
Abstract
Effective responses to the COVID-19 pandemic require reliable estimates of actual cases and deaths, and models that incorporate behavioral factors including differential priorities for allocating limited testing capacity, heterogeneous risk perceptions and resulting contact reductions, improved treatment, and adherence fatigue. We develop a behavioral dynamic model integrating these factors with asymptomatic transmission, disease acuity, and hospital capacity. Using a hierarchical Bayesian framework we estimate the model parameters with a panel dataset spanning all 91 nations with reliable testing data. Cumulative cases and deaths through 30 October 2020 are estimated to be 8.5 and 1.4 times greater than official reports, yielding an overall infection fatality rate (IFR) of 0.48%, with wide variation across nations and significant decline in IFR over time. Adherence fatigue is estimated to have increased cumulative cases by 61% through October 2020. Scenarios through March 2021 show modest policy interventions and behavior change could reduce cumulative cases ≈18%. The model endogenously generates the multiple waves of infection and mortality observed in many nations as behavioral responses to perceived risk cause the reproduction number to fluctuate around 1, but with death rates that vary by two orders of magnitude depending on responsiveness to perceived risks.
One Sentence Summary COVID-19 under-reporting is large, varies widely across nations, and strongly conditions projected outbreak dynamics.
Introduction
Effective responses to the COVID-19 pandemic require an understanding of its global magnitude, and how behavioral responses to its risks condition dynamics and outcomes. Yet more than eight months after WHO declared a global pandemic, the true number of cases and infection fatality rate remain uncertain, and the experience of different nations varies widely. As of late October 2020, countries have reported cumulative cases ranging between 5.42 and 4790 per 100,000, and case fatality rates between 0.05% and 9.9%. Asymptomatic infection (Gudbjartsson, Helgason et al. 2020), variation in testing rates across countries (Roser, Ritchie et al. 2020), and false negatives (Fang, Zhang et al. 2020, Li, Yao et al. 2020, Wang, Xu et al. 2020) complicate assessment of the true magnitude of the pandemic from official data. The inference problem also requires disentangling other explanatory mechanisms: (i) differences in population density and social networks create variations in the effective reproduction number, RE; (ii) risk perceptions, behavior change, adherence fatigue, and policy responses alter transmission rates endogenously; (iii) testing is prioritized based on symptoms and risk factors, so detection depends on both testing rates and current prevalence (Onder, Rezza et al. 2020); (iv) limited hospital capacity is allocated based on case severity, influencing fatality rates; (v) age, socioeconomic status, comorbidities, differential adherence to non-pharmaceutical interventions (NPIs) such as social distancing and masking by at-risk populations, and improvements in treatment affect transmission risk and case severity (Guan, Ni et al. 2020, O’Driscoll, Dos Santos et al. 2020, Wu and McGoogan 2020); (vi) weather may play a role in transmission (Xu, Rahmandad et al. 2020); and (vii) all these vary across nations.
Prior studies have shed light on important parts of the puzzle by estimating basic epidemiological parameters and IFR in well-controlled settings (Russell, Hellewell et al. 2020), assessing the asymptomatic fraction and prevalence in specific populations (Hao, Cheng et al. 2020, Li, Pei et al. 2020, Mizumoto, Kagaya et al. 2020, Salje, Tran Kiem et al. 2020, Sutton, Fuchs et al. 2020), estimating the role of undocumented infections (Ghaffarzadegan and Rahmandad 2020, Li, Pei et al. 2020, Moghadas, Fitzpatrick et al. 2020), illuminating the effects of various NPIs on expected future cases (Chinazzi, Davis et al. 2020, Flaxman, Mishra et al. 2020, Hsiang, Allen et al. 2020, Kissler, Tedijanto et al. 2020, Ruktanonchai, Floyd et al. 2020, Walker, Whittaker et al. 2020, Wu, Leung et al. 2020), and contrasting risks and healthcare demands across countries and populations (Britton, Ball et al. 2020, Gatto, Bertuzzo et al. 2020, Moghadas, Shoukat et al. 2020, Struben 2020, Walker, Whittaker et al. 2020). Yet we lack a global view of the pandemic that is simultaneously consistent with these more focused findings, explains the substantial variation in official case and death rates across countries, and offers projections accounting for endogenous behavioral responses underpinning multiple waves of incidence (Lopez and Rodo 2020) and mortality.
Model and estimation
We use a multi-country modified SEIR model to simultaneously estimate SARS-CoV-2 transmission across 91 countries. For each country, the model tracks the population from susceptible through presymptomatic, infected, and recovered or deceased states, with explicit states for those whose cases are detected or undetected, and hospitalized or not (Figure 1).

Expanded SEIR model for each country. Key state variables denoted by boxes.
Besides its multi-country scope, the model includes three novel features. First, tests are allocated to individuals based on symptom severity relative to available testing capacity. Individuals with more severe symptoms, including those with COVID-19 and those without but presenting with similar symptoms or risk factors, e.g., frontline healthcare workers, get priority for testing. We model symptom severity with a zero-inflated Poisson distribution, where zero severity indicates asymptomatic infection (S1 and Figure S3 provide details). Prioritized test allocation determines the ascertainment rate of COVID-positive cases as a function of the current testing rate and prevalence. It also results in different average COVID severity in the tested vs. untested populations (Rahmandad and Hu 2010). We also account for false negatives from tests (Fang, Zhang et al. 2020, Wang, Xu et al. 2020).
Second, hospital capacity is allocated between COVID-positive cases and demand from non-COVID patients. The COVID infection fatality rate therefore depends endogenously on the adequacy of hospital capacity relative to the burden of severe cases, along with the age distribution of the population (Guan, Ni et al. 2020, O’Driscoll, Dos Santos et al. 2020, Wu and McGoogan 2020). Furthermore, we account for reductions in IFR that may result improved treatments, deaths of high-risk populations such as the elderly and those with comorbidities in the first wave of the pandemic, heterogeneous adherence to NPIs as higher-risk subpopulations perceive greater risk than those lacking risk factors, shifting incidence toward younger, lower-risk people, and other factors.
Third, the hazard rate of transmission responds to the perceived risk of COVID. Perceived risk reduces transmission through NPIs, from social distancing and masking to lockdowns. Perceived risk is based on subjective perceptions of the hazard of death, which respond with a lag to both official data (reported in the media) and actual deaths (gleaned from personal experience and word of mouth). Rising mortality eventually increases perceived risk, driving the hazard rate of transmission down, while declining cases and deaths can lead to the erosion of perceived risk, potentially leading to rebound outbreaks. We also account for potential decline in the responsiveness of communities to perceived risk as a result of adherence fatigue.
Model parameters are specified based on prior literature and formal estimation. Parameters specified from the literature include the incubation period (mean μ = 5 days (Guan, Ni et al. 2020, Linton, Kobayashi et al. 2020)), onset-to-detection delay (μ = 5 days (Linton, Kobayashi et al. 2020)), postonset illness duration (μ = 15 days (Guan, Ni et al. 2020)), and the sensitivity of RT-PCR-based testing (70% (Fang, Zhang et al. 2020, Wang, Xu et al. 2020)). Sensitivity analysis is presented in S7.
We estimate the remaining parameters using a panel of data covering all nations with at least 1000 confirmed COVID-19 cases by 30 October 2020 and sufficient testing data to enable parameter estimation, a total of 91 nations spanning 4.87 billion people. These include all disease hotspots to date, with three notable exceptions, China, Brazil, and Argentina, for which reliable testing data are not available. The panel includes reported daily testing rates, reported COVID cases and deaths, and all-cause mortality (where available), along with population, population density, age distribution, hospital capacity, and daily meteorological data. Estimation is by maximum likelihood, using a negative binomial likelihood function. To avoid overfitting, we do not use any time-varying parameters in the estimation. We also use a hierarchical Bayesian framework (Gelman and Hill 2006) to estimate country-level heterogeneity in each model parameter using informed priors on cross-country parameter variances (see S7 for sensitivity analysis on priors). For example, the asymptomatic fraction of cases and other parameters representing biological processes should have low cross-national variance, whereas parameters specifying risk perceptions and responses are expected to vary more widely. These choices reduce the quality of fit for some nations compared to estimates that allow the parameters for each nation to be independent, but enhance the generalizability of parameter estimates and the robustness of projections. Uncertainties are quantified using a Markov Chain Monte Carlo method designed for high dimensional parameter spaces (Vrugt, Ter Braak et al. 2009) (details in S2).
Building confidence in the model
Estimating parameters for a complex model and assessing its ability to capture important real-world processes are both critical and challenging. Before discussing results we present three sets of analyses addressing these challenges, and later report extensive sensitivity analyses to quantify various uncertainties. First, we validated the estimation framework using synthetic data generated by simulating the model with known parameters and adding auto-correlated noise in infection rates and IFR. Our estimation procedure accurately identifies the vast majority of parameters in the synthetic dataset. The absolute error between the estimated and true values was significantly smaller than the estimated uncertainty (median error 12% of the 95% credible interval (CI), with 92% of the absolute errors less than half the 95% CI (see S3 for details).
Second, we assess in- and out-of-sample accuracy of model projections. Figure 2 compares actual and simulated reported daily new cases and deaths for 18 larger countries. Panel A reports fits for both deaths and cases using data through 30 October 2020. Panel B shows out-of-sample prediction performance for reported infections after fitting the model to data through 10 August 2020. S5 and S6 report the full sample. Over the full set of nations and full sample, Mean Absolute Errors Normalized by the mean of the actual data (MAEN) are 5.6% and 3.8% for cumulative infections and deaths, respectively, and less than 20% for 62 (68.1%) and 69 (75.8%) of the 91 nations, despite wide variation in the size and dynamics of national outbreaks, from those nearly quenched (New Zealand, Thailand), to those still growing (Bulgaria, Poland) to those exhibiting multiple waves (Iran, Israel, USA). R2 exceeds 0.9 for 56% of 364 country-specific time series and exceeds 0.5 for 86%. Aggregation of within-nation heterogeneities reduces the quality of fit in a few countries. For example, we do not explicitly model outbreaks concentrated among subpopulations such as migrant workers (important in e.g., Qatar, Singapore) or nursing homes (important in, e.g., Belgium, France). The coupling of parameters across countries also limits fits for outliers. Nevertheless, 94% and 97% of official infection and death rates fall within the 95% uncertainty intervals for in-sample projections.

Model projections vs. data. A) Simulated (thick solid) vs. data (dotted and dashed) for reported cases (blue; right axis, thousands/day) and deaths (red; left axis; deaths/day) in countries with more than 40 million population and 300,000 confirmed cases by 30 October 2020 and testing data until at least September 2020. B) Out of sample death predictions for the same countries based on estimates with data until August 10, 2020 (blue vertical line). Numbers on each graph show fraction of predicted data inside the 95% confidence interval.
The model provides reasonable out-of-sample predictions (Figure 2B): across all predictions, 71% and 76% of observations for infections and deaths, respectively, fall within the 95% prediction intervals over the last 80-day period. Out-of-sample projections are limited by the fact that by August 10th the majority of countries had not experienced second waves or significant adherence fatigue, offering few clues in the data for these behavioral feedbacks. Despite these challenges, the model correctly predicts the existence of second waves in the majority of countries, and in many cases correctly predicts the timing and magnitude as well (see S6 for details).
Finally, we compare model estimates of actual cumulative cases against available national-level estimates from serological surveys. Few national seroprevalence studies include reliably representative samples. Nevertheless, using the SeroTracker project (Arora, Joseph et al. 2020) we identified nine country-level meta-estimates for actual prevalence. Figure 3 compares those meata-analytic estimates against official data from testing and model estimates. Seroprevalence and official counts vary by an order of magnitude or more. Model estimates are very close for eight of the nine seroprevalence estimates (model estimates are significantly higher than the seroprevalence estimate for Spain). Note that seroprevalence data were not used in model specification or parameter estimation.

