
Abstract
Background Standard Mendelian randomization analysis can produce biased results if the genetic variant defining the instrumental variable (IV) is confounded and/or has a horizontal pleiotropic effect on the outcome of interest not mediated by the treatment.
Development We provide novel identification conditions for the causal effect of a treatment in the presence of unmeasured confounding, by leveraging an invalid IV for which both the IV independence and exclusion restriction assumptions may be violated. The proposed Mendelian Randomization Mixed-Scale Treatment Effect Robust Identification (MR MiSTERI) approach relies on (i) an assumption that the treatment effect does not vary with the invalid IV on the additive scale; and (ii) that the selection bias due to confounding does not vary with the invalid IV on the odds ratio scale; and (iii) that the residual variance for the outcome is heteroscedastic and thus varies with the invalid IV. Although assumptions (i) and (ii) have, respectively appeared in the IV literature, assumption (iii) has not; we formally establish that their conjunction can identify a causal effect even with an invalid IV subject to pleiotropy. MR MiSTERI is shown to be particularly advantageous in the presence of pervasive heterogeneity of pleiotropic effects on additive scale, a setting in which two recently proposed robust estimation methods MR GxE and MR GENIUS can be severely biased. For estimation, we propose a simple and consistent three-stage estimator that can be used as preliminary estimator to a carefully constructed one-step-update estimator, which is guaranteed to be more efficient under the assumed model. In order to incorporate multiple, possibly correlated and weak IVs, a common challenge in MR studies, we develop a MAny Weak Invalid Instruments (MR MaWII MiSTERI) approach for strengthened identification and improved accuracy. We have developed an R package MR-MiSTERI for public use of all proposed methods.
Application We illustrate MR MiSTERI in an application using UK Biobank data to evaluate the causal relationship between body mass index and glucose, thus obtaining inferences that are robust to unmeasured confounding, leveraging many weak and potentially invalid candidate genetic IVs.
Conclusion MaWII MiSTERI is shown to be robust to horizontal pleiotropy, violation of IV independence assumption and weak IV bias. Both simulation studies and real data analysis results demonstrate the robustness of the proposed MR MiSTERI methods.
1 Introduction
Mendelian randomization (MR) is an instrumental variable (IV) approach that uses genetic variants, for example, single-nucleotide polymorphisms (SNPs), to infer the causal effect of a modifiable risk treatment on a health outcome (Smith and Ebrahim 2003). MR has recently gained popularity in epidemiological studies because, under certain conditions, it can provide unbiased estimates of causal effects even in the presence of unmeasured exposure-outcome confounding. For example, findings from a recent MR analysis assessing the causal relationship between low-density lipoprotein cholesterol and coronary heart disease (Ference et al. 2017) in an observational study are consistent with the results of earlier randomized clinical trials (Scandinavian Simvastatin Survival Study Group 1994).
For a SNP to be a valid IV, it must satisfy the following three core assumptions (Didelez and Sheehan 2007; Lawlor et al. 2008):
(A1) IV relevance: the SNP must be associated (not necessarily causally) with the exposure;
(A2) IV independence: the SNP must be independent of any unmeasured confounder of the exposure-outcome relationship;
(A3) Exclusion restriction: the SNP cannot have a direct effect on the outcome variable not mediated by the treatment, that is, no horizontal pleiotropic effect can be present.
The causal diagram in Figure 1(a) graphically represents the three core assumptions of a valid IV. It is well-known that even when assumptions (A1)-(A3) hold for a given IV, the average causal effect of the treatment on the outcome cannot be point identified without an additional condition, the nature of which dictates the interpretation of the identified causal effect. Specifically, Angrist et al. (1996) proved that under (A1)-(A3) and a monotonicity assumption about the IV-treatment relationship, the so-called complier average treatment effect is nonparametrically identified. More recently, Wang and Tchetgen Tchetgen (2018) established identification of population average causal effect under (A1)-(A3) and an additional assumption of no unmeasured common effect modifier of the association between the IV and the endogenous variable, and the treatment causal effect on the outcome. A special case of this assumption is that the association between the IV and the treatment variable is constant on the additive scale across values of the unmeasured confounder (Tchetgen Tchetgen et al. (2020)). In a separate strand of work, Robins (1994) identified the effect of treatment on the treated under (A1)-(A3) and a so-called “no current-treatment value interaction” assumption (A.4a) that the effect of treatment on the treated is constant on the additive scale across values of the IV. In contrast, Liu et al. (2020) established identification of the ETT under (A1)-(A3), and an assumption (A.4b) that the selection bias function defined as the odds ratio association between the potential outcome under no treatment and the treatment variable, is constant across values of the IV. Note that under the IV DAG Figure 1(a), assumption (A1) is empirically testable while (A2) and (A3) cannot be refuted empirically without a different assumption being imposed (Glymour et al. 2012). Possible violation or near violation of assumption (A1) known as the weak IV problem poses an important challenge in MR studies as the associations between a single SNP IV and complex traits can be fairly weak (Staiger and Stock 1997; Stock et al. 2002). But massive genotyped datasets have provided many such weak IVs. This has motivated a rich body of work addressing the weak IV problem under a many weak instruments framework, from a generalized method of moments perspective given individual level data (Chao and Swanson 2005; Newey and Windmeijer 2009; Davies et al. 2015), and also from a summary-data perspective (Zhao et al. 2019a,b; Ye et al. 2019). Violation of assumption (A2) can occur due to population stratification, or when selected SNP IV is in linkage disequilibrium (LD) with another genetic variant which has a direct effect on the outcome (Didelez and Sheehan 2007). Violations of (A3) can occur when the chosen SNP IV has a non-null direct effect on the outcome not mediated by the exposure, commonly referred to as horizontal pleiotropy and is found to be widespread (Solovieff et al. 2013; Verbanck et al. 2018). A standard MR analysis (i.e. based on standard IV methods such as 2SLS) with an invalid IV that violates any of those three core assumptions might yield biased causal effect estimates.

Methods to address possible violations of (A2) or (A3) given a single candidate IV are limited. Two methods have recently emerged as potentially robust against such violation under certain conditions. The first, known as MR-GxE, assumes that one has observed an environmental factor, which interacts with the invalid IV in its additive effects on the treatment of interest, and that such interaction is both independent of any unmeasured confounder of the exposure-outcome relationship, and does not operate on the outcome in view (Spiller et al. 2019, 2020). In other words, MR-GxE essentially assumes that while the candidate SNP may not be a valid IV, its additive interaction with an observed covariate constitutes a valid IV which satisfies (A1)-(A3). In contrast, MR GENIUS relies on an assumption that the residual variance of the first stage regression of the treatmenton the candidate IV is heteroscedastic with respect to the candidate IV, i.e. the variance of the treatment depends on the IV, an assumption that may be viewed as strengthening of the IV relevance assumption (Tchetgen Tchetgen et al. 2020). Interestingly, as noted by Tchetgen Tchetgen et al. (2020), existence of a GxE interaction that satisfies conditions (A1)-(A3) required by MR GxE had such an E variable (independent of G) been observed, necessarily implies that the heteroscedasticity condition required by MR GENIUS holds even when the relevant E variable is not directly observed. Furthermore, as it is logically possible for heteroscedasticity of the variance of the treatment to operate even in absence of any GxE interaction, MR GENIUS can be valid in certain settings where MR GxE is not.
In this paper, we develop an alternative robust MR approach to estimating a causal effect of a treatment subject to unmeasured confounding, leveraging a potentially invalid IV which fails to fulfill either IV independence or exclusion restriction assumptions. The proposed “Mendelian Randomization Mixed-Scale Treatment Effect Robust Identification” (MR MiSTERI) approach relies on (i) an assumption that the treatment effect does not vary with the invalid IV on the additive scale; and (ii) that the selection bias due to confounding does not vary with the invalid IV on the odds ratio scale; and (iii) that the residual variance for the outcome is heteroscedastic and thus varies with the invalid IV. Although assumptions (i) and (ii) have, respectively appeared in the IV literature, assumption (iii) has not; we formally establish that their conjunction can identify a causal effect even with an invalid IV subject to pleiotropy. MR MiSTERI is shown to be particularly advantageous in the presence of pervasive heterogeneity of pleiotropic effects on the additive scale, a setting in which both MR GxE and MR GENIUS can be severely biased whenever heteroscedastic first stage residuals can fully be attributed to latent heterogeneity in SNP-treatment association (Spiller et al. 2020). For estimation, we propose a simple and consistent three-stage estimator that can be used as preliminary estimator to a carefully constructed one-step-update estimator, which is guaranteed to be more efficient under the assumed model. In order to incorporate multiple, possibly correlated and weak IVs, a common challenge in MR studies, we develop a MAny Weak Invalid Instruments (MaWII MR MiSTERI) approach for strengthened identification and improved accuracy. Simulation study results show that our proposed MR method give consistent estimates of the causal parameter and the selection bias parameter with nominal confidence interval coverage with an invalid IV, and the accuracy is further improved with multiple weak invalid IVs. For illustration, we apply our method to the UK Biobank data set to estimate the causal effect of body mass index (BMI) on average glucose level.
