
ABSTRACT
Smartphone-based digital biomarker (DB) assessments provide objective measures of daily-life tasks and thus hold the promise to improve diagnosis and monitoring of Parkinson’s disease (PD). To date, little is known about which tasks perform best for these purposes and how different confounds including comorbidities, age and sex affect their accuracy. Here we systematically assess the ability of common self-administered smartphone-based tasks to differentiate PD patients and healthy controls (HC) with and without accounting for the above confounds. Using a large cohort of PD patients and healthy volunteers acquired in the mPower study, we extracted about 700 features commonly reported in previous PD studies for gait, balance, voice and tapping tasks. We perform a series of experiments systematically assessing the effects of age, sex and comorbidities on the accuracy of the above tasks for differentiation of PD patients and HC using several machine learning algorithms. When accounting for age, sex and comorbidities, the highest balanced accuracy on hold-out data (73%) was achieved using random forest when combining all tasks followed by tapping using relevance vector machine (67%). Only moderate accuracies were achieved for other tasks (60% for balance, 56% for gait and 53% for voice data). Not accounting for the confounders consistently yielded higher accuracies of up to 77% when combining all tasks. Our results demonstrate the importance of controlling DB data for age and comorbidities.
I. INTRODUCTION
Diagnosis of Parkinson’s disease (PD) still often relies on in-clinic visits and evaluation based on clinical judgement as well as patient and caregiver reported information. This lack of objective measures and the need for in-clinic visits result in the often late and initially inaccurate diagnosis [1]. Recent studies have identified digital assessments as such promising objective biomarkers for PD symptoms including bradykinesia [2], [3], freezing of gait [4], [5], impaired dexterity [6], balance and speech difficulties [7]–[9]. Most of these results were obtained with a moderate number of participants and in a standardized and controlled clinical setting, reducing generalizability and limiting an interpretation with respect to applicability of these measures to an at-home self-administered setting [10]–[12].
As most relevant sensors deployed in these in-clinic studies are also embedded in modern smartphones, this opens the possibility to collect such objective, reliable and quantitative information as digital biomarkers (DB) in an at-home setting and therewith to facilitate diagnosis, health monitoring or treatment management using low-cost, simple and portable technology [13]. Indeed, recent studies applying machine learning algorithms to these high-dimensional data suggested a good diagnostic sensitivity of the respective digital assessments for detection of Parkinson’s disease [14]–[17]. However, such at-home assessments create a range of new challenges including selection bias, confounding and sources of noise that need to be understood and dealt with to ensure good reliability of respective outcomes to a level that is sufficient for at home data collection [18]. For example, age, sex and comorbidities are known confounding factors that impact many measures of disease symptoms across neurodegenerative diseases including PD [19]–[23]. Yet, several studies eluded the importance of matching and controlling for these variables [24]–[26], including age, sex [27], [28] or comorbidities which might induce motor (i.e. bradykinesia, tremor or rigidity) and non-motor (i.e. fatigue, restless legs or sleep) symptoms [25]. Other potential data collection biases include small sample sizes [14], [29], inclusion of several recordings per subject [15], [27] or signals of different time lengths [28], which may potentially lead the classifier to detect the idiosyncrasies of each subject rather than specific PD related symptoms, as demonstrated by Neto et al. [30]–[32]. In addition, replicability of results is rarely performed in current studies, which may lead to lack of generalizability. Despite the considerable promise for DB in healthcare, these issues limit comparability across studies, hindering interpretation and obstructing translation to the clinic.
Recently, a large dataset of at-home smartphone-based assessments of commonly applied PD tasks including gait, balance, finger tapping and voice evaluations was collected in the mPower study providing a unique resource to examine DB in the study of PD [33], [34]. Indeed, several studies applying machine learning (ML) algorithms have employed this dataset in the study of PD diagnosis, achieving quite different results across studies. Whilst plausible, the impact of the aforementioned confounds on ML-based detection of PD using different at-home digital assessments has not been yet systematically established and has indeed been ignored in many previous studies [15], [24], [28], [35], [36].
Here we systematically explore the influence of accounting for age, sex and comorbidities in the detection of PD in a large at-home dataset. Concretely, we use the mPower dataset to evaluate the ability of common DB task (gait, balance, voice, tapping) for differentiation between PD and HC. In addition, we identify potential DB of Parkinson’s disease. With this work, we aim to outline practical suggestions to guide future studies practices and improve comparability across studies.
