
Abstract
As we begin to recover from the COVID-19 pandemic, a key question is if we can avert such disasters in future. Current surveillance protocols generally focus on qualitative impact assessments of viral diversity 1. These efforts are primarliy aimed at ecosystem and human impact monitoring, and do not help to precisely quantify emergence. Currently, the similarity of biological strains is measured by the edit distance or the number of mutations that separate their genomic sequences 2–6, e.g. the number of mutations that make an avian flu strain human-adapted. However, ignoring the odds of those mutations in the wild keeps us blind to the true jump risk, and gives us little indication of which strains are more risky. In this study, we develop a more meaningful metric for comparison of genomic sequences. Our metric, the q-distance, precisely quantifies the probability of spontaneous jump by random chance. Learning from patterns of mutations from large sequence databases, the q-distance adapts to the specific organism, the background population, and realistic selection pressures; demonstrably improving inference of ancestral relationships and future trajectories. As important application, we show that the q-distance predicts future strains for seasonal Influenza, outperforming World Health Organization (WHO) recommended flu-shot composition almost consistently over two decades. Such performance is demonstrated separately for Northern and Southern hemisphere for different subtypes, and key capsidic proteins. Additionally, we investigate the SARS-CoV-2 origin problem, and precisely quantify the likelihood of different animal species that hosted an immediate progenitor, producing a list of related species of bats that have a quantifiably high likelihood of being the source. Additionally, we identify specific rodents with a credible likelihood of hosting a SARS-CoV-2 ancestor. Combining machine learning and large deviation theory, the analysis reported here may open the door to actionable predictions of future pandemics.
Introduction
With estimated mortality rates significantly higher compared to that of the seasonal flu, the current COVID-19 pandemic is one of the most devastating disasters of the last 100 years. As researchers strive to develop effective therapeutics and vaccine(s) to combat the SARS-CoV-2 virus, a looming question is if we can be better prepared for the next pandemic. Can we preempt emergence of novel pathogens with an actionable timeline to avert such global devastation the next time around? Current surveillance paradigms, while crucial for mapping disease ecosystems, are limited in their ability to address this challenge. Habitat encroachment, climate change, and other ecological factors 7–9 unquestionably drive up the odds of zoonotic spill-over. Nevertheless, efforts at tracking and modeling these effects till date have not improved our ability to quantify future risk of emergence of a specific strain from a specific host 1. Existence of viral diversity in hosts such as bats or swines or wild ducks, while important, might not transparently map to emergence risk, and does not address the problem at hand.
Here we argue that a key hurdle to making progress in this direction has been the missing ability to quantitatively assess the risk of emergence from strains that circulate in the wild. The state of the art urgently needs the tools necessary to numerically compute the likelihood of a biological sequence replicating in the wild to spontanously give rise to another by random chance. Indeed, currently the similarity between two genomic sequences is measured by how many mutations it takes to change one to the other. Such a measure does not tell us anything about the true jump-risk. In reality, the odds of one sequence mutating to another is a function of not just how many mutations they are apart to begin with, but also how specific mutations incrementally affect fitness. Without taking into account the constraints arising from the need to conserve function, assessing the jump-likelihood is open to subjective guesswork. Here, we show that a precise calculation is possible: provided the similarity of the sequences is evaluated via a new biology-aware metric, which we call the q-distance.
As applications of the q-distance, we show that 1) learning from the mutational patterns of key surface proteins Hemaglutinnin (HA) and Neuraminidase (NA) for Influenza A (selected for their known roles in cellular entry and exit 10), we can improve forecasts for the future dominant circulating strain under seasonal antigenic drift. We outperform WHO’s recommendations for the flu-shot composition almost consistently over past two decades, measured as the number of mutations that separate the predicted from the dominant circulating strain in the target season. Our recommendations repeatedly end up being closer, illustrating the potential of our approach to correctly predict evolutionary trajectories. And, 2) using coding sequences for the surface spike (S) protein, again selected for its known role in cellular entry 11, we investigate the SARS-CoV-2 origin problem. We quantify the likelihood of viral strains collected across disparate host species to give rise to the observed SARS-CoV-2 strains, and offer new insights backed by precise numerical assessments not possible with existing tools.
Material & Methods
Aiming to validate our metric in the context of viral evolution, we begin by collecting relevant coding sequences pertaining to key genes implicated in cellular entry from two public databases (NCBI and GISAID, See Tab. III for tally of total number of distinct sequences used). In this study we use in excess of 30; 000 distinct sequences for betacoronaviruses and Influenza A, focusing on three genes/proteins. For each organism, we uncover a network of dependencies between individual mutations revealed through subtle variations of the aligned sequences. These dependecies define our organism-specific model referred to as the quasi-species network or the Qnet (see Fig. 1 and 2). And the q-distance, informed by the dependencies modeled by the inferred Qnets, adapts to the specific organism, allelic frequencies, and nucleotide variations in the background population. The role of epistatic effects in phenotypic change is well-recognized 12; here we factor in such effects in a numerically precise manner to compute bounds on the likelihood of specific strains giving rise to target variants (See Fig. 1b-c).
Out-Performance of Qnet recommendations over WHO for Influenza A vaccine composition

Panel a. Using sequence variations observed in large databases, we distill evolutionary constraints on a genomic sequence to induce a biology-aware metric for comparing subtle differences in mutating sequences. This metric (q-distance) adjusts to specific organisms, background populations and selection pressures, and reflects the true likelihood of a spontaneous jump from one sequence to the other. We can use this sequence level metric to compute distances between a sequence and a population, and two populations. Panels b and c illustrates that we can calculate bounds on the exact likelihood of a spontaneous jump between strains (panel b) and rank-order strains observed in a diverse set of hosts to accurately model future emergence risk (panel c).

Panel a. As an example, beginning with aligned sequences, we calculate a conditional inference tree for index 1274, which involves indices 1064, 1445, 197 as predictive features. These features are automatically selected by the algorithm, as being maximally predictive of the base at 1274. Then, we compute predictors for each of these predictive indices, e:g: we show the inference tree computed for index 1064, which involves index 1314 and 339 as features. Continuing, we find that the predictor for 1314 involves indices 1263, 636 and 21, and that for 1263 involves 1314, 667 and 313. Note that recursive dependencies arise automatically: the predictor for 1263 depends on 1314, and that for 1314 depends on 1263. Panels b-c show Qnet dependency graphs for SARS-CoV-2 spike protein and Influenza A HA respectively, illustrating the distinct patterns of mutational constraints inferred. Both HA in Influenza A and the spike protein in SARS-CoV-2 are implicated in viral entry into host cells, and crucial for host specificity of infections. Additionally, the inferred structures underscore the significantly more complex dependencies in SARS-CoV-2 compared to Influenza A.
Clearly in any surveillance effort, we may only observe sequences of high fitness, and only a small subset of viable sequences are ever isolated. A single 10KB observed equence represents a single observation in a 10,000 dimensional space; thus we might never collect enough data points to exhaustively model the set of epistatic dependencies for any realistic genome length. Nevertheless, our results indicate that the scientific community has now accumulated enough sequences for us get meaningful results, at least for some RNA viruses with high mutational rates that reveal enough of the hidden constraints. Admittedly this is but one piece of the puzzle: putting numbers in place of qualitative judgments does not automatically resolve the complex modeling problem of emergence 13–20. Notwithstanding the limitations, the ability to quantitatively contrast sequence similarity addresses key aspects of this problem, allowing us to carry out precise comparisons not possible before.
To design our metric, we employ a suite of customized machine learning algorithms to infer the Qnet from aligned genomic sequences sampled from the similar populations, e.g. HA from Human Influenza A in year 2008, or the spike protein from all bat betacoronaviruses. The Qnet predicts the nucleotide distribution over the base alphabet (the four nucleic acid bases ATGC) at any specific index, conditioned on the nucleotides making up the rest of the sequence of the gene or genome fragment under consideration. We define the q-distance (See Eq. (3) in Methods) as the square-root of the Jensen-Shannon (JS) divergence 21 of these conditional distributions from one sequence to another, averaged over the entire sequence. Invoking Sanov’s theorem on large deviations 21 (See Methods), we show that the likelihood of spontaneous jump is bounded above and below by a simple exponential function of the q-distance.
