
Abstract
The Czech Republic (or Czechia) is facing the second wave of COVID-19 epidemic, with the rate of growth in the number of confirmed cases (among) the highest in Europe. Learning from the spring first wave, when many countries implemented interventions that effectively stopped national economics (i.e., a form of lockdown), political representations are now unwilling to do that again, at least until really necessary. Therefore, it is necessary to look back and assess efficiency of each of the first wave restrictions, so that interventions can now be more finely tuned. We develop an age-structured model of COVID-19 epidemic, distinguish several types of contact, and divide the population into 206 counties. We calibrate the model by sociological and population movement data and use it to analyze the first wave of COVID-19 epidemic in Czechia, through assessing effects of applied restrictions as well as exploring functionality of alternative intervention schemes that were discussed later. To harness various sources of uncertainty in our input data, we apply the Approximate Bayesian Computation framework. We found that (1) personal protective measures as face masks and increased hygiene are more effective than reducing contacts, (2) delaying the lockdown by four days led to twice more confirmed cases, (3) implementing personal protection and effective testing as early as possible is a priority, and (4) tracing and quarantine or just local lockdowns can effectively compensate for any global lockdown if the numbers of confirmed cases not exceedingly high.
It is about eight months when COVID-19 infection entered the Czech Republic. The epidemic started and was initially fueled by Czech citizens returning from the popular alpine ski resorts of Italy and Austria. The first three confirmed cases arose on March 1, 2020. Population-wide interventions began on March 11, 2020, with closing schools, which were soon followed by travelling restrictions, closing of restaurants, sports and cultural facilities, and shops (with exceptions), as well as duty to wear face masks, use disinfection and keep at least 2 m inter-personal distance on public (Table 1). In May 2020, the epidemiological situation in Czechia has stabilized, and the government started to gradually relax the restrictions implemented during the lockdown. Contrary to dramatic epidemics in many European countries, Czechia appeared to face a relatively mild first wave. In the summer months, only low infection incidence was reported, and life returned nearly to its pre-pandemic state (in view of school vacations and related national and international holidays). All started to change by the end of August 2020 when the number of confirmed cases started to rise again, this time affecting mainly younger age cohorts. Still, not much was done, presumably because of low numbers of hospitalized and dead. This has changed dramatically during September 2020, and as of late October 2020, the Czech Republic faces an unprecedented second wave, accompanied with a worrying increase in the numbers of hospitalized, including those in serious conditions. An overview of the COVID-19 epidemic in Czechia is provided on the web pages of the Ministry of Health of the Czech Republic (onemocneni-aktualne.mzcr.cz/covid-19).
Population-wide interventions against COVID-19 (the lockdown) in the Czech Republic during the spring first wave.
Learning from the spring lockdown, especially as regards its negative economic impacts, governments all over the world are now not so eager to implement intense population-wide restrictions (i.e., a form of lockdown) again. Clearly, even if implemented again, this state could not be kept forever, as it does not only dive economics, but also negatively affects mental state of people. For example, an increase in divorce rate was reported in Wuhan, China, after quite stringent restrictions were eventually alleviated there (19). Therefore, it is necessary to look back and assess effectiveness of the particular interventions adopted during the spring lockdown. Moreover, some other measures such as tracing and quarantining recent contacts of confirmed cases or implementing a geographically restricted lockdown were later applied or considered, and it is useful to look also at what might happen if they were alternatively implemented in the early phases of epidemic.
Here we develop a detailed compartmental model to (i) reproduce the initial phase and lockdown period of COVID-19 epidemic in the Czech Republic, accounting for all implemented interventions, (ii) conduct a retrospective analysis of those interventions, and (iii) assess potential effects of alternative strategies proposed during the first wave or later. We structure our model by age, type of inter-individual contacts and space, thus allowing to explore and compare relative efficiency of a number of realistic intervention strategies that can be incorporated and timed explicitly (Methods). It contains a core epidemic layer, hospital layer, quarantine layer, and testing layer. In our model, we integrate public health data on the first wave in Czechia, results of sociological surveys performed before and during the first wave, real-time population movement data, and epidemiological parameters estimated from both public health and published data. To account for all these sources of information and their uncertainty, we use an Approximate Bayesian Computation framework based on massive super-computing simulations; this allows us to assess credibility intervals of our results given up-to-date knowledge on COVID-19 (Methods).
Initial phase and lockdown period as baseline scenario
To reach the goals we outline above, we first focus on the initial phase of epidemic and subsequent lockdown, spanning the period between 1 February 2020 and 7 May 2020. The first three cases of the COVID-19 epidemic in the Czech Republic were reported on March 1, 2020. Population-wide interventions soon followed (Table 1). Till May 7, the restriction scheme was clear, there were no unreported local interventions, and the numbers of confirmed cases were high enough to match assumptions of our population model. Therefore, we use 1 February 2020 as our arbitrary starting date to cover a real epidemic beginning (the first three cases apparently got infected and showed symptoms before March 1 and some undetected asymptomatic cases were certainly imported, too) and 7 May 2020 as a date until which all those interventions apply. Based on the age-specific cumulative numbers of confirmed cases from this period, we infer uncertain epidemiological parameters (i.e., calibrate our model) and use the resulting setup as the baseline state for our retrospective analyses. The mechanistic character of our model allows for exact implementation of specific dates of intervention initiation (and relaxation), and for setting up factors that reflect impacts of these interventions on epidemiological as well as behavioral parameters our model contains. Where possible, we base these factors on results of sociological surveys on behavioral responses before and during the lockdown (Methods, Fig. 1).

(A) Behavioral responses before and during the lockdown in Czechia, based on public opinion polls organized by the PAQ Reseach agency (Methods; www.paqresearch.cz) every week (in between the subsequent polls, data are linearly interpolated). The orange line is a proportional reduction in the number of contacts with respect to the pre-pandemic state (value 1), the red and blue lines are proportions of respondents that reported using face masks and increased hygiene. (B) Reduction of the weekly number of contacts in different environments due to the COVID-19 epidemic, according to the public opinion polls organized by the Median agency (Methods; www.median.eu). The respective proportional reductions in contacts that we use during the lockdown are thus 0.44 for home, 0.45 for work, 0.03 for schools, and 0.35 for other types of contact; our model distinguishes just these four types of contact (Methods).