II. METHODS
A. DATA
Data used in this work were derived from the mPower study [33]. MPower is a mobile application-based study to monitor indicators of PD progression and diagnosis by the collection of data in subjects with and without PD. Using this app, subjects were presented with a one-time demographic survey about general demographic topics and health history. Completion of the Movement Disorder Society’s Unified Parkinson’s Disease Rating Scale (MDS-UPDRS) and the Parkinson’s Disease Questionnaire short form (PDQ-8) surveys used for PD assessment was requested at baseline as well as monthly throughout the course of the study. Due to the length of the MDS-UPDRS instrument, subjects were presented only a subset of questions focusing largely on the monitor symptoms of PD [33]. Participants had to select “true” or “false” to the following question “Have you been diagnosed by a medical professional with Parkinson Diseaseã”. According to this answer, they were classified as Parkinson’s Disease (PD) or Healthy Control (HC). Subjects who did not answer this question were discarded from further analysis. All subjects were presented with different tasks including gait, balance, voice and tapping, which they could complete up to 3 times per day. Subjects who self-identified as having a professional diagnosis of PD were asked to perform these tasks (1) immediately before taking their medication, (2) after taking their medication and (3) at some other time (Table 8). Subjects who self-identified as not having a diagnosis of PD could complete these tasks at any time during the day. In the gait task, subjects were asked to walk 20 steps in a straight line. In the balance task they were required to stand still for 30 seconds. During the voice activity task, subjects were requested to say ‘Aaah’ into the microphone for 10 seconds. Finally, during the tapping task participants were instructed to alternatively tap two points on the screen within a 20 seconds interval. We additionally excluded those subjects who gave no information about their age, sex or had inconsistencies in their clinical data (e.g. self-reported healthy controls who answered questions about PD diagnosis or PD medication). Since the mPower dataset is strongly slanted toward young HC (Table 15), we restricted our analysis to those subjects within the age range of 35 to 75 years old. This cleaning step resulted in the exclusion of 40-50% of the data depending on the task. To avoid “learning effects” and biases due to several recordings, we only considered the first recording of each subject in the analyses. Further details about data cleaning can be found in Appendix I. Demographic details are shown in Table 1.
B. PRE-PROCESSING
The tri-axial accelerometer integrated in the smartphone records acceleration in the 3 axes (vertical, mediolateral and anteroposterior) during the gait and balance tasks. A 4th order 20 Hz cut-off low-pass Butterworth filter was applied to the 3 accelerometer signals. An additional 3rd order 0.3 Hz cut-off high-pass Butterworth filter was applied to minimize the acceleration variability due to respiration [37]. Signals were then standardized to eliminate the gravity component while maintaining the information from outlier data. According to Pittman et al. [24], 30% of the devices were not held in the correct position and therefore, we additionally calculated the average acceleration signal. Several signals were extracted from the gait recordings including the step series, position along the 3 axes calculated by double integration, velocity and acceleration along the path [38] (Fig. 1).

Two additional signals were considered for the balance task (Fig. 1). Tremor frequency in PD is estimated to fall in the 4-7 Hz band [39], whereas postural acceleration measures (tremor-free) fall in the 0-3.5 Hz interval. To extract tremor-free measures of postural acceleration, we applied a 3.5 Hz cut-off low-pass Butterworth filter [40].
Voice was recorded at a sample rate of 44.1 Kbps. Pre-processing included a downsampling to 25 KHz and a noise reduction using a 2nd order Butterworth filter with a low-pass frequency at 400 Hz. The fundamental frequency signal was calculated using a Hamming window of 20 ms with 50% overlap, and verified with the software Praat (Fig. 1). Time, frequency and amplitude series were extracted from the voice signals.
Tapping recordings consist of the {x,y} screen pixel coordinates and timestamp for each tap on the screen. Both the inter-tapping interval (time) and the {x,y} inter-tap distance series were computed (Fig. 1). Further details about pre-processing for each task can be found in Appendix I.
C. FEATURE EXTRACTION
A comprehensive search was conducted in PubMed (https://pubmed.ncbi.nlm.nih.gov/) with the following search terms ((Parkinson’s disease) AND (walking OR gait OR balance OR voice OR tapping) AND (wearables OR smartphones)) to identify features commonly applied for each task and corresponding signals generated. Based on the results of this search, 423, 183, 124 and 43 features were identified and computed using Matlab R2017a from gait [41]–[44], balance [7], [37], [40], [45], voice [25], [26], [46] and tapping data [15], [33], [47], respectively (Table 4-Table 7).
D. MACHINE LEARNING ALGORITHMS
As a different ML algorithm may provide the best performance for a given task, we evaluated four commonly applied algorithms for differentiation between PD and HC:
Least Absolute Shrinkage and Selection Operator (LASSO) is a linear method commonly used to deal with high-dimensional data. LASSO applies a regularization process, where it penalizes the coefficients of the regression variables shrinking some of them to zero. During the feature selection process, those variables with non-zero coefficients are selected to be part of the model [48]. LASSO performs well when dealing with linearly separable data and avoiding overfitting.
Random Forest (RF) uses an ensemble of decision trees, where each individual tree outputs the classes. The predicted class is decided based on majority vote. Each tree is built based on a bootstrap training set that normally represents two thirds of the total cohort. The left out data is used to get an unbiased estimate of the classification error and get estimates of feature importance. RF runs efficiently in large datasets and deals very well with data with complicated relationships [49].
A Support Vector Machine (SVM) with Radial Basis Function (RBF) kernel with Recursive Feature Elimination (SVM-RFE). An SVM is a linear method whose aim is to find the optimal hyperplane that separates between classes. When data is linearly non-separable, it may be transformed to a higher dimensional space using a non-linear transformation function that spreads the data apart such that a linear hyperplane can be found in that space. Here, we used a radial basis kernel function. RFE is a feature selection method that ranks features according to importance, improving both efficiency and accuracy of the classification model. This model is known to remove effectively non-relevant features and achieve high classification performance [50].