Comparison of cumulative percentage of cases based on official data (black circles), seroprevalence estimates (blue circles with 95% CIs), and model estimates (red squares with 95% CIs) for 9 countries at various dates.
Results
Quantifying under-reporting
We find COVID-19 prevalence and deaths are widely under-reported. Across the 91 nations, the estimated ratio of actual to reported cumulative cases (through 30 October 2020) is 8.5, corresponding to 314 million undetected cases (95% CI 295-321 million). Underreporting varies substantially across nations (10th-90th percentile range 3.2-22; Figure 4).

Ratio of estimated to reported cases (blue circles) and deaths (red squares) by country; log scale.
Underreporting is due in part to the large fraction of asymptomatic infections, estimated at 51%, consistent with many other estimates (Oran and Topol 2020). The mean inter-quartile range, MIQR, of the credible intervals in the national estimates is 1.3%. However, the estimated asymptomatic fraction varies little across nations (standard deviation, σ = 0.6%) and therefore cannot explain the large cross-national variation in the ratio of estimated to reported cases (Figure 4).
The extent of underestimation depends primarily on testing capacity and how it is utilized. If every person could be tested the estimated ratio of actual to reported cases would be approximately 1.43, given assumed test sensitivity of ≈70% (Fang, Zhang et al. 2020, Wang, Xu et al. 2020). Testing capacity is limited, however. When testing capacity is small relative to the need, individuals presenting with COVID and COVID-like symptoms are prioritized, along with at-risk groups such as health care providers. Consequently, a larger proportion of those tested will be positive, but many infected individuals will go undetected, increasing the degree of underestimation, as seen in e.g. Mexico. Conversely, when testing capacity is high relative to the population, more of those infected will be identified, as seen in e.g. New Zealand.
COVID-19 deaths are also underreported (Figure 4). We estimate 1.35 (1.30-1.38) million deaths by 30 October 2020 across the 91 countries, 1.4 times larger than reported, with large cross-national variance (10th-90th percentile range 1.2-2.4). Results are consistent with some country-specific estimates (Weinberger, Chen et al. 2020, Woolf, Chapman et al. 2020). Underreporting is significantly less for deaths than cases because deaths are concentrated among severe cases who are more likely to have been tested, and post-mortem testing corrects some of the undercount.
Trends and Fluctuations in Cases and Mortality
National IFR estimates are reported in Figure 5A. IFR across the 91 nations through 30 October 2020 is 0.48% (CI: 0.46%-0.51%), with wide cross-national variation, from 0.04% (CI: 0.04%-0.05%; Singapore) to 1.68% (CI: 1.31%-1.74%; France), a range similar to estimates across counties in the USA (Basu 2020). These variations arise in the model from differences in age distribution (O’Driscoll, Dos Santos et al. 2020, Wu and McGoogan 2020) and the adequacy of health care. Consistent with prior estimates (Walker, Whittaker et al. 2020), we find that hospitalization can reduce the age- and severity-adjusted risk of death to 39% of the rate without treatment, but with large cross-national variation (σ=19%; MIQR: 7%). Simulated IFR varies endogenously over time, exhibiting fluctuations around an overall declining trend (Figure 5B). The fluctuations are due to variations in the adequacy of treatment capacity, with IFR rising when surging caseloads overtake hospital capacity. The peak in global IFR in spring 2020 arose as cases overwhelmed hospital capacity in several nations, including many European countries with older populations. Since then, many—but not all—countries show notable reductions in IFR, due to factors including (i) improvements in treatments and greater availability of ventilators and PPE; (ii) heterogeneity in cases as some in the highest-risk populations were lost in the early waves; and (iii) heterogeneity in risk perceptions and responses as older, high-risk individuals adhere more strongly to NPIs including distancing and masking compared those who perceive less personal risk, resulting in a decline in the average age of new confirmed cases in many nations. We cannot tease apart these different processes, but estimate that their combined effect reduced IFR by 24.8% (σ=20.4%; MIQR=10.9%) for every doubling in cumulative cases. Despite the overall decline in IFR, hospital capacity shortages caused by renewed waves of infection increase IFR above the trend (e.g., India in June and July).

Fatality rates. A) Average estimated infection fatality rates (%) across countries. B) IFR trajectories over time across full sample and selected nations.
We also find significant heterogeneity across countries in the initial effective reproduction number, RE (median 2.97, IQR 2.43-4.26), reflecting differences in population density, social networks, and cultural practices (Figure S9 provides details). Importantly, RE changes over time as people and policymakers respond to perceived risk (Pan, Liu et al. 2020). We find behavioral and policy responses to the perceived risk of death reduce transmission and RE with a mean lag of 19 days, though with substantial cross-national variation (σ=25.9; MIQR: 5.1). These responses are relaxed as perceived risk falls, though more slowly (mean lag 118 days; σ=100; MIQR: 54). Importantly, we also find that extended periods of contact reduction, and the personal and economic hardship it causes, lead to “adherence fatigue”—a reduction in the impact of perceived risk on behaviors that reduce contacts, with an estimated average elasticity of 1.21 (σ=0.75; MIQR: 0.36). A counter-factual simulation (Figure 6, dotted line) shows that, absent adherence fatigue, total cases and deaths through 30 October 2020 would have been lower by 38% and −71307%, 195 (173-203) million and 964 (895-974) thousand, respectively.

Most likely estimate (solid lines) of cumulative cases (A) and deaths (B) compared with counterfactuals for scenario I, in which testing rises to 0.1% of population per day starting 11 March 2020 (dashed line); and scenario II with no adherence fatigue (dotted line). Thin lines show 95% CIs.
The model endogenously captures the multiple waves observed across many countries through 30 October despite their different magnitudes and timing (Figure 2A). These rebounds are due to lags in perception and responses to the risk of COVID-19: initial reductions in transmission eventually lower deaths, leading to lower adherence to NPIs as perceived risk gradually falls, setting the stage for renewed outbreaks. Rebound outbreaks are larger in nations where adherence fatigue is greater. Rebound waves are also larger where reductions in IFR are larger, because the decline in mortality erodes adherence to NPIs.
Testing shapes early trajectories
Testing, treatment, risk perceptions, individual behavior, and government policy all change through several important feedbacks. We find that those receiving a positive test reduce their infectious contacts somewhat (Mean: 13.8% of original contact rate; σ=8.7%; MIQR: 10.7%). These reductions are especially important because symptomatic individuals, who are more likely to get tested, are estimated to be more infectious than asymptomatic ones (Mean asymptomatic infectiousness vs. symptomatic: 28.5%; σ=0.42%; MIQR: 1.3%; consistent with (Li, Pei et al. 2020)).
Testing also regulates the reported rate of deaths, which drives perceived risk. More reported deaths increase perceived risk, triggering behavioral and policy responses that reduce transmission. Plentiful early testing results in high detection rates, greater perceived risk, and stronger responses, slowing transmission. Conversely, insufficient early testing increases underestimation, limiting perceived risk and allowing transmission to further outpace testing. Testing thus reduces future cases, allowing a larger fraction of severe cases to be hospitalized, reducing IFR. The exponential nature of contagion means even small early differences can lead to notable differences in epidemic size (Pei, Kandula et al. 2020), and thus IFR.
Figure 6 (dashed line) shows the impact of these feedbacks by comparing the estimated results to a counterfactual in which all countries increase testing to 0.1% of their population per day, a rate currently achieved by multiple countries. We assume enhanced testing begins when WHO declared COVID-19 a pandemic (11 March 2020). We find enhanced testing would have reduced total cases from 314 million to 249 (CI: 223-255) million, with a reduction in deaths from 1.35 to 1.16 million (CI: 1.07-1.19).
Projections with endogenous responses to risk
We explore two scenarios projecting the pandemic through 20 March 2021 (Figure 7): (I) Baseline: assumes country-specific testing rates continue as of 30 October 2020 with country-specific estimated parameters; and (II) Responsive: the least responsive countries become more responsive to risk (Supplement S5). Scenario II represents a modest increase in responsiveness given levels of perceived risk: on average, contact rates fall by 13% (σ=22%) on the day of adoption, comparable to the impact of enhanced mask use (Chu, Akl et al. 2020). Note that all scenarios exclude vaccines and new treatments. Despite promising progress and the potential for vaccine approval before March 2021, vaccine administration at scale across the 91 nations is not expected until late 2021 (WHO 2020). Moreover, these scenarios help identify policies that may be effective in future pandemics where vaccine development is likely to again lag disease spread.

Projections across two scenarios. Estimated true cumulative cases (A) and deaths (B) (with 95% CIs) across 91 countries until Spring 2021 under scenarios I (baseline; solid line) and II (modestly responsive; dotted). C) Median (95% CI) estimated true cumulative cases (blue; bottom axis) and deaths (red; top axis) as % of population, projected by the end of Winter 2021 under baseline Scenario (Logarithmic Scale). D) Median (95% CI) reductions in cumulative cases in Scenario II (modestly stronger response) compared with Scenario I (in % of population) for top 20 countries by the end of Winter 2021 (blue circles; bottom scale); red squares (top scale) represent initial change in contacts (% of contacts on 1 December 2020) required for corresponding case reductions.
Figure 7 contrasts the results. Scenario I yields 0.80 billion cumulative cases by 20 March 2021, with most cases concentrated in a few countries, with Russia (95 million median cumulative cases; 95% CI 88-99 million), USA (71 million; 62-89), Mexico (52 million; 43-59), and Iran (48 million; 22-54) suffering the largest burdens; Figure 7A & B show estimated cumulative actual cases and deaths by 20 March 2021 (Supplement S5 provides Scenario I projections over time). Scenario II reduces cases (Figure 7A) and deaths (Figure 7B) by 18% and 32%, to 657 million (CI: 647-708) and 2.90 million (CI: 2.88-3.47). The largest improvements arise in countries currently estimated to have large potential for new waves enabled by weak responses to renewed risk (Figure 7D), including Russia (42.1 million reduction in cases), Iran (17.1 million), Ukraine (16.4 million), and Mozambique (9.4 million) among others.
The scenarios demonstrate the sensitivity of outcomes to responses to perceived risk, but should not be interpreted as predictions: changes in testing, individual behavior, and government responses to risk not accounted for in the model are possible, perhaps likely, in the coming months. Stronger responses to perceived risk would significantly reduce future cases. Lax responses and greater adherence fatigue would lead to larger rebound outbreaks.
A global dilemma: similar behaviors, different outcomes
Across scenarios, a few nations are projected to experience significant growth in incidence before vaccines become widely available, but most are able to stabilize their epidemics through NPIs, albeit with occasional new outbreak waves. Endogenous risk perceptions create an important negative feedback that leads most countries to converge to effective reproduction numbers RE ≈ 1: RE > 1 leads to rapid growth in cases and deaths, increasing perceived risk and renewed use of NPIs that bring RE down; RE < 1 lowers cases and deaths, leading to erosion of perceived risk and reduced adherence to NPIs that then lead to more cases.
Critically, however, RE fluctuates around 1 at very different quasi-steady state infection and fatality rates across nations. Recall that RE ≈ 1 means that, on average, infected individuals infect one new case before they are removed from the infectious pool by recovery or death. That balance can be achieved at a high or low level of prevalence. Those nations with high responsiveness to risk settle at RE ≈ 1 with low prevalence and death rates, while those with lower responsiveness to perceived risk achieve that balance only when cases and deaths rise high enough to drive transmission risk and RE down to approximately 1. The large cross-national variation in the behavioral responses to risk lead to death rates more than two orders of magnitude higher in nations with weak responsiveness and greater adherence fatigue compared to those with stronger, sustained responses (Figure 8). Over the 6 months preceding 30 October 2020, average estimated RE values have approximately converged to ≈1 (mean=1.13, σ=0.17), indicating comparable levels of contact reduction across nations. In contrast, deaths per million over the same period show a 10-90th percentile range of 0.022 to 6.29.