The mathematical intuition behind relating the new distance to jump-probability is the same as in the prediction of a biased outcome when we sequentially toss a fair coin. With an overwhelming probability, such an experiment with a fair coin should result in roughly equal number of heads and tails. However, “large deviations” can happen, and the probability of such rare events is quantifiable 22 with existing theory. We show here that the likelihood of a spontaneous transition of a genomic sequence to a substantially different variant by random chance may also be similarly bounded, given we have the Qnet as an estimated model of the evolutionary constraints.
How are Qnets constructed? The key idea is surprisingly simple: we learn models for predicting the mutational variations at each index of the genomic sequence using other indices as features. For example, in Fig. 2a, the predictor for index 1274 uses variation at index 1064 as a feature, and the predictor for index 1064 uses index 1314 as a feature, and so on – ultimately uncovering a recursive dependency structure. Collectively, these inter-dependent predictors represent the constraints that shape evolutionary trajectories driven by selection. The inferred dependencies are illustrated in Fig. 2b-c for SARS-CoV-2 S protein and Influenza A HA respectively, showing that these viruses have markedly different dependency networks for proteins that carry out similar functions (Class I fusion protiens 23 mediating cellular entry).
Importantly, the q-distance between two sequences may change if we simply change the background populations, and not the sequences themselves (See Table I for examples, where the distance between two specific Influenza A H1N1 Hemaglutinnin sequences vary when we assume they were collected in different years), and sequences might have a large q-distance and a small edit distance, and vice versa (although on average the two distances tend to be positively correlated, see Tab. II). Hence we construct a new Qnet whenever the background populations are expected to be substantially different, e.g., we construct separate Qnets for betacoronavirus S protein sequences isolated from bats, rodents, cattle, non-SARS-CoV-2 human betacoronaviruses, and SARS-CoV-2 strains. For tracking drift in Influenza A, we construct a seasonal Qnet for each subtype and protein that we consider. As an important limitation, the q-distance assumes aligned sequences of identical length (although gaps arising from alignment are acceptable and are modeled as missing data). Thus, the Qnet framework is applicable to closely related sequences, and is well-suited to track subtle changes in evolving viral populations.
Eaxmples: Qnet induced distance varying for fixed sequence pair when background population changes (rows 1-5), sequences with small edit distance and large q-distance, and the converse (rows 6-9)
Correlation between q-distance and edit distance between sequence pairs
Before we enumerate our results, we note that the phylogeny based on the q-distance (q-phylogeny) is potentially distinct from the one constructed using the classical distance. And the jump-probability between two strains connected by a path in a q-phylogenetic tree is bounded above and below by simple exponential functions of the path length (See SI Methods). Thus, smaller phylogenetic distances indicate a higher probability of spontaneous transition and vice versa, making the trees much more useful for interpretation of ancestral relationships and charting possible futures. For example, comparing the phylogenies constructed using the q-distance and the classical metric for all betacoronavirus spike protein sequences from the NCBI and GISAID databases (including those for the novel SARS-CoV-2 strains) in Fig 2a-b, we find that the q-distance leads to cleaner phenotypic separation with clues to SARS-CoV-2 origin.
Results
Our first application aims to predict dominant strains for the seasonal flu epidemic. Periodic adjustment of the Influenza vaccine components is necessary to account for antigenic drift 24. The flu shot is annually prepared at least six months in advance, and comprises a cocktail of historical strains determined by the WHO via global surveillance 25, hoping to match the circulating strain(s) in the upcomimg flu season. A variety of hard-to-model effects hinders this prediction, and has limited vaccine effectiveness in recent years 26.
We hypothesized that since the probability of a jump or deviation exponentially decreases with an increasing q-distance, the centroid of the strain distribution in our metric will drift slowly. If true, the strain selected closest to the “q”-centroid will be a good approximation of next season’s dominant strain. We tested this hypothesis on past two decades of sequence data for Influenza A (H1N1 and H3N2), with promising results: the q-distance based prediction demonstrably outperforms WHO recommendations by reducing the distance between the predicted and the dominant strain (Fig. 3). Here, we identify the dominant strain to be the one that occurs most frequently, computed as the centroid of the strain distribution observed in a given season in the classical sense (no. of mutations). For H1N1 HA the Qnet induced recommendation outperforms the WHO suggestion by > 31% on average over the last 19 years, and > 81% in the last decade in the northern hemisphere. The gains for NA over the same time periods for H1N1 for the north are > 60% and > 22% respectively. For the southern hemisphere, the gains for H1N1 over the last decade are > 72% for HA, and > 50%. The full table of results is given in Tab. I in the Supplementary text. Fig. 3 illustrates the relative gains computed for both subtypes and the two hemispheres (since the flu season occupy distinct time periods and may have different dominant strains in the northern and southern hemispheres 24). Additional improvement is possible if we recommend multiple strains every season for the vaccine cocktail (Fig. 3e,f,k,l). The details of the specific strain recommendations made the Qnet approach for two subtypes (H1N1, H3N2), for two genes (HA, NA) and for the northern and the southerm hemispheres over the previous 19 years are enumerated in the Supplementary Tab. V-XIV.
Number of sequences collected from public databases
General linear model for evaluating effect of data diversity on Qnet performance
H1N1 HA Northern Hemisphere
H1N1 HA Southern Hemisphere
H1N1 NA Northern Hemisphere
H1N1 NA Southern Hemisphere
H3N2 HA Northern Hemisphere
H3N2 HA Southern Hemisphere
H3N2 NA Northern Hemisphere
H3N2 NA Southern Hemisphere
H1N1 NA Southern Hemisphere (Multi-cluster)
H3N2 NA Southern Hemisphere (Multi-cluster)

A. Relative out-performance of Qnet predictions against WHO recommendations for H1N1 and H3N2 subtypes for the HA and NA coding sequences and over the northern and southern hemispheres. The negative bars (red) indicate the reduced edit distance between the predicted sequence and the actual dominant strain that emerged that year. We see that for the overwhelming majority of seasons, we outperform WHO. Note that the recommendations for the northern hemisphere are given in Februrary, while that for the southern hemisphere are given at teh end of December the previous year, keeping in mind that the flu season in the south begins a few months early. Panels e,f,k,l show further possible improvement in NA predictions if we return 3 recommendations instead of one each year.
As our second application of the q-distance approach, we investigate the origin problem of SARS-CoV-2, via quantifying the likelihood of different animal species hosting the immediate progenitor. For any novel pathogen, a plausible history of emergence is generally constructed by estimating similarity of the consensus strain with candidates in suspected animal hosts 27,28. However, interpreting a small edit distance as being indicative of a higher chance of a species-jump is problematic, particularly if multiple potential progenitor candidates arise. In contrast, a smaller average q-distance of a novel strain from animal reservoir A vs that from B implies that there is indeed a quantifiably higher probability of a jump from A.