Relevance Vector Machine (RVM), which follows the same principles of SVM but provides probabilistic classification. The Bayesian formulation prevents from tuning the hyper-parameters of the SVM. Nonetheless, RVMs use an expectation maximization (EM)-like learning that can lead to local minima unlike the standard sequential optimization (SMO)-based algorithms used by SVMs, that guarantee to find a global optima [51].
E. FRAMEWORK
The following six experiments were performed to address the questions on the impact of age, sex and comorbidities that may influence task performance on the classification accuracy for each task and on the combination of all tasks for differentiation between PD and HC (Table 2):
Experiment 1 (E1: all) includes all subjects only restricting the age range (35-75 years old).
Experiment 2 (E2: matched) includes subjects after an age and sex matching between PD and HC, where we strictly match one HC for each PD subject with the same age and where possible with the same sex.
Experiment 3 (E3: no comorbidities, matched) excludes all comorbidities that may affect task performance (see Appendix I) and strictly matches for age and where possible sex on the remaining subjects.
Experiments 4-6 (E4-6): Three additional experiments assess if controlling for age and sex impacts the results. These experiments exclude comorbidities, match for age and sex and control for age and/or sex applying multiple regression to regress out their effects prior to classification: Experiment 4 (E4): no comorbidities, matched, controlled for age; Experiment 5 (E5): no comorbidities, matched, controlled for sex; Experiment 6 (E6): no comorbidities, matched, controlled for age and sex.
As the performance obtained after removing comorbidities and matching for age and sex (E3) provides a relatively unbiased estimate for differentiation between PD and HC, these results were used for selection of the best performing ML algorithm for each task and interpretation of the main outcomes throughout this work. Demographic and clinical information for each experiment are provided in Table 1.
Additionally, to compare the performance of our analyses to those in the literature, we performed an analysis including all data without restricting age range (Table 15) and an analysis including all data and both age and sex as features.
F. MODEL PERFORMANCE
Data leakage occurs when information of the holdout test set leaks into the dataset used to build the model, leading to incorrect or overoptimistic predictions. Therefore, in every experiment and task, data was initially split into 2/3 of data to build the predictive model and 1/3 of holdout data to validate this model. To build the model, we performed 1000 repetitions of 10-fold cross-validation (CV) in the 2/3 of the data for each classifier to avoid data leakage and increase robustness. The parameter Lambda of the LASSO model was set to 1 and the number of trees for RF to 100. A nested cross-validation was implemented to tune the parameters of the SVM-RFE classifier, following a grid search for the regularization constant (C) ranging from 2-7 to 27 and for gamma (γ) ranging from 2-4 to 24 for the SVM. For each model, we report the following measures of predictive performance: balanced accuracy (BA), sensitivity, specificity, positive (PPV) and negative predictive value (NPV), mean receiver operating characteristic (ROC) curves with 95% confidence intervals and area under the curve (AUC). Comparisons between models are based on BA.