Effective reproduction number RE vs. estimated true daily deaths per million in each nation, averaged over the 6 months ending 30 October 2020, with a few countries highlighted. Inset: Oscillation in death rate vs. RE in the USA caused by lags in the perception of and behavioral responses to the risk of death, and lags between behavioral responses that reduce transmission and subsequent deaths. Data are weekly averages over the six-month period ending 30 Octover 2020 (darker circles are the more recent weeks).
Robustness and boundary conditions
We conducted several analyses to assess the robustness of the results. (A) We ensured MCMC chains had converged (100% of Gelman-Rubin convergence statistics were below 1.2 and 97% under 1.1). (B) We varied the priors for cross-country parameter variances to 4 and 0.25 times the base values, resulting in <3% change across historical measures, though scenario results for a few countries are more sensitive (S7 provides details). (C) To see if any country disproportionately affects the results we repeated the analysis using three different samples, excluding the top 5 countries by (i) estimated cases, (ii) reported cases, and (iii) population. Only India and USA appear in all three sets. Average outcomes across the remaining countries changed less than 1% (see S7). (D) We assessed the sensitivity of results to the parameters estimated from prior research by calculating the elasticities of key outcomes to these parametric assumptions. Across metrics all elasticities are less than approximately 0.5. The largest (≈0.5) is for the impact of test sensitivity; greater sensitivity reduces underestimation.
These robustness tests do not address a few limitations which should temper the interpretation of the results. Given limits to data availability across nations and computational costs (reported analyses take 2 weeks of parallelized computation on a 48-core server), we make several simplifications. First, we do not represent within-nation heterogeneity that may affect the course of the epidemic. These variations likely matter especially in large, diverse nations (e.g., USA), including differences in transmission risk between rural and urban areas, differences in adherence to NPIs based on political views, and especially differences in the ability of individuals and households to limit transmission risk or receive treatment based on socio-economic status, race and ethnicity, and other factors affecting social justice (Britton, Ball et al. 2020, Laxminarayan, Wahl et al. 2020, Painter and Qiu 2020). Second, we model IFR as depending on age distribution and hospitalization, but do not explicitly model how well different nations are able to protect vulnerable subpopulations (the effect is aggregated into the overall impact of cumulative cases on IFR). Third, the model aggregates behavioral and government policy responses, and does not represent the effectiveness of specific NPIs. Fourth, we assume testing is primarily done to identify new cases, not to confirm those already suspected through clinical diagnosis. The latter approach would lead to very high positivity rates for tests, from which our model would estimate incorrectly large underlying transition rates. Finally, without explicit travel networks our results may under-estimate the risk of re-introduction of the disease where it has been contained.
Discussion
The model we develop integrates the biological and social factors conditioning transmission captured in typical SEIR models with a range of behavioral factors, including endogenous test allocation and hospitalization based on symptom severity relative to capacity; endogenous risk perceptions and responses, including adherence fatigue; and learning and other factors that cause the infection fatality rate to decline on average over time. To estimate model parameters we utilized a cross-national panel of data spanning all nations with more than 1000 reported cases that publish needed data, a total of 91 nations encompassing 4.87 billion people. The model enables us to estimate the likely actual toll of COVID-19 and degree of underestimation relative to reported data on confirmed cases and deaths, explain multiple waves of infection, and assess the likely impact of policies.
Two methodological contributions may inform future work. Our modeling framework captures heterogeneity in disease severity, affecting test and treatment capacity allocation, without the need for explicit disaggregation into subpopulations or to the individual level, making estimation computationally feasible and providing a consistent approach to track the allocation of testing, hospital capacity, and the impact of acuity on mortality. The estimation framework enables us to use the data from all nations to inform the estimated parameters for each, including consistent estimates of the differences across nations. As expected, parameters capturing biological attributes of SARS-CoV-2 and COVID-19, such as the asymptomatic fraction of cases, have far less cross-national variation than parameters characterizing risk perceptions and behavioral responses to the threat.
Substantively, we find prevalence and mortality are substantially underestimated: across the 91 nations for which data are available, estimated cumulative COVID cases are greater than official reports, with under-reporting across nations spanning three orders of magnitude across nations. Despite underreporting, cumulative cases constitute small fractions of the populations, so herd immunity remains distant in nearly all nations (see S5). We find deaths are times larger than official reports, again with substantial cross-national variation. The overall infection fatality rate to date is ≈0.48%, consistent with growing evidence (Russell, Hellewell et al. 2020, Verity, Okell et al. 2020). Substantial cross-national variation in IFR arises from differences in population age structure and in the burden of severe cases relative to hospital capacity, highlighting the importance of limiting case growth. We also find that IFR has, on average, declined substantially since the onset of the pandemic. The decline is likely due to a combination of better treatments and greater supplies of ventilators and PPE, and heterogeneity in behavioral responses to risk whereby higher-risk individuals adhere more strongly to isolation, distancing, masking and hygiene recommendations compared to those who perceive lower personal risk. Despite the overall declining trend in IFR, mortality spikes upward when renewed outbreaks overwhelm treatment capacity.
Importantly, the large differences across nations are explained well without exogenous time-varying parameters and with parameters characterizing COVID-19 that are consistent with prior research and are similar across nations. We estimate that approximately half of infections are asymptomatic, consistent with estimates from smaller samples (Gudbjartsson, Helgason et al. 2020, Lavezzo, Franchin et al. 2020, Mizumoto, Kagaya et al. 2020), with asymptomatic individuals estimated to be about a third as infective as symptomatic patients.
The wide variation across nations arises endogenously. First, the growth rate, timing, and size of outbreak waves depend strongly on the magnitude of behavioral and policy responses to perceived risk, and the lags in forming and eroding those perceptions, which we find vary notably across countries. Projections through 20 March 2021 show that modest reductions in transmission through NPIs can lead to large reductions in cumulative cases and deaths in many countries, even absent effective vaccines. Second, inadequate early testing in some countries has led to greater underestimation of prevalence, and thus later and weaker responses, causing faster epidemic growth, further outstripping testing and treatment capacity. These feedbacks amplify minor differences in testing and responsiveness to perceived risk, generating significant heterogeneity in cases and deaths despite convergence of RE across nations. Consequently, we find greater testing early in the pandemic would have avoided over 190,000 deaths, more than 14% of the estimated total through 30 October 2020.
A counter-intuitive finding provides important policy implications. After controlling the initial peak, most countries settle into a quasi-steady state with the effective reproduction number RE fluctuating around 1: lower mortality erodes adherence to NPIs, raising RE and leading to rebound outbreaks, which then lead to renewed contact reductions that bring RE back down. However, responsiveness to risk varies widely across nations. Those with strong responses bring RE to 1 with few cases and deaths, while those with weak responses require much larger death rates to drive RE toward 1. Consequently, different nations pay widely different prices in lost lives. Although we do not carry out a detailed analysis of the economic costs of NPIs, the behavioral and policy changes that reduce contacts from pre-pandemic levels sufficiently to bring RE to 1 are a rough measure of the self-isolation, distancing, and other actions that reduce economic activity and employment by cutting travel, dining, shopping, and other activities sustaining commerce and industry. Thus, by increasing responsiveness to risks, communities and nations can bring down death rates at little additional economic cost, a finding consistent with analysis of the 1918 influenza pandemic (Correia, Luck et al. 1918). Although contrary to the intuitions of many policy makers, the results suggest no strong tradeoff between saving lives and saving the economy. Stronger responsiveness to risk and adherence to NPIs offer an opportunity to save lives at limited costs even as vaccines are approved and deployed.
Data Availability
All data, codes, and simulation models are publicly available.
Author contributions
HR designed the study; HR and TYL collected the data; HR and TYL conducted the analysis; HR, JS, TYL revised the model and prepared the manuscript.
Competing interests
Authors declare no competing interests.
Data and materials availability
Supplementary materials provide model documentation and full estimates. All data, code, and simulation models are available at: https://github.com/tseyanglim/CovidGlobal
Supplementary Materials
S1 MODEL STRUCTURE AND KEY FORMULATIONS
The model simulates the evolution of COVID-19 epidemic, risk perception and response, testing, hospitalization, and fatality at the level of a country. Here we explain key equations and structures in each sector, followed by complete listing of model equations and parameters in S8.
Population Groups and Transmission Dynamics
The model is a derivative of the well-known SEIR (Susceptible, Exposed, Infectious, Recovered) framework for simulating infection dynamics. Figure S1 provides an overview of key population groups and the population movements among them1.

Key population stocks and flows. Rectangles represent stocks (state variables), while arrows and valves represent the flows between them (state transitions).
The Susceptible population (S) transitions to the Pre-Symptomatic Infected state (P) based on the Infection Rate (rSP). After an average Incubation Period (τP), these pre-symptomatic infected transition into the Infected Pre-Detection (IP) state. After a further average Onset to Detection Delay (τT), this group splits among multiple pathways. First, if tested positive for COVID-19, they transition into either Infectious Confirmed Not Hospitalized (IC) or Hospitalized Infectious Confirmed (ICH). Anyone not tested positive, whether for lack of testing or erroneous test results, transitions into either Hospitalized Infectious Unconfirmed (IUH) or Infectious Unconfirmed Post-Detection (IU). We assume demand for testing and hospitalization are driven by symptoms, so all asymptomatic patients will be in the latter category.
From these Infectious categories, resolution flows (r…) take individuals to either Recovered (R…) or Dead (D…) states, with corresponding subscripts U, C, CH, and UH for stocks and UU, UHCH etc. for flows. Given the differences in severity and potential survival extension due to hospitalization, we distinguish between resolution delay for those in hospital (Hospitalized Resolution Time; τH) and those not hospitalized (Post-Detection Phase Resolution Time; τR). We use first order exponential delays for all lags, though sensitivity analyses showed very little impact of using higher order delays.
The Infection Rate (rSP) controls the flow from S to P and depends on Infectious Contacts (CI), fraction of total Population (N) that is susceptible, and Weather Effect on Transmission (W). The latter is a function of RW, the country-level projections for impact of weather on COVID-19 transmission risk year-round developed by Xu and colleagues (1) and a parameter, Sensitivity to Weather (sW), to be estimated:


Infectious contacts depend on the Reference Force of Infection (β), various infectious sub-populations (and their relative transmission rates; ma for asymptomatic and mT for confirmed), and Contacts Relative to Normal (FC), which captures behavioral and policy responses as a fractional multiplier to baseline infectious contacts:
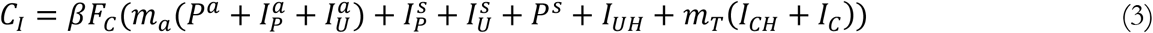
In this equation we separate various stocks (of I and P) into asymptomatic (a superscript) and symptomatic (s superscript). That distinction is treated analytically using a zero-inflated Poisson distribution that is discussed in the next section. In light of evidence on the short serial interval for COVID-19, likely below the incubation period (2, 3), we do not distinguish the infectivity of pre-symptomatic individuals from those post onset. Contagion dynamics start from Patient Zero Arrival Time, T0, another estimated parameter. The key mechanisms regulating the population flows among these stocks are discussed below, and a schematic of important relationships is provided in Figure S2.
Five parameters are estimated in the equations discussed above. One of them (sW) is global (i.e. assumed identical across countries; see the estimation section below for details on the distinction between global and country-specific parameters) and the remaining four are country-specific: β, mT, ma, and T0.