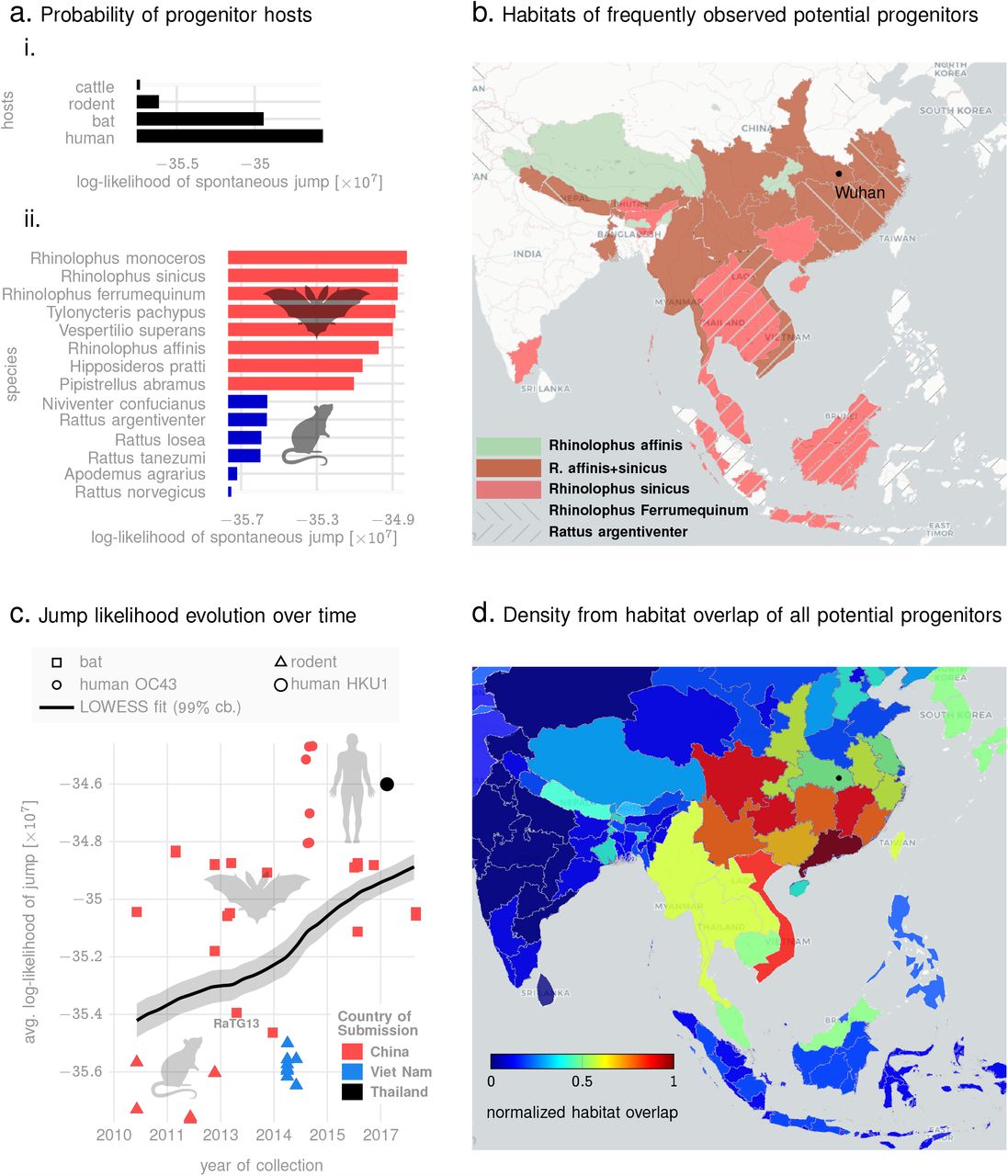
To demonstrate the applicability of this idea, we estimate numerical bounds on the likelihood of the SARS-CoV-2 progenitor arising from specific hosts. Using betacoronavirus sequences from NCBI database corresponding to different animal hosts, we estimate the mean q-distance of SARS-CoV-2 sequences to bats, mouse/rodents, cattle (including camels) and pre-existing human strains including SARS-CoV1, OC43 and HKU1 strains (See Fig. 5a, showing the average log-likelihood of jump from different animal species). We do not a priori restrict our investigation to hosts geographically bound to South East Asia, and demonstrate that this localization arises naturally from our analysis. Our results corroborate the high probability of the progenitor originating from bats as suggested in recent studies 29,30 (See Fig. 5a (i), which shows the average lower bound of the log-likelihood of a spontaneous jump from broad host categories to SARS-CoV-2 strains collected upto early March in 2020). In addition, we are also able to identify a ranked list of related bat species with the highest potential of hosting a SARS-CoV-2 progenitor (See Fig 5a (ii), which shows the minimum likelihood of jump to the nearest SARS-CoV-2 strain for the respective host species). Additionally, we find a high likelihood of a close ancestor of SARS-CoV-2 existing in rodents (Fig. 5a).
Discussion
In this study we formulate a new biology-aware distance between genomic sequences. As a function of this distance, we compute bounds on the explicit probability of a spontaneous jump between nearby variants. We show that quantification of historically qualitative characterizations of ancestral relationaships and future variant calculation improves strain predictions for Influenza A vaccines, and offers new insights into SARS-CoV-2 origin.
High season-to-season genomic variation in the key Influenza capsidic proteins is driven by two opposing influences: 1) the need to conserve function limiting random mutations, and 2) hyper-variability to escape recognition by neutralizing antibodies. Even a single residue change in the surface proteins might dramatically alter recognition characteristics, brought about by unpredictable 31,32 changes in local or regional properties such as charge, hydropathy, side chain solvent accessibility 33–36. Comparing the Qnet inferred strain (QNT) against the one recommended by the WHO, three important observations come forward: 1) the high likelihood of QNT being closer to the dominant strain (DOM) over the part two decades, and almost consistently over the last decade (See Tab. I and Fig. 3), 2) the residues that only the QNT matches correctly with DOM (while the WHO fails) are largely localized within the receptor binding domain (RBD), with > 57% occurring within the RBD on average (see Fig. 4a for a specific example), and 3) when the WHO strain deviates from the QNT/DOM matched residue, the “correct” residue is often replaced in the WHO recommendation with one that has very different side chain, hydropathy and/or chemical properties (See Fig. 4b-f), suggesting deviations in recognition characteristics. Combined with the fact that we find circulating strains are almost always within a few edits of the DOM (See SI-Fig. 1), these observations suggest that hosts vaccinated with the QNT recommendation is more likely to have season-specific antibodies that are more likely to recognize a larger cross-section of the circulating strains.

The observed dominant strain, we note that the correct Qnet deviations tend to be within the RBD, both for H1N1 and H3N2 for HA (panel a shows onbe example). Additionally, by comparing the type, side chain area, and the accessible side chain area, we note that the changes often have very different properties (panel b-f). Panels g-i show the localization of the deviationbs in the molecular structure of HA, where we note that the changes are most frequesnt in the HA1 subunit (the globular head), and around residues and structures that have been commonly implicated in receptor binding interactions e.g the 200 loop, the 220 loop and the 180-helix.
Focusing on the average localization of the QNT to WHO deviations in the HA molecular structure, the changes are observed to primarily occur in the HA1 subunit (See Fig. 4g-i, HA0 numbering used, other numbering conversions are given in Supplementary Tab. XVI), with the most frequent deviations occuring around the ≈200 loop, the ≈220 loop, the ≈180 helix, and the ≈100 helix, in addition to some residues in the HA2 subunit (≈49 & ≈124). Unsurprisingly, the residues we find to be most impacted in the HA1 subunit (the globular top of the fusion protein) have been repeatedly implicated in receptor binding interactions 37–39. Thus, we are able to fine tune the future recommendation over the state of the art, largely by modifying residue recommendations around the RBD and structures affecting recognition dynamics.
In the context of the origin problem of the 2020 pandemic, we note that literature on SARS-CoV-2 ancestry is still developing, with emerging consensus on horseshoe bats of Chinese origin 30 as the potential host of the progenitor sequence. This narrative is primarily driven by observed edit-distance and motif similarities to bat coronavirus (RaTG13, accession MN996532.1) detected in R. affinis from the Yunnan province. However, intriguing questions remain, e.g., the existence of a polybasic furin cleavage site on the spike protein which is absent in RaTG13 and related betacoronaviruses, but do occur in other human coronaviruses including HKU130. Our q-distance analysis (See Fig. 5a) corroborates the progenitor host potential of R. affinis, but we find that a related species R. sinicus is a slightly more probable source. Also, we find several other closely related horseshoe bats including R. ferrumequinum and R. monoceros, and other bats such as T. pachypus, V. superans, and P. abramus are also potential progenitor hosts. In addition, rodents such as R. argentiventer, N. confucianus, and A. agrarius have credible potential as hosting a SARS-CoV-2 ancestor. The top-ranking contenders (excluding humans) ranked by the lower bound of log-likelihood of spontaneous jump to the nearest SARS-CoV-2 strain collected in the relatively early days of the COVID19 pandemic (by early March 2020) is shown in Fig 5a (ii). The role of rodents is further strengthened by noting that SARS-CoV-2 strains and betacoronaviruses from rodents appear in the same clade nested within the clade comprising betacoronaviruses from bats, rodents and SARS-CoV-2 strains (while the rodent strains not being actually closer than those isolated in bats, see Fig. 6)).