Once the best predictive model with the highest cross-validation BA was identified using the CV dataset, it was validated using the holdout dataset, reporting the aforementioned performance metrics. In addition, to test whether the BA of the predictive model is higher than chance level (0.5 for binary classification), we ran 1000 permutations randomly permuting the predicted classes, reporting BA at 95% confidence intervals.
III. RESULTS
A. CLASSIFIER SELECTION AND RESULTS FOR THE CV DATASET
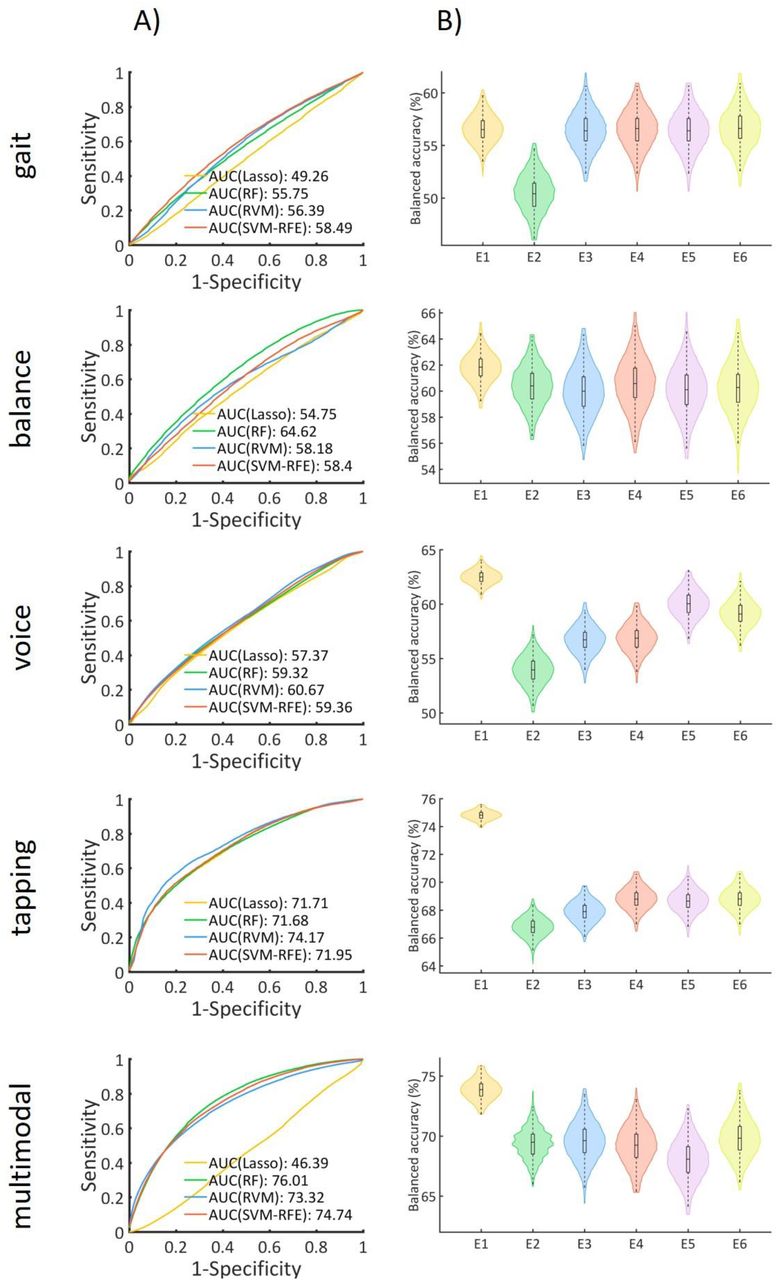
Four different classifiers (random forest: RF, Least Absolute Shrinkage and Selection Operator: LASSO, support vector machine: SVM, relevance vector machine: RVM-RFE) were applied to each of the four tasks and their combination during the main experiment (E3: no comorbidities, matched for age and sex). Table 9 provides detailed information on the classification performance for each ML algorithm and each task. The ROC curves and corresponding AUC values for the four classifiers for each of the tasks during the cross-validation (CV) step are displayed in Fig. 2A. RF, RVM and SVM-RFE performed similarly across all tasks, whereas LASSO was the classifier performing the poorest. Best performance was achieved on the combination of all tasks using RF (balanced accuracy (BA)): 69.6%), followed by tapping using RVM (BA: 67.9%), balance using RF (BA: 60%), voice using RVM (BA: 56.7%) and gait using SVM-RFE (BA: 56.5%).

A) ROC curves and AUC values for 4 different classifiers for each task, during the main experiment (E3: no comorbidities, matched). B) Balanced accuracy distributions for each task and experiment (E1-E6). E1: all data. E2: age and sex matched. E3: no comorbidities, age and sex matched. E4: no comorbidities, age and sex matched, controlled for age. E5: no comorbidities, age and sex matched, controlled for sex. E6: no comorbidities, age and sex matched, controlled for age and sex.
B. COMPARISON OF EXPERIMENTS IN THE CROSS-VALIDATION SETTING
ML algorithms performing best for each task in the main experiment (E3: no comorbidities, matched for age and sex) were applied to corresponding task data of the other five experiments (E1: all subjects, E2: matched for age and sex, E4-6: same as E3 but additionally regressing out the effects of age and/or sex). Classification performance for each task and experiment during the CV and over holdout sets is summarized in Table 3 and Table 10-Table 14. BA distributions for each experiment and task during the CV are displayed in Fig. 2B.
In the CV, E1 (all data) resulted in the highest but modest BA for all tasks (gait: 56.6%; balance: 61.8%; voice: 62.5%; tapping: 74.8; multimodal combining all four tasks: 73.9%). Removal of comorbidities in E3 had a marginal effect on BA as compared to E2 (matched for age and sex) with increased BA for gait (E2: 50.3%; E3: 56.5%), voice (E2: 53.9%; E3: 56.7%) and tapping (E2: 66.8%; E3: 67.9%) but lower BA for balance (E2: 60.4%; E3: 60.0%). After additionally regressing out the effects of age and/or sex (E4-E6) the change in the BA was negligible for all tasks (< 1%) except for voice when regressing out sex (E3: 56.7%; E5: 60%) and both age and sex (E3: 56.7%; E6: 59.2%) (Table 3, Table S7-S11).
Analyses including all data without trimming for age range led to the highest accuracy of 74.4% using tapping data, followed by 72.7% for the multimodal case and 58%, 52.9% and 51% for balance, voice and gait data respectively. In all cases specificity was close to 100% whereas sensitivity was exceedingly low (Table 16-Table 20). When including both age and sex as additional features, accuracy increased to 80.8% for tapping data, 75.3% for the multimodal case and 73.1%, 69% and 57% for voice, balance and gait data respectively with high specificities and low sensitivities.