2 Methods
2.1 Identification with a Binary treatment and a Possibly Invalid Binary IV
Suppose that we observe data Oi = (Zi, Ai, Yi) of size n drawn independently from a common population, where Zi, Ai, Yi denote a SNP IV, a modifiable treatment and a continuous outcome of interest for the ith subject (1 ≤ I ≤ n), respectively. In order to simplify the presentation, we drop the sample index i and do not consider observed covariates at this stage, although all the conclusions continue to hold within strata defined by observed covariates. Let z, a, y denote the possible values that Z, A, Y could take, respectively. Let Yaz denote the potential outcome, had possibly contrary to fact, A and Z been set to a and z respectively, and let Ya denote the potential outcome had A been set to a. We are interested in estimating the ETT defined as
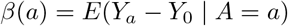 To facilitate the exposition, consider the simple setting where both the treatment and the SNP IV are binary, then the ETT simplifies to β = E(Y1 − Y0 | A = 1). By the consistency assumption, we know that E(Y1 | A = 1) = E(Y | A = 1). However, the expectation of the potential outcome Y0 among the exposed subpopulation E(Y0 | A = 1) cannot empirically be observed due to possible unmeasured confounding for the exposure-outcome relationship. The following difference captures this confounding bias on the additive scale Bias = E(Y0 | A = 1) − E(Y0 | A = 0), which is exactly zero only when exposed and unexposed groups are exchangeable on average (i.e. under no confounding) (Hernan and Robins 2020), and is otherwise not null. With this representation and the consistency assumption, we have
To facilitate the exposition, consider the simple setting where both the treatment and the SNP IV are binary, then the ETT simplifies to β = E(Y1 − Y0 | A = 1). By the consistency assumption, we know that E(Y1 | A = 1) = E(Y | A = 1). However, the expectation of the potential outcome Y0 among the exposed subpopulation E(Y0 | A = 1) cannot empirically be observed due to possible unmeasured confounding for the exposure-outcome relationship. The following difference captures this confounding bias on the additive scale Bias = E(Y0 | A = 1) − E(Y0 | A = 0), which is exactly zero only when exposed and unexposed groups are exchangeable on average (i.e. under no confounding) (Hernan and Robins 2020), and is otherwise not null. With this representation and the consistency assumption, we have
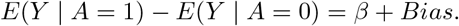 This simple equation implies that one can only estimate the sum of the causal effect β and the confounding bias but cannot tease them apart using the data (A, Y) only. With the availability of a binary candidate SNP IV Z that is possibly invalid, we can further stratify the population by Z to obtain under consistency:
This simple equation implies that one can only estimate the sum of the causal effect β and the confounding bias but cannot tease them apart using the data (A, Y) only. With the availability of a binary candidate SNP IV Z that is possibly invalid, we can further stratify the population by Z to obtain under consistency:
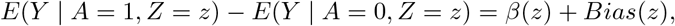 where z is equal to either 0 or 1, and β(z) = E(Ya − Y0 | A = a, Z = z), Bias(z) = E(Y0 | A = 1, Z = z) E(Y0 | A = 0, Z = z) denote the causal effect and bias in the stratified population with the IV taking value z. Note that there are only two equations but four unknown parameters: β(z), Bias(z), z = 0, 1. Therefore, the causal effect cannot be identified without imposing assumptions to reduce the total number of parameters to two.
where z is equal to either 0 or 1, and β(z) = E(Ya − Y0 | A = a, Z = z), Bias(z) = E(Y0 | A = 1, Z = z) E(Y0 | A = 0, Z = z) denote the causal effect and bias in the stratified population with the IV taking value z. Note that there are only two equations but four unknown parameters: β(z), Bias(z), z = 0, 1. Therefore, the causal effect cannot be identified without imposing assumptions to reduce the total number of parameters to two.
Our first assumption extends Robins (1994) no current-treatment value interaction assumption (A.4a), that the causal effect does not vary across the levels of the SNP IV so that β(z) is a constant as function of z. Formally stated:
(B1) Homogeneous ETT assumption: E(Ya=1,z − Ya=0,z | A = 1, Z = z) = β.
It is important to note that this assumption does not imply the exclusion restriction assumption (A3); it is perfectly compatible with presence of a direct effect of Z on Y (the direct arrow from Z to Y is present in Figure 1(b)), i.e. E(Ya=0,z=1 − Ya=0,z=0 | A = 1, Z = z) ≠ 0, which we accommodate.
In order to state our second core assumption, consider the following data generating mechanism for the treatment, which encodes presence of unmeasured confounding by making dependence between A and Y0 explicit under a logistic model:
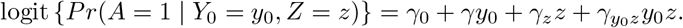 This model can of course not be estimated directly from the observed data without any additional assumption because it would require the potential outcome Y0 be observed both on the untreated (guaranteed by consistency) and the treated. Nevertheless, this model implies that the conditional (on Z) association between A and Y0 on the odds ratio scale is
This model can of course not be estimated directly from the observed data without any additional assumption because it would require the potential outcome Y0 be observed both on the untreated (guaranteed by consistency) and the treated. Nevertheless, this model implies that the conditional (on Z) association between A and Y0 on the odds ratio scale is 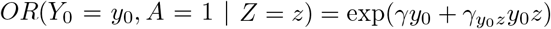 .
.
Together, γ and 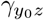 encode the selection bias due to unmeasured confounding on the log-odds ratio scale. If both γ and
encode the selection bias due to unmeasured confounding on the log-odds ratio scale. If both γ and 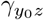 are zeros, then A and Y0 are conditionally (on Z) independent, or equivalently, there is no residual confounding bias upon conditioning on Z. Our second identifying assumption formally encodes assumption A4.b of Liu et al. (2020) of homogeneous odds ratio selection bias
are zeros, then A and Y0 are conditionally (on Z) independent, or equivalently, there is no residual confounding bias upon conditioning on Z. Our second identifying assumption formally encodes assumption A4.b of Liu et al. (2020) of homogeneous odds ratio selection bias 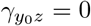 :
:
(B2) Homogeneous selection bias: OR(Y0 = y0, A = a | Z = z) = exp(γay0).
Assumption (B2) states that the selection bias on the odds ratio scale is homogeneous across levels of the IV. Thus, this assumption allows for the presence of unmeasured confounding which, upon setting 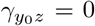 is assumed to be on average balanced with respect to the SNP IV (on the odds ratio scale). Following Liu et al. (2020), we have that under (B2)
is assumed to be on average balanced with respect to the SNP IV (on the odds ratio scale). Following Liu et al. (2020), we have that under (B2)
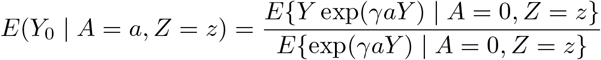 Define ε = Y − E(Y | A, Z), and suppose that ε | A, Z ∼ N (0, σ2(Z)), then after some algebra we have,
Define ε = Y − E(Y | A, Z), and suppose that ε | A, Z ∼ N (0, σ2(Z)), then after some algebra we have,
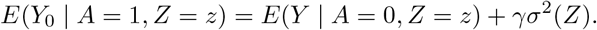 The selection bias on the odds ratio scale does not vary with the levels of the IV, however in order to achieve identification, the bias term γσ2(Z) must depend on the IV. This observation motivates our third assumption,
The selection bias on the odds ratio scale does not vary with the levels of the IV, however in order to achieve identification, the bias term γσ2(Z) must depend on the IV. This observation motivates our third assumption,
(B3) Heteroscedasticity, that is σ2(Z) cannot be a constant.