Overview of model’s mechanisms. Major feedback loops are identified as Balancing (Negative feedback; B) and Reinforcing (Positive feedback; R).
Modeling the Severity of Symptoms
COVID-19 infection varies in acuity, from asymptomatic to life-threatening. Disease acuity affects fatality risk and also testing and hospitalization decisions, which in turn affect official records of infection and fatality rates. Since movement between population groups via testing or hospitalization is itself a function of acuity, to allow for consistent inference of mean acuity across different population groups, we use an analytical framework to track acuity levels. The framework, which we adapted from prior research (4), obviates the need to disaggregate the population by different acuity levels (which would prohibitively raise the computational costs for estimation).
Specifically, we represent acuity using a zero-inflated Poisson distribution. This distribution combines two subpopulations – one with Poisson-distributed acuity levels with mean Covid Acuity (αC), and another Additional Asymptomatic Fraction with zero acuity, which is the zero-inflated component. The sum of those with zero acuity from the Poisson part of the population and the second group is the Total Asymptomatic Fraction (pa). We assume this asymptomatic group is not given priority in testing or hospitalization, and is not at risk of death. Thus they will always follow the 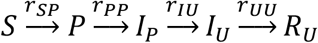 pathway. The pathways for the remaining population depend on acuity and its impacts on testing, hospitalization, and death. Note that the concept of acuity defined here only needs to have a monotonic relationship with tangible symptoms and risk factors and it does not have a one-to-one relationship with any real world measure of acuity, and as such is better seen as a mathematical construct that informs modeling rather than a real-world variable with clinical definition.
pathway. The pathways for the remaining population depend on acuity and its impacts on testing, hospitalization, and death. Note that the concept of acuity defined here only needs to have a monotonic relationship with tangible symptoms and risk factors and it does not have a one-to-one relationship with any real world measure of acuity, and as such is better seen as a mathematical construct that informs modeling rather than a real-world variable with clinical definition.
From this framework two parameters, a and αC, are estimated as country specific parameters with limited variability across countries.
Testing
The testing sector reads the Active Test Rate (Tt) for each country as exogenous input data (see appendix S3 for pre-processing details for this data). A fraction of the total test rate, typically small, is allocated to post-mortem testing of COVID-19 victims who have not been previously confirmed (Post Mortem Tests Total, TPM). Specifically, of the deaths of unconfirmed infectious individuals (whether hospitalized or not), a certain Fraction of Fatalities Screened Post Mortem (nPM) will be identified true post-mortem tests. We anchor the nPM to Fraction Covid Death In Hospitals Previously Tested (nDCH). The rationale for this anchoring is that on the margin if there are many unidentified COVID patients in hospitals, the chances are that the system lacks enough testing capacity and thus post-mortem testing should also be less thorough:

We experimented other functional forms with a free parameter connecting the two constructs, but following our conservative estimation principle decided against including that free parameter in the final model. We feared that absent clear observables to identify this additional parameter (e.g. on country-specific policies regulating post-mortem testing) the degree of freedom would improve the fit but potentially for the wrong reason.
The remaining Testing Capacity Net of Post Mortem Tests (TNet = Tt − TPM) is allocated to test demand from two sources. First, symptomatic COVID patients leaving the pre-detection (IP) phase may seek testing (Positive Candidates Interested in Testing Poisson Subset: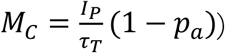 . Second, COVID-negative individuals may seek testing due to various perceived risks and other conditions with overlapping symptoms such as common cold and influenza-like illnesses (MN, Potential Test Demand from Susceptible Population). This “negative” demand includes a Baseline Daily Fraction Susceptible Seeking Tests (nST) of the population not previously tested positively (NU), and increases with the Recent Detected Infections (TPIR), which is an exponentially weighted moving average of Positive Tests of Infected (TPI). COVID-positive and COVID-negative sources of demand add up to create the overall Testing Demand (MT):
. Second, COVID-negative individuals may seek testing due to various perceived risks and other conditions with overlapping symptoms such as common cold and influenza-like illnesses (MN, Potential Test Demand from Susceptible Population). This “negative” demand includes a Baseline Daily Fraction Susceptible Seeking Tests (nST) of the population not previously tested positively (NU), and increases with the Recent Detected Infections (TPIR), which is an exponentially weighted moving average of Positive Tests of Infected (TPI). COVID-positive and COVID-negative sources of demand add up to create the overall Testing Demand (MT):


Where the Multiplier Recent Infections to Test (mIT), captures the sensitivity of negative test demand to recent infection reports.
To allocate the available tests (TNet) between these two sources of demand, we use an analytical logic that allocates testing based on symptom severity. Via self-selection and screening by testing centers, people who have more symptoms or other signals that correlate with COVID infection (e.g., high exposure risk) are more likely to be tested. We assume each unit of acuity increases the likelihood that an individual gets tested, based on a variable Prob Missing Symptom, pMS. This variable represents the probability that each acuity unit fails to convince the testing decision process to test a given individual, i.e. how selectively and sparingly tests are conducted. Specifically, in this model an individual with k acuity units is tested with probability:
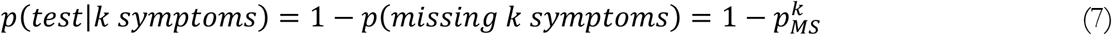
We assume the negative test demand is coming from a population with a Poisson-distributed, unit average acuity level (αN=1) for symptoms of non-COVID influenza-like illnesses. The test demand from COVID patients also comes from a Poisson distribution of acuity, but with mean αC. With the Poisson distribution and given a level of α and pMS, one can calculate the fraction of each demand source that would be tested:
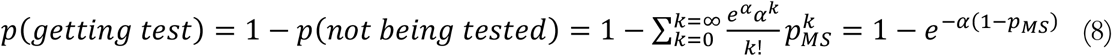
We therefore need to find the pMS that allows test supply to match demand that is satisfied, specifically, by solving the following equation for pMS*:
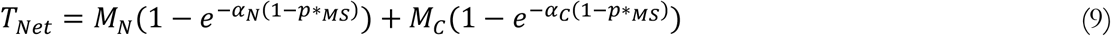
Figure S3 provides a graphical summary of the zero-inflated Poisson symptom and testing framework. In this figure testing outcomes are graphed for a population where 10% are COVID-positive, assuming that Covid Acuity, αC, is 6, and with two different levels of pMS (=0.8 and 0.95). For this figure we also assume a 55% asymptomatic fraction for COVID patients. Even with testing that prioritizes patients with more symptoms, and despite the large difference in symptom frequency between COVID patients and negative cases, the majority of tests are allocated to negative cases with a few symptoms. COVID patients with multiple symptoms are likely to be identified if PMS is not very large, but when total demand for testing (i.e. the sum of all bars with symptoms>0) is large, PMS, found from solving equation 9, may be close to 1, excluding many COVID patients with multiple symptoms and thus higher risks of fatality.

Schematic overview of zero-inflated Poisson process and test allocation. Red bars represent COVID-positive individuals and blue ones are COVID- negative. Asymptomatic fraction is assumed to be 55% for COVID patients with the symptomatic cases following a Poisson distribution with mean 6. Color coded bars signal fraction of tested individuals with different levels of probability of missing symptoms, PMS.
Having solved for p*MS (numerically), we analytically calculate the average acuity level for those positively tested (αCP: Average Acuity of Positively Tested) and those either not tested or having received a false negative result (αCN). Specifically, if test sensitivity was 100%, the average acuity for those not tested would be:
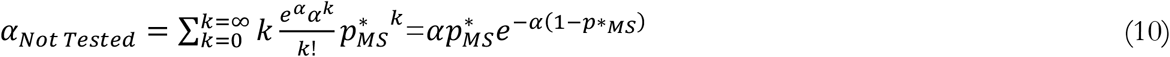
The acuity level for those tested could then be found based on the conservation of total acuity across those positively tested and those not. Starting with this basic specification we further account for the Sensitivity of Covid Test (sT) to calculate the values of αCP and αCN. We parametrize sensitivity at 70%, which is the estimated sensitivity for the PCR-based tests used as the primary diagnosis method of current infections of COVID-19 (5, 6).
Overall, the testing rates that are determined by solving for 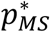 , combined with sensitivity of tests, inform the fraction of COVID positive individuals transitioning from pre-detection (IP) to confirmed vs. unconfirmed states (IC or ICH vs. IU or IUH), while the calculated α values inform the likelihood of hospitalization and fatality rates, as discussed next.
, combined with sensitivity of tests, inform the fraction of COVID positive individuals transitioning from pre-detection (IP) to confirmed vs. unconfirmed states (IC or ICH vs. IU or IUH), while the calculated α values inform the likelihood of hospitalization and fatality rates, as discussed next.
The testing sector includes the following two country level parameters that are estimated: nST, mIT.
Hospitalization
The hospitalization sector of the model starts with each country’s Nominal Hospital Capacity (hN) in total hospital beds. In practice, geographic variation in hospital density and demand creates imperfect matching of available beds with cases of COVID-19 at any point in time, e.g. because some potential capacity is physically distant from current COVID hotspots. This imperfect matching means some of the nominal hospital capacity is effectively unavailable at any time, especially in larger, less densely populated countries. We therefore calculate Effective Hospital Capacity (hE) by considering geographic density of hospital beds (Bed per Square Kilometer; dH):

Where the 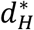 represents a large Reference Hospital Density of 6.06 beds per km2 (which is the value of dH for South Korea). The parameter sDH (Impact of Population Density on Hospital Availability) is estimated.
represents a large Reference Hospital Density of 6.06 beds per km2 (which is the value of dH for South Korea). The parameter sDH (Impact of Population Density on Hospital Availability) is estimated.
Effective capacity is allocated between Potential Hospital Demand (HCD) from COVID-19 cases and the regular demand for hospital beds from all other conditions (which we assume equals pre-pandemic effective hospital capacity). We assume that COVID-19 patients will have higher priority for hospitalization compared to regular demand. Specifically, we assume that fraction of regular demand allocated (mHR) would be the square of that for COVID demand (mHC),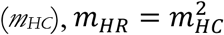 , and solve the resulting hospital capacity allocation problem analytically:
, and solve the resulting hospital capacity allocation problem analytically:
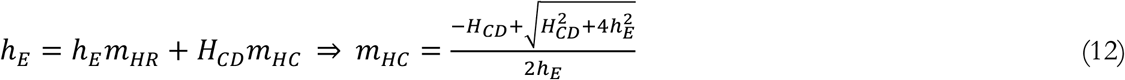
We determine the COVID demand for hospitalization based on a screening process similar to that for testing. Two types of COVID patients may seek hospitalization: those with confirmed test results and those without. The former are more likely to seek hospital treatment. We first calculate a parameter analogous to pMS in the testing sector that informs the demand from confirmed COVID patients for hospitalization. This parameter, the PMAS Confirmed for Hospital Demand (pMHC) is determined based on acuity level of confirmed (αCT) and Reference COVID Hospitalization Fraction Confirmed (rH), an estimated parameter capturing the overall need for hospitalization among COVID patients:

For unconfirmed COVID patients we scale the analogue of this parameter (pMHU) based on how much priority non-COVID patients generally receive:

This formulation ensures that: 1) Confirmed COVID patients are more likely to be hospitalized, but also that 2) if there is ample hospital capacity (mHR∼1), then confirmed and unconfirmed COVID patients will receive similar priority for the same level of acuity. In short, the pM. values determine hospital demand by confirmed and unconfirmed COVID patients, which add up to HCD. The latter determines the fraction of hospital demand that is met. Analogous to the testing sector, this fraction along with demand determines the flow of individuals from the pre-detection (IP) state to hospitalized vs. non-hospitalized states (ICH or IUH vs. IC or IU). Matching demand to allocated capacity also allows us to calculate the realized Probability of Missing Acuity Signal at Hospitals (p*M) for confirmed and unconfirmed patients. As in the testing sector, those probabilities let us approximate for the expected acuity levels for COVID patients in and out of hospital, as well as tested vs. not-tested, i.e. αCT, αCH, αU, and αUH. These average acuity levels in turn inform fatality rates for each group.
The hospital sector includes two country level estimated parameter with limited variation across countries: sDH and rH.
Infection Fatality Rates
For patients in each of the U, C, CH, and UH groups we specify the Infection Fatality Rate (f), as:

The parameter Base Fatality Rate for Unit Acuity (fb) sets the baseline for fatality rate. Sensitivity of Fatality Rate to Acuity (sf) determines how fatality changes with estimated acuity levels; more severe cases are expected to have higher fatality rates. Hospitalization reduces fatality rates, expressed as the relative Impact of Treatment on Fatality Rate (sHF); Finally, IFR reduction due to heterogenous responses (e.g. high risk groups becoming more cautious as cases accumulate), improved treatment with learning curves, and other drivers is captured in Time variant change in fatality (vf).
The gAg function incorporates the impact of age distribution on fatality rates. For age effect, we calculate a risk factor for each country. We use data from the World Bank on the age distribution of each country’s population in 10-year age strata to calculate an age-weighted average of the IFRs for COVID patients by 10-year age group reported in prior work (7). We normalize this age-weighted average IFR against its value for China, where the data on IFRs by age group were originally recorded. Normalizing in this way means the age effect is not sensitive to any systematic over- or under-estimation of the IFR in prior work, only to the relative risk by age group. The resulting normalized age effect ranges from 0.271 (Kenya, median age ∼20 years) to 2.368 (Japan, median age ∼48 years). Given the well-established impact of age on fatality, this factor is directly multiplied into the infection fatality equations.
Finally, we formulate the vf factor as a function of cumulative cases to-date in each country using a standard learning curve formulation, bounded by a minimum multiplier that is 10% baseline, and starts to operate after cases reach 0.5% of population. The Learning and Death Reduction Rate, lIFR,, is estimated for each country. Specifically:
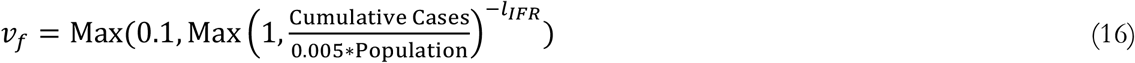
Overall, the fatality sector includes three parameters that are estimated at the country level, with limited variance across countries, those are: fb, sHF, and sf. A fourth country-level parameter, lIFR,, is allowed to very more widely across different nations.
Note on comorbidities and fatality
We also explored including three comorbidities but found the estimates unreliable and therefore they are not included in the main specification of the model. Those comorbidities include obesity, chronic disease, and liver disease. The effects we explored for each were: 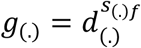 , where we used the following country-level indicators from the World Health Organization (8), normalized by the average across all countries (d(.)):
, where we used the following country-level indicators from the World Health Organization (8), normalized by the average across all countries (d(.)):
For obesity: Prevalence of obesity among adults, BMI ≥30 (age-standardized estimate) (%) For chronic health issues: Probability (%) of dying between age 30 and exact age 70 from any of cardiovascular disease, cancer, diabetes, or chronic respiratory disease For liver disease: Liver cirrhosis, age-standardized death rates (15+), per 100,000 population
Risk Perception, Behavioral Responses, and Adherence Fatigue
In equation 3 we noted that Contacts Relative to Normal (FC) regulates infection rates. This factor ranges between a minimum (Min Contact Fraction; cMin) and 1 as a function of the relative Utility from Normal Activities (UN) compared to Utility from Limited Activities (UL) in light of additional risks associated with normal activity patterns:


The utilities from normal and limited activities are specified as 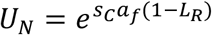 and
and 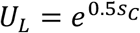 . The former depends on the Perceived Risk of Life Loss (LR) while the latter depends only on the Sensitivity of Contact Reduction to Utility (sC) and Impact of Adherence Fatigue (af) on responsiveness. LR adjusts to an underlying Indicated Risk of Life Loss
. The former depends on the Perceived Risk of Life Loss (LR) while the latter depends only on the Sensitivity of Contact Reduction to Utility (sC) and Impact of Adherence Fatigue (af) on responsiveness. LR adjusts to an underlying Indicated Risk of Life Loss 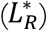 with a time constant that is asymmetric, i.e. Time to Upgrade Risk (τRU) could be different from Time to Downgrade Risk (τRD). The
with a time constant that is asymmetric, i.e. Time to Upgrade Risk (τRU) could be different from Time to Downgrade Risk (τRD). The 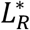 itself depends on Perceived Hazard of Death (ZDP) from pursuing normal activities, the perceived risk of loss of life in case of infection (pD, for which we use the global ratio of cumulative deaths to cases to date); a discount rate to turn daily costs to life-long ones (γ=0.03/year); and an estimated parameter to capture variations in risk communication, policies, and risk perceptions across countries (Dread Factor in Risk Perception, λ) and is further adjusted based on the adherence fatigue factor (af):
itself depends on Perceived Hazard of Death (ZDP) from pursuing normal activities, the perceived risk of loss of life in case of infection (pD, for which we use the global ratio of cumulative deaths to cases to date); a discount rate to turn daily costs to life-long ones (γ=0.03/year); and an estimated parameter to capture variations in risk communication, policies, and risk perceptions across countries (Dread Factor in Risk Perception, λ) and is further adjusted based on the adherence fatigue factor (af):


The Perceived Hazard of Death (ZDP) is an average of reported daily hazard of death (with the weight Weight on Reported Probability of Infection, wR) and true hazard for death which individuals may perceive through word of mouth and their social networks.
Finally, we formulate the Impact of Adherence Fatigue based on an 100-day exponential average of relative contacts, Recent Relative Contacts (FR) and a country-specific estimated parameter, Strength of Adherence Fatigue (sa):


Overall, the risk perception and response sector includes the following six country-specific parameters that are estimated: cMin, τRU, τRD, λ, wR, and sa.
Summary of Key Equations and Parameters
Table S1 summarizes the main equations discussed in S1, providing the mapping between full variable names and the short forms. It also includes all estimated model parameters, as well as those specified based on prior research.
Mapping between full variable names and their short form for the subset of variables and parameters discussed in S1. Also included are equations explained above and sources for other variables.
S2 ESTIMATION METHOD
Overview of the Approach
The model we estimate is nonlinear and complex, and any estimation framework is unlikely to have clean analytical solutions or provable bounds on errors and biases. Therefore, in designing our estimation procedure we apply 3 guideposts: 1) Being conservative by incorporating uncertainties. 2) Avoid over-fitting; and 3) Enhance generalizability and robustness of estimates and projections. To these ends: we use a likelihood function that accommodates overdispersion and autocorrelation (negative binomial); we utilize a hierarchical Bayesian framework to couple parameter estimates across different countries which reduces the risk of over-fitting the data; and we use the conceptual definitions of parameters and their expected similarity across countries to inform the priors for the magnitude of that coupling across countries. Compared to more common choices in similar estimation settings (e.g. use of Gaussian likelihood functions), these choices tend to widen the credible regions for our estimates and reduce the quality of the fit between model and data. In return, we think the results may be more reliable for projection, more informative about the underlying processes, and better reflective of uncertainties in such complex estimation settings. We also conduct a validation test of our estimation framework using synthetic data in section S3.
The model is a deterministic system of ordinary differential equations with a set of known and unknown parameters. The known parameters are those specified based on the existing literature and do not play an active role in estimation. The unknown parameters can be categorized into those that vary across different countries and those that are the same across all countries (i.e. “general” parameters). The estimation method is designed to identify both the most likely value and the credible regions for the unknown parameters, given the data on reported cases and deaths (and for a subset of countries, the excess deaths). This is done through a combination of estimating the most likely parameter values in a likelihood based framework, and using Markov Chain Monte Carlo simulations to quantify the uncertainties in parameters and projections.
We first introduce the 3 different components of the likelihood function we use: the fit to time series data, the random effects component coupling country-level parameters, and the penalty for excess mortality. Then we explain the implementation details.
The Fit to Time Series for Cases and Deaths
Define model calculations for expected reported cases and deaths for country i as μij(t) (with index j specifying cases and deaths) and the observed data for those variables as yij(t); the country-level vector of unknown parameters as θi and the general unknown parameters as ϕ. Note that θi vector includes several parameters, each specifying an unknown model parameter, such as Impact of Treatment on Fatality, or Total Asymptomatic Fraction, for country i. The model can be summarized as a function f that produces predictions for expected cases and deaths for each country given the general and country-specific parameters:

We use a negative binomial distribution to specify the likelihood of observing the y values given θ and ϕ. Specifically, the logarithm of likelihood for observing the data series y given model predictions μ(θ,ϕ) is:
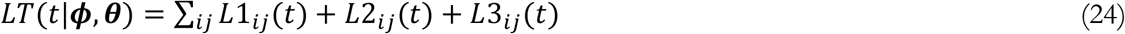 where (dropping time index for clarity):
where (dropping time index for clarity):


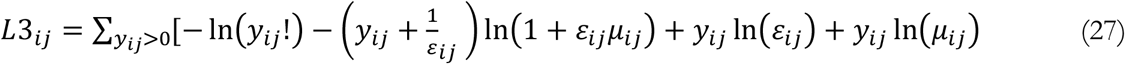
Summing the LT function over time provides the full (log) likelihood for the observed data given a parameterization of the model. The negative binomial likelihood function includes two parameters, μ and ε which determine the mean and the scaling/shape of the observed outcomes. The second parameter, ε, provides the flexibility needed fit outcomes with fat tails and auto-correlation. This parameter could itself be subject to search in the optimization process. Specifically, we assume that:

Thus we create a (set of) country specific parameter(s) (εi) and two general parameters (εj) which should be estimated along with the conceptual model parameters. The country level scale (εi) implicitly assesses the reliability and inherent variability in country level reports, and the general ones inform the variability in case data vs. deaths. We augment the vectors ϕ and θ to include these scaling parameters as well.
Incorporating the coherence of parameters across countries
Up to this point we have not included any relationship among country specific parameters, θi. This independence assumption would allow parameters representing the same underlying concept to vary widely across different countries. Such treatment, by providing more flexibility, enhances the model’s fit to historical data. However, it ignores the conceptual link that exists for a given parameter across countries, potentially allowing the model to fit the data for the wrong reasons (i.e. using parameter values that do not correspond to meaningful real world concepts). The result would likely be less reliable and also not robust for future projections. We therefore define a Hierarchical Bayesian framework to account for the potential dependencies among model parameters. Specifically, we assume the same conceptual parameters (e.g. Impact of Treatment on Fatality), across different countries, are coming from an underlying normal distribution with an unknown mean (to be estimated) and a pre-specified prior for the standard deviation. This assumption is similar to the use of “Random Effect” models common in regression frameworks, though we deviate from canonical random effect models by pre-specifying the standard deviation. In fact it is possible to estimate the standard deviation across countries as well (and to obtain better fits to data by including the additional degrees of freedom), but adding those degrees of freedom ignores qualitatively relevant insights about the level of coupling across different countries for each parameter, and thus results may fit the data better but for the wrong reasons. For example, some parameters, such as Patient Zero Arrival Time, could be very different across countries, whereas parameters reflecting innate properties of the SARS-CoV-2 virus itself (e.g. Total Asymptomatic Fraction (a)) or those determining fatality (e.g. Base Fatality Rate for Unit Acuity (fb)) should be very similar across different countries. Allowing the model to determine the variance for the latter will lead to better fits: the model can find baseline fatality rates that easily match fatality variations across countries, and would expand the corresponding variance parameter accordingly. However, as a result the estimation algorithm will have too easy a job: it will not require a precise balancing between hospitalization, impact of acuity on fatality, and post-mortem testing decisions to fit fatality data. Thus, the estimates may well be less informative, or further from true underlying processes and the general characteristics of the disease which we care about. Overall, our implementation of a hierarchical Bayesian estimation framework to account for the coupling among the variables may reduce the apparent quality of fit but offer more robust results better informing the underlying mechanisms.
The implementation of this random effect introduces another element to the overall likelihood function:

Here θik represents the kth parameter for country i, and 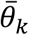 is the (estimated) average across countries for the kth parameter. σk is the pre-specified allowable variability for the kth parameter across different countries.
is the (estimated) average across countries for the kth parameter. σk is the pre-specified allowable variability for the kth parameter across different countries.
In setting these factors we chose small values for factors representing biological and natural processes, while adding more room for variation when human behaviors and perceptions were involved (See Table S2 for those settings). Specifying these standard deviation priors adds a subjective element to the estimation process. We note that subjective elements are ultimately indispensable in any modeling activity: from specifying the model boundary to the level of aggregation, use of various functional forms, and choice of likelihood functions, these choices are built on subjective assessments that experts bring to a modeling project. Absent our conceptually informed variability factors, we would need to make the assumption that country-level parameters are independent, or that our complex estimation process would correctly identify the true dependencies among those parameters. We think both those alternatives are inferior in the chosen method. So here we focus on transparently documenting and explaining those assumptions, and Supplement S3 provides a validation experiment. Table S2 summarizes the estimated model parameters, their estimated values (mean across countries and mean of Inter-Quartile Range) and the assumed variability factor (σk) for each.
Estimated model parameters, their estimated values (mean and standard deviation (std) across countries and the mean of Inter-Quartile Range (MIQR). Last column reports the variability allowances used to specify the coupling among country-level estimates. See equation 29 and related discussions above.
Excess mortality penalty
Finally, we include a likelihood-based penalty term to allow model predictions be informed by excess mortality data collected by various news agencies and researchers for a subset of countries in our sample. These data provide snapshots of excess mortality (compared to a historical baseline) for a window of time in each country. Subtracting from total excess mortality the COVID-19 deaths officially recorded in that window offers a data point for excess mortality not accounted for in official data (ei). We can calculate in the model the counter-part for this construct: the simulated mortality that is not included in the simulated reported COVID-19 deaths (ēi). There is uncertainty in these excess mortality data: the historical baselines used by various sources do not adjust for demographic change, excess mortality may be due to factors other than COVID-19, and some of it may be due to changes in healthcare availability and utilization motivated by COVID-19 but not directly attributable to the disease (for example when surgeries are delayed, hospitalization is avoided, or heart conditions are ignored). Excess mortality may also be reduced due to reduced traffic accidents (in light of physical distancing policies) and pollution related deaths. Given these uncertainties, we use the following penalty function to keep the simulated unaccounted excess mortality close to data:

This penalty could be seen as a likelihood coming from the probability distribution 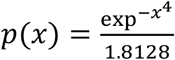 defined for all values of x. It assumes that in the most likely case for excess mortality, 90% of unaccounted mortality should be attributed to COVID-19 deaths, but that there is significant uncertainty around this, so some 20% variation across this figure is quite plausible (70%-110% of data). However, numbers outside of this range start to impose increasingly large penalties, so that very large deviation becomes unlikely.
defined for all values of x. It assumes that in the most likely case for excess mortality, 90% of unaccounted mortality should be attributed to COVID-19 deaths, but that there is significant uncertainty around this, so some 20% variation across this figure is quite plausible (70%-110% of data). However, numbers outside of this range start to impose increasingly large penalties, so that very large deviation becomes unlikely.
Combining these three components, we obtain the full likelihood function used in the analysis:

For each country we include the LT component from the first day they have reached 0.1% of their cumulative cases to-date, or a minimum of 50 cumulative cases. This excludes very early rates that are both unreliable and which, given very small estimated model predictions for infection, could lead to unreasonably large likelihood contributions.
Numerical Methods
The model includes a large number of parameters to be estimated: a general parameter for the impact of weather, 2 general parameters for εj, and 22 parameters for each country that are coupled together based on the random effects framework described above. Out of those 1 parameter (per country) is for εi and the other 21 are informing various features of disease transmission, testing, hospitalization, and risk perception and response. With a sample of 91 countries, this would lead to 2005 parameters to be estimated. A direct optimization approach to this problem suffers from potential risk of getting stuck in local optima, and direct use of MCMC methods to find the promising regions of parameter space suffers from the curse of dimensionality. We therefore designed the following 4-step procedure to find more reliable solutions to both problems and the synthetic data exercise in S3 provides some evidence on the effectiveness of the method.
We estimate the model with the full parameter vector for a smaller number of countries with larger outbreaks (3-5 countries). We use the Powell direction search method implemented in Vensim™ simulation software for this step. The method is a local search approach though it has features that allows it to escape local optima in some cases. We restart the optimization from various random points in the feasible parameter space and track the convergence of those restarts to unique local peaks. We stop this process when we are repeatedly landing on the same local peaks in the parameter space. This procedure showed that local peaks do exist, but they are not many; for example, within 100 restarts we may find 2-4 distinct peaks, with one being distinctly better than others. This quasi-global peak provides a coherent set of starting points for ϕ and
 for next steps.
for next steps.We go through iterations of the following two steps: A) Conduct country-specific optimizations with 50 restarts to find the vector of θi given the ϕ and
from first optimization or from the step B. B) Conduct a global optimization, including all countries but fixing θi and optimizing on ϕ (and ; though that is simply the mean across country level parameters from previous round). We stop when iterations offer little improvement from one round to the next (less than 0.05% improvement in log-likelihood).We conduct a full optimization allowing all parameters (θi, ϕ and
) to change, starting from the point found in the last iteration of step 2. This step finds the exact peak on the likelihood landscape which is the best-fitting parameter set for the model.For the MCMC, theoretically one should conduct the sampling from all model parameters in the full model. However, our experiments showed that the large dimensionality of the parameter space requires an infeasible number of samples to achieve adequate mixing and ensure reliable credible regions for parameters and projections. To overcome this challenge we note that the parameters of different countries are connected to each other only through ϕ and
, and these general parameters are rather insensitive to dynamics in each country. The insensitivity is due to the fact that a single country only contributes about 1% to the general parameters’ values, and within a typical MCMC the country-level parameters often can’t change more than 10% before the resulting samples become highly unlikely. Therefore, one can conduct an approximate country-level MCMC by fixing the general parameters at those from step 3, and only sampling from the θi for each country. The MCMC algorithm used is one designed for exploring high dimensional parameter spaces using differential evolution and self-adaptive randomized subspace sampling (11). Using this method we obtain good mixing and stable outcomes (Robin-Brooks-Gelman PSFR convergence statistic remaining under 1.1) after about 600,000 samples (the burn-in period). We continue the MCMC for each country for another 400,000 samples and then randomly take a subsample of those points after the burn-in period for the next step.The resulting subsamples for different countries from step 4 are assembled together to create a final sample of parameters for the full model to conduct projections and sensitivity analysis at the global scale. Uncertainties in the handful of global parameters is not identified in this procedure, but can be quantified by assessing the sensitivity of the global likelihood surface to changes in those parameters.
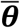
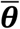
The process above is automated using a Python script that controls the simulation software (Vensim). We conduct the analysis using a parallel computing feature of Vensim on a Windows server with 48 cores. After compiling the simulation model into C++ code (which speeds up calculations significantly), and using a simulation time step of 0.25 days, it takes about 60 hours to complete the estimation for 91 countries, and almost two weeks to complete the full suite of sensitivity analyses reported in the paper. Full analysis code is available online at https://github.com/tseyanglim/CovidGlobal.
S3 VALIDATION OF ESTIMATION FRAMEWORK
The complexity of model and the large number of parameters involved complicates the assessment of estimation method based on theoretical considerations alone. We therefore use a synthetic data experiment to build confidence in the estimation framework. Specifically, we first simulate the model using known parameters without using historical deaths and cases to provide a ‘ground-truthed’ set of synthetic data. We then apply the exact estimation framework used on the actual data to infer the parameters of the model from this synthetic dataset. Finally, we assess how well the estimated parameters correspond to the “true” values and how inclusive the estimated credible intervals are of the true parameters. The ability of the estimation framework to find the true parameter values, and consistent credible intervals, would increase our confidence that parameters estimated using actual data are also not particularly biased and that the credible intervals are informative. While repeating this procedure for multiple sets of synthetic data, with various parameterizations, is desirable, the computational costs in our setting make such an approach infeasible. Nevertheless, the large number of parameters estimated in a single full calibration exercise provides ample opportunities to test the precision of the method in the range of parameter values relevant in the actual data. The three steps of the process are discussed below.
Generation of synthetic data
We used the model specified above, with the parameters estimated in the baseline analysis from actual data, to generate the synthetic data. Given the deterministic nature of the model, it would be easy for the estimation process to identify the model parameters should we use the exact outcome of the baseline simulation. To test the model in a more realistic scenario, therefore, we inject two different random noise time series into the model, effectively turning the data generation simulation model into a stochastic one with underlying noise processes not accurately captured in the estimation model (because of the autocorrelation in the driving noise). Specifically, we make the following two modifications to the model equations:

Where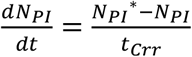
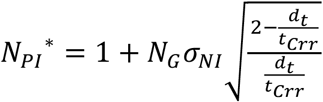
And

Where NP. are the noise terms changing infection and IFR rates. NPD is formulated similar to NPI, with parameters tCrr and σND. NG is a standard Gaussian random number generator producing a new independent draw every time step of the simulation (dt) for each of the two noise streams separately and independently.
These equations specify two first order autocorrelated Normally distributed noise streams. The autocorrelation time constant, tCrr, is set to 10 days for both streams of noise. The σNI and σND parameters are set to 0.1 (i.e. leading to standard deviation of noise around infections and deaths being 10% of the model generated baselines). As in the real world, the substantial correlation time leads to significant swings in the infection and death rates beyond those explained by model mechanisms.
We also add a “measurement” noise to both daily infections and deaths in synthetic data by drawing Negative Binomial random samples from the estimated distributions for each country at any given time and using those (rather than expected values) as the data in this estimation exercise.
To best replicate the features of actual data, the model uses actual country level data for test rates (which are exogenous inputs driving simulations) and various country level statistics such as population, population density, and age structure.
We record the data generated from this simulation for confirmed cases and deaths, corresponding to the data we have available to estimate the actual model. For each country we only record the data for the days in which we have a corresponding actual data point. We also record excess mortality counts for the subset of countries and periods for which we have such data. These three data items (two time series for confirmed infections and deaths and point estimates for excess mortalities in a subset of countries) are the inputs into the estimation process.
Estimation using synthetic data
The synthetic data generated in the previous step is available on the project’s GitHub repository. This data is then used, following the estimation process discussed in S2, to find the model parameters. This step requires no other assumptions and follows the exact process used in the main analysis. Note that we start the estimation with uninformed (uniform with large ranges) priors on all parameters.
Results and comparisons
Figure S5 reports the estimated parameters, their 95% credible intervals, and the true parameters across all 1911 (91 countries x 21 parameters each) country-level parameters of the model that impact outcomes. Overall, the estimation process successfully identifies the vast majority of parameters. For example the median distance between estimated and true values, as a percentage of the length of estimated 95% credible interval, is 12%. Moreover, the credible intervals envelope the true values rather consistently. Specifically, the 50% CI includes the true value in 44% of cases and this measure increases to 64%, 70%, 79%, and 87% for 80%, 90%, 95%, and 98% CIs respectively. The theoretical vs. actual intervals are showed in Figure S4.

Theoretical vs. actual fraction of parameters enveloped by different Credible Interval percentiles.
While not identical to the expected theoretical values, these coverage levels are close, especially in the context of very large parameter spaces and complex estimation exercises where finding reliable CIs is often harder than estimating the parameters. Figure S5 also shows that some parameters are more likely to have imprecise confidence intervals than others. More interestingly, for several parameters (e.g. fb, T0 and β) the baseline estimated values also fall outside the 95% confidence intervals and are closer to the true values. These instances point to asymmetric likelihood surfaces and the possibility that the MCMC chains may require larger samples for getting at true confidence intervals. Overall these results add to our confidence that the estimated credible intervals are in the right range, though some may be somewhat tighter than they should be.