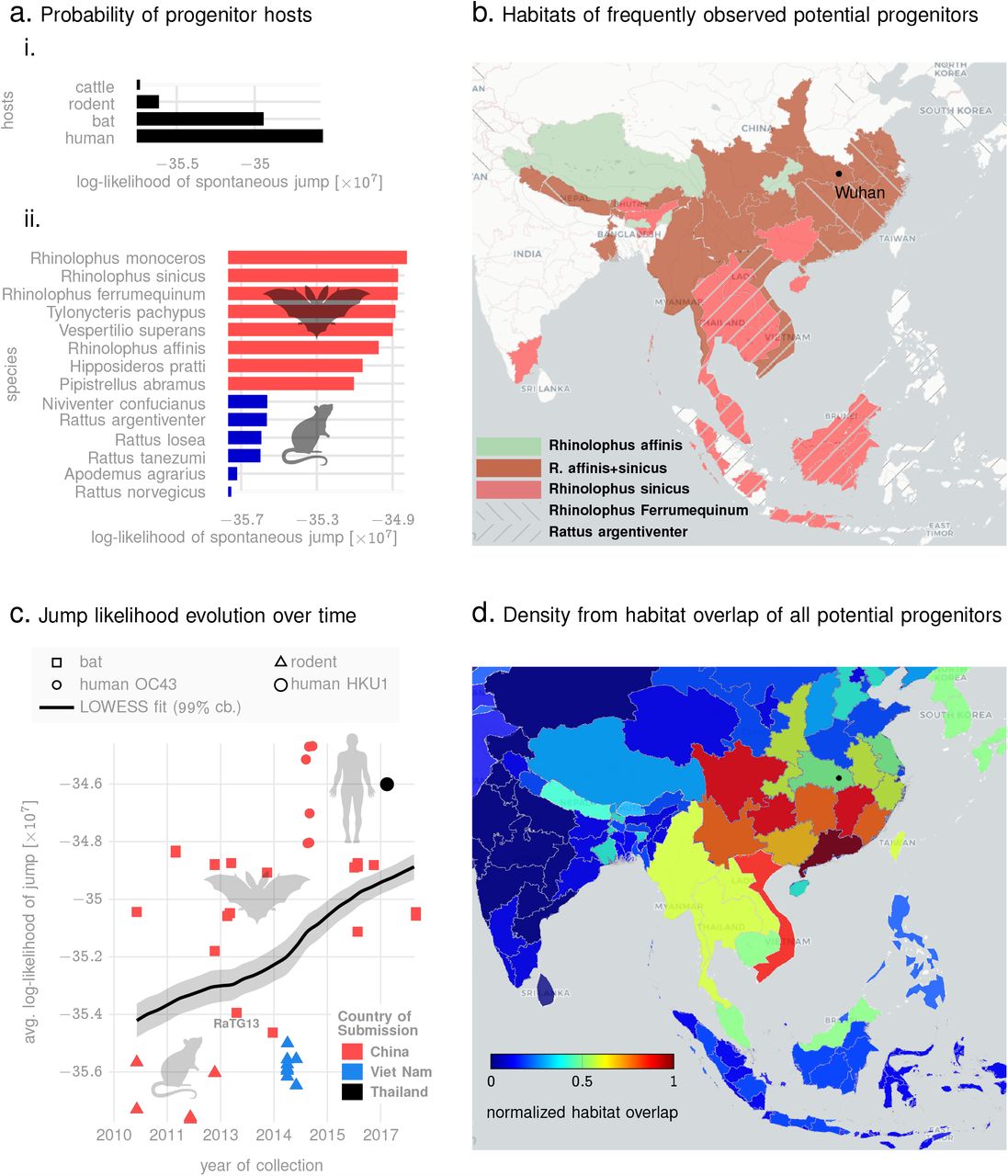
Panel a (i): average lower bounds on the log-likelihood of jump from different animal hosts to the set of SARS-CoV-2 sequences collected in the early days of the pandemic. Panel a (ii): lower bounds on the log-likelihood of jump from specific species to their respective nearest SARS-CoV-2 neighbors (among sequences collected in the early days of the pandemic). Panel b shows the geographic extent of the habitats of the top four most frequently occurring species among the list shown in a(ii). Also, the location of Wuhan, China, ground zero for COVID-19 is shown. Panel c plots the lower bound on log-likelihood of various sequences to their nearest neighbors over the time of collection, suggesting a trend of increasing risk over time, and across hosts, as evidenced by a nearly constant gradient LOWESS fit (black line) with 99% confidence bounds. Finally, panel d shows the normalized footprint of risk-mediating hosts from overlapping the geographic extents of the habitats of all species from the list in a (ii).
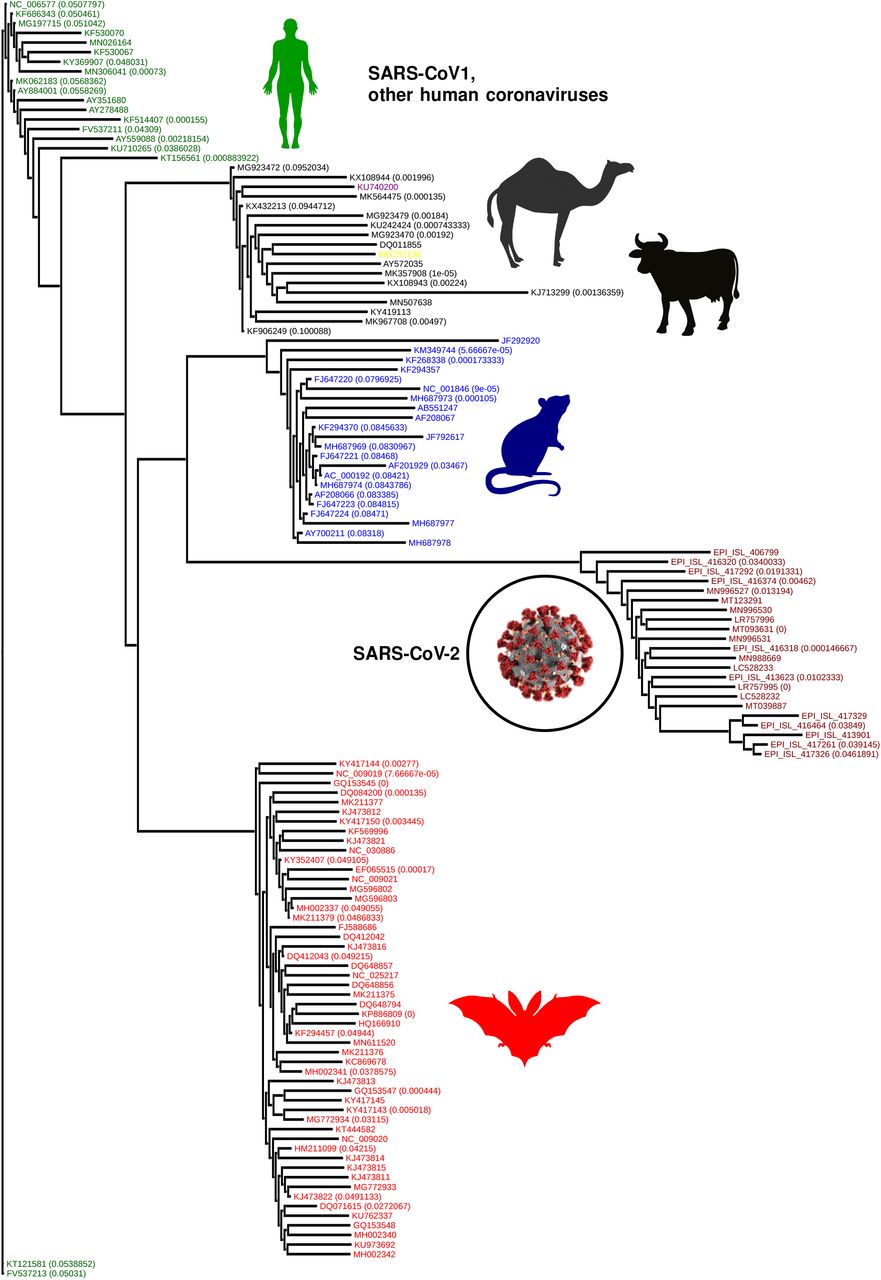
Importantly, the chronology of SARS-CoV-2 vs existing betacoronaviruses is automatically preserved, and we see the intriguing clade-hierarchy between bat, rodent and SARS-CoV-2 strains. Some branches of the phylogenetic tree is collapsed, and the numbers in bracket list the magnitude of q-distance within which leaves have been collapsed.