Assumption (B3) is empirically testable using existing statistical methods for detecting non-constant variance in regression models. For example, the Levene test has been used in genetic association studies and found several SNPs associated with the variance of several phenotypes. The well-known FTO variant (rs7202116) was found to be associated with the phenotypic variability of body mass index (BMI) (P=2.4E-10; N=131233) by using a two-stage procedure (Yang et al. 2012). They first regress BMI on the SNP genotype, then regress the squared residuals on the SNP genotype again to test for association of the SNP with the variance of BMI. Previous large-scale genetic association studies show that our assumption (B3) is scientifically plausible. Furthermore, one can generally expect the assumption to hold in presence of pervasive heterogeneity of pleiotropic effects on additive scale for the outcome, a setting in which both MR GxE and MR GENIUS can be severely biased. Under assumptions (B1)-(B3), we have
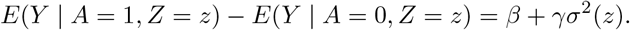 Note that σ2(z) is the variance of Y given z, and thus can be estimated with no bias. For the binary IV Z, σ2(Z = 0) and σ2(Z = 1) are the variance of Y within each IV stratum and can easily be estimated using the sample variance in each group. We will describe estimating procedures in the next section for more general settings where Z is not necessarily binary. Importantly, in the present case, we now have two equations and two unknown parameters β, γ.
Note that σ2(z) is the variance of Y given z, and thus can be estimated with no bias. For the binary IV Z, σ2(Z = 0) and σ2(Z = 1) are the variance of Y within each IV stratum and can easily be estimated using the sample variance in each group. We will describe estimating procedures in the next section for more general settings where Z is not necessarily binary. Importantly, in the present case, we now have two equations and two unknown parameters β, γ.
Denote D(Z = z) = E(Y | A = 1, Z = z) − E(Y | A = 0, Z = z). Therefore we have the following main identification result.
Under assumptions (B1)-(B3), the selection bias parameter and the causal effect of interest are uniquely identified as follows:
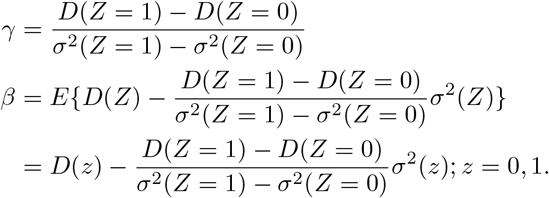
In an observed sample, one can simply use the sample versions of unknown quantities to obtain estimates for β and γ. Standard errors can be deduced by a standard application of the multivariate delta method, or by using resampling techniques such as the jacknife or the bootstrap.
Note that as stated in the theorem, the causal parameter β can be estimated based on data among either Z = 0 or Z = 1 group. In practical settings, in order to improve efficiency, one may take either unweighted average of the two estimates as given in the theorem, or their inverse variance weighted average. In fact, one may fit a saturated linear model for the variance σ2(Z = z) = b0 + bz; We give a graphical illustration of our identification condition as shown in Figure 2. By using the heteroscedasticity assumption (B3), we can identify the selection bias parameter γ and then the causal effect parameter β. Without the assumption (B3) as shown by the red dashed line, we can only obtain β + γb0 and thus cannot tease apart the causal effect and the selection bias.

2.2 Identification with a Continuous treatment and a Possibly Invalid Discrete IV
The identification strategy in the previous section extends to the more general setting of continuous treatment and a more general discrete IV, for example, the SNP IV taking values 0, 1, 2 corresponding to the number of minor alleles. To do so requires we introduce the notion of generalized conditional odds ratio function as a measure of the conditional association between a continuous treatment and a continuous outcome. To ground idea, consider the following model for the treatment free potential outcome:
 where ϵ is independent standard normal; then one can show that the generalized conditional odds ratio function associated with Y0 and A given Z with (Y0 = 0, A = 0) taken as reference values Chen (2007) is given by
where ϵ is independent standard normal; then one can show that the generalized conditional odds ratio function associated with Y0 and A given Z with (Y0 = 0, A = 0) taken as reference values Chen (2007) is given by
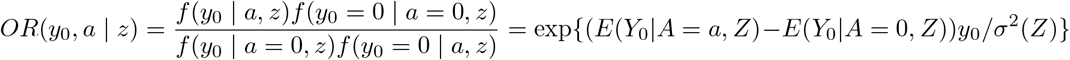 which by Assumption (B2) implies that E(Y0|A, Z) − E(Y0|A = 0, Z) = γσ2(Z)A. We therefore have
which by Assumption (B2) implies that E(Y0|A, Z) − E(Y0|A = 0, Z) = γσ2(Z)A. We therefore have
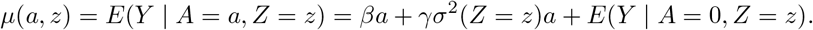 For practical interpretation, we assume A has been centered so that A = 0 actually represents average treatment value in the study population. Assume the following model E(Y | A = 0, Z = z) = θ0 + θzz and a log linear model for σ2(Z) such that
For practical interpretation, we assume A has been centered so that A = 0 actually represents average treatment value in the study population. Assume the following model E(Y | A = 0, Z = z) = θ0 + θzz and a log linear model for σ2(Z) such that
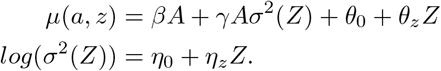 The conditional distribution of Y given A and Z is
The conditional distribution of Y given A and Z is
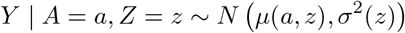 Then we can simply use standard maximum likelihood estimation (MLE) to obtain consistent and fully efficient estimates for all parameters under the assumed model. However, the likelihood may not be log-concave and direct maximization of the likelihood function with respect to all parameters might not always converge. Instead, we propose a novel three-stage estimation procedure which can provide a consistent but inefficient preliminary estimator of unknown parameters. We then propose a carefully constructed one-step update estimator to obtain a consistent and fully efficient estimator. Our three-stage estimation method works as follows.
Then we can simply use standard maximum likelihood estimation (MLE) to obtain consistent and fully efficient estimates for all parameters under the assumed model. However, the likelihood may not be log-concave and direct maximization of the likelihood function with respect to all parameters might not always converge. Instead, we propose a novel three-stage estimation procedure which can provide a consistent but inefficient preliminary estimator of unknown parameters. We then propose a carefully constructed one-step update estimator to obtain a consistent and fully efficient estimator. Our three-stage estimation method works as follows.
Stage 1 Fit the following linear regression using standard (weighted) least-squares
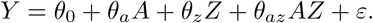 We obtain parameter estimates
We obtain parameter estimates 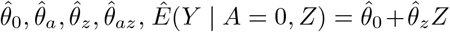 , with corresponding estimated residuals
, with corresponding estimated residuals 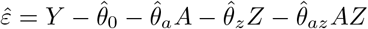 .
.
Stage 2 Regress the squared residuals 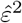 on (1, Z) in a log-linear model and obtain parameter estimates
on (1, Z) in a log-linear model and obtain parameter estimates 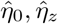 and
and 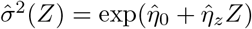 .
.
Stage 3 Regress Y − Ê(Y | A = 0, Z) on A and 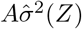 without an intercept term and obtain the two corresponding regression coefficients estimates
without an intercept term and obtain the two corresponding regression coefficients estimates 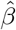 and
and 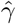 respectively.
respectively.
Alternatively, we may also fit 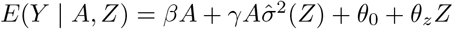 in Stage 3.
in Stage 3.