Country-level parameter estimates and 95% credible intervals from synthetic estimation exercise (blue circles and bars) compared with true values (red cross signs) across all parameters. Numbers on the right represent the fraction of true values enveloped by the interval.
S4 DATA PRE-PROCESSING
Getting contemporaneous, comprehensive, national-level data on Covid-19 is a challenge. The most widely-cited data aggregators, such as the Johns Hopkins Center for Systems Science and Engineering’s COVID-19 database (12), OurWorldInData portal (13), and the US-focused COVID Tracking Project (14), get their data from the same few official sources, such as the US Centers for Disease Control and Prevention (CDC), the European CDC (ECDC), and the World Health Organization (WHO). These official agencies in turn get their data from national and subnational public health authorities, which ultimately rely on reports from hospitals, clinics, and private and public health labs.
As a result, idiosyncrasies in the ground-level data collection processes permeate virtually all sources of aggregate data. Most notably, data collection involves time lags, which can differ from source to source. Daily death counts could reflect the date of actual death or the date a death is registered or reported; different UK government sources, for instance, use each of these metrics.2 Daily infection or case counts could include the total new cases reported on a given date, or the total cases confirmed from that date; the latter would result in some ‘backfill’ whereby case counts for previous days can continue to increase for some time as delayed confirmations come in. Daily counts of tests conducted could report samples collected, samples processed, results reported, or a mix of these; the US CDC, for instance, reports a mix of testing by date of sample collection and date of sample delivery to the CDC.3 Aside from differences in unit of measure (people vs. tests vs. samples), there may be different time lags involved as well. In addition to these idiosyncrasies, testing data in particular is also patchy for many countries, even as testing has become more widespread. The WHO does not report country-by-country testing, nor does the JHU Covid map outside the US. Furthermore, there are sometimes irregular delays in the reporting of test results, which can create occasional unexpected spikes in reported numbers of tests, infections, or both.4
Depending on the specifics of how daily infection and test counts are reported, there can in some cases be a disjunction between the two. Because confirmed case counts largely depend on positive test results, test and infection counts should be correlated – ceteris paribus, a day with a lot of samples collected for testing should see more confirmed cases attributed to it, while a day with no sample collection should see no cases. But since cases may not be reported by the date of the test, and tests may not be reported by the date of sample collection, officially reported numbers can get out of sync in either direction.
This problem is most salient when there are clear weekly cycles in daily rates. In most of the world, particularly western countries, daily test rates are far lower on weekends than during the week. As a result, infection numbers show a clear weekly cyclical component as well. But the weekly cycles in testing and infection numbers for a given country do not always line up. Our model explicitly accounts for the effect of testing on reported infections, but we do not explicitly model the country-level idiosyncrasies of reporting and how they vary between test data and infections. Instead we account for any such lags in pre-processing of the data to align testing and case data.
The weekly cycle occurs in many countries’ death rate data as well, where it presents a different problem. A weekly cycle in testing is a behaviourally realistic part of the data-generation process, as many labs, clinics, or other testing sites for instance may be closed on weekends. As testing provides the window on the state of confirmed infections, a comparable cycle in confirmed cases is to be expected as well. By linking case confirmations to testing, our model explicitly accounts for this limited visibility on the true state of the epidemic. However, a weekly cycle in death rates almost certainly reflects different limitations of the data-generation process, typically to do with hospital staffing,5 which we do not explicitly model. As such we need to address any weekly cycle in death rates through data pre-processing as well.
To deal with these challenges, we developed a multi-step algorithm to pre-process our data before feeding it into the model for calibration. The algorithm is described below. It was implemented in Python, largely using the Pandas and NumPy packages, and the code is available in full at: https://github.com/tseyanglim/CovidGlobal.
The algorithm proceeds country-by-country, following these steps on each country.
Examine daily cumulative test data; if data are insufficient (6 or fewer data points), drop country from the dataset.
Interpolate any missing daily cumulative test data points using a piecewise cubic Hermite interpolating polynomial (PCHIP) spline. If the first reported infection is before the first reported cumulative test, also extrapolate cumulative tests back to the date of first reported infection.
Extrapolation to the date of first reported infection is necessary since both in the model and, to a large extent, in reality, reported infections require testing for confirmation.
PCHIP spline interpolation yields a continuous monotonic function with a continuous first derivative, thus avoiding generating any anomalous rapid change in daily test rate.
We used the implementation of PCHIP interpolation from the widely used SciPy package for Python.6
Calculate daily test rate as daily cumulative tests less the preceding day’s cumulative test total:
Examine the original daily cumulative test data to estimate how much of the calculated daily test rate is based on interpolated vs. original data.
Daily test rates calculated based on mostly original data should be expected to include any weekly cycles or occasional irregularities that would also be reflected in daily infection counts. Conversely, daily test rates calculated from cumulative test counts that are largely interpolated would not be expected to fully reproduce any such cycles or irregularities, since the interpolation produces a relatively smooth function.
As a rule of thumb, we examine the cumulative test data for the second half of the time from the first test to the latest test. If fewer than half the days in that window have original cumulative test data, we consider the test data to be ‘sparse’, requiring further processing.
If the test data are not sparse, account for any potential lag or other reporting delay differences between daily test rate and daily infection rate using a time-shift algorithm to estimate any such lags or delays from the data and shift the test rate time series accordingly. The time-shift algorithm ensures that any weekly cycles present in the daily infection rate data are reflected in the daily test rate data and aligned as best as possible on date, thereby accounting for the fact that model-generated reported infections depends on testing but with no time lag between test and result.
First, identify the weekly component of the time series of daily infection rate and daily test rate using a seasonal-trend decomposition based on LOESS (STL) procedure.7
STL deconstructs time series data into several components, including a trend and a seasonal component over a specified period (weekly, in this case) as well as a residual. STL is an additive decomposition, and has the advantage of allowing the seasonal component to change over time (rather than being a fixed pattern repeated exactly across the whole time series).
We used the STL implementation from the Statsmodels package for Python.8
Shift the time series over a one-week range (from −2 to +4 days of lag between test and infection reporting), calculating the cross-correlation between the weekly seasonal component of the daily infection rate data and the daily test rate data for each time shift.
Identify the time shift within this range that maximizes the cross-correlation between the infection rate and test rate data, and shift the test rate data accordingly.
If the test data are sparse, the spline interpolation will generally cut out some of any weekly cyclicality that may be present. Visual inspection of daily test rates for countries with sparse test data also shows large, irregular spikes in reported tests are not uncommon, without necessarily having concomitant irregular spikes in reported daily infection rates. As such, rather than attempting to eliminate differences in reporting lags through the time-shift algorithm described above, we instead apply a data-smoothing algorithm to both daily test rate and daily infection rate, in order to reduce any cyclicality and irregular spikes. This smoothing allows the calibration of the main model to focus on matching the underlying trends in the data.
In all cases, whether daily cumulative test data are sparse or not and whether infection and test rate data are smoothed or not, since weekly cycles in death data are reflective of reporting lags not captured in the model, daily death rate data is smoothed using the same algorithm.
The smoothing algorithm used is designed first to conserve the total number of reported cases (tests, infections, or deaths), and second to preserve some degree of variation in the time series, as some noise may be informative and retaining some is important to the calibration of the model.
Starting from when the time series of daily rate (test or infection) exceeds a specified minimum value (5/day), calculate the rolling mean of the daily rate, using a centred moving window of 11 days.
Calculate the residual between each day’s data point and the rolling mean for that day, and divide by the square root of the rolling mean, to get an adjusted deviation value:
Dividing by the square root of the rolling mean reflects a heuristic assumption that each daily rate (of infections, deaths, or tests) behaves as a Poisson process (StDev of Pois(λ) = λ0.5).
The functional result of this adjustment is that both absolute and relative magnitudes of deviations from the rolling mean are given some weight – large relative deviations when absolute values are small (and data are noisier) are not ignored, but neither do they outweigh larger absolute (but smaller relative) deviations that occur when the mean is large, which is important since most of the time series data are growing significantly over the time horizon of the model.
Calculate thresholds for identifying dips and peaks in the data based on the median of the adjusted deviations, ± one median absolute deviation (MAD) of the adjusted deviations:
Using the median absolute deviation to determine thresholds for peaks and dips is robust to outliers in the deviations, which do arise occasionally in the data.
A threshold width of one MAD is relatively narrow for outlier detection, but by inspection of the data, is about right for identifying most of the peaks and dips caused by weekly cycles in test, infection, and death rates, as well as larger outliers.
Once thresholds are calculated, iterate through the data points in the time series first forward in time from oldest to newest, filling in any ‘dips’ (data points with adjusted deviations below the lower threshold), then backward in time from newest to oldest, smoothing out any ‘peaks’ (data points with adjusted deviations above the upper threshold) that remain. Repeat the process until all data points’ adjusted deviations are within the originally calculated thresholds for the time series.
We infer that the underlying processes generating dips and peaks are somewhat different. Dips are generally the result of weekly cycles in the data, e.g. lower rates of testing or longer lags in death reporting that occur on weekends. Peaks arise to some extent due to the same weekly processes, e.g. some deaths that occur on weekends only being recorded at the start of the next week. However, some peaks, especially larger ones, may result from irregular random delays in reporting, such as large batches of tests being held up due to logistical issues and then getting processed all at once. As such the smoothing procedure for dips vs. peaks is slightly different.
The dip-filling step fills a fraction of each dip (specified as a smoothing factor) by redistributing data counts based on a multinomial draw from the subsequent few days following each dip.
First, calculate the amount to fill based on the deviation and the smoothing factor specified, in this case 0.67:
Calculate the amount redistributed from each of the following few (7) days Xt+1, Xt+2, … Xt+K, K = 7, based on a multinomial distribution as follows:
Where pt+1, pt+2, … pt+7 are calculated as:
This formulation allows some redistribution from any of the subsequent few days whose adjusted deviations exceed the focal day’s adjusted deviation, but with more redistribution from days with higher adjusted deviations.
The peak-smoothing step similarly redistributes a fraction of each peak, specified by the smoothing factor, to the preceding several days based on another multinomial draw.
First, calculate the amount to redistribute similarly to the dip-filling step:
Calculate the amount redistributed to each of the preceding several (14) days
Yt−1, Yt−2, … Yt−K, K = 14, based on a multinomial distribution as follows:
Where pt−1, pt−2, … pt−14 are calculated as:
This formulation redistributes peaks to preceding days based on the calculated rolling mean counts of those days, on the assumption that the irregular delays that generate random spikes in counts are essentially random and equally likely to affect any given unit of data over a several-day span. As such, the probability that a unit showing up in a spike due to such delays comes from a given preceding day is simply proportional to the expected count for that day, as approximated by the rolling mean.
By filling dips first before smoothing peaks, the combined algorithm largely addresses any peaks that are due primarily to weekly cycles during the dip-filling stage, such that remaining peaks that get smoothed tend to be the larger, irregular ones.


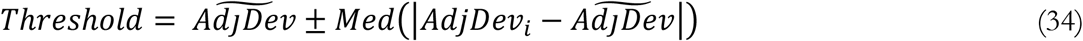
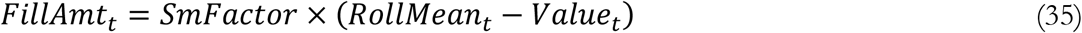
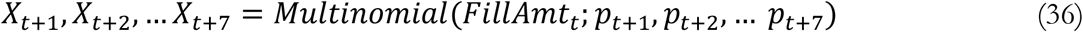

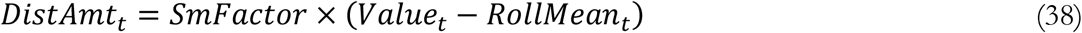
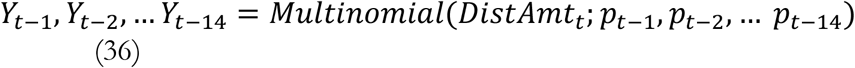

S5 EXTENDED RESULTS
Quality of fit measures
Table S3 reports two quality of fit metrics for different countries and different time series. The first four columns report Mean Absolute Error Normalized by Mean (MAEN) and the last four report the R-Squared measures. Errors for cumulative infection and deaths are followed by those for the new cases and deaths (flow variables).
Measures of fit between data and simulations for different countries. Mean Absolute Error Normalized by Mean (MAEN) and R-Squared are reported for cumulative and new cases and deaths.
Figure S6 shows the visualization of fit between data and simulations for all the countries in our sample. These graphs include data and model outputs for reported new cases (blue; left axis in thousands per day) and deaths (red; right axis in thousands per day) starting from the beginning of the epidemic in each country until 30 October 2020.

Comparison of data and simulation. New cases in blue (left axis, in thousands per day) and new deaths (red, right axis).
Estimates for true magnitude of epidemic
Estimates for true cumulative cases (blue; left axis in millions) and deaths (red; right axis in thousands) across different countries up to 30 October 2020 are reported in Figure S7.