We use the Approximate Bayesian Computation (ABC), a technique used to estimate parameters of complex models in genomics and other biological disciplines (1, 6), including epidemic modeling (2, 17), to integrate all our data sources, including their uncertainty. More specifically, using a high performance computer, we simulated 100,000 realizations of epidemic dynamics from the model, using parameter values randomly generated from prior distributions based on public health data in Czechia or literature review (Methods; blue distribution in Fig. 2A). Subsequently, we used a rejection-sampling algorithm to select 0.1% of model realizations (100) that best matched the observed age-specific cumulative numbers of confirmed cases (Fig. 2B). The parameters used to generate these selected realizations form an outer estimate of Bayesian posterior distribution of parameter values (1, 6) (red distribution in Fig. 2A).

(A) Prior parameter distributions based on available information are first built for every parameter to be estimated (blue distribution). (B) Parameter sets randomly generated from these priors are then used to run the model, and the sets for which the corresponding simulations provided a sufficiently good fit to the observed data were not rejected and were used to built posterior distributions for the estimated parameters; red distribution of panel A is the marginal distributions calculated from the resulting multidimensional posterior distribution.
The distributions of parameter values corresponding to selected simulation runs thus possess residual uncertainty in the parameters after the model is confronted with the observed data (1, 6). We may think of the individual accepted parameter sets as different worlds our observations of which are compatible with real observations, and we can study the epidemic of COVID-19 in any of these worlds or in all of them simultaneously (Methods).
As Figs 2B and 3 indicate, our model is able to grasp dynamics beyond the COVID-19 epidemic in Czechia. We emphasize that while reasonably fitting the numbers of confirmed cases in any age cohort (Fig. 3) means reasonable fit of the total number of confirmed cases (Fig. 2B), the converse is not true (not shown). Therefore, we think that age-structured models should always be calibrated on age-structured data, simply to be able assess effects of interventions that are often targeted to specific age cohort.

Temporal dynamics of the age-structured and total cumulative numbers of confirmed cases for the baseline scenario, covering the initial phase of epidemic and the following lockdown, for children (age cohort 0-19, A), adults (age cohort 20-64, B), seniors (age cohort 65+, C), and the probability density functions for the number of confirmed cases by 7 May 2020 (D). In panels A-C, blue curves represent real observations, while the orange lines are results of model simulations run for 100 selected posterior parameter sets. In panel D, the vertical lines represent the numbers of confirmed individuals by May 7, 2020.
Retrospective analysis
A lot of epidemiological models developed to describe the COVID-19 epidemic have been prospective and were not calibrated on real observations, providing qualitative predictions forward in time (8, 10, 11). Another large group of models are statistical in nature, attempting to retrospectively analyze an effect of applied interventions right from observed data (4, 9). Our model in a sense bridges these two groups of models, providing a mechanistic description of the epidemic, enabling freely switch interventions on and off and modify their intensity, while at the same time being calibrated on a robust set of observed data.
We consider the following scenarios that we are going to compare with the baseline one (more detailed description of each scenario follows):
R1 Lockdown interventions adopted four days before their actual date
R2 Lockdown interventions adopted two days before their actual date
R3 Lockdown interventions adopted two days after their actual date
R4 Lockdown interventions adopted four days after their actual date
R5 No contact reduction assumed, degree of personal protection as observed
R6 Contact reduction as observed, no personal protection assumed
R7 Dates of imposing protective measures and closing schools plus recommending home office swapped
R8 Testing in March assumed as effective as later in April and May
R9 Tracing and quarantine applied since April 1, 2020
R10 Local lockdowns applied since April 1, 2020
All these scenarios work with posterior parameter sets identified above; in each of the 100 selected posterior sets a change in policy is made and a corresponding model is run. An absolute impact of each scenario is examined, as well as its relative impact with respect to the baseline scenario (Methods).
Experience from many countries demonstrates that one of the most important issues is timing of interventions; every single day of postponing them or of implementing them earlier counts (we are of course aware of other than epidemiological factors that enter the stakeholders’ decision process, but we focus just on epidemiology in this study). Indeed, establishing every single intervention two or four days earlier or later produces significant differences in the number of confirmed cases by 7 May 2020. (Figs 4 and 5). Thus, every day counts in the rate of responding to the incipient epidemic. As we show below, delay of four days in implementing lockdown roughly doubles the number of confirmed cases by May 7.

Temporal dynamics of the total cumulative numbers of confirmed cases for the lockdown scenario shifted four days back (A-B) or two days back (C-D). Blue lines in the left panels represent real observations, while the orange lines are results of model simulations run for 100 selected posterior sets. In the right panel, probability density functions for the number of confirmed cases by 7 May 2020 is provided for each considered age group; the vertical lines represent the numbers of confirmed individuals by May 7, 2020.

Temporal dynamics of the total cumulative numbers of confirmed cases for the lockdown scenario shifted two days forward (A-B) or four days forward (C-D). Legend as in Fig. 4.
The scenario R5 is inspired by a highly discussed issue of whether leave schools open or rather close them (4, 21, 14). Since leaving schools open means in our model on average nearly 5 child-child contacts more per day, we extend the commonly assumed scenario of closing schools to asking more generally whether personal protection itself would suffice, without limiting any type of contact in the population. Not limiting contacts worsens the epidemic about five times (Fig. 6A). On the other hand, keeping the amount of contacts limited as observed, but without any personal protection, produces twenty times more confirmed cases on average by May 7 (scenario R6, Fig. 6B). Model results are thus less sensitive to changes in contact structure than to changes in the factor reducing infection transmission due to protective measures (face masks, increased hygiene, interpersonal distance).

Temporal dynamics of the total cumulative numbers of confirmed cases for the scenario without limiting contact structure (A) or with reducing compliance to enhanced protection to zero (B). Legend as in Fig. 4.
The art of responding to any epidemic is not only in setting up the right restrictions and setting up them in time, but also setting them in an optimal order or implementing them as effectively as possible. With regard to our above finding that personal protection measures in the form of wearing face masks, using hand disinfection and keeping interpersonal distance appears more effective than just limiting social contacts, we suggest that implementing the former as early as possible is more effective (Fig. 7A). Similarly, any decrease in the delay related to testing symptomatic cases weakens the epidemic spread (Fig. 7B).