The proposed three-stage estimation procedure is computationally convenient, appears to always converge and provides a consistent estimator for all parameters under the assumed model. Next we propose the following one-step update to obtain a fully efficient estimator. Consider the following normal model
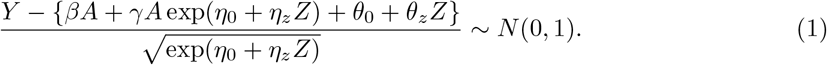 Denote Θ = (β, γ, η0, ηz, θ0, θz) and denote the log-likelihood function as l(Θ; Y, A, Z) for an individual. With a sample of size n, the log-likelihood function is
Denote Θ = (β, γ, η0, ηz, θ0, θz) and denote the log-likelihood function as l(Θ; Y, A, Z) for an individual. With a sample of size n, the log-likelihood function is
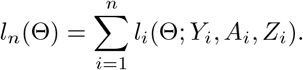 The score function Sn(Θ) = ∂ln(Θ)/∂Θ is defined as the first order derivative of the log-likelihood function with respect to Θ, and use in(Θ) = ∂2ln(Θ)/∂Θ∂ΘT to denote the second order derivative of the log-likelihood function. Suppose we have obtained a consistent estimator
The score function Sn(Θ) = ∂ln(Θ)/∂Θ is defined as the first order derivative of the log-likelihood function with respect to Θ, and use in(Θ) = ∂2ln(Θ)/∂Θ∂ΘT to denote the second order derivative of the log-likelihood function. Suppose we have obtained a consistent estimator 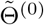 of Θ using the three-stage estimating procedure, then one can show that a consistent and fully efficient estimator is given by the one-step update estimator
of Θ using the three-stage estimating procedure, then one can show that a consistent and fully efficient estimator is given by the one-step update estimator 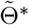

In biomedical studies, continuous outcomes of interest are often approximately normally distributed, and the normal linear regression is also routinely used by applied researchers. When the normal assumption is violated, a typical remedy is to apply a transformation to the outcome prior to modeling it, such as the log-transformation or the more general Box-Cox transformation to achieve approximate normality. Alternatively, below we propose to model the error distribution as a more flexible Gaussian mixture model which is more robust than the Gaussian model. Alternatively, as described in the Supplemental materials, one may consider a semiparametric location-scale model which allows the distribution of standardized residuals to remain unrestricted, a potential more robust approach although computationally more demanding.
2.3 Estimation and Inference under Many Weak Invalid IVs
Weak identification bias is a salient issue that needs special attention when using genetic data to strengthen causal inference, as most genetic variants are only weakly associated with the traits.
When many genetic variants are available, we recommend using the conditional maximum likelihood estimator (CMLE) based on (1), where Z is replaced with a multi-dimensional vector. Let 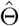 be the solution to the corresponding score functions, i.e.,
be the solution to the corresponding score functions, i.e.,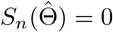 ; let
; let
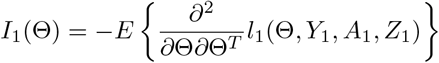 be the Fisher information matrix based on the conditional likelihood function for one observation. Let k be the total number of parameters in Θ, which is equal to 4 + 2p when Z is p dimensional. When λmin {nI1(Θ)}/k→∞ with {λmin nI1(Θ)} being the minimum eigenvalue of nI1(Θ), we show in the supplementary materials (Theorem 3) that
be the Fisher information matrix based on the conditional likelihood function for one observation. Let k be the total number of parameters in Θ, which is equal to 4 + 2p when Z is p dimensional. When λmin {nI1(Θ)}/k→∞ with {λmin nI1(Θ)} being the minimum eigenvalue of nI1(Θ), we show in the supplementary materials (Theorem 3) that 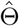 is consistent and asymptotically normal as the sample size goes to infinity, and satisfies
is consistent and asymptotically normal as the sample size goes to infinity, and satisfies
 In other words, the CMLE is robust to weak identification bias and the usual inference procedure can be directly applied.
In other words, the CMLE is robust to weak identification bias and the usual inference procedure can be directly applied.
The key condition λmin{nI1(Θ)}/k → ∞ warrants more discussion. Note that the quantity λmin nI1(Θ) /k measures the ratio between the amount of information that a sample of size n carries about the unknown parameter and the number of parameters. In classic strong identification scenarios where the minimum eigenvalue of I1(Θ) is assumed to be lower bounded by a constant, then the condition simplifies to that the number of parameter is small compared with the sample size, i.e., n/k → ∞. However, when identification is weak, the minimum eigenvalue of I1(Θ) can be small. In practice, the condition λmin nI1(Θ) /k can be evaluated by 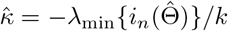 , which is the ratio between the minimum eigenvalue of the negative Hessian matrix and the number of parameters. We remark that the condition stated in the supplementary materials (Theorem 3) is more general and applies to general likelihood-based methods, which, for example, implies the condition for consistency for the profile likelihood estimator (MR.raps) in Zhao et al. (2019b).
, which is the ratio between the minimum eigenvalue of the negative Hessian matrix and the number of parameters. We remark that the condition stated in the supplementary materials (Theorem 3) is more general and applies to general likelihood-based methods, which, for example, implies the condition for consistency for the profile likelihood estimator (MR.raps) in Zhao et al. (2019b).
For valid statistical inference, a consistent estimator for the variance covariance matrix for 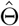 is simply the negative Hessian matrix
is simply the negative Hessian matrix 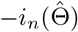 , whose corresponding diagonal element estimates the variance of the treatment effect estimator
, whose corresponding diagonal element estimates the variance of the treatment effect estimator 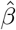 . Other variants of the CMLE can also be used, for example, the one-step iteration estimator
. Other variants of the CMLE can also be used, for example, the one-step iteration estimator 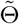 in (2) is asymptotically equivalent to the CMLE
in (2) is asymptotically equivalent to the CMLE 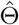 as long as the initial estimator
as long as the initial estimator 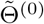 is
is 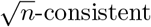 (Shao 2003).
(Shao 2003).
2.4 Gaussian mixture model
Consider the general location-scale model
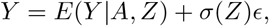 where ϵ ⊥ A, Z. Under assumptions (B1)-(B3), the conditional mean function is given by
where ϵ ⊥ A, Z. Under assumptions (B1)-(B3), the conditional mean function is given by
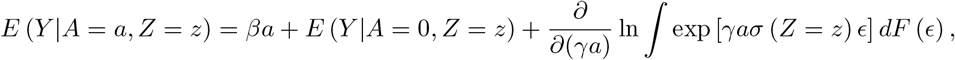 where F () denotes the cumulative distribution function of ϵ. The error distribution may be reasonably approximated by a Gaussian mixture model with enough components (Goodfellow et al. 2016). Specifically, let
where F () denotes the cumulative distribution function of ϵ. The error distribution may be reasonably approximated by a Gaussian mixture model with enough components (Goodfellow et al. 2016). Specifically, let 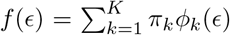 where ϵk(·) is the normal density with mean µk and variance
where ϵk(·) is the normal density with mean µk and variance 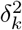 satisfying the constraints
satisfying the constraints
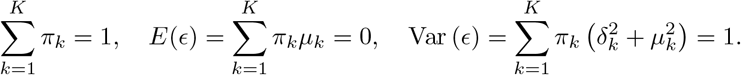 The conditional mean function with Gaussian mixture error is given by
The conditional mean function with Gaussian mixture error is given by
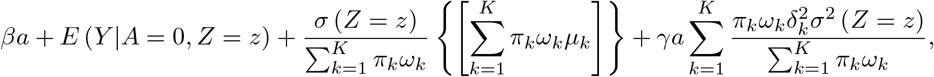 Where
Where 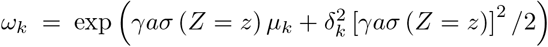 . The conditional distribution is
. The conditional distribution is 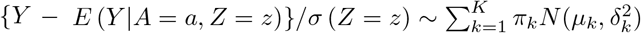 . In practice, estimation of (β, γ) may proceed under a user-specified integer value K < as well as parametric models for E(Y|A = 0, Z = z) and σ(Z = z) via an alternating optimization algorithm which we describe in the Supplementary Materials.
. In practice, estimation of (β, γ) may proceed under a user-specified integer value K < as well as parametric models for E(Y|A = 0, Z = z) and σ(Z = z) via an alternating optimization algorithm which we describe in the Supplementary Materials.