In Fig. 5c, we plot the collection times of animal samples against the average lower log-likelihood bound on spontaneous jump to SARS-CoV-2 sequences. We only show sequences that we find to be the top contenders based on their minimum distance from some SARS-CoV-2 sequence collected early in the pandemic (See Table XV). The dependence of the jump probability with collection date suggests risk-progression over time, from at least around 2011. We find that the early risky sequences are exclusively from rodents, and the risk elevates through late 2018, with the majority of the hosts switching from rodents to bats to human coronaviruses (OC43 and HKU1). This progression is further highlighted by a LOWESS regression 40 (local polynomial fit to the data points), which shows an almost constant gradient of risk elevation over the past decade. Additionally, overlapping habitats of the top species that pose this risk, we find a normalized habitat distribution (See Fig. 5d) consistent with the presumed ground zero of the outbreak (Wuhan, China).
Neighbors at the edge of emergence
Numbering Conversion to pdm09 and H3 Schemes
The quantitative assessments shown in Fig. 5 are impossible in the classical approach, and might suggest that the evolution of SARS-CoV-2 began in rodents, went through bats, and with final maturation in humans. Although we do not provide definitive proof of such a course of events (which realistically might never be found), and these assessments might be impacted by the sparsity of sequences available, the gradual elevation of risk through multiple host species, the overlapping habitats of those species, and the ability to quantify the minimum bounds on jump probability deserve serious consideration.
Limitations & Conclusion
Calculation of q-distance is currently limited to similar and aligned sequences, e.g. coronoviruses across different hosts, or time frames, or Influenza strains from different subtypes, hosts or seasons. Furthermore, we need a sufficient diversity of observed strains before we can successfully construct the Qnet model; simply having a large number of sequences is not enough, those observations must have sufficient diversity so that the underlying constraints are actually revealed. A multi-variate regression analysis (See SI Methods) indicates that the most important factor for our approach to succeed is indeed the diversity of the sequence dataset, i.e., how many sufficiently distinct sequences have we collected (See Tab. IV). Finally, in the context of strain forecasting, we note that simply reducing the edit distance from the dominant strain is not guaranteed to translate to a better immunological protection. Nevertheless consistent improvement in this metric achieved purely via computational means suggests the possibility of improvement over current practice.
In conclusion, we introduce a data-driven distance metric to track subtle deviations in sequences, and quantify jump risk of risky pathogens. Demonstrated ability of perdicting future flu strains via subtle variations in a limited set of immunologically important residues suggest that the tools developed here could be essential in preempting and actionably mitigating the next pandemic.
Data Management
Models generated in this study is included as supplementary material, and working software is publicly available at https://pypi.org/project/quasinet/. Accession numbers of all sequences used, and acknowledgement documentation for GISAID sequences in also available as supplementary information.
Data Availability
Models generated in this study is included as supplementary material, and working software is publicly available at https://pypi.org/project/quasinet/. Accession numbers of all sequences used, and acknowledgement documentation for GISAID sequences in also available as supplementary information.
https://github.com/zeroknowledgediscovery/quasinet/tree/master/examples
Supplementary Text
SI Methods
Data Source
In this study, we use sequences for the spike (S) protein on betacoronaviruses 1, which plays a crucial role in host cellular entry, and the Hemaglutinnin (HA) and Neuraminidase (NA) for Influenza A (for subtypes H1N1 and H3N2), which are key enablers of cellular entry and exit mechanisms respectively 2. We use two sequences databases: 1)National Center for Biotechnology Information (NCBI) virus 3 and 2) GISAID 4 databases. The former is a community portal for viral sequence data, aiming to increase the usability of data archived in various NCBI repositories. GISAID has a somewhat more restricted user agreement, and use of GISAID data in an analysis requires acknowledgment of the contributions of both the Submitting and the Originating laboratories (Corresponding acknowledgment tables are included as Supplementary files). We use a total of 30,204 sequences in our analysis (See Tab. III).
Next, we briefly describe the details of the computational framework.
Qnet Framework
In defining the q-distance, we do not assume that the mutational variations at the individual indices of a genomic sequence are independent (See Fig 1a in the main text). Irrespective of whether mutations are truly random 5, since only certain combinations of individual mutations are viable, individual mutations across a genomic sequence replicating in the wild appear constrained, which is what is explicitly modeled in our approach. The mathematical form of our metric is not arbitrary; JS divergence is a symmetricised version of the more common KL divergence 6 between distributions, and among different possibilities, the q-distance is the simplest metric such that the likelihood of a spontaneous jump (See Eq. (9) in Methods) is provably bounded above and below by simple exponential functions of the q-distance.
Consider a set of random variables X = {Xi}, with, i ∈{1,…,N}, each taking value from the respective sets Σi. A sample  is an ordered N-tuple, consisting of a realization of each of the variables Xi with the ith entry xi being the realization of random variable Xi. We use the notation x−i and xi,< to denote:
is an ordered N-tuple, consisting of a realization of each of the variables Xi with the ith entry xi being the realization of random variable Xi. We use the notation x−i and xi,< to denote:

 Also, 𝒟(S) denotes the set of probability measures on a set S, e.g., 𝒟(Σi) is the set of distributions on Σi.
Also, 𝒟(S) denotes the set of probability measures on a set S, e.g., 𝒟(Σi) is the set of distributions on Σi.
We note that X defines a random field over the index set {1, …, N}. Also, to clarify the biological picture, we refer to the sample x as an amino acid or nucleotide sequence, identifying the entry at each index with the corresponding protein residue or the nucleotide base pair.
For a random field X = {Xi} indexed by i ∈ {1, …, N}, the Qnet is defined to be the set of predictors Φ = {Φi}, i.e., we have:
 where for a sequence x, Φi(x−i) estimates the distribution of Xi on the set Σi.
where for a sequence x, Φi(x−i) estimates the distribution of Xi on the set Σi.
We use conditional inference trees as models for predictors 7, although more general models are possible.
Qnet Induced Biology-Aware Distance Between Strains
Given two sequences  , such that x, y are drawn from the populations P, Q inducing the Qnet ΦP, ΦQ, respectively, we define a pseudo-metric θ(x, y), as follows:
, such that x, y are drawn from the populations P, Q inducing the Qnet ΦP, ΦQ, respectively, we define a pseudo-metric θ(x, y), as follows:
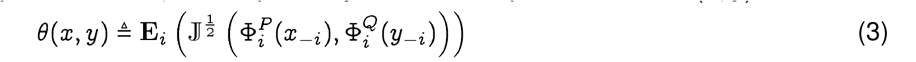 where 𝕁 (·, ·) is the Jensen-Shannon divergence8 and Ei indicates ation over the indices.
where 𝕁 (·, ·) is the Jensen-Shannon divergence8 and Ei indicates ation over the indices.
The square-root in the definition arises naturally from the bounds we are able to prove, and is dictated by the form of Pinsker’s inequality 6, making sure that we satisfy the requirement that distances along a path in a constructed phylogeny sum linearly. This allows standard algorithms to be used for phylogeny construction.