Temporal dynamics of the total cumulative numbers of confirmed cases for (A) the scenario with swapped application of personal protective measures (from March 19 to March 11) and closing schools and recommending home office (from March 11 to March 19) or (B) with testing efficiency (average time delay from symptom onset to case confirmation) in March equal to that in April and May. Legend as in Fig. 4.
Effects of two scenarios that have been used or considered to compensate an expected increase in the number of confirmed cases when lockdown was relaxed are now examined. We consider either tracing contacts of confirmed cases and their quarantining or local lock-down when a given threshold in the number of new cases per 100,000 inhabitants during the last seven days is exceeded in any specific county. Either intervention is implemented since the beginning of epidemic. Both scenarios suggest that both tracing and quarantine and only local lockdowns can successfully replace any global lockdown if intensive efficient enough (Fig. 8); no contact limitation was imposed in tracing and quarantine scenario and in counties not under local lockdown, while the degree of personal protection remained as under global lockdown.

(A-B) Temporal dynamics of the total cumulative numbers of confirmed cases for when tracing and quarantine were applied since the beginning of epidemic. The efficiency of tracing was set to 90%, while the numbers of contacts reached 100% of pre-pandemic state; the personal protection level remained as during the lockdown. Without quarantine, the situation is as in Fig. 6A-B. Legend as in Fig. 4. (C-D) Temporal dynamics of the total cumulative numbers of confirmed cases for when local lockdowns are alternatively applied instead of full lockdown since April 1, 2020. A local lockdown means full lockdown except of limiting mobility when in a county the number new cases are observed per 100,000 inhabitants during the last 7 days exceeds 10. Legend for the left panels as in Fig. 4, the right panels show the proportions of counties (out of 206) that are closed at a given date.
More quantitative way of assessing the effect of (not) implementing an intervention is to calculate effects of an intervention relative to the baseline (i.e., general lockdown) scenario when both simulations come from respective worlds (Methods; Fig. 9. Obviously, intervening as soon as possible, sequencing the involved restrictions optimally and testing efficiently is by far a preferred strategy. We show that every four days of delaying the interventions double the number of confirmed cases by the end of period we follow, that personal protective measures are more efficient than reducing the number of contacts and that tracing and quarantine or just local lockdowns may compensate for relaxation, but only if some measures still remain in effect. These conclusions may seem trivial, and they actually are. The advantage of modeling epidemics is in providing some quantitative assessment of what intensity of interventions is not enough and which may hopefully suffice.

Effects of adopted scenarios in absolute terms (A-B) and relative to the baseline general lockdown scenario (C-D) for the expected number of confirmed cases on May 7, 2020. Codes for different scenarios are described earlier in the text.
Discussion
We developed a mathematical model to analyze the spring first wave of COVID-19 in the Czech Republic. The model allows decoupling of protective as opposed to contact-limiting measures, setting up dates of implementing and relaxing of various types of interventions, and structures the population by age (three age cohorts: children, adults and seniors), type of contact (four types: at home, at school, in work and within community) and space (206 counties). Moreover, we included tracing and quarantining contacts of confirmed individuals and calibrated the model to the cumulative number of confirmed cases (so we needed a testing layer that modeled transition from real numbers of cases to the observed ones). We found that (1) personal protective measures as face masks and increased hygiene are more effective than reducing contacts, (2) delaying the lockdown by four days led to twice more confirmed cases, (3) implementing personal protection and effective testing as early as possible is a priority, and (4) tracing and quarantine or just local lockdowns can effectively compensate for any global lockdown if the numbers of confirmed cases not exceedingly high.
Two types of models have generally been used to get an insight into the effects of non-pharmaceutical interventions in controlling COVID-19 epidemics. One of these groups, exemplified by Davies et al. (8), Domenico et al. (10), Ferguson et al. (11), contains mechanistic prospective models that aim at predicting a future course of epidemics, which use parameter values found in the literature, often coming from different parts of the world, and are not calibrated on real observations in a given country. Another group of models, exemplified by Brauner et al. (4), Dehning et al. (9), are statistical in nature, attempt to retrospectively analyze an effect of applied interventions right from the observed data, and often analyze many countries at once. Our model in a sense bridges these two groups of models. It provide a mechanistic description of the epidemic, enables freely switch interventions on and off and modify their intensity, while is at the same time calibrated on a robust set of observed data from the Czech Republic. Hence, it can be used to make prospective predictions, but can also look back and retrospectively analyze an effect of interventions applied in the past. One of its unique features is a use of sociological data to quantify a degree of compliance of established interventions, that is, a degree of contact limitation in various environments as well as a degree of compliance of obeying required protective measures (wearing face masks, using disinfection, keeping interpersonal distance).
Another unique feature of our model is how it deals with uncertainty. Although a deterministic model, it is calibrated via a stochastic technique called Approximate Bayesian Computation (1, 6) applied to model parameters least known from either the literature or data we have for the Czech Republic epidemic. In this way, we generate a number of posterior parameter sets (or loosely said different hidden worlds) that all more or less result in observations we make on the numbers of confirmed cases in any of the three age cohorts, and ask how in any of these world the observations would look like if our responsive strategies change. Moreover, this technique deals with uncertainty in the model structure; the estimated parameters need not always be biology realistic (even if we try to reflect current knowledge in the respective priors), but if behavior of a strategy relative to the baseline scenario demonstrates consistent behavior across different worlds, we may have an increased confidence in the actual effect, since even if worlds are different they demonstrate similar relative impacts.
Why do we apply our model just to Czechia and not to a wider set of countries? There are several reasons for that. First, the adopted detail of our model requires that: we do not have sufficient data for other countries (such as sociological data on behavior during epidemics, moving patterns of population). But also, other countries generally differ in a number of things, such as school system, community structure, structure of households, health system, testing strategy, etc. Nevertheless, there is no country-specific feature in the model structure, so once properly parameterized it can easily be used to any country affected by COVID-19.