3 Simulation Studies
In this section, we conduct simulation studies to evaluate the finite-sample performance of our one-step-update estimating method. Sample sizes of n = 10, 000, 30, 000, 100, 000 are considered; still considerably smaller than the UK Biobank study considered below for illustration with sample size of a couple of hundred thousands independent samples. If our method can produce good estimates in smaller sample settings, we expect it will have even better performance in larger sample settings. The IV Z is generated from a Binomial distribution with probability equal to 0.3 (minor allele frequency). The treatment A is simply generated from the standard normal distribution N (0, 1). The outcome Y is also generated from a normal distribution with mean and variance given by
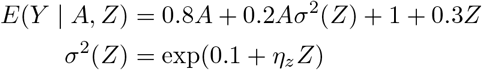 where ηz is set to be 0.2, 0.15, 0.1, 0.05. We generated in total 1000 such data sets and then apply our proposed method to each of them. Results are summarized in Table 1. We found that when sample size is 10,000, the bias and standard error of the causal effect and selection bias parameter estimates become larger when the IV strength ηz decreases from 0.2 to 0.1. The causal effect is less sensitive to the IV strength compared to the selection bias parameter γ. As we increase sample size, the bias gets much smaller and becomes negligible when the sample size is 100,000. Confidence intervals achieved the nominal 95% coverage.
where ηz is set to be 0.2, 0.15, 0.1, 0.05. We generated in total 1000 such data sets and then apply our proposed method to each of them. Results are summarized in Table 1. We found that when sample size is 10,000, the bias and standard error of the causal effect and selection bias parameter estimates become larger when the IV strength ηz decreases from 0.2 to 0.1. The causal effect is less sensitive to the IV strength compared to the selection bias parameter γ. As we increase sample size, the bias gets much smaller and becomes negligible when the sample size is 100,000. Confidence intervals achieved the nominal 95% coverage.
Simulation results for estimating the confounding bias parameter γ and the ETT β using the one-step estimator approach (without covariates) based on 1000 Monte Carlo experiments with a range of sample sizes n. 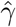 is the averaged point estimates of γ, and bias is calculated in percentage format. Likewise for
is the averaged point estimates of γ, and bias is calculated in percentage format. Likewise for 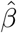 . SE is the averaged standard error. SD stands for the sample standard deviation of the 1000 point estimates for γ and β. Coverage is calculated as the proportion of 95% confidence intervals that contains the true parameter value among those 1000 experiments. We vary the value of ηz in σ2(Z) = exp(η0 + ηzZ)) to assess the impact of decreasing IV strength on the estimation results.
. SE is the averaged standard error. SD stands for the sample standard deviation of the 1000 point estimates for γ and β. Coverage is calculated as the proportion of 95% confidence intervals that contains the true parameter value among those 1000 experiments. We vary the value of ηz in σ2(Z) = exp(η0 + ηzZ)) to assess the impact of decreasing IV strength on the estimation results.
The second simulation study is designed to evaluate the finite sample performance of the proposed three-stage estimator and the CMLE in presence of many weak invalid IVs. The sample size is set to be 100,000, each IV Zj, j = 1, …, p, is still generated to take values 0,1,2 with minor allele frequency equal to 0.3. The treatment A is generated from standard normal distribution. The outcome Y is generated from a normal distribution with mean and variance given by
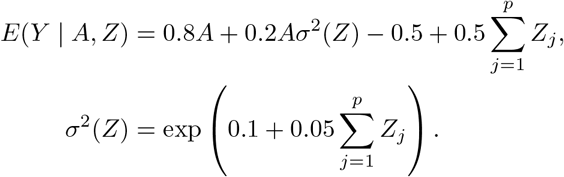 Simulation results are presented in Table 2, where the standard error (SE) for the three-stage estimator is the bootstrap estimator approximated using 100 Monte Carlo simulations, the SE for the CMLE is obtained from the inverse Hessian matrix discussed in Section 2.3. From the results in Table 2, the three-stage estimator has negligible bias when p = 20, but shows evidently larger bias when p grows to 50, which is also reflected by the fact that the coverage probabilities are smaller than 95%. In contrast, the CMLE shows negligible bias in both scenarios. The standard errors for the CMLE are close to the standard deviations, and the CMLE estimators show nominal coverage in both simulation scenarios. These observations agree with our theoretical assessment that the CMLE is efficient and is robust to many weak invalid IVs. In particular, it is consistent and asymptotically normal as long as the condition
Simulation results are presented in Table 2, where the standard error (SE) for the three-stage estimator is the bootstrap estimator approximated using 100 Monte Carlo simulations, the SE for the CMLE is obtained from the inverse Hessian matrix discussed in Section 2.3. From the results in Table 2, the three-stage estimator has negligible bias when p = 20, but shows evidently larger bias when p grows to 50, which is also reflected by the fact that the coverage probabilities are smaller than 95%. In contrast, the CMLE shows negligible bias in both scenarios. The standard errors for the CMLE are close to the standard deviations, and the CMLE estimators show nominal coverage in both simulation scenarios. These observations agree with our theoretical assessment that the CMLE is efficient and is robust to many weak invalid IVs. In particular, it is consistent and asymptotically normal as long as the condition 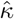 is reasonable large.
is reasonable large.
Simulation results for estimating the confounding bias parameter γ = 0.2 and the ETT β = 0.8 using the three-stage estimator and the CMLE based on 1000 Monte Carlo experiments, with n = 100, 000 and varying p. The third column is the averaged 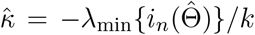 , which is the consistency and asymptotic normality condition for the CMLE and is preferably to be large.
, which is the consistency and asymptotic normality condition for the CMLE and is preferably to be large. 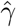 is the averaged point estimates of γ, and bias is calculated in percentage format. Likewise for
is the averaged point estimates of γ, and bias is calculated in percentage format. Likewise for 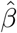 . SE is the averaged standard error. SD stands for the sample standard deviation of the 1000 point estimates for γ and β. Coverage is calculated as the proportion of 95% confidence intervals that contains the true parameter value among those 1000 experiments.
. SE is the averaged standard error. SD stands for the sample standard deviation of the 1000 point estimates for γ and β. Coverage is calculated as the proportion of 95% confidence intervals that contains the true parameter value among those 1000 experiments.
We similarly generate the treatment A from the standard normal distribution, the IV Z which takes values in 0, 1, 2 with minor allele frequency equal to 0.3. However we generate Y = E(Y|A, Z) + σ(Z)ϵ where the error ϵ is generated from a Gaussian mixture distribution with two components,
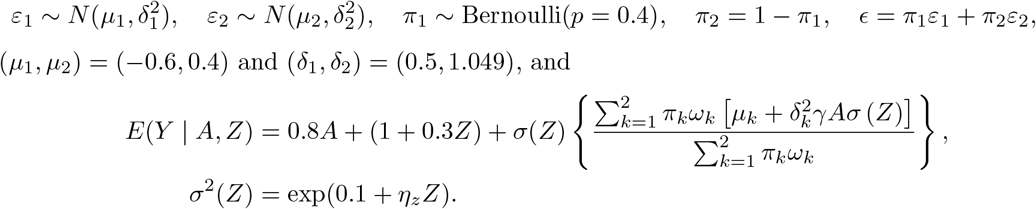 We vary the value of ηz in the set 0.1, 0.25, 0.5 to assess the impact of IV strength. The results using the proposed Gaussian mixture method with K = 2 are summarized in Table 3. There is noticeable finite-sample bias and under-coverage when ηz = 0.1, especially for estimation of the selection bias parameter γ, but the performance improves with larger ηz or sample size. We perform an additional set of simulations to assess the impact of model misspecification. Specifically, the error is generated from a mixture of two uniform distributions
We vary the value of ηz in the set 0.1, 0.25, 0.5 to assess the impact of IV strength. The results using the proposed Gaussian mixture method with K = 2 are summarized in Table 3. There is noticeable finite-sample bias and under-coverage when ηz = 0.1, especially for estimation of the selection bias parameter γ, but the performance improves with larger ηz or sample size. We perform an additional set of simulations to assess the impact of model misspecification. Specifically, the error is generated from a mixture of two uniform distributions
Simulation results for estimating the confounding bias parameter γ = 0.2 and the ETT β = 0.8 under Gaussian mixture error based on 1000 replicates. See the caption of Table 1 for description of the summary statistics.