Importantly, the q-distance defined above is technically a pseudo-metric since distinct sequences can induce the same distributions over each index, and thus evaluate to have a zero distance. This is actually desirable, since we do not want our distance to be sensitive to changes that are not biologically relevant. The intuition is that not all sequence variations brought about by substitutions are equally important or likely. Even with no selection pressure, we might still see random variations at an index if such variations do not affect the replicative fitness. Under that scenario, the corresponding Φi will predict a flat distribution no matter what the input sequence is, thus contributing nothing to the overall distance. And even if two strains x, y have the same entry at some index i, the remaining residues might induce different distributions Φi based on the remote dependencies, i.e., the entries in x−i, y−i. Also, it matters if the sequences come from two different background populations P, Q, i.e., if the induced Qnets ΦP, ΦQ are different. Thus, if we construct Qnets for H1N1 Influenza A separately for the collection years 2008 and 2009, then the same exact sequence collected in the respective years might have a non-zero distance between them, reflecting the fact that the background population the sequences arose from are different, inducing possibly different expected mutational tendencies.
Next, we induce a q-distance between a sequence and a population and between two populations.
Using the notion of Hausdorff metric between sets:


In-silico Corroboration of Qnet Constraints
We carry out in-silico experiments to corroborate that the constraints represented within an inferred Qnet are indeed reflective of the biology in play. To that effect, we compare the results of simulated mutational perturbations to sequences from our databases (for which we have already constructed Qnets), and then use NCBI BLAST (https://blast.ncbi.nlm.nih.gov/Blast.cgi) to identify if our perturbed sequences match with existing sequences in the databases (and if so, then where and how many matches they produce). The objective here is to compare such Qnet constrained perturbations against random variations. The results are shown in Fig. 3, where we find that in contrast to random variations, which rapidly diverge the trajectories, the Qnet constraints tend to produce smaller variance in the trajectories, maintain a high degree of match as we extend our trajectories, and produces matches closer in time to the collection time of the initial sequence — suggesting that the Qnet does indeed capture realistic constraints.
Significance Test for Population Membership & Progressive Drift in Population Characteristics
For our modeling to be reliable, we need a quantitative test of how well the Qnet represents the data and whether we need to re-calculate the predictors or we have sufficiently many sequences. Here, we formulate an explicit membership test to address this.
Given a population P inducing the Qnet ΦP and a sequence x, we can compute the membership probability of x:
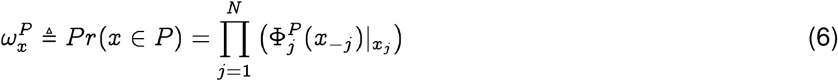
Note that xj is the jth entry in x, and is thus an element in the set Σj. Since we are mostly concerned with the case where Σj is a finite set, 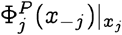 is the entry in the probability mass function corresponding to the element of Σj which appears at the jth index in sequence x.
is the entry in the probability mass function corresponding to the element of Σj which appears at the jth index in sequence x.
We can carry out this calculation for a sequence x known to be in the population P as well, which allows us to define the membership degree 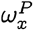 .
.
Let X be a random field representing a population P, ie.. X = x is a randomly drawn sequence from P. Then the membership degree wP is a function of the random variable X:
 Note that wP takes values in the unit interval [0, 1], and the probability x is a member of the population P is wP(X = x), denoted briefly as
Note that wP takes values in the unit interval [0, 1], and the probability x is a member of the population P is wP(X = x), denoted briefly as 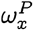 or wX if P is clear from context.
or wX if P is clear from context.
Since wP(X) is a random variable, we can now compute sets of sequences that better represent the population P, and ones that are on the fringe. We can also evaluate using a pre-specified significance-level if a particular sequence is not from the population P, thus identifying if we need to recompute the predictors Φ, or split the base population. We can set up a hypothesis testing scenario to determine if sequences are indeed from a test population, as follows:
Significance Test for the Validity of Inferred Model
Given a population P, inducing a Qnet ΦP, and a sequence x, we assume the null hypothesis is x ∉ P. We reject the null hypothesis at a pre-specified significance α, if
 The fraction of newly observed sequences that do not reject the null hypothesis can then be used as an estimate of the species-specific divergence in population characteristics.
The fraction of newly observed sequences that do not reject the null hypothesis can then be used as an estimate of the species-specific divergence in population characteristics.
The membership degrees for the SARS-CoV-2 sequences in the early days of the pandemic, with respect to our constructed Qnet, is shown in Fig. 4. We find that the distribution of membership degrees is very stable, and almost has no change when we add more sequences (Fig. 4b). In addition, as we collect more sequences, the p-value improves (Fig. 4c), and stabilizes to about 0.02 giving us confidence in the validity of our model.
Theoretical Probability Bounds
The Qnet framework allows us to rigorously compute bounds on several quantities of interest, and these bounds are rigorously established in Theorem 1. The fundamental bound is on the probability of a spontaneous change of one strain to another, brought about by chance mutations. While any sequence of mutations is equally likely, the “fitness” of the resultant strain, or the probability that it will even result in a viable strain, is not. Thus the necessity of preserving function dictates that not all random changes are viable, and the probability of observing some trajectories through the sequence space are far greater than others. The Qnet framework allows us to explore this constrained dynamics, as revealed by a sufficiently large set of genomic sequences. With the exponentially exploding number of possibilities in the sequence space, it is computationally intractable to exhaustively model this dynamics. Nevertheless, we can constrain the possibilities using the patterns distilled by the Qnet construction.
We show in Theorem 1 that at a significance level α, with a sequence length N, the probability of spontaneous jump of sequence x from population P to sequence y in population Q, Pr(x → y), is bounded by:
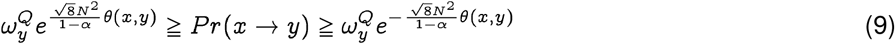 where
where 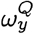 is the membership probability of strain y in the target population.
is the membership probability of strain y in the target population.
The ability to estimate the probability of spontaneous jump between sequences in terms of 0 has crucial implications. It allows us to 1) construct a new phylogeny that directly relates the probability of jumps rather than the number of mutations between descendants. 2) simulate realistic trajectories in the sequence space from any given initial strain, and 3) estimate drift in the sequence space by analyzing the statistical characteristics of the diffusion occurring in the strain space.
More Fit in the Target Population Makes Jump More Probable
As an immediate consequence of Eq. (9), we can argue that the lower bound of the likelihood of a jump to a target sequence is higher if the final sequence is more fit in the target population. Note that the membership degree by definition quantifies the probability of generating a sequence from our inferred qnet, and since we are far more likely to collect dominant strains when we survey a population, it follows that the membership degree is related to the qualitative notion of fitness.
Conversely, as the fitness of the initial strain (in the neighborhood of 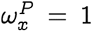 ) measured by its membership degree falls, the minimum probability of going through a spontaneous jump is higher. We can see this by first noting that for x ≠ y:
) measured by its membership degree falls, the minimum probability of going through a spontaneous jump is higher. We can see this by first noting that for x ≠ y:
 which follows since each term in the product on the right hand side in Eq. (22) is either zero or one if
which follows since each term in the product on the right hand side in Eq. (22) is either zero or one if 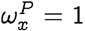 , and there is at least one zero since x ≠ y. To see that the suppression of probability of jump is not simply true if
, and there is at least one zero since x ≠ y. To see that the suppression of probability of jump is not simply true if 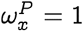 but also in the neighborhood, note that:
but also in the neighborhood, note that:
 which implies that in the neighborhood of
which implies that in the neighborhood of 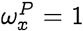 , we have:
, we have:
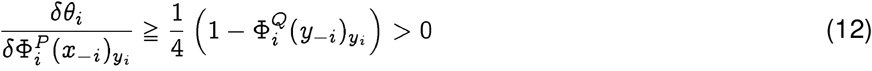 implying that the distance decreases as the membership degree of x falls, thus lowering the lower bound on the probability of a spontaneous jump. The argument is not necessarily true if x is not in the neighborhood of
implying that the distance decreases as the membership degree of x falls, thus lowering the lower bound on the probability of a spontaneous jump. The argument is not necessarily true if x is not in the neighborhood of  in the first place, and so is of lesser practical interest.
in the first place, and so is of lesser practical interest.