An issue commonly discussed in both country-specific studies (8) and studies spanning more countries (4), is whether to leave schools open or to close them. Closing schools turned to be among the first interventions in many countries (4), presumably because of governmental pandemic plans prepared tailored to influenza. This issue, causing quarrels already 100 years back during the Spanish influenza pandemic, still persists and studies of COVID-19 can also be divided into those that claim relatively small effect (8, 14, 21) and those that rank closing schools among the most important interventions (4, and references therein). We do not follow this line of inquiry, mainly because it makes no sense to single out this specific intervention. Closing school requires parents of small pupils to remain home and thus affects home and work contacts, while large pupils tend to gather in shopping malls and other public places, affecting contacts within a broader community (this is one of the things that may differ among countries). To prevent just this shift of contacts elsewhere one needs to implement broader set of interventions beyond just closing schools, which is exactly what happened in Czechia. Shopping malls were closed shortly after in spring, and open wi-fi signal has been switched there now. Therefore, although schools can be closed in our model without affecting the other types of contact, we examined whether limiting contacts at large was more or less effective than personal protective measures, showing tat the latter is what should always be enforced first. Interestingly, Brauner et al. (4) rank wearing masks among interventions that decreased reproductive number relatively less than closing schools and businesses. Brauner et al. (4) claimed that a probable reason for this conclusion was that wearing face masks was among the last interventions implemented during lockdown in many countries, including Czechia (interestingly, many other countries enforced wearing face masks just following Czechia, seeing that it apparently works, which after some time admitted also WHO). We showed that implementing wearing face masks, together with other protective measures, among the earliest interventions would prevent many from containing infection during the spring first wave. On the contrary, the prospective study of Ferguson et al. (11) is more in line with our findings: although not fitted to any time series data, the authors find much less pronounced effect of closing schools than of implementing social distancing measures.
Western civilization appears to be not much obedient in adherence to guidelines. An indirect indication of this is a much severe second wave in Europe compared to many South-Asian countries, even those with democratic governments. Any kind of lockdown is always a displeasing state that clashes with our perception of freedom. However, the lockdown is usually the last attempt to get an epidemic under control, and it turns out that is in not often necessary if we effectively adhere to less severe restrictions that usually come first. We suggest that a combination of timely application of protective measures and somewhat limited contacts, effective testing and contact tracing, possibly couples with local lockdowns, is apparently an optimal strategy. This may sound trivial. Mathematical models are needed to say how much is not enough, but also how much is probably unnecessarily much.
Methods
Here we provide a description of our mathematical model, structured by age, type of contact and space. The model consists of four layers: a core epidemic layer, observation layer, quarantine layer, and hospital layer. Although we do not report results regarding hospitals and deaths in this study, due to low number of affected people during the first epidemic wave, for completeness we give description of the hospital layer here. We first describe unstructured versions of all layers. Their extensions to age, various types of contact, and space then follow.
Epidemic layer
Our core epidemic model is a variant of the classic SEIR model. Due to contacts with infectious individuals, susceptible individuals (S) may become exposed (E), that is, infected but not yet infectious (the process of infection transmission is described below). The exposed individuals then become asymptomatic for the whole course of infection (In, with probability 1 − pS) or presymptomatic for just a short period of time before becoming symptomatic (Ia, with probability pS). The Ia individuals later become symptomatic, reducing their contacts with others by the factor rC. We assume that a proportion pT of individuals that become symptomatic decide to undergo testing for the presence of SARS-CoV-2 (Is). They either contact their general practitioner and are sent for testing or go and pay by themselves. On the contrary, the proportion 1 − pT of symptomatic individuals (most likely those with very mild symptoms) decide not to undergo testing and rather stay at home (Ih). The In, Is and Ih individuals then recover (R). Since in the Czech Republic, deaths attributed to COVID-19 did not generally occur outside hospitals, we do not consider deaths in the core epidemic layer, but only in the hospital layer described below. Deaths outside hospitals were an important issue in countries heavily hit by the COVID-19 spring wave where hospital capacities were soon depleted.
Considering discrete time, with one time step corresponding to one day, our core epidemic model consists of the system of six equations:
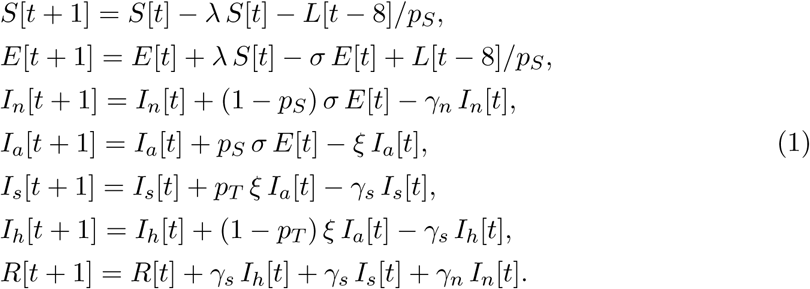 The hitherto unexplained variable L[t] accounts for the imported COVID-19 cases from abroad, mostly from Italy and Austria. A list of all confirmed (symptomatic) imported cases is available at onemocneni-aktualne.mzcr.cz/covid-19. However, we do not introduce such imported cases as symptomatic. We assume they came earlier as exposed, and introduce them before they were actually tested positive (to account for delay between exposition and confirmation). Moreover, to account for the likely situation that some of the imported cases remained undetected as being asymptomatic for the whole course of infection, we divide the number of known imported cased by pS, the probability of exposed individuals eventually becoming symptomatic.
The hitherto unexplained variable L[t] accounts for the imported COVID-19 cases from abroad, mostly from Italy and Austria. A list of all confirmed (symptomatic) imported cases is available at onemocneni-aktualne.mzcr.cz/covid-19. However, we do not introduce such imported cases as symptomatic. We assume they came earlier as exposed, and introduce them before they were actually tested positive (to account for delay between exposition and confirmation). Moreover, to account for the likely situation that some of the imported cases remained undetected as being asymptomatic for the whole course of infection, we divide the number of known imported cased by pS, the probability of exposed individuals eventually becoming symptomatic.
The force of infection λ in the model (1) sums contributions from all infectious classes, that is, In, Ia, Is, and Ih:
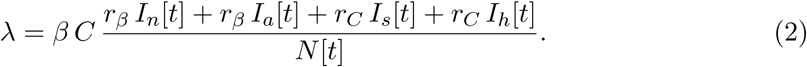 Here, β is the probability of infection transmission upon contact between susceptible and infectious individuals, C is the contact rate (the mean number of other individuals an individual has an effective contact with per day), rβ is a factor reducing the infection transmission probability for an asymptomatic individual relative to a symptomatic one, rC is a factor reducing the contact rate of a symptomatic individual relative to an asymptomatic one (having symptoms should force an individual to reduce contacts with others), and N [t] is the total population size at time t. The remaining model parameters, σ, ξ, γs and γn, represent probabilities at which individuals leave the respective model classes. They are related to the mean duration an individual spends in each such class (Table 7), which in turn is defined and set in Table 6. All model variables are summarized in Table 5. We emphasize here that the calculation of λ will change (be expanded) further in the text, as we extend our model description.
