
Abstract
Background Carotid endarterectomy (CEA) and carotid artery stenting (CAS) are recommended for high stroke-risk patients with carotid artery stenosis to reduce ischemic events. However, we often face difficulty in determining the best treatment strategy.
Objective We aimed to develop an accurate post-CEA/CAS outcome prediction model using machine learning that will serve as a basis for a new decision support tool for patient-specific treatment planning.
Methods Retrospectively collected data from 165 consecutive patients with carotid stenosis underwent CEA or CAS were divided into training and test samples. The following five machine learning algorithms were tuned, and their predictive performance evaluated by comparison with surgeon predictions: an artificial neural network, logistic regression, support vector machine, random forest, and extreme gradient boosting (XGBoost). Seventeen clinical factors were introduced into the models. Outcome was defined as any ischemic stroke within 30 days after treatment including asymptomatic diffusion-weighted imaging abnormalities.
Results The XGBoost model performed the best in the evaluation; its sensitivity, specificity, positive predictive value, and accuracy were 31.9%, 94.6%, 47.2%, and 86.2%, respectively. These statistical measures were comparable to those of surgeons. Internal carotid artery peak systolic velocity, low density lipoprotein cholesterol, and procedure (CEA or CAS) were the most contributing factors according to the XGBoost algorithm.
Conclusion We were able to develop a post-procedural outcome prediction model comparable to surgeons in performance. The accurate outcome prediction model will make it possible to make a more appropriate patient-specific selection of CEA or CAS for the treatment of carotid artery stenosis.
Introduction
Carotid artery stenosis is an important cause of ischemic stroke, which remains a major public health problem worldwide [25]. To reduce the risk of ischemic stroke, carotid endarterectomy (CEA) and carotid artery stenting (CAS) are recommended for patients at high stroke risk with carotid artery stenosis. Based on the evidence that there are no significant differences in long-term outcomes after CEA and CAS [1,10,23], there are general guidelines for patient selection for CEA and CAS [10,13,26]. However, we often face difficulty in determining the best treatment method. Therefore, it is necessary to develop a useful decision support tool for patient-specific treatment planning for carotid artery stenosis. Recently, the use of artificial intelligence (AI) has been increasing in medical field because of advances in technology including robust machine learning (ML) algorithms for successful prediction and diagnosis [14]. However, no studies have applied modern ML models in the carotid stenosis cohort.
In this study, we aimed to develop an accurate ML model for the prediction of ischemic events within 30 days after CEA or CAS with 17 clinical factors. The usefulness of the ML models was evaluated by comparing their predictions with those of surgeons. Because early periprocedural major and minor stroke is associated with long-term outcomes [18], our model to predict post-procedural ischemic events can serve as the basis for an effective decision support tool for patient-specific adaptation of CEA and CAS. Additionally, the relative importance of the clinical features was measured using an ML method.
Materials and Methods
Study population
We enrolled 170 consecutive cases of carotid stenosis treated with CEA or CAS at a single center in Japan between January 2013 and December 2018. Patient information was retrospectively collected from the hospital carotid stenosis database and anonymized before analysis. This retrospective study was approved by the institutional review board. Written informed consent was obtained from all patients before treatment. We excluded patients with arterial dissection and those who could not undergo MRI because of pacemaker implantation. The missing values were imputed by the k-nearest-neighbours (kNN) method [29]. We used the clinical data of patients until March 2018 as training data to optimize the hyperparameters and train the ML models, and used the data of more recent patients, from April to December 2018, as test data to evaluate the predictive performance of each model. The sample size was determined based on a previous study [8]. We conducted and reported this study in compliance with the transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD) statement for multivariate prediction models [19].
Treatments
Therapeutic approach was in accordance with the guidelines [13,26] based on stenosis degree assessed by NASCET criteria [7]. Basically, CAS was performed for CEA high-risk patients according to the inclusion criteria in the SAPPHIRE study [10]. The final treatment strategy was made by a multidisciplinary team. CEA was performed under general anaesthesia by three surgeons. Continuous neurophysiological monitoring was performed by neurophysiologists during surgery with a multimodality protocol involving electroencephalogram (EEG), median nerve somatosensory evoked potentials (SSEP), and bilateral regional cerebral oximetry (rSO2). Shunt placement was determined by the onset of alarm criteria for either EEG or SSEP, which was defined as a >50% decrease in amplitude [9]. CAS was performed under local anaesthesia by four surgeons. The rSO2 was monitored during the procedure. Each patient treated with CAS was administered 100 mg aspirin and 75 mg clopidogrel daily for at least 7 days before and 90 days after the CAS. The choice of stent and interventional strategy were determined by the interventional team.