C. RESULTS FOR THE HOLDOUT DATASET
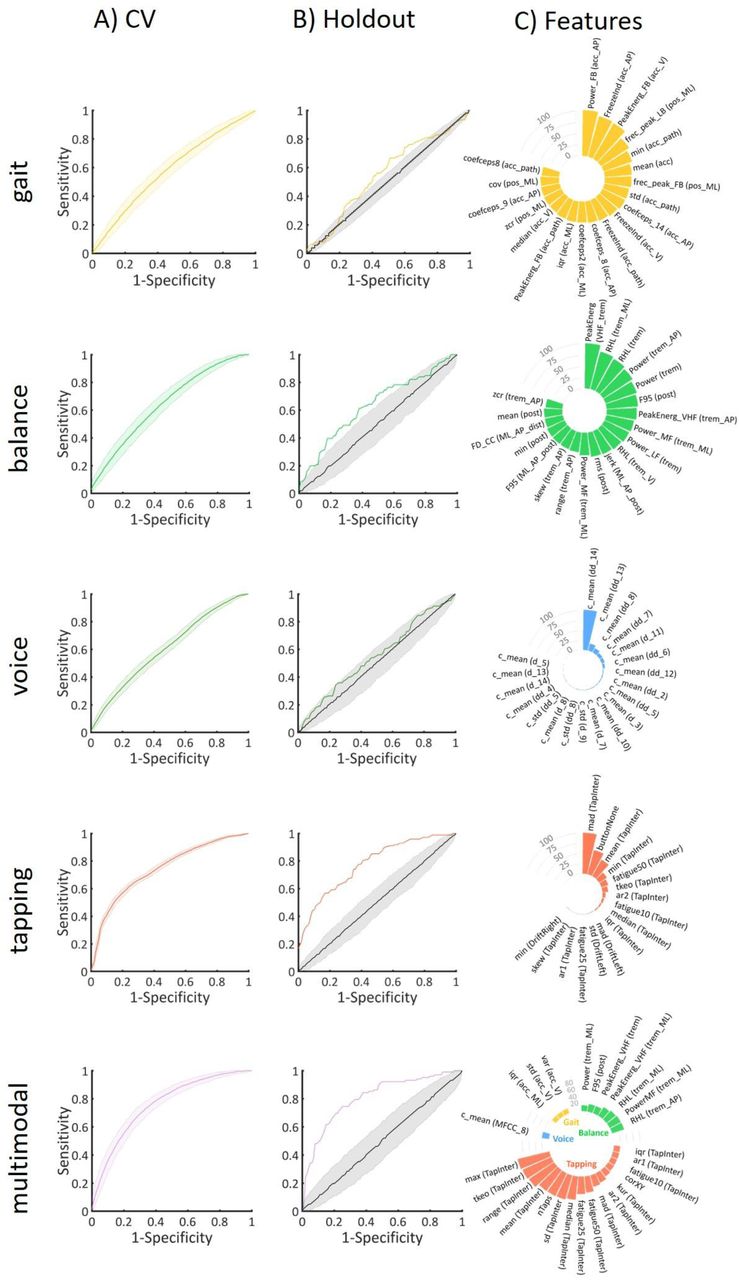
Best performing classifiers trained on the 2/3 of the initial dataset used for cross-validation were applied to the 1/3 holdout dataset. Results for the holdout dataset were highly similar to the CV results (Table 3, Table S7-S11). All results are summarized in Fig. 3 and Table 3. The multimodal combination of all tasks resulted in the best performance for differentiation of PD and HC in the holdout cohort (BA: 73.5%) followed by the tapping features (67.2%). Voice features achieved the lowest BA of 53% followed by gait (55.7%) and balance (59.9%) features (Table 3). For the base experiment E3, the difference in BA between CV and holdout sets was less than 1% for all tasks except for a 3.7% reduction in BA for voice data and a 3.9% increase for the multimodal feature combination. Exclusion of comorbidities resulted in only minor changes for gait, balance and tapping (<2%) with a 6.8% drop only observed using voice data and a 3.5% increase for the multimodal case. BA performance for all tasks increased by 1.4% (gait) to 7.4% (voice) for all tasks when using the dataset only restricting the age range (E1) as compared to E3. No systematic effects of additionally controlling for age and/or sex prior to classification (E4-E6) were observed with BA changes being small and inconsistent across tasks and experiments.

{kind=link}
{kind=link}
{kind=link}
A) ROC curves at 95% CI during CV. B) ROC curves at 95% CI during validation of holdout set and at the chance level. C) Scaled average weights of features for each task for the main experiment (E3: no comorbidities, matched). Gait) acc - average acceleration, acc_path – acceleration along path, AP – anteroposterior, FB – freezing band, LB – locomotor band, ML – mediolateral, pos – position, V – vertical, vel – velocity. Balance) trem – tremor, post – postural, dist – distance, LF – low frequency, MF – medium frequency, VHF – very high frequency, RHL – ratio between high and low frequency, F95 –frequency containing 95% of the power spectrum. Voice) c – cepstral coefficient, d – 1st derivative of cepstral coefficient, dd – 2nd derivative of cepstral coefficient. Tapping) TapInter – tap interval. For details on features refer to Appendix I.
Analyses including all data without trimming for age range reached the highest accuracy in the holdout set of 73.3% using multimodal features, followed by 71.1% for the tapping task and 55.8%, 52.6% and 51.6% for balance, voice and gait data respectively (Table 16-Table 20). When including both age and sex as additional features, accuracy in the holdout data raised to 78.9% for tapping data, 75.9% for the multimodal case and 74.6%, 66% and 58.3% for voice, balance and gait data respectively with very high specificities and very low sensitivities.