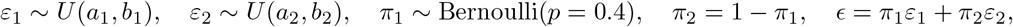 where (a1, b1) = (0.6 0.87, 0.6 + 0.87) and (a2, b2) = (0.4 1.82, 0.4 + 0.82). To be consistent with the implications of assumptions (B1)-(B3), we then generate the outcome with
where (a1, b1) = (0.6 0.87, 0.6 + 0.87) and (a2, b2) = (0.4 1.82, 0.4 + 0.82). To be consistent with the implications of assumptions (B1)-(B3), we then generate the outcome with
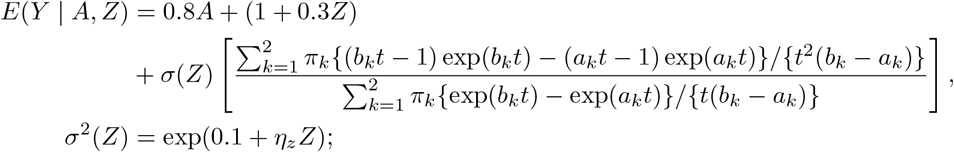 where t(A, Z; γ) ≡ γAσ(Z). The Gaussian mixture procedure with K = 2 failed to converge in the weak IV setting where ηz = 0.1; we only report results for ηz = 0.25 or 0.5 in Table 4. The absolute bias of the Gaussian mixture estimator becomes noticeably larger for the same values of (n, ηz), especially in estimation of γ. The average standard error at ηz = 0.25 is significantly larger than the Monte Carlo standard error, resulting in somewhat conservative confidence intervals. Although simulations for the mixture model were only performed in the single IV case in which case the approach appeared to become unreliable in the weak single IV setting, we expect the CMLE under mixture Gaussian error will exhibit similar robustness in many weak IV regimes as the simple Gaussian model explored in the previous simulation study.
where t(A, Z; γ) ≡ γAσ(Z). The Gaussian mixture procedure with K = 2 failed to converge in the weak IV setting where ηz = 0.1; we only report results for ηz = 0.25 or 0.5 in Table 4. The absolute bias of the Gaussian mixture estimator becomes noticeably larger for the same values of (n, ηz), especially in estimation of γ. The average standard error at ηz = 0.25 is significantly larger than the Monte Carlo standard error, resulting in somewhat conservative confidence intervals. Although simulations for the mixture model were only performed in the single IV case in which case the approach appeared to become unreliable in the weak single IV setting, we expect the CMLE under mixture Gaussian error will exhibit similar robustness in many weak IV regimes as the simple Gaussian model explored in the previous simulation study.
Simulation results for estimating the confounding bias parameter γ = 0.2 and the ETT β = 0.8 under uniform mixture error based on 1000 replicates. See the caption of Table 1 for description of the summary statistics.
4 An Application to the Large-Scale UK Biobank Study Data
UK Biobank is a large-scale ongoing prospective cohort study that recruited around 500,000 participants aged 40-69 in 2006-2010. Participants provided biological samples, completed questionnaires, underwent assessments, and had nurse led interviews. Follow up is chiefly through cohort-wide linkages to National Health Service data, including electronic, coded death certificate, hospital, and primary care data (Sudlow et al. 2015). To control for population stratification, we restricted our analysis to participants with self-reported and genetically validated white British ancestry. For quality control, we also excluded participants with (1) excess relatedness (more than 10 putative third-degree relatives) or (2) mismatched information on sex between genotyping and self-report, or (3) sex-chromosomes not XX or XY, or (4) poor-quality genotyping based on heterozygosity and missing rates > 2%.
To illustrate our methods, we extracted a total of 289,010 white British subjects from the UK Biobank data with complete measurements in body mass index (BMI) and glucose levels. We further selected BMI associated SNP potential IVs among the list provided by Sun et al. (2019). We found 7 SNPs (in Table 5) that are predictive of the residual variance of glucose levels in our Stage 2 regression (p < 0.01). The average BMI is 27.39 kg/m2 (SD: 4.75 kg/m2), and the average glucose level is 5.12 mmol/L (SD: 1.21 mmol/L). We applied the proposed methods to this data set with the goal of evaluating the causal relationship between BMI as treatment and glucose level as outcome; analysis results are summarized in Table 5. For comparison purposes, we also include results for standard two-stage least square method implemented in the R package ivreg (Fox et al. 2020). The allele score for the 7 SNPs selected is defined as the signed sum of their minor alleles, where the sign is determined by the regression coefficient in our stage 2 regression. We also implemented MR-GENIUS method (Tchetgen Tchetgen et al. 2020) using the same 7 SNPs, the causal effect of BMI on glucose was estimated as 0.046 (se: 0.01, p-value: 2.24 ×10−6). Crude regression analysis by simply regressing glucose on BMI gives an estimate of 0.041 (se: 4.65 × 10−4, p-value: < 2 10−16). Further, we included all 7 SNPs into a conventional regression together with BMI, and obtained a similar estimate 0.039 (se: 4.65 × 10−4, p-value: < 2 10−16). It is interesting to consider results obtained by selecting each SNP as single candidate IV as summarized in the table. For instance, take the SNP rs2176040, the corresponding causal effect estimate is 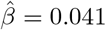 (se: 0.0139, p-value: 0.003), and the selection bias parameter is estimated as
(se: 0.0139, p-value: 0.003), and the selection bias parameter is estimated as 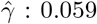 (se:0.0098, p-value: 2.93 × 10−9). However, the standard two-stage least squares (TSLS) method gives causal effect estimate 1.619(se: 2.04, p-value: 0.428). These conflicting inferences may be due to SNP rs2176040 being an invalid IV, in which case TSLS likely yields biased results. We further combine 20 SNPs, 13 of them are weakly associated with the residual variance of glucose levels, we obtain using MLE a causal effect estimate of BMI on glucose
(se:0.0098, p-value: 2.93 × 10−9). However, the standard two-stage least squares (TSLS) method gives causal effect estimate 1.619(se: 2.04, p-value: 0.428). These conflicting inferences may be due to SNP rs2176040 being an invalid IV, in which case TSLS likely yields biased results. We further combine 20 SNPs, 13 of them are weakly associated with the residual variance of glucose levels, we obtain using MLE a causal effect estimate of BMI on glucose 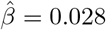 (se:0.0025, p-value:6.87 × 10−31), and a selection bias estimate of
(se:0.0025, p-value:6.87 × 10−31), and a selection bias estimate of 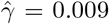 (se: 0.0017, p-value: 2.82 × 10−7). This final analysis suggests a somewhat smaller treatment effect size than all other MR methods, while providing strong statistical evidence of a positive effect with a relatively small but statistically significant amount of confounding bias detected.
(se: 0.0017, p-value: 2.82 × 10−7). This final analysis suggests a somewhat smaller treatment effect size than all other MR methods, while providing strong statistical evidence of a positive effect with a relatively small but statistically significant amount of confounding bias detected.
UK Biobank data analysis results. Columns 2-5 contain the results based on the model (1), columns 6-9 contain results based on the Gaussian mixture model described in Section 2.4, columns 10-11 contain results using the standard two-stage least squares using the R package ivreg.
5 Discussion
In this paper, we have considered identification and inference about a causal effect in an observational study using a novel MR approach. MR MiSTERI leverages a possible association between candidate IV SNPs and the variance of the outcome in order to disentangle confounding bias from the causal effect of interest. Importantly, MR MiSTERI can recover unbiased inferences about the causal effect in view even when none of the candidate IV SNPs is a valid IV. Key assumptions which the approach relies on include no additive interaction involving a candidate IV SNP and the treatment causal effect in the outcome model, and a requirement that the amount of selection bias (measured on the odds ratio scale) remains constant as a function of SNP values. Violation of either assumption may result in incorrect inferences about treatment effect. Although not pursued in this paper, robustness to such violation may be assessed via a sensitivity analysis in which the impact of various departures from the assumption may be explored by varying sensitivity parameters. Alternatively, as illustrated in our application, providing inferences using a variety of MR methods each of which relying on a different set of assumptions provides a robustness check of empirical findings relative to underlying assumptions needed for a causal interpretation of results. A notable robustness property of the MLE approach to MR MiSTERI is that as we formally establish, it is robust to many weak IV bias, thus providing certain theoretical guarantees of reliable performance in many common MR settings where one might have available a relatively large number of weak candidate IVs, many of which may be subject to pleiotropy. While the proposed methods require correctly specified a Gaussian model for the conditional distribution of Y given A and Z, such an assumption can be relaxed. In fact, in the paper, We also consider a Gaussian mixture model as a framework to assess and possibly correct for possible violation of this assumption. Furthermore, in the Supplementary Materials, we briefly describe a semiparametric three-stage estimation approach under the location-scale model which allows the distribution of standardized residuals to remain unrestricted. It will be of interest to investigate robustness and efficiency properties of this more flexible estimator, which we plan to pursue in future work. It would likewise be of interest to investigate whether the proposed methods can be extended to the important setting of a binary outcome, which is of common occurrence in epidemiology and other health and social sciences.