Clinical parameters
A total of 17 clinical parameters were used for the ML model development. These parameters consisted of age [27], pretreatment modified Rankin scale (mRS) [21], hypertension [21], diabetes mellitus [11,24,30], medical history of arteriosclerotic disease [5], serum low-density lipoprotein (LDL) cholesterol value (mg/dL) [24], internal carotid artery peak systolic velocity (ICA-PSV, cm/sec), symptomatic [24,27], crescendo transient ischemic attack (TIA) or stroke in evolution [11], previous neck irradiation [6], type III aorta [24], contralateral carotid occlusion [30], stenosis at a high position, mobile plaque, plaque ulceration [11,24], vulnerable plaque, and procedure (CEA or CAS) [4,18,20]. History of arteriosclerotic disease was defined as a history of acute coronary syndrome or peripheral artery disease requiring treatment. Crescendo TIA was defined as at least two similar TIAs in one week. Contralateral carotid occlusion, stenosis at a high position, and type III aorta were assessed using MRA, CTA, or angiography. Stenosis at a high position was defined as carotid stenosis that extends distally to the height of the vertebral body of C2. The ICA-PSV, mobile plaque, and plaque ulceration were assessed using echocardiogram. A vulnerable plaque was defined as a plaque that presents a hyperintense signal on an MRI time-of-flight image.
Outcomes
Outcome was defined as minor or major ischemic stroke including asymptomatic diffusion weighted imaging (DWI) hyperintense lesions within 30 days after CEA or CAS. Minor stroke was defined as a National Institutes of Health Stroke Scale score of less than 3, and major stroke was defined as a score of 3 or higher. Postprocedural MRI was performed the day after the procedure for CAS and less than one week afterwards for CEA. Additional MRI was performed if any neurological deficit was observed.
Development of machine learning models
The following five ML models were applied: artificial neural network (ANN), logistic regression, random forest, support vector machine (SVM), and extreme gradient boosting (XGBoost) [3]. The logistic regression, random forest, and SVM were implemented using scikit-learn, which is a free ML library for Python. The ANN model was implemented using the Keras library with a TensorFlow backend. All the ML models were developed using Python version 3.7.7, Scikit-learn version 0.22.1, and TensorFlow version 2.2.0. First, we performed hyperparameter tuning of all models except for ANN using a grid-search algorithm with log-loss as the objective function on the training data. All numerical variables were standardized using centring and scaling. When applying grid-search, the value of the objective function was evaluated by stratified 5-fold cross-validation. The hyperparameters of the ANN model were hand-tuned using the holdout method on the training data with cross-entropy as the objective function. The base ANN model consisted of three dense layers with two dropout layers and two batch normalization layers (Supplemental table 1). After identifying the optimal hyperparameters for every model that minimize the log-loss value, we evaluated the predictive performance of each model using 10 times repeated stratified 5-fold cross-validation on the training data. The averages of the area under the receiver operating characteristic curve (ROC AUC), sensitivity, specificity, positive prediction value (PPV), and prediction accuracy were calculated through the cross-validation, and 95% confidence intervals were estimated. We also created and evaluated an ensemble model which comprises of the three models with the highest ROC AUC on the training data.
Test of machine learning models
The data of 22 consecutive patients treated by CEA or CAS at the same institution from April to December 2018 were used as a test data. Their post-procedural outcomes were predicted using the trained ML models with the 17 factors. In this procedure, we used the standard bootstrap method as an additional internal validation technique. In this study, the number of resampling repetitions, which should be as large as possible to ensure the stability of the estimates, was set to 1000 repetitions. The bootstrap averages of sensitivity, specificity, PPV, and prediction accuracy were calculated, and 95% confidence intervals were estimated. Using the same 17 factors, four surgeons (board-certified neurosurgeons who had at least 10 years of experience) also predicted the post-procedural outcomes for each patient based on the test data within 10 minutes. When surgeons performed the outcome prediction test, to ensure that other information was never leaked, a paper test with information on only the 17 clinical factors for each patient was used. The average sensitivity, specificity, PPV, and prediction accuracy of the predictions of the four surgeons were compared with those of the ML models.
Feature importance measurement
The relative importance of the clinical features was measured by the total gain of the XGBoost algorithm. The gain is the relative contribution of a feature to the model, calculated by taking each feature’s contribution to each tree in the gradient boosting decision tree model. Thus, the features with higher gain are more important for generating the prediction of the XGBoost model.