D. PREDICTIVE FEATURES
Best performance during CV for the main experiment E3 was achieved using the multimodal set of features. Fig. 3 shows the scaled average absolute feature weights for RVM and SVM-RFE and the scaled average importance scores for RF, calculated with the out-of-bag (OOB) permuted predictor delta error across 1000 repetitions during the CV. Features with the highest importance scores belong to the tapping task followed by the balance task. Tapping features with the highest importance scores comprised the range of intertap interval (100), maximum value of the intertap interval (99.8) and Teager-Kaiser energy operator of the intertap interval (83.2). Balance features with highest importance scores were the power ratio between high (3.5-15 Hz) and low (0.15-3.5 Hz) frequency for anteroposterior acceleration (31.5) and energy in the medium frequency band for mediolateral acceleration (25.3). Gait and voice tasks had the least contributions in terms of importance scores.
IV. DISCUSSION
Here, we systematically evaluated the ability of four commonly applied DB tasks to differentiate between PD and HC in a self-administered remote setting. Our findings indicate that, depending on the constellation, not accounting for confounds in PD digital biomarker task data may lead to under-but also over-optimistic results.
A. IDENTIFICATION OF PARKINSON’S DISEASE
Out of the four evaluated machine learning algorithms, similar performance was achieved for all classifiers except LASSO which showed the poorest performance. Whereas some previous studies using the mPower dataset selected different algorithms according to tasks [25], [26], others simply applied a single classifier [28], [30]. No single classifier performed best for all four tasks in our study. This is in line with previous research showing that the selection of the classifier depends mainly on the type and complexity of the data [52], [53]. For instance, RF, RVM and Gaussian SVM are non-linear algorithms, offering more flexibility regarding the type of data. On the contrary, LASSO is a linear classifier and thus, its performance depends on whether the data is linearly separable. Whereas the generalizability of this observation is limited by the use of only one linear classifier, it may point to a better usability of non-linear approaches for classification of digital assessments.
For discrimination of PD and HC, combination of all tasks reached a BA of 74%, followed by tapping that achieved 67%, outperforming other tasks which were close to chance level. These results are in line with previous literature using the mPower dataset, where tapping reached the highest accuracies and gait and voice were closer to chance level [30]. Several studies reported higher accuracies for this type of data [24], [28]. Yet, these studies followed certain “optimistic” approaches as discussed below.
B. POTENTIAL CONFOUNDERS
Exclusion of comorbidities resulted in increased accuracies by a few percent, suggesting that other diseases may add more variability to the signal. Prediction performances considerably decreased for all tasks after matching for age and sex indicating the importance of controlling for such confounds in DB data. When including all data without trimming age range, accuracies greatly increase. Nonetheless, specificity values are exceedingly high whereas sensitivity values are vastly low. This indicates a greater prediction ability for the HC group, which is considerably larger than the PD group for subjects under 35 years old. Including age and sex as part of the features resulted in further accuracy increases, yet with very low sensitivities. Since the dataset is strongly slanted toward young HC, the model is most likely distinguishing HC based on age and gender in this case. Such effects may also explain the high accuracies in some of the previous studies using mPower dataset, where no proper matching for these confounds was performed, age and/or sex were used as features despite a large imbalance across groups or non-balanced accuracies were reported [24], [26], [28], [35]. In example, in the overall mPower dataset HC outnumber PD by a factor of five and age and sex alone provide a high discrimination accuracy between PD and HC with PD being on average 28 years older and more often female (34% of PD vs 19% of HC). Our findings are also in line with previous studies demonstrating a similarly strong decrease in accuracies when accounting for respective confounds. Neto et al. [54] studied the effect of confounders on gait data. They reached very high accuracy when not accounting for confounders, compared with a very modest accuracy when using unconfounded measures. Schwab and Karlent [25] performed analysis with all the tasks from the mPower dataset with and without including age and sex, the latter resulting in a similarly low accuracy as in our study.
For all classification experiments, we used only one recording per subject to prevent the classifier from detecting the idiosyncrasies of each subject rather than specific PD related symptoms [30]–[32]. Single measures are likely to contain more noise due to higher variation in task administration as well as in individual performance in a poorly-controlled setting [55]. Using multiple time points may therefore further increase the discrimination between PD and HC as demonstrated in several previous studies [30]– [32]. Yet, our results in this respect highlight the need of further understanding and better control of the individual parameters which impact the task performance during a single administration.
C. PREDICTORS OF PARKINSON’S DISEASE
Features with largest weights in the multimodal discrimination between PD and HC were derived from the tapping task. These features mostly related to the inter-tapping interval (time), presumably reflecting bradykinesia-like symptoms. These results are in line with previous studies, where tapping features related to speed and accuracy had the strongest correlation with clinical scores [56], [57]. Balance task features related to tremor measures had larger weights than postural ones. In addition, features from the frequency domain had greater weights than spatiotemporal features. Spatiotemporal features have been extensively studied and applied, due to their ease of computation and interpretability [58]. However, these features offer information limited primarily to leg movement, whilst frequency features add information regarding asymmetry and variability. Furthermore, balance features with higher weights belonged to the mediolateral and anteroposterior signals, related to stability. Even though gait had limited contribution to the classification accuracy, acceleration features had the highest weights from this task. This observation is in line with previous findings where acceleration proved to better capture PD-related gait changes [59]. In line with some previous studies, features with the highest weights from the voice task were all based on Mel Frequency Cepstral Coefficients which can detect subtle changes in speech articulation that are common in PD [60], [61].