Data Availability
This research has been conducted using the UK Biobank resource (https://www.ukbiobank.ac.uk) under application number 44430.
Conflict of interest
None declared.
Proof of Theorem 1
Supplementary Materials
Proof. Under assumptions (B1) - (B3), we have
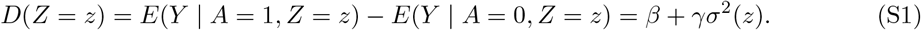 Hence, we have the following two equations
Hence, we have the following two equations
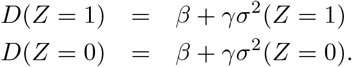 Solving these two equations simultaneously gives the result in Theorem 1.□
Solving these two equations simultaneously gives the result in Theorem 1.□
Estimation and Inference under Weak Identification
Consider the normal model (1). Let
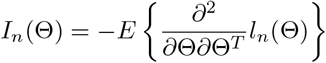 be the Fisher information matrix for a sample of size n, λmin{In(Θ)} be the minimum eigenvalue of In(Θ), tr(A) be the trace of a square matrix A.
be the Fisher information matrix for a sample of size n, λmin{In(Θ)} be the minimum eigenvalue of In(Θ), tr(A) be the trace of a square matrix A.
Condition 2 summaries the regularity conditions.
Condition 2 (Regularity Conditions). For every o = (y, a, z) in the support of O = (Y, A, Z), the likelihood function denoted by f (Θ; o) is twice continuously differentiable in Θ and satisfies
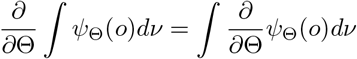 for ψΘ(o) = fΘ(o) and = ∂fΘ(o)/∂Θ, where ν is a suitable measure; there is a positive E such that the Fisher information matrix In(Γ) is positive definite for Γ : ‖Γ − Θ ‖ < ϵ; and for any given Θ, there exists a positive number E and a positive integrable function h, such that
for ψΘ(o) = fΘ(o) and = ∂fΘ(o)/∂Θ, where ν is a suitable measure; there is a positive E such that the Fisher information matrix In(Γ) is positive definite for Γ : ‖Γ − Θ ‖ < ϵ; and for any given Θ, there exists a positive number E and a positive integrable function h, such that
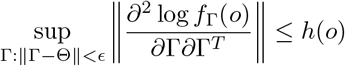 for all o in the support of O, where
for all o in the support of O, where 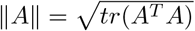 for any matrix A.
for any matrix A.
Theorem 3 establishes the consistency and asymptotic normality of solutions to the score function.
(a) Under Condition 2 and assume that the observed data Oi, i = 1, …, n are independent and identically distributed, if k/[λmin{nI1(Θ)}] → 0, then the sequence of conditional maximum likelihood estimators 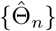 is consistent, i.e.,
is consistent, i.e.,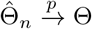 .
.
(b) Any consistent sequence 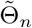 such that
such that 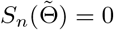 is asymptotically normal, and as n → ∞,
is asymptotically normal, and as n → ∞,

In fact, the general consistency condition in Theorem 3 can be written as λmin{nI1(Θ)} → ∞ and
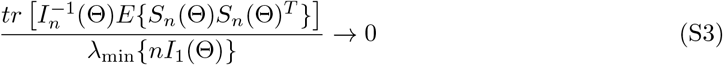 for general likelihood-based methods, which, for example, applies to the profile-likelihood estimator in Zhao et al. (2019b). Specifically, in Zhao et al. (2019b), in their notations, k = 1, E{Sn(Θ)Sn(Θ)T } = V1, In(Θ) = V2, and V1 = V2 + O(p), V2 ⩆ n‖γ‖2, and thus, condition (S3) becomes
for general likelihood-based methods, which, for example, applies to the profile-likelihood estimator in Zhao et al. (2019b). Specifically, in Zhao et al. (2019b), in their notations, k = 1, E{Sn(Θ)Sn(Θ)T } = V1, In(Θ) = V2, and V1 = V2 + O(p), V2 ⩆ n‖γ‖2, and thus, condition (S3) becomes 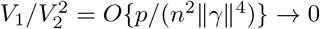 , which is the condition for consistency in Zhao et al. (2019b, Theorem 3.1).
, which is the condition for consistency in Zhao et al. (2019b, Theorem 3.1).
Proof. First, notice that the condition k/[λmin{nI1(Θ)}] → 0 implies λmin{nI1(Θ)} → ∞. Let Bn(c) = {Γ : ‖[In(Θ)]1/2(Γ − Θ)‖ ≤ c} for c > 0, where 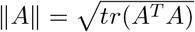 for any matrix A. Since Bn(c) shrinks to Θ as n → ∞, the consistency result in Theorem 3(a) is implied by the fact that for any ϵ > 0, there exists c > 0 and n0 > 1 such that
for any matrix A. Since Bn(c) shrinks to Θ as n → ∞, the consistency result in Theorem 3(a) is implied by the fact that for any ϵ > 0, there exists c > 0 and n0 > 1 such that
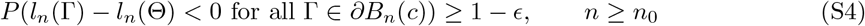 and
and 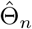 is unique for n ≥ n0, where ∂Bn(c) is the boundary of Bn(c). For Γ ∈ ∂Bn(c), the Taylor expansion gives
is unique for n ≥ n0, where ∂Bn(c) is the boundary of Bn(c). For Γ ∈ ∂Bn(c), the Taylor expansion gives
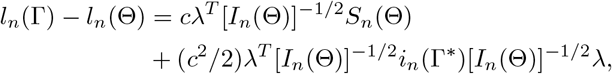 where λ = [In(Θ)]1/2(Γ − Θ)/c satisfying ‖λ‖ = 1, in(Γ) = ∂2ln(Γ)/∂Γ∂ΓT, and Γ* lies between Γ and Θ. Note that
where λ = [In(Θ)]1/2(Γ − Θ)/c satisfying ‖λ‖ = 1, in(Γ) = ∂2ln(Γ)/∂Γ∂ΓT, and Γ* lies between Γ and Θ. Note that
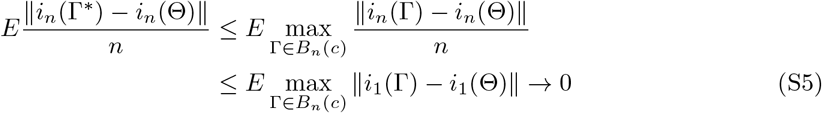 which follows from the dominated convergence theorem combined with the facts that (a) i1(Γ) = ∂l1(Γ)/∂Γ∂ΓT is continuous in a neighborhood of Θ for any fixed observation; (b) Bn(c) shrinks to {Θ} from λmin(In(Θ)) → ∞; and (c) for sufficiently large n,
which follows from the dominated convergence theorem combined with the facts that (a) i1(Γ) = ∂l1(Γ)/∂Γ∂ΓT is continuous in a neighborhood of Θ for any fixed observation; (b) Bn(c) shrinks to {Θ} from λmin(In(Θ)) → ∞; and (c) for sufficiently large n, 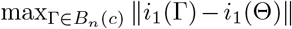 is bounded by an integrate function under Condition 2. By the strong law of large numbers,
is bounded by an integrate function under Condition 2. By the strong law of large numbers,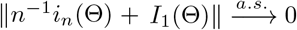 . These results imply that
. These results imply that
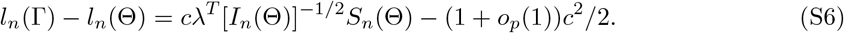 Note that maxλ{λT [In(Θ)]−1/2Sn(Θ)} = In(Θ)−1/2Sn(Θ) with
Note that maxλ{λT [In(Θ)]−1/2Sn(Θ)} = In(Θ)−1/2Sn(Θ) with
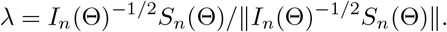 Therefore, (S4) follows from (S6) and
Therefore, (S4) follows from (S6) and
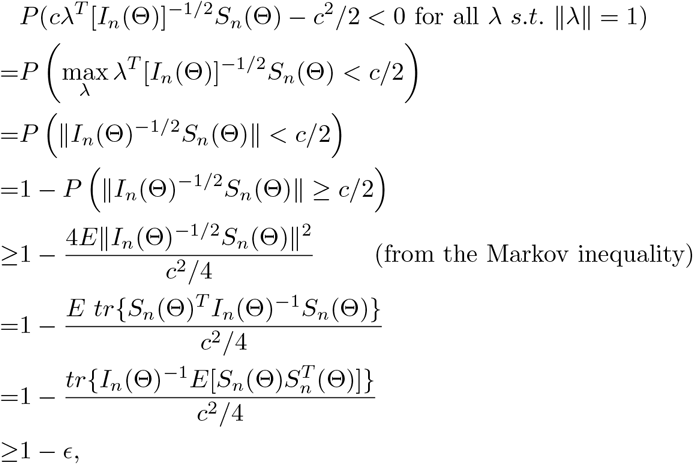 from choosing c such that
from choosing c such that 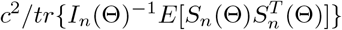 is large enough, which is possible because
is large enough, which is possible because
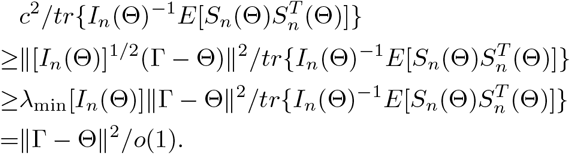 For n ≥ n0,
For n ≥ n0, 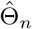 is unique because from Condition 2, the Fisher information In(Γ) is positive definite in a neighborhood of Θ.