Here, β is the probability of infection transmission upon contact between susceptible and infectious individuals, C is the contact rate (the mean number of other individuals an individual has an effective contact with per day), rβ is a factor reducing the infection transmission probability for an asymptomatic individual relative to a symptomatic one, rC is a factor reducing the contact rate of a symptomatic individual relative to an asymptomatic one (having symptoms should force an individual to reduce contacts with others), and N [t] is the total population size at time t. The remaining model parameters, σ, ξ, γs and γn, represent probabilities at which individuals leave the respective model classes. They are related to the mean duration an individual spends in each such class (Table 7), which in turn is defined and set in Table 6. All model variables are summarized in Table 5. We emphasize here that the calculation of λ will change (be expanded) further in the text, as we extend our model description.
Observation layer
We assume that the period from the onset of symptoms, through sampling and subsequent processing, up to infection confirmation and case isolation is assumed to take dT days (testing delay). The length of this period was found to decrease during the course of epidemic as all involved steps were performed more efficiently. The infectious individuals are assumed always tested positive (we do not assume false negatives). We thus have equation for Is redefined as:
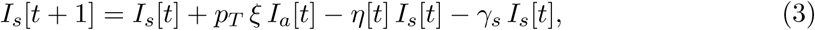 where η = 1 − exp(−1/dT) is the testing rate.
where η = 1 − exp(−1/dT) is the testing rate.
The number of newly positively tested symptomatic individuals at day t thus equals η[t] Is[t]. Therefore, the total number of positively tested symptomatic individuals yet to be reported (B) is
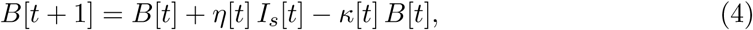 where κ is a (also possibly time-varying) publication rate. This rate is calculated as κ = 1− exp(−1/dP), where dP is the period from case confirmation to case reporting (publication delay). The total number of reported positively tested symptomatic individuals (K) is therefore
where κ is a (also possibly time-varying) publication rate. This rate is calculated as κ = 1− exp(−1/dP), where dP is the period from case confirmation to case reporting (publication delay). The total number of reported positively tested symptomatic individuals (K) is therefore
 This simple testing procedure, assuming that all symptomatic individuals are at any time t tested and reported at the same rate, links the real number of symptomatic individuals to the number of reported positively tested symptomatic individuals, and requires two (possibly time-varying) parameters dT and dP (Table 2).
This simple testing procedure, assuming that all symptomatic individuals are at any time t tested and reported at the same rate, links the real number of symptomatic individuals to the number of reported positively tested symptomatic individuals, and requires two (possibly time-varying) parameters dT and dP (Table 2).
Parameters for the testing layer. These numbers are based on data provided by The Institute of Health Information and Statistics of the Czech Republic (“IHIS CR”); www.uzis.cz; mean values in days are provided over the period from March 1, 2020 to May 7, 2020, for dP, and separately for March and April/May for dT.
Hospital layer
A proportion pH of positively tested individuals (those with relatively severe symptoms) needs hospitalization. The remaining proportion 1 − pH of positively tested individuals (those that have only mild symptoms) are sent home to stay isolated (Iz) until recovery. Hence, we add a new equation
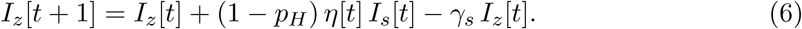 A scheme showing structure of the model involving all elements defined up to now is sketched in Fig. 10.
A scheme showing structure of the model involving all elements defined up to now is sketched in Fig. 10.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
A scheme showing structure of the epidemic and testing model layers. The box H representing hospitalized individuals is elaborated in this section.
Hospitalized individuals may follow several pathways, depending on the number of hospital states one considers. Whereas most published models have not consider a class of hospitalized individuals (15), the others considered one to three hospital states: one to cover all hospitalized individuals (12), two to distinguish between common hospital beds and ICUs (10), and three to further detach ICU patients that need lung ventilators or ECMOs (23).
We consider one hospital state, for which we need to introduce three parameters: the proportion pD of hospitalized individuals that eventually die, mean duration from hospital admission to death dHD, and mean duration from hospital admission to recovery dHR (Table 3). We thus introduce two hospital classes, HD and HR, representing the hospitalized individuals that eventually die or recover, respectively, and compose the following dynamic equations for these two hospital classes:
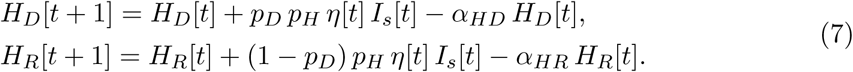 Here αHX = 1 − exp(−1/dHX) for X = D, R. Also, we need to introduce an equation for dead individuals and modify the equation for those that recover:
Here αHX = 1 − exp(−1/dHX) for X = D, R. Also, we need to introduce an equation for dead individuals and modify the equation for those that recover:
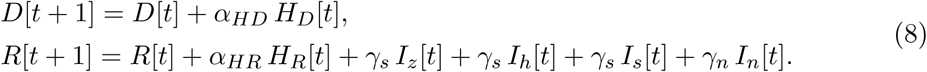 The force of infection λ for the S individuals (2),
The force of infection λ for the S individuals (2),
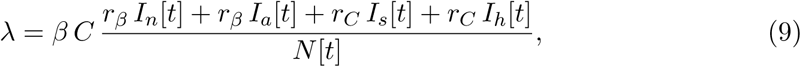 now needs another modification: N [t] in its denominator is now the total population size at time t except those individuals that have already died (D), are isolated at home (Iz), or are hospitalized (HD and HR). These four classes are expected not to transmit infection to others.
now needs another modification: N [t] in its denominator is now the total population size at time t except those individuals that have already died (D), are isolated at home (Iz), or are hospitalized (HD and HR). These four classes are expected not to transmit infection to others.