Statistical Analysis
Descriptive and comparative statistics were used to describe clinical characteristics of the patients. We performed a statistical comparison between training and test groups using Welch’s t-test for numerical values, Fisher’s exact test for categorical variables, and the Mann–Whitney U test for pretreatment mRS. A 2-tailed probability value of 0.05 or lower was considered statistically significant. Statistical analysis was performed using EZR version 1.38.
Results
Study participants
The flow diagram of model development and validation is presented in Figure 1. Among the 170 patients with carotid stenosis, five (2.9%) were excluded. Thus, the data of a total of 165 patients with carotid stenosis were included for analysis and separated into training and test data. The baseline characteristics before missing value imputation are shown in Table 1. There were 36 (22%) patients over 80 years of age, and 127 (77%) patients in good condition (mRS 0-1). Severe carotid stenosis, which was defined as an ICA-PSV of more than 200 cm/s, was observed in 115 (70%) patients. CEA and CAS were performed on 95 (58%) and 70 (42%) patients, respectively. The outcome was observed in 45 (27%) patients. Major stroke, minor stroke, and asymptomatic DWI hyperintense lesions were diagnosed in 3 (1.8%), 3 (1.8%), and 39 (24%) patients, respectively. All missing values were imputed using the kNN method. No significant difference was found in the comparison before and after imputation of the missing values (data not shown). Although age and follow-up duration were significantly older and shorter, respectively, in the test data, there was no significant difference between the training and test data for the other factors that were used for analysis after imputation (Table 1). The test data tended to have more CAS and fewer outcomes, but there were no significant differences.

Flow diagram describing the general framework of the study. Models were built using the training dataset. The test dataset was used for measuring the predictive performance and comparison with the surgeons. CAS, carotid artery stenting; CEA, carotid endarterectomy; ICA-PSV, internal carotid artery peak systolic velocity; kNN, k-nearest-neighbours; LDL, low density lipoprotein; PPV, positive predictive value
Patient characteristics
Prediction of post-procedural ischemic events on the training dataset
To evaluate the predictive performance of five ML models for post CEA/CAS outcomes, 10 times repeated stratified 5-fold cross-validation was first performed on the 143-patient training data. The prediction results showed that the ROC AUC of XGBoost was highest at 0.719, sensitivity of SVM was highest at 36.2%, and the specificity, PPV, and accuracy of random forest were highest at 98.3%, 78.9%, and 75.4%, respectively (Table 2). Then, an ensemble model of the logistic regression, XGBoost, and ANN models, which were the three most highest ROC AUC models, was also created and evaluated. It yielded a ROC AUC of 0.739, sensitivity of 15.1%, specificity of 97.4%, PPV of 75.1%, and accuracy of 72.7%. Thus, the ensemble model obtained the highest ROC AUC on the training data.
Prediction results on the training dataset evaluated by repeated 5-fold cross validation and sorted by ROC AUC
Prediction of post-procedural ischemic events on the test dataset and comparison with surgeons
Next, to confirm the post-CEA/CAS outcome prediction performances of the six ML models including the ensemble model, these models were further evaluated on the 22-patient test data with the bootstrap method. The results are shown in Table 3. XGBoost achieved the highest PPV, and accuracy scores, which were 47.2% and 86.2%, respectively. The highest sensitivity was 34.0%, which was achieved by random forest, SVM, and logistic regression. The highest specificity was 95.4%, which was achieved by ANN. The ensemble model, which obtained the highest ROC AUC on the training data, did not perform so well on the test data.
Prediction results on the test dataset evaluated using the bootstrap technique and sorted by accuracy.
The average of the outcome predictions made by four surgeons had a sensitivity of 41.7%, specificity of 75.0%, PPV of 20.1%, and accuracy of 70.5%. Therefore, all of the current ML models trained with 143 cases and 17 factors outperformed the surgeons’ predictions in terms of specificity and accuracy. However, surgeons showed a higher predictive sensitivity than the current ML models. A statistical analysis was not performed on these results because of the small sample size. The optimized hyperparameters of these models are listed in Supplemental table 1.