Next, we briefly describe the key applications of the Qnet framework explored in this study, highlighting the predictions made and validations obtained.
A Biology Aware Phylogeny
There are more than one computational approach to construct phylogenies, but a majority of these algorithms require a notion of distance between biological sequences, and the edit distance is the one that is most commonly used to construct phylogenies. Using the Qnet induced distance described earlier we can construct phylogenetic trees distinct from those obtained using the classical metric. More importantly, the qnet induced phylogeny is reflective of evolutionary change in a manner that conventional trees are not. As we follow a path in an Q-phylogeny, we can explicitly compute the probability of the changes represented by that path. This probability is bounded above and below by a function of the total path length, i.e., the sum of the q-distances along the path. We can show that for the path x = x° → … xk → … xm = z, we have:
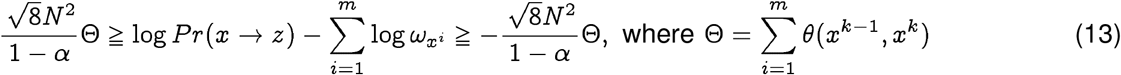 Considering only the lower bound,
Considering only the lower bound,
 where
where  is the membership probability in the base population of the strain xi. Thus, we relate closer phylogenetic distance to explicit probability of spontaneous jump. Note that the definition of the distance function in the Qnet framework allows the summation in Eq. (13), allowing standard tools to construct the phylogenetic tree.
is the membership probability in the base population of the strain xi. Thus, we relate closer phylogenetic distance to explicit probability of spontaneous jump. Note that the definition of the distance function in the Qnet framework allows the summation in Eq. (13), allowing standard tools to construct the phylogenetic tree.
Application 1: Predicting Seasonal Strains
Analyzing the distribution of sequences using the q-distance allows us to estimate seasonal drift, which is particularly applicable to Influenza and Influenza-like viruses for which periodic adjustments of vaccine components are necessary to account for antigenic variations.
Our prediction is based on the following intuition: since the probability of spontaneous jump to a strain further away in the q-distance is exponentially lower, the q-centroid of the strain distribution (the centroid computed in the q-distance metric) observed over a season is expected to move slowly, and will be close to the dominant strain in the next season. Thus, we estimate the predicted dominant strain 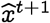 at time t + 1, as a function of the observed population at time t as follows:
at time t + 1, as a function of the observed population at time t as follows:
 where Pt is the sequence population at time t. Here the unit of time is chosen to reflect the appropriate frequency over which vaccine components are re-assessed. In the case of Influenza, this is typically one year. Using this formulation, we test if the predicted strains actually turn out to be closer to the dominant strain in the classical edit distance, when compared against the WHO vaccine recommendation for that season. Our results in Fig. 3 in the main text show that our hypothesis turns out to be correct with few exceptions.
where Pt is the sequence population at time t. Here the unit of time is chosen to reflect the appropriate frequency over which vaccine components are re-assessed. In the case of Influenza, this is typically one year. Using this formulation, we test if the predicted strains actually turn out to be closer to the dominant strain in the classical edit distance, when compared against the WHO vaccine recommendation for that season. Our results in Fig. 3 in the main text show that our hypothesis turns out to be correct with few exceptions.
Application 2: Identifying Animal Host of Progenitor Sequence
The Qnet based phylogenetic analysis provides a significantly more reliable history of the progenitor strain. In fact, using Eq. (9) we have for the pandemic strain y ∈ H, and animal strain x ∈ P:
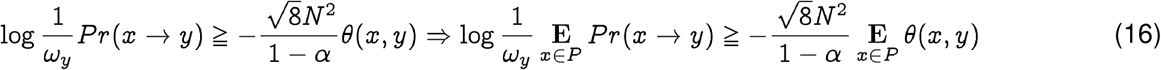 we have constants C, C′ such that
we have constants C, C′ such that
 Note that since we always know N, we can calculate C′ without the knowledge of the pandemic strain y. In the case of the SARS-CoV-2 spike protein, at 95% significance, we have:
Note that since we always know N, we can calculate C′ without the knowledge of the pandemic strain y. In the case of the SARS-CoV-2 spike protein, at 95% significance, we have:
 Note that if we have the pandemic strain and are aiming to compare and contrast the likelihood of jump from potential hosts after we already have the emergence event, then we can explicitly calculate C. For SARS-CoV-2, this estimate is 4, 805.4 (See Fig. 4), which leads to the following linear relationship between log-likelihood of emergence and the average distance calculated in the Qnet framework:
Note that if we have the pandemic strain and are aiming to compare and contrast the likelihood of jump from potential hosts after we already have the emergence event, then we can explicitly calculate C. For SARS-CoV-2, this estimate is 4, 805.4 (See Fig. 4), which leads to the following linear relationship between log-likelihood of emergence and the average distance calculated in the Qnet framework:
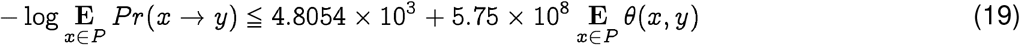 thus providing a quantitative ranking of potential progenitor hosts. It follows from Eq. (19) that for rank-ordering potential hosts, we need to only consider the average distance Ex∈ P θ(x, y). It also follows from the relative magnitudes of the constants in the case of SARS-CoV-2, that we can ignore C and have approximately:
thus providing a quantitative ranking of potential progenitor hosts. It follows from Eq. (19) that for rank-ordering potential hosts, we need to only consider the average distance Ex∈ P θ(x, y). It also follows from the relative magnitudes of the constants in the case of SARS-CoV-2, that we can ignore C and have approximately:
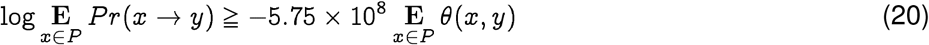 Note that at least in the case of SARS-CoV-2, the fitness term is approximately five orders of magnitude smaller, which implies the jumps probabilities are roughly symmetric. But this is not required to be true in general. At the same time, it is important to note that the probability of jump from strain x to strain y vs the reverse is actually asymmetric due to the contribution from the population-specific membership degree.
Note that at least in the case of SARS-CoV-2, the fitness term is approximately five orders of magnitude smaller, which implies the jumps probabilities are roughly symmetric. But this is not required to be true in general. At the same time, it is important to note that the probability of jump from strain x to strain y vs the reverse is actually asymmetric due to the contribution from the population-specific membership degree.
Proof of Probability Bounds
Theorem 1 (Probability Bound). Given a sequence x of length N that transitions to a strain y ∈Q, we have the following bounds at significance level α.
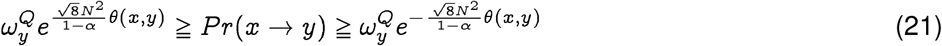 where
where 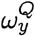 is the membership probability of strain y in the target population Q(See Def. 4), and θ(x, y) is the q-distance between x, y(See Def. 2).
is the membership probability of strain y in the target population Q(See Def. 4), and θ(x, y) is the q-distance between x, y(See Def. 2).