Parameters for the hospital layer. These numbers are based on data provided by The Institute of Health Information and Statistics of the Czech Republic (“IHIS CR”); www.uzis.cz/index-en.php; mean values are provided over the period from March 1, 2020 to May 7, 2020.
Quarantine layer
Quarantine is ordered to anyone that has been traced as having a recent (epidemiologically relevant) contact with a positively tested individual. At time t, there is η[t] Is[t] positively tested individuals. We assume it takes dI days from identifying an infectious individual to quarantining her or his contacts (quarantine delay; dI = 0 means all traced contacts are quarantined on the same day an individual is positively tested for SARS-CoV-2). So, to find the number of contacts traced and quarantined at time t we need to start with individuals that were tested positively at time t − dI, which is η[t − dI] Is[t − dI].
We assume that dB + 1 is the number of days we look back for the contacts of a positively tested individual. On any single day from t − dI to t − dI − dB, there is C actual contacts with others. We assume that a proportion Φ of the actual contacts are successfully traced (successful tracing ratio; Φ = 1 means all recent contacts are traced). Therefore, there is overall η[t − dI] Is[t − dI]Φ C traced contacts of individuals positively tested at time t − dI with the other individuals in the population. This number of contacts is further reduced by the factor rC for the days the positively tested individuals have been symptomatic.
Due to quarantine delay, an epidemiological status of a contact of a positively tested individual may change between the moments of contact and quarantine. We assume that the successfully traced contacts are only from the classes S, E, Ia, In, Ih and R, and are initially proportionally distributed among these, with the class Ih however weighted by rC (mobility reduction due to presence of symptoms). The resulting initial numbers of traced individuals are denoted as 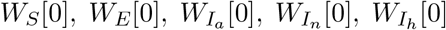 and WR[0]. We follow the epidemiological status of any such individual in time. In particular, any of the S individuals selected as contacts becomes infected during the contact with a positively tested individual with probability β when the latter is symptomatic and with probability rβ β when it is asymptomatic. All traced individuals actually undergo a short separate epidemic that runs for dI + w time steps, where w goes from 0 to dB, with infection transmission applicable only in the first time step:
and WR[0]. We follow the epidemiological status of any such individual in time. In particular, any of the S individuals selected as contacts becomes infected during the contact with a positively tested individual with probability β when the latter is symptomatic and with probability rβ β when it is asymptomatic. All traced individuals actually undergo a short separate epidemic that runs for dI + w time steps, where w goes from 0 to dB, with infection transmission applicable only in the first time step:
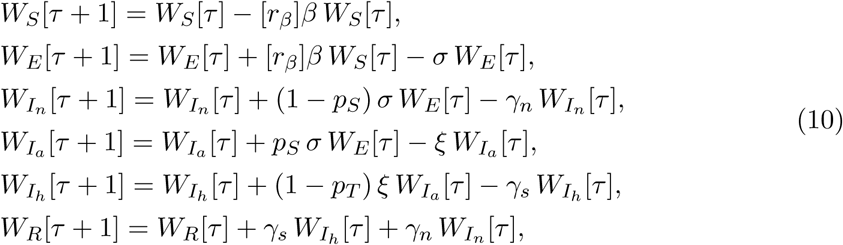 where we use the time index τ instead of t not to mix it with the main system of equations.
where we use the time index τ instead of t not to mix it with the main system of equations.
Thus calculated numbers of individuals 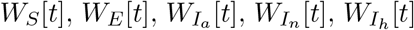 then go to the respective classes
then go to the respective classes 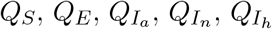 , respectively.
, respectively.
Consideration of the quarantine layer requires modification of the force of infection. The eventual form thus is:
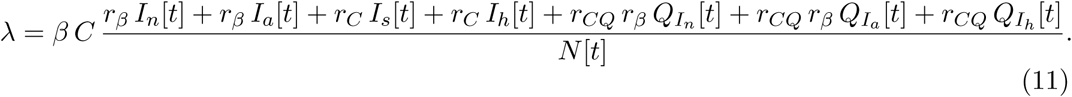 Moreover, the quarantined exposed individuals QE become QIn when asymptomatic for the whole course of infection or
Moreover, the quarantined exposed individuals QE become QIn when asymptomatic for the whole course of infection or 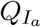 when eventually symptomatic. The
when eventually symptomatic. The 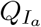 then either go to Is with probability pT or to
then either go to Is with probability pT or to 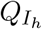 with probability 1 − pT. The force of infection by quarantined individuals is reduced by a factor rCQ (due to a reduction in their contact rate).
with probability 1 − pT. The force of infection by quarantined individuals is reduced by a factor rCQ (due to a reduction in their contact rate).
Denoting by α the rate at which individuals sent to quarantine as S (hence to class QS) return to the class S if not infected in the meantime (in which case they would go to QE), the equations related to quarantine or containing a quarantine class eventually are:
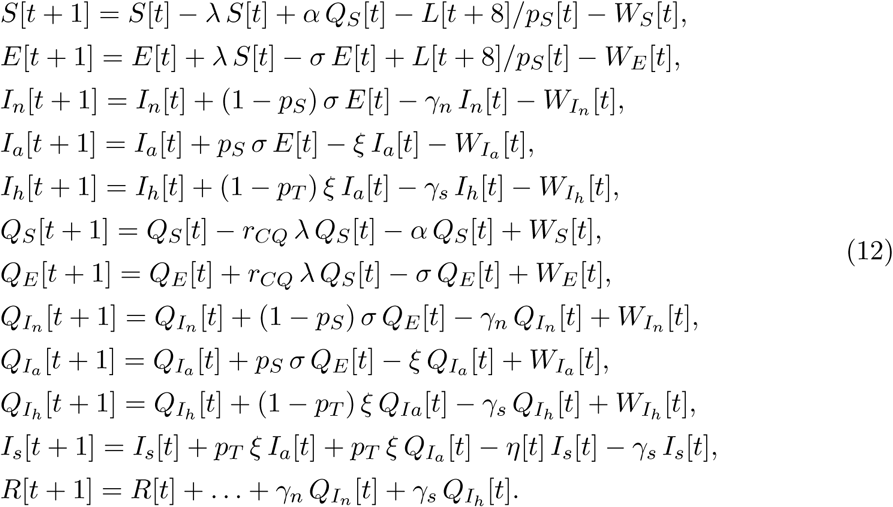
Age structure
As SARS-CoV-2 is known to differently impact children, adults and seniors (8), we distinguish three major age classes: 0-19 years (children), 20-64 years (adults), and 65+ years (seniors). These classes interact via the force of infection: infectious individuals of any age classes contribute to the force of infection of a susceptible individual of any age class. Both the probability of infection transmission upon contact β and daily number of contacts C are thus now 3 × 3 matrices, referred to below as the transmission matrix and contact matrix, respectively.