Importance values of the clinical factors
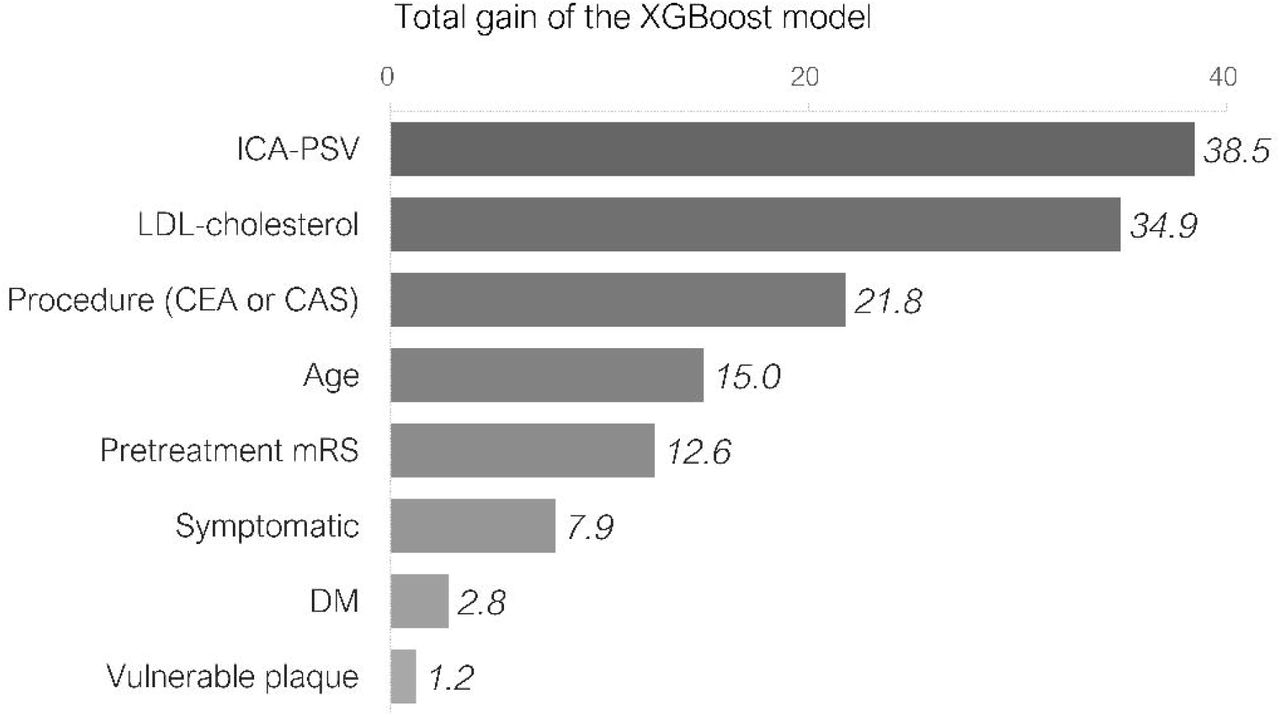
The feature importances were measured using a function of the XGBoost algorithm, which obtained the best predictive performance on the test data. The results reveal that ICA-PSV, serum LDL-cholesterol value, and procedure (CEA or CAS) are the most important in this order (Figure 2).

{kind=link}
{kind=link}
Importance values of the clinical factors measured using the total gain of the XGBoost algorithm. CAS, carotid artery stenting; CEA carotid endarterectomy; DM, diabetes mellitus; ICA-PSV, internal carotid artery peak systolic velocity; LDL, low density lipoprotein; mRS, modified Rankin scale
Discussion
In this study, we identified two notable findings. First, using an appropriate model construction process with effective clinical factors, we were able to develop a post-CEA/CAS outcome prediction model that is comparable to surgeons in terms of sensitivity, specificity, PPV, and accuracy, although our models were developed with a relatively small number of patients.
Second, in our validation process, the XGBoost model had the highest predictive performance, and the factors that contributed most to the accurate model were ICA-PSV, serum LDL-cholesterol value, and procedure (CEA or CAS).
ML and ICAS
Using an appropriate model construction process with effective clinical factors, we were able to develop a post-CEA/CAS outcome prediction model that is comparable to surgeons in terms of sensitivity, specificity, PPV, and accuracy, although the ML models were developed using relatively few patients. This is the first study to predict the outcome after treatment of carotid artery stenosis using ML models. Our model makes it possible to preoperatively calculate the post-CEA/CAS stroke risk as a concrete numeric value; for example, 10% with CEA and 15% with CAS for postprocedural stroke risk, which could contribute to better treatment and prevention designs. However, a problem of the current models is that sensitivity is relatively low. To increase the prediction sensitivity, we tuned the models with sensitivity as the objective function during model development. However, such sensitivity-oriented models showed a considerable decrease in accuracy, although sensitivity increased slightly (data not shown). Therefore, these sensitivity-oriented models were not adopted this time. To further improve the predictive performance of an ML model, it would be necessary to use big data and more dominant influential factors. In this study, the incidence rate of postprocedural ischemic events was 27%, which was similar to the results of previous studies [28].