D. LIMITATIONS AND FURTHER RESEARCH
Whereas sensors-integrated in smartphones open new opportunities for at-home continuous, reliable, non-invasive and low-cost monitoring of PD, our finding highlight the need for further development, optimization and standardization of specific measures for such applications.
The interpretation of our findings is limited by several aspects, including the lack of standardization, poor control of environmental and medication effects during performance of the tasks and intentionally or unintentionally incorrect information provided by the participants. In addition, removal of comorbidities and matching for age and sex led to exclusion of about 50% of data, which may affect the training of classifiers [54].
Data Availability
The m-Power dataset used for this article is available upon registration from Synapse at: https://www.synapse.org/#!Synapse:syn4993293/
AUTHOR CONTRIBUTION
MG performed the overall analyses and wrote manuscript. JD designed the overall study and contributed to writing the manuscript. KRP, SBE and MSF provided input on the analyses. All authors contributed to interpretation of results, reviewed and commented on the manuscript.
AUTHOR DECLARATION
The access to the Mpower data was granted after registration in the Synapse system, signing an oath, submitting an Intended Data Use Statement and accepting data-specific Conditions. All appropriate institutional forms have been archived.
ACKNOWLEDGMENT
Data used in this study were contributed by users of the Parkinson m-Power mobile application as part of the m-Power study developed by Sage Bionetworks and described in Synapse [doi:10.7303/syn4993293].
APPENDIX I
SUPPLEMENTARY METHODS
A. DATA CLEANING
MPower dataset offers demographic, PDQ8 and MDS-UPDRS surveys and task-based data. The demographics table contains data for 6805 subjects. In order to establish a diagnosis, participants had to select “true” or “false” to the following question “Have you been diagnosed by a medical professional with Parkinson Diseaseã”. According to this answer, they are classified as Parkinson’s Disease (PD) or Healthy Control (HC). Some subjects left this question unanswered and thus they were discarded from further analysis. Those subjects classified as PD which did not completed the PDQ8 and MDS-UPDRS questionnaire were also excluded. Subjects with no information on age, sex or any task data were also removed, resulting in 6614 subjects. Those empty, null or corrupted files for each task were deleted, resulting in 2807 subjects with gait and balance data, 4925 with voice data and 6366 with tapping data. Since a large number of subjects are HC under 35 years old, our analysis focused on a subset of subjects within the age range of 35 to 75 years old, leading to 1435 subjects with gait and balance data, 2186 subjects with voice data and 2644 subjects with tapping data. Finally, all subjects with inconsistencies for each of the tasks were discarded (i.e., subjects that reported not to have been diagnosed with Parkinson’s disease but filled in PD medication questions, year of diagnosis of PD, surgery or deep brain stimulation). This last elimination resulted in 1416 subjects with gait and balance data, 2153 subjects with voice data and 2600 subjects with tapping data.
B. SIGNALS LENGTH
Gait task consists of walking 20 steps in a straight line. In order to analyse the same signal length for each subject, we examined how many subjects had gait data for different time durations. We observed that after 10 seconds, participation was dropping heavily. Therefore, we selected a time length of 10 seconds and discarded those participants with shorter signals. Following the same reasoning, we chose voice signals of 7 seconds, trimming the first second and last two seconds, and tapping signals of 20 seconds. Similarly, balance task consists of standing still for 30 seconds although just 20 seconds were selected. Nonetheless, whereas gait, voice and tapping are independent tasks, and therefore they are started by the user, balance task starts straight after the gait task. This is, as soon as the gait task ends, the app plays out loud “turn around and stand still for 30 seconds”. As a result, most of the balance recordings include initial slots of noise, which most likely coincide with the time that subjects listen to the instructions, react, turn around and start the task. Therefore, we trimmed the first 5 seconds of the signal, resulting in balance signals of 15 seconds for all subjects. Final number of subjects consisted of 1397 subjects with gait data, 1415 subjects with balance data, 2150 subjects with voice data and 2600 subjects with tapping data.
C. PRE-PROCESSING AND SIGNAL EXTRACTION
Gait and balance data consists on vertical (V), anteroposterior (AP) and mediolateral (ML) acceleration signals. For these 3 gait acceleration signals, we applied a Butterworth low pass filter with cut-off frequency at 20 Hz followed by a 3° order high pass filter at 0.3 Hz. According to Pittman et al. [24], around 30% of devices were not held in the correct position. Therefore, the greatest gravitational displacement is not always along the vertical axis. Then, we standardized these three signals and calculated an additional average acceleration signal. Based on the standardized acceleration signal, we extracted the step series. We calculated position signals along the three axes by double integrating the acceleration signals and the average position. Then, we extracted velocity and acceleration along the path by derivation [38].
