step sizes are set to ε/10 and ε/4 for BIM and PGD, respectively.
Data Preprocessing and Augmentation
For each medical dataset, the classes (“cancer” and “noncancer”) were balanced. All images were center-cropped and resized, and pixels were normalized to have unit variance. For training the medical DL models, we used simple data augmentations: horizontal and vertical flips as well as random rotations with angles ranging between − 20° and 20°.
Model Architecture
Model parameters of VGG16 model.
Model Training Parameters
Training parameters for VGG16 models for all datasets.
Adversarial Training Protocol
We used a multi-step PGD adversarial training to increase the robustness of our DL models against adversarial attacks. In each batch, 50% of training samples were normal images, and the other 50% were adversarial images generated by PGD attack.
The hyperparameters for adversarial training are detailed below.
Adversarial training parameters for multi-step PGD training of VGG16 models.
Classification accuracy (%) of VGG16 model (before and after adversarial training) on clean test images and the 3 types of adversarial examples under maximum perturbation size of 0.003 (CT, mammogram, and MRI).





{kind=link}
{kind=link}
{kind=link}