The number of studies using ML to explore stroke and neurosurgical diseases has increased rapidly over the past decade. The most frequently applied algorithms are ANN, logistic regression, random forest, and SVM [2,12,31], which suggests that our model selection is appropriate. In our study, the predictive performance of the XGBoost was better than those of the ANN, logistic regression, SVM, and random forest. Although the superior performance of the GBDT model has been shown in many data-science contests in recent years [32], there is still very little research on neurosurgery or stroke using the GBDT model [22,32]. The ensemble model, which had the highest ROC AUC on our training data, did not perform so well on the test data, probably because of overfitting on the training data.
Feature Importance
In our validation process, the XGBoost model showed the highest predictive performance, and the factors that contributed most to its accuracy were ICA-PSV, serum LDL-cholesterol value, and procedure (CEA or CAS). The procedure type, CEA or CAS, has previously been reported as a potential predictor of periprocedural stroke [4,18,20,21]. Thus, it seems reasonable that the procedure type is the third most important factor in this study. However, no studies have suggested that ICA-PSV or serum LDL-cholesterol value are associated to postprocedural outcome. Although ICA-PSV should reflect the degree of stenosis, many studies reported that the degree of stenosis is not associated with postprocedural outcome [24,27]. ICA-PSV might be used in our model as a valid predictor in combination with other clinical factors. In a study investigating the components of emboli captured by the filter-protection device during CAS, more postoperative DWI high intensity lesions were observed in patients whose main component of the emboli was cholesterol [17]. It may be inferred from such results that serum LDL-cholesterol might be related to post-procedural outcome because it should be possible for a higher serum LDL-cholesterol value to leads to a higher cholesterol content of the plaque, which produces emboli.
Comparison of clinician and AI performance
Many studies have compared clinicians and AI with image interpretation or diagnostic performance and have shown that ML models are equivalent to or superior to specialists [16,33]. However, there were very few studies that compared the predictive performance of clinicians and AI as in this study [15]. The sensitivity of the surgeons’ prediction was higher than our ML models, presumably because the surgeons have experience of more than 143 patients, which comprise the dataset that our ML models learned. Therefore, instead of a difference in predictive ability, the number of experienced and learned cases might have influenced the results. The advantage of an ML model is that if only the question and answer are provided correctly, it can learn an enormous number of cases that one surgeon would not be able to experience. Therefore, in future, as the number of training cases increases, the predictive performance of the ML model would further improve.
Limitations
One of the main limitations of our study is the small sample size. Because big data generally makes ML models more accurate, a larger sample size would be needed for more accurate predictions. However, a previous report suggested that 80–560 samples are required for ML algorithms excluding deep neural networks, and the required sample size depends on the dataset and sampling method [19]. Furthermore, a systematic review of AI in neurosurgery has shown that the median number of patients in each study was 120 [2]. Thus, the sample size might not be insufficient for our ML models (excepting the ANN model). Next, optimizing hyperparameters for neural network models is generally difficult because they have many hyperparameters that need to be adjusted. In addition to hyperparameters, the neural network architecture should be optimized for better performance [34]. In this study, because the ANN was hand-tuned by multiple trial-and-error sessions, a more effective hyperparameter set might be found by other, more sophisticated optimization methods. Finally, because the dataset was collected retrospectively from a single institution, it is prone to selection bias, and our ML models may not be applicable to other institutions where different treatment strategies or patient demographics might exist. Although internal validation was applied with repeated cross-validation and bootstrap methods, further external validation is necessary in another setting that differs in time or place to validate the performance of our prognostic models.
Conclusion
We were able to develop a post-CEA/CAS outcome prediction model with a performance comparable to that of surgeons. The XGBoost model showed the best predictive performance which achieved more than 85% accuracy, and the factors that contributed most to model building were ICA-PSV, serum LDL-cholesterol value, and procedure (CEA or CAS). Larger datasets and analysis of potential prognostic factors would be necessary to further improve the predictive performance of the ML models, which will enable a more appropriate patient-specific selection of CEA or CAS for the treatment of carotid stenosis.
Data Availability
The patient data that support the findings of this study are available from the corresponding author upon reasonable request. A subset of the program code generated for this study is available at GitHub.
https://gist.github.com/kkmatsuo/e77e78a0346280d5570829164760132f
Conflict of Interest
None.
Supplementary Information
Supplemental Table1 Optimized hyperparameters of five machine learning models.
Footnotes
The results were up-dated with re-evaluation of our models by using repeated stratified cross validation and bootstrapping method. Table 1 and Figure 1 were also revised for clarity.
References