Balance acceleration signals were filtered with a low pass Butterworth filter at 20 Hz. Since tremor in PD usually falls in the 4-7Hz frequency band [39], [40], the interval 0-3.5 Hz is considered for tremor-free or postural acceleration measures. Hence, we applied a Butterworth filter at 3.5 Hz to extract postural acceleration measures. We also calculated the average of the tremor acceleration in the 3 axes and the average of the postural acceleration in the 3 axes.
Voice signals were recorded at a sample frequency of 44.1 KHz. We downsampled the signal to 25KHz, applied a second order Butterworth filter with cut-off frequency at 400 Hz followed by a pre-emphasis FIR filter for noise reduction and correct for distortions. We extracted the fundamental frequency (f0) series, which was verified with the Praat software.
Tapping recordings consists of the {x,y} screen pixel coordinates and timestamp for each tap on the screen. Signals derived out of these recordings were the inter-tapping interval (time) and the {x,y} inter-tap distance series.
D. FEATURE EXTRACTION
GAIT
We extracted 11 signals from the original accelerometer recordings during gait tasks. These are V, AP and ML acceleration, the step series, the average of the acceleration in the three axes, the V, AP and ML position, the average position in the three axes, the velocity and the acceleration along the path. Table 4 collects a list of features extracted for these signals along with their acronyms.
BALANCE
Balance signals consist in the V, AP and ML tremor acceleration (4-7 Hz), the average of these 3 signals, the V, AP and ML postural acceleration (0-3.5 Hz) and the average of these 3 signals. We extracted displacement-related postural features from ML, AP and average of both distance signals, following the formulation in Martinez-Mendez et al. [37] (Table 5).
View this table:Table 5. List of balance featuresVOICE
Most of voice features were extracted following the formulation in Tsanas et al. [46]. Tsanas et al. state that the period (T) signal provides different information than f0. Therefore, we additionally extracted the T series. Further signals include glottis quotient and 14 Mel Frequency Cepstral Coefficients (MFCCs), including the 0th coefficient and the log-energy of the signal, along with their associated delta and delta-delta coefficients as applied in the Voicebox Matlab ToolBox [62] (Table 6).
View this table:Table 6. List of voice featuresTAPPING
We considered a set of features computed from the inter-tapping interval (time) and the {x,y} inter-tap distance signals, according to Bot et al. [47] (Table 7).
View this table:Table 7. List of tapping features
E. COMORBIDITIES
Comorbidities selected for removal in the experiments E3-E6 include “Alzheimer Disease or Alzheimer dementia”, “Dementia”, “Schizophrenia or Bipolar Disorder”, “Alcoholism”, “Multiple Sclerosis”, “Leukemia or Lymphoma”, “Acute Myocardial Infarction/Heart Attack”, “Stroke/Transient Ischemic Attack”, “Breast Cancer”, “Colorectal Cancer”, “Prostate Cancer”, “Lung Cancer”, “Endometrial/Uterine Cancer”, “Any other kind of cancer OR tumor”, “Heart Failure/Congestive Heart Failure”, “Ischemic Heart Disease”. These comorbidities were removed since they may lead to brain damage or to undertake chemotherapy or other therapy, which might induce brain changes.
F. MEDICATION STATUS
Table 8 shows the number of subjects that performed the task just before taking their medication, after taking their medication, at another random time, number of those who were not taking any medication and number of those who did not give any information about their medication status.
G. SELECTION OF THE BEST CLASSIFIER DURING THE MAIN EXPERIMENT (NO COMORBIDITIES; MATCHED)
Table 9 shows the classification performance for the four classifiers under consideration for each task.
APPENDIX II
SUPPLEMENTARY RESULTS
Table 10-Table 14 summarize the results for each task (gait, balance, voice, tapping) and the combination of all the tasks, for the experiment 1 (all data), experiment 2 (matched data), experiment 3 (no comorbidities and matched data), experiment 4 (no comorbidities, matched, controlled for age), experiment 5 (no comorbidities, matched, controlled for sex) and experiment 6 (no comorbidities, matched, controlled for age and sex).
A. ADDITIONAL EXPERIMENTS
Our results may differ to those in the current literature using the mPower dataset since we follow different approaches. To explain these discrepancies and compare with the literature, we included two additional experiments including all data without trimming for age range and all data including both age and sex as features in the analyses (Table 15). Classification performances for both additional experiments for each tasks are summarized in Table 16-Table 20.
REFERENCES
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].
- [9].↵
- [10].↵
- [11].
- [12].↵
- [13].↵
- [14].↵
- [15].↵
- [16].
- [17].↵
- [18].↵
- [19].↵
- [20].
- [21].
- [22].
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].
- [32].↵
- [33].↵
- [34].↵
- [35].↵
- [36].↵
- [37].↵
- [38].↵
- [39].↵
- [40].↵
- [41].↵
- [42].
- [43].
- [44].↵
- [45].↵
- [46].↵
- [47].↵
- [48].↵
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].↵
- [59].↵
- [60].↵
- [61].↵