To account for this differential impact, we assume that the elements of the transmission matrix are not identical yet rather β has the following structure:
 where β1 is a transmission probability between two children, β2 is a transmission probability between children and adults or seniors, β3 is a transmission probability between two adults, β4 is a transmission probability between seniors and adults, and β5 is a transmission probability between seniors. We estimate parameters β1, β2, β3, β4, and β5 by fitting our model to age-specific data on the cumulative number of confirmed cases (see below). In addition to modeling age-specificity of COVID-19, having β as a 3 × 3 matrix allows for considering interventions that may impact various of its elements differently.
where β1 is a transmission probability between two children, β2 is a transmission probability between children and adults or seniors, β3 is a transmission probability between two adults, β4 is a transmission probability between seniors and adults, and β5 is a transmission probability between seniors. We estimate parameters β1, β2, β3, β4, and β5 by fitting our model to age-specific data on the cumulative number of confirmed cases (see below). In addition to modeling age-specificity of COVID-19, having β as a 3 × 3 matrix allows for considering interventions that may impact various of its elements differently.
The contact matrix C describes the mean number of other individuals of any age cohort that an individual of an age cohort meets per day. Prem et al. (20) published such a contact matrix for 152 countries, including the Czech Republic. Moreover, they expressed it as a sum of four specific contact matrices describing daily numbers of contacts at home (CH), school (CS), work (CW), and of other types of contact (CO):
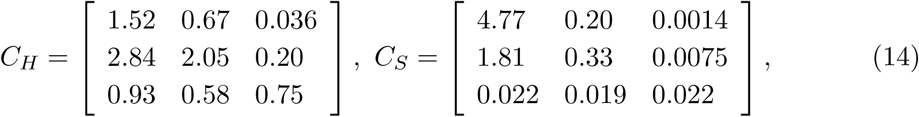
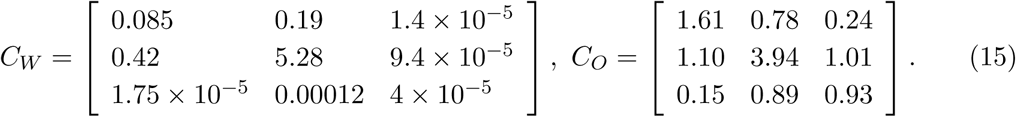 In these matrices, columns represent those that find, while rows those that are contacted. We exploit this division when defining and exploring impacts of various realistic intervention strategies.
In these matrices, columns represent those that find, while rows those that are contacted. We exploit this division when defining and exploring impacts of various realistic intervention strategies.
Once infected, individuals of each age cohort proceed independently of individuals of other age cohorts (except quarantine, where we trace contacts to a positively tested individual that are from any age cohort). Also, we formally treat most model parameters as age-specific, with the same value for each age cohort if age-specific information is not available. Finally, since we know age of any imported COVID-19 case in the initial phase of epidemic, we assign each such case to the appropriate age cohort.
Spatial structure
Spreading of any pathogen in a population, including current epidemic of SARS-CoV-2, has a spatial component. To explore this process, we split the Czech Republic geographically into well-defined 206 counties. For each county, the population size and its distribution into the above-defined three age classes is known (Czech Statistical Office, www.czso.cz/csu/czso/home). Moreover, we compose and use a 206 × 206 mobility matrix that gives mean daily mobility patterns of individuals between all pairs of those counties (proportions of individuals travelling per day from a county to another).
Only individuals from the classes S, E, Ia, In, and R are allowed to travel in our model, unless interventions are implemented to restrict their movement, too (see the section on interventions below). At each time step (one day), our age-structured model is first run (independently) in each county, and then the mobility matrix is applied to the updated county populations. Regarding the imported cases in the initial phase of epidemic, we have information about the broader region in the Czech Republic each case comes from, so we assign a random county from the corresponding region to each such case.
The mobility matrix was constructed by averaging mobility patterns obtained from a telecommunication company across two weeks. Two such matrices were used, one representing the normal state using data from January 2020, and the other representing the lockdown state using data from the second half of March 2020. Both matrices were re-calculated to account for the company’s market share. Furthermore, movement matrices were adjusted to account for average visiting time of 6 hours, i.e. all movement intensities were divided by 4. Due to the lack of age-specific data, these matrices were assumed identical for all three age classes.
Sociological data
Several scenarios for intervention implementation and relaxation are tested for their effect on the course of epidemic in the Czech Republic. Our baseline scenario considers all interventions that were in effect during lockdown established during March 2020 (Table 1). In modeling the various interventions, we exploit a division of the contact matrix C into four matrices describing contacts at home (CH), school (CS), work (CW), and other types of contacts (CO). Starting from the appropriate dates listed in Table 1, we multiply the respective matrices by factors 0.44 for home, 0.45 for work, 0.03 for schools, and 0.35 for other types of contact. Moreover, personal protection, activated on 19 March 2020, including wide use of disinfection, wearing face masks on public, and keeping inter-individual distances of more than 2 metres on public, was modeled so that all elements of the transmission matrix β were reduced by a given factor, corresponding to 88% efficiency (averaging masks and hygiene and computing mean over the high efficiency data). All these numbers are based on results of public opinion polls organized by two agencies during lockdown: the PAQ Reseach agency (www.paqresearch.cz) and the Median agency (www.median.eu). Results of these polls, summarized to our modeling purposes, are provided in Fig. 1. These data show that during the second half of March and essentially the whole April, contacts of all kinds have been largely reduced while personal protection increased.
Model calibration
Values of several model parameters will always remain uncertain, of which the transmission matrix β is commonly the principal of those. This and some other model parameters, listed in Table 4, are estimated by fitting the variable K (representing the cumulative number of confirmed cases in any age class and county), summed over counties but not age, to the age-specific time series on the reported cumulative numbers of confirmed cases in the Czech Republic.