is unique because from Condition 2, the Fisher information In(Γ) is positive definite in a neighborhood of Θ.
(b) Using the mean value theorem for vector-valued functions, we obtain that
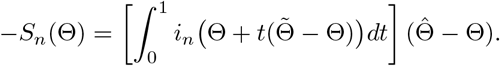 Note that using a similar argument as in (S5), when
Note that using a similar argument as in (S5), when 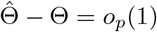 ,
,
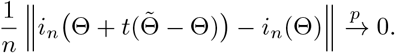 Since
Since 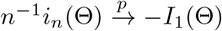 and In (Θ) = nI1 (Θ),
and In (Θ) = nI1 (Θ),
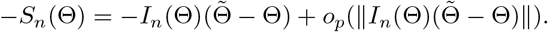 This and Slutsky’s theorem imply that
This and Slutsky’s theorem imply that 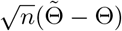 is asymptotically equivalent with
is asymptotically equivalent with
 by the central limit theorem for i.i.d. samples. □
by the central limit theorem for i.i.d. samples. □
Estimation method under Gaussian mixture error
We describe the alternating optimization procedure with user-specified K and parametric models σ(Z = z; η) and E(Y|A = 0, Z = z; θ) µ0(z; θ) indexed by finite-dimensional parameters η and θ respectively.
Initialization step: maximize the standard Gaussian location scale model
 with respect to (β, θ, η, γ) by maximum likelihood estimation, to obtain . Construct the standardized residuals
with respect to (β, θ, η, γ) by maximum likelihood estimation, to obtain . Construct the standardized residuals
Maximize the Gaussian mixture location scale model
with respect to (π1, …, πK, µ1, …, µK, d1, …, dK) using constrained maximum likelihood estimation to obtain . Construct
where
Minimize
using the least squares method with offset to obtain new , followed by regressing the squared residuals to obtain new . Construct the standardized residuals
based on the new values .Iterate between steps (ii) and (iii) until change in log-likelihood derived at step (ii) falls below a user-specified tolerance level. In this simulation we iterate until |log LLj − log LLj−1|/| log LLj−1|< 0.001 at the j-th iteration.
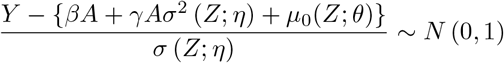
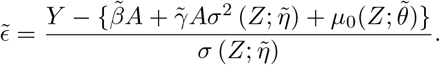
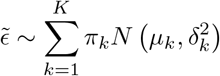
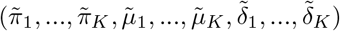
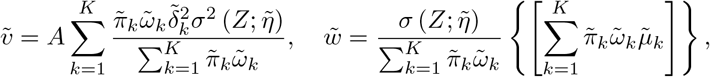
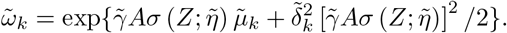
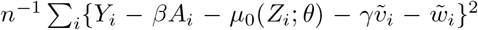
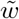
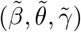
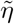
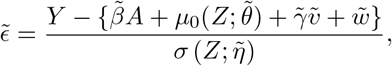
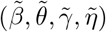
Asymptotic variance is estimated based on standard M-estimation theory by stacking the estimating functions in steps (ii) and (iii), evaluated at the final parameter values at convergence.
Semiparametric three-stage estimation
Consider the general location-scale model
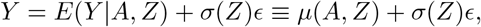 where ϵ⊥ A, Z. Under assumptions (B1)-(B3), the conditional mean function is given by
where ϵ⊥ A, Z. Under assumptions (B1)-(B3), the conditional mean function is given by
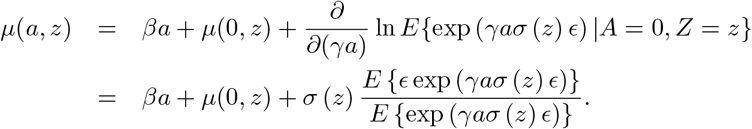 A semiparametric three-stage estimator of (β, γ) may be implemented via the following steps:
A semiparametric three-stage estimator of (β, γ) may be implemented via the following steps:
Fit the regression model µ(a, z) = ma (a)+mz (z)+maz (a, z), where 0 = mz (0) = maz (a, 0) = maz (0, z) for identification, using a nonparametric method such as generalized additive model. For example, if the support of Z is 0, 1, 2, then the nonparametric model for the outcome is of the form µ(a, z) = ma (a)+ {γ1z + γ2z2} + {zm1 (a)+ z2m2 (a)} with m1 (0) = m2 (0) = 0; a saturated model may be considered if A also has finite support. Let
denote the resulting estimator of the mean µ(a, z).Using the residuals from (i), fit a nonparametric model for the conditional variance σ2 (z). If the support of Z is 0, 1, 2, then we can specify the saturated model σ2(z) = exp(η0 + η1z + η2z2). Let
denote the resulting estimator of σ2(z).Define
and let
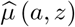
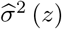
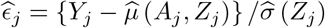
{kind=link}
{kind=link}
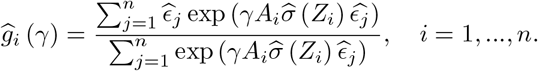 The proposed semiparametric three-stage estimator of (β, γ) is
The proposed semiparametric three-stage estimator of (β, γ) is
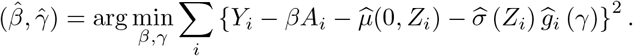 We note that a potentially more efficient approach is to maximize the log-likelihood for the model using a kernel estimator for the density of standardized residuals from step (iii). Specifically, let
We note that a potentially more efficient approach is to maximize the log-likelihood for the model using a kernel estimator for the density of standardized residuals from step (iii). Specifically, let
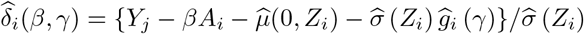 and define
and define
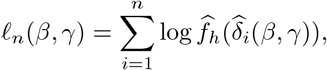 where
where 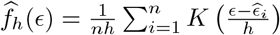 is a kernel density estimator with bandwidth h > 0. The alternative estimator of (β, γ) is given by
is a kernel density estimator with bandwidth h > 0. The alternative estimator of (β, γ) is given by
Acknowledgements
Dr. Zhonghua Liu’s research is supported by the start-up research fund of the University of Hong Kong. Dr Eric Tchetgen Tchetgen is supported by grants R01AG065276, R01CA222147 and R01AI27271. Dr Baoluo Sun is supported by the National University of Singapore Start-Up Grant (R-155-000-203-133). This research has been conducted using the UK Biobank resource (https://www.ukbiobank.ac.uk) under application number 44430.
Footnotes
Correct a few typos.
References