Proof. Using Sanov’s theorem6 on large deviations, we conclude that the probability of spontaneous jump from strain x ∈P to strain y ∈ Q, with the possibility P ≠ Q, is given by:
 Writing the factors on the right hand side as:
Writing the factors on the right hand side as:
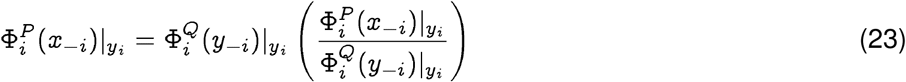 we note that
we note that 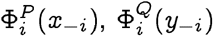 , are distributions on the same index i, and hence:
, are distributions on the same index i, and hence:
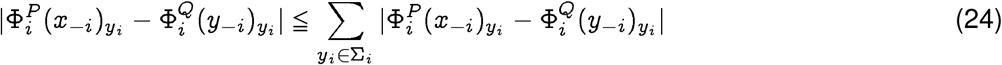 Using a standard refinement of Pinsker’s inequality 9, and the relationship of Jensen-Shannon divergence with total variation, we get:
Using a standard refinement of Pinsker’s inequality 9, and the relationship of Jensen-Shannon divergence with total variation, we get:
 where a0 is the smallest non-zero probability value of generating the entry at any index. We will see that this parameter is related to statistical significance of our bounds. First, we can formulate a lower bound as follows:
where a0 is the smallest non-zero probability value of generating the entry at any index. We will see that this parameter is related to statistical significance of our bounds. First, we can formulate a lower bound as follows:
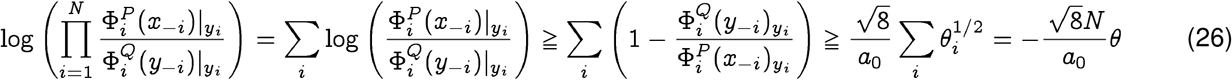 Similarly, the upper bound may be derived as:
Similarly, the upper bound may be derived as:
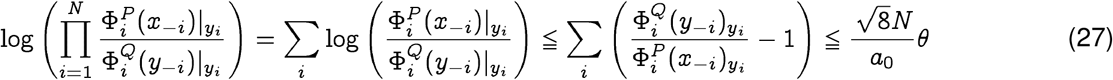 Combining Eqs. 26 and 27, we conclude:
Combining Eqs. 26 and 27, we conclude:
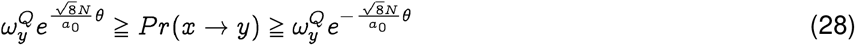 Now, interpreting a0 as the probability of generating an unlikely event below our desired threshold(i.e. a “failure”), we note that the probability of generating at least one such event is given by 1 − (1 − a0)N. Hence if α is the pre-specified significance level, we have for N >> 1:
Now, interpreting a0 as the probability of generating an unlikely event below our desired threshold(i.e. a “failure”), we note that the probability of generating at least one such event is given by 1 − (1 − a0)N. Hence if α is the pre-specified significance level, we have for N >> 1:
 Hence, we conclude, that at significance level ≧α, we have the bounds:
Hence, we conclude, that at significance level ≧α, we have the bounds:
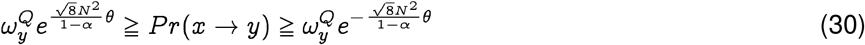 □
□
This bound can be rewritten in terms of the log-likelihood of the spontaneous jump and constants independent of the initial sequence x as:
 where the constants are given by:
where the constants are given by:


Multivariate Regression to Identify Factors in Strain Prediction
We investigate the key factors that contribute to our successful prediction of the dominant strain in the next season. We carry out a multivariate regression with data diversity, the complexity of inferred Qnet and the edit distance of the WHO recommendation from the dominant strain as independent variables. Here we define data diversity as the number of clusters we have in the input set of sequences, such that any two sequences five or less mutations apart are in the same cluster. Qnet complexity is measured by the number of decision nodes in the component decision trees of the recursive forest.
We select several plausible structures of the regression equation, and in each case conclude that data diversity has the most important and statistically significant contribution (See Tab. IV).

The quasispecies that circulates each season for each subtype is tightly distributed around the dominant strain on average.
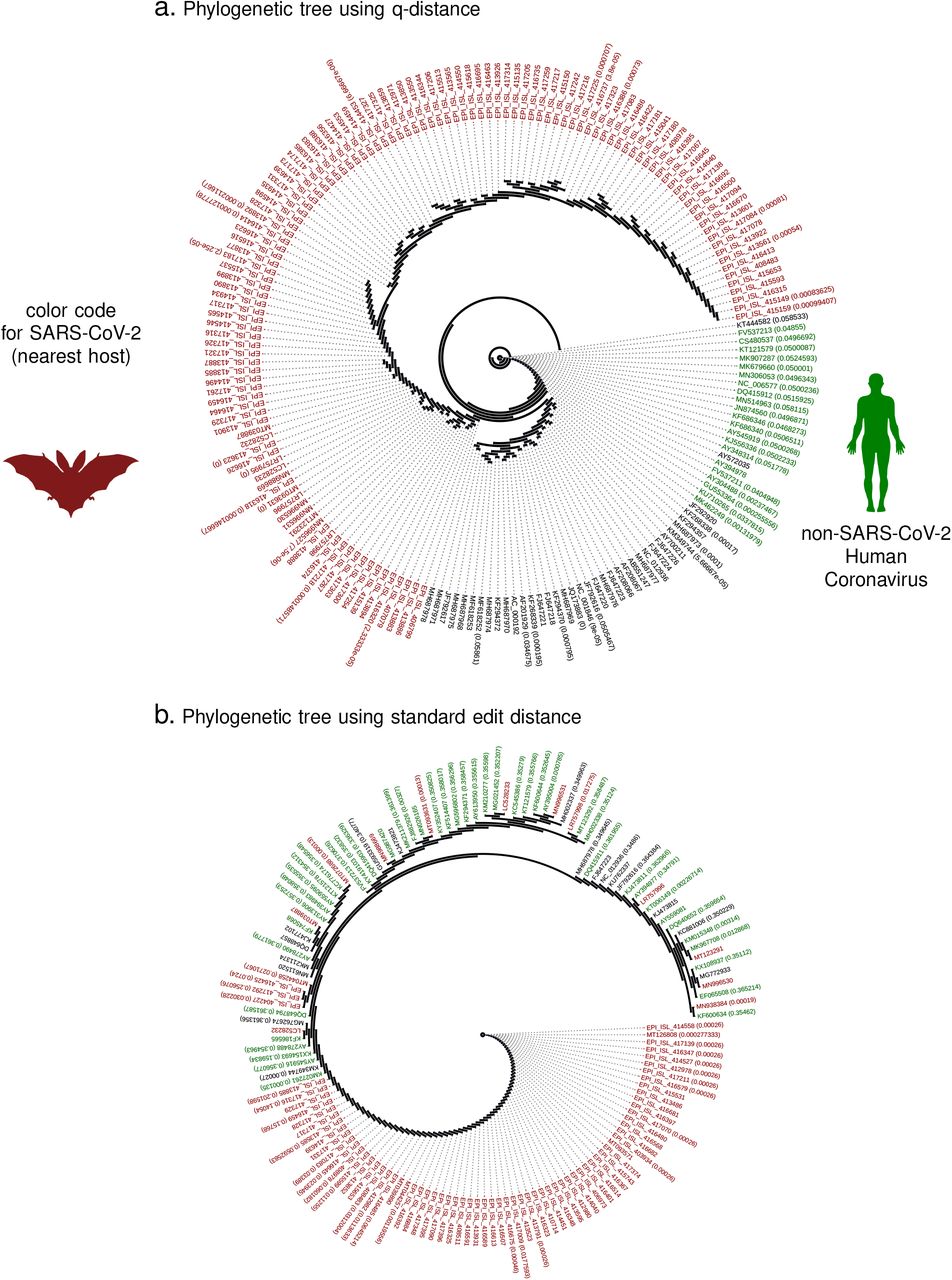
The numbers within brackets is the distance within which the specific branch is collapsed for visualization. The classical distance produces a phylogeny which clearly violates chronological ordering, arising the novel coronavirus appears before strains that have been collected years before, including the SARs-1 strains. The new distance using Qnet is shown to automatically respect this known ordering.

Panel a illustrates that the Qnet induced modeling of evolutionary trajectories initiated from known haemagglutinnin (HA) sequences are distinct from random paths in the strain space. In particular, random trajectories have more variance, and more importantly, diverge to different regions of the landscape compared to Qnet predictions. Panel b-e show that unconstrained Q-sampling produces sequences maintain a higher degree of similarity to known sequences, as verified by blasting against known HA sequences, have a smaller rate of growth of variance, and produce matches in closer time frames to the initial sequence. Panel c shows that this is not due to simply restricting the mutational variations, which increases rapidly in both the Qnet and the classical metric.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The membership degree quantifies the likelihood that a test sequence actually is generated by the inferred model, i.e., the Qnet (See Methods for definition of membership degree).
Acknowledgments
This work is funded in part by the Defense Advanced Research Projects Agency (DARPA) project #FP070943-01-PR. The claims made in this study do not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.
References