List of parameters that are estimated by the ABC model calibration procedure, including the corresponding prior distributions.
List of state and tracing variables used in the model.
List of epidemiological parameters.
List of model parameters.
There are many ways to meaningfully perform model calibration on real-world data and many optimization and filtering methods exist (24). We use the Approximate Bayesian Computation (ABC), a technique used to estimate parameters of complex Markov models in genomics and other biological disciplines (1, 6), including epidemic modeling (2, 17). The major advantage of this method is that it naturally works with all sources of uncertainty acknowledged in the model. At the same time, ABC does not rely of likelihood calculations and in case of sufficient computation power it can be used with models of virtually any complexity. The ABC procedure with rejection sampling we used here consisted of three steps. First, we used our model to simulate summary statistics for calibration (number of detected cases in age categories, state variable K) N times (100,000), drawing the uncertain model parameters from prior distributions based on literature (see above); selected prior distributions for estimated parameters are also given in Table 4. Second, we compared the simulated summary statistics with the observed one, using the Euclidean distance D. Third, we selected model simulations that satisfy D < E, where E was chosen to pass 0.05% of simulations into the selected set. Given the used summary statistics are informative, the distribution of parameter used for such selected simulations is known to converge from outside to the Bayesian posterior distribution of parameter values with E going to 0, and is referred to as approximate posterior (1). The choice of E and N in ABC is driven by compromise between computation power, smoothness and accuracy of approximate posterior.
The set of accepted sets of parameters thus allows us to evaluate remaining parameter uncertainty, given the available data and adopted summary statistics (1, 6). This is crucial to realize, since although different parameter sets may similarly fit the available data (have similar summary statistics), and often provide similar short-term predictions, they may demonstrate significant differences in longer-term predictions and in the interplay with intervention policies. To accommodate this uncertainty, we do not evaluate only an absolute impact of implementation or relaxation of an intervention. We also present its impact relative to the baseline (here the actually adopted full lockdown) scenario. If such a relative impact is consistent over whole posterior distribution of parameters, we may have confidence in its potential effect. To apply the ABC technique, we use the abc package in R (7), modified to work with non-normalized summary statistics.
Determination of prior distributions for some parameters from literature
The prior distribution for the latent period (dE) was set as normal with mean 5.08 days and standard deviation 0.5 days, based on He et al. (13). The duration of the infectious period before the onset of symptoms was reported in the literature as ranging from 1-3 days (22). The mean duration of test positivity for viral RNA (a proxy for infectiousness) was reported in the literature as 25.2 days for symptomatic patients (dS) and and 22.6 days for asymptomatic patients (dN) (18).
The prior probability of factor reducing the infection transmission in a/presymptomatic individuals (rβ) was set as uniform distribution from 0.4 to 1, respecting a number of studies. In particular, He et al. (13) re-analyzed results previously published in local Chinese journals to show a somewhat higher probability of virus transmission in symptomatic individuals (the asymptomatic infection rate to be 46% of the symptomatic one, with the 95% CI (18.48%-73.60%)), but the source of primary data could not be verified. The value of 0.55 was assumed by Domenico et al. (10) in setting up their model, based on Li et al. but for “undocumented” rather than “asymptomatic” patients. On the other hand, Chen et al. (5) showed no statistically significant difference in the transmissibility of the virus between symptomatic and a/presymptomatic cases.
The percentage of asymptomatic individuals out of those positively tested for COVID-19 (pS) has been estimated by a number of studies and the estimates vary significantly as does the quality of the evidence. The range of the percentage of the asymptomatic individuals among those positively tested reported is 4.4-89%. As a result, we use the uniform distribution on the whole interval 0-100% as a prior.
Data Availability
Data used in the manuscript were either taken from the letarture or provided by state institutions of the Czech Republic. In the latter case, they are not publicly avilable, but are acknowledged in the manuscript. The software code used to run the model is available (without publicly unavailable data) on reasonable request.
Acknowledgements
We thank The Institute of Health Information and Statistics of the Czech Republic (IHIS CR; www.uzis.cz) for providing us detailed data on many characteristics of confirmed cases of COVID-19. We also acknowledge the PAQ Reseach agency and in particular Daniel Prokop (www.paqresearch.cz) and the Median agency (www.median.eu) for sharing with us results from their public opinion polls. The mobility data were provided by the project “RODOS Transport Systems Development Centre” which is supported by the Technology Agency of the Czech Republic. VT was supported by the QuantiXLie Center of Excellence, a project cofinanced by the Croatian Government and European Union through the European Regional Development Fund - the Competitiveness and Cohesion Operational Programme (KK.01.1.1.01.0004).
This paper uses data from SHARE Waves 1, 2, 3, 4, 5, 6 and 7 (DOIs: 10.6103/SHARE.w1.700, 10.6103/SHARE.w2.700, 10.6103/SHARE.w3.700, 10.6103/SHARE.w4.700, 10.6103/SHARE.w5.700, 10.6103/SHARE.w6.700, 10.6103/SHARE.w7.700), see Börsch-Supan et al. (3) for method-ological details. The SHARE data collection has been funded by the European Commission through FP5 (QLK6-CT-2001-00360), FP6 (SHARE-I3: RII-CT-2006-062193, COMPARE: CIT5-CT-2005-028857, SHARELIFE: CIT4-CT-2006-028812), FP7 (SHARE-PREP: GA N211909, SHARE-LEAP: GA N227822, SHARE M4: GA N261982) and Horizon 2020 (SHARE-DEV3: GA N676536, SERISS: GA N654221) and by DG Employment, Social Affairs & Inclusion. Additional funding from the German Ministry of Education and Research, the Max Planck Society for the Advancement of Science, the U.S. National Institute on Aging (U01 AG09740-13S2, P01 AG005842, P01 AG08291, P30 AG12815, R21 AG025169, Y1-AG-4553-01, IAG BSR06-11, OGHA 04-064, HHSN271201300071C) and from various national funding sources is gratefully acknowledged (see www.share-project.org). This work was supported by the Ministry of Education, Youth and Sports of the Czech Republic through the project SHARE-CZ+ (CZ.02.1.01/0.0/0.0/16 013/0001740).
References