Estimates and 95% credible intervals for true magnitude of epidemic. Cumulative cases (blue, left axis in millions) and cumulative deaths (red, right axis, in thousands)
Excess deaths
Figure S8 shows the ratio of estimated excess deaths, i.e. COVID-19 fatalities not reported as such, to reported excess deaths, i.e. deaths over historical baseline not accounted for by reported COVID-19 deaths, for the countries for which such data are available.

Ratio of estimated excess deaths to reported excess deaths.
Maximum reproduction number
Figure S9 shows the initial reproduction number (RE) occurring in each country. Reproduction numbers are changing dynamically and transient dynamics may lead to larger than equilibrium numbers if maximum RE values were used. We therefore use the 90th percentile of simulated reproduction number in this graph. Also note the large credible intervals for these estimates. This range is partly driven by what exact point of the curve is represented by the 90th percentile. It is also due to the inherent uncertainty when both reproduction number and behavioral and policy responses are estimated: one can have smaller initial RE and smaller response functions, or larger values for both, and stay consistent with the data, specially because early in the epidemic ascertainment rates are very low and data is not very informative about the true magnitude. Moreover, given the recording of RE values at their (often initial) high values, they may reflect non-representative subpopulations or events. For example the large maximum RE value estimated for Iran may be partially explained by the fact that the start of epidemic in the country coincided with the major official ceremonies and rallies at the anniversary of 1979 revolution. Those rallies probably seeded the epidemic in thousands people, and are picked up by the model to inform the maximum RE.
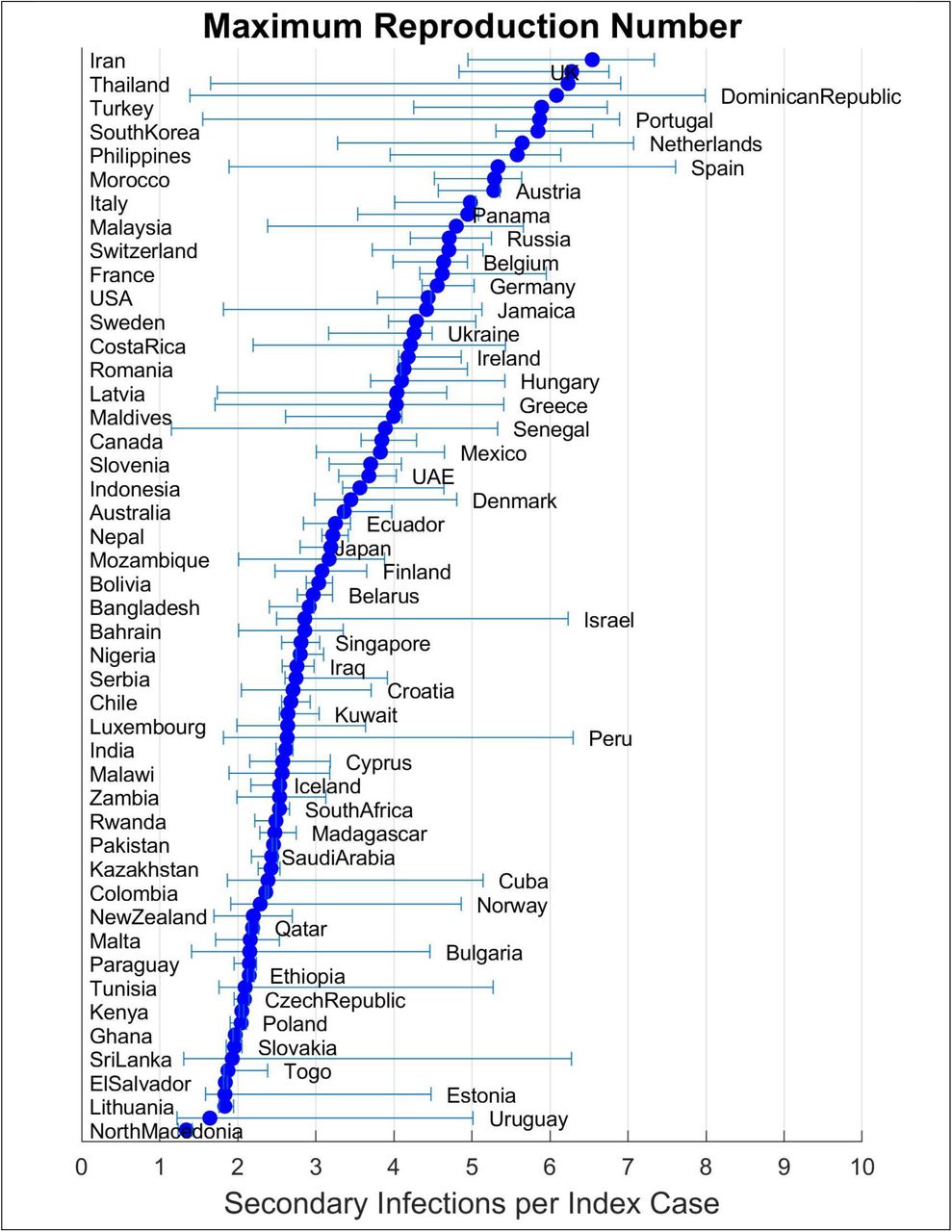
Maximum reproduction number RE for each country’s outbreak
Time to herd immunity
Figure S10 shows estimated time to herd immunity across nations. These estimates are based on time it takes before 60% of population has been infected by COVID-19. Depending on the basic reproduction number in each location and the heterogeneity in contacts, the 60% threshold will not be an exact value for most countries, but offers a reasonable intuition for the ranges of time involved and could be adjusted with a linear scaling to other thresholds. Two estimates are offered, one for the estimated number based on current true infection rates, and another based on the peak infection rates experienced in that country. The two may be the same if the current rates are the peak rates.
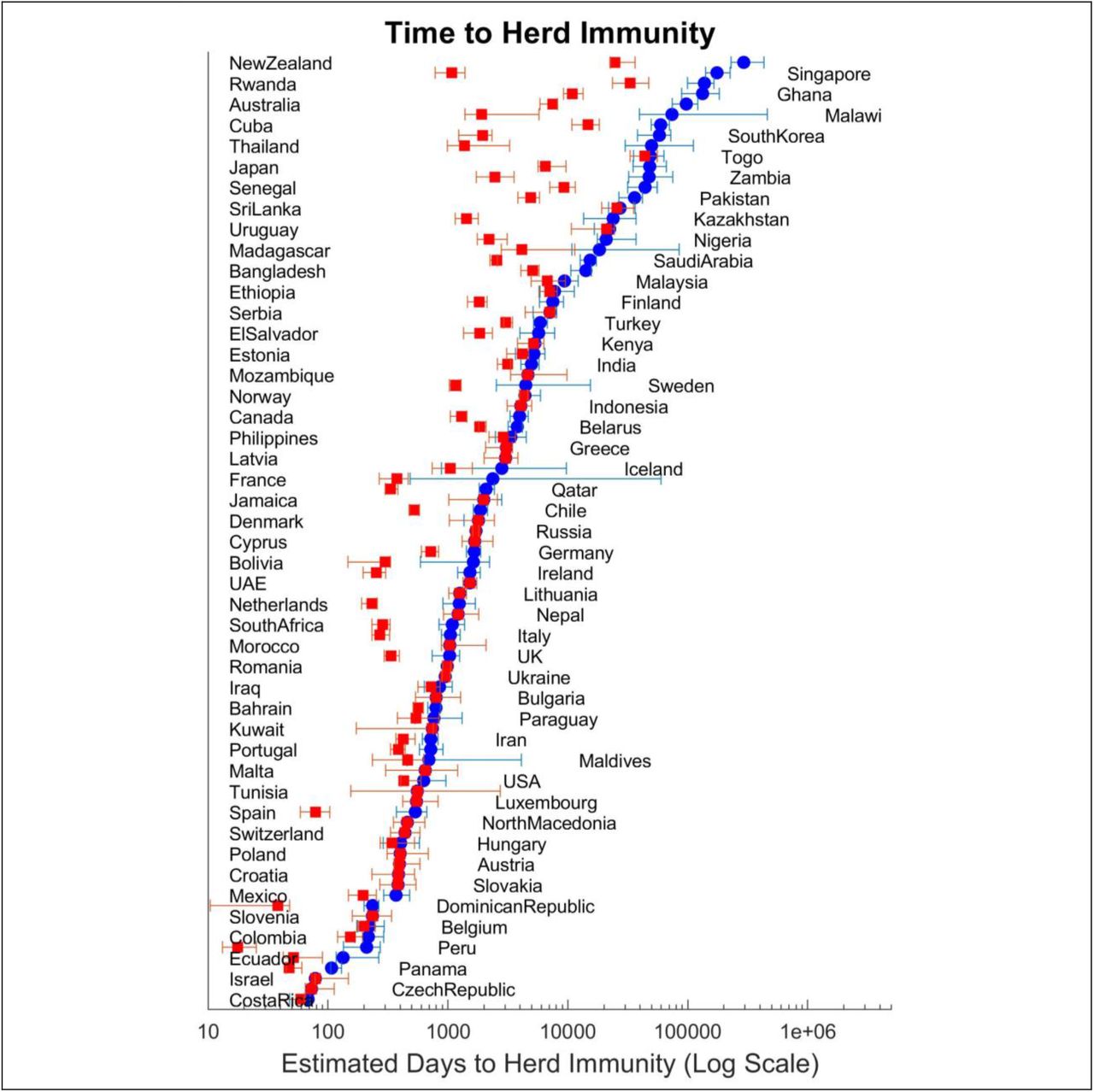
Time to 80% cumulative infection based on current infection rates (blue circles) and peak infection rates to-date (red squares) in days (log scale).
Parameter estimates
Figure S11 reports most likely estimates for the vector of country-specific parameters (θi). The figure also includes 95% credible intervals for these parameter estimates.


Parameter estimates and 95% credible regions for country-specific parameters.
Future projections
Figure S12 reports country-level projections for new cases and deaths based on the scenario I (no changes in estimated parameters; testing fixed at values observed for 30 October 2020; consistent with those reported in Figure 7 in the main paper). Note that in scenario II in the main paper (not shown here) we shift contact sensitivity to perceived risks (sC) to represent some improvement in behavioral and policy responses to infection risk, without completely changing how each country behaves. Specifically, on 30 November 2020 we shift sC to a value 20% between the one estimated for the country and 18 (80 percentile of estimated value across countries; which strengthens response in most countries and weakens it in a few).

Country level projections until Spring 2021 in scenario I. Daily cases (in thousands, blue, left axis) and daily deaths (red, right axis) are graphed.
S6 OUT OF SAMPLE PREDICTION TEST
We conducted an out of sample prediction test of the model by comparing the quality of fit for model projections for future data not used in model estimation against the version of the model using that data. We calculate the quality of fit for projections of that model (the “early model”) for data later released for the period 10 August 2020-30 October 2020. Those projections are reported in Figure S13 and are directly comparable with Figure S6. Note that we use the actual testing rates to drive the model for this prediction interval. Inspection of this graph points to various outcomes across countries, ranging from close fit for the prediction interval to a few with major discrepancies. For example, the model was able to predict the emergence of a second wave, before it was detectable in the infection data, for Austria, Canada, Russia, Poland, and the Czech Republic, and the model predicts the third waves in Iran and USA well.
The discrepancies arise from both the baseline gaps between the model and data and emerging features of the epidemic in the prediction interval. The baseline gaps typically appear because our method enforces a strong coupling among countries. For instance, keeping IFR parameters similar across countries, the model cannot explain the unexpectedly low fatality rates in Qatar and Singapore. Moreover, the model is unable to accommodate changes in responses that are not detectable in the historical data (e.g. missing the magnitude of the “second wave” when first wave is not yet complete and thus the parameters for risk perception and response are not fully identifiable).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Predictions from the model fitted with data until August 10th for the August 10th to October 30th interval. The start of prediction interval is marked with a horizonal blue line. Red numbers represent the fraction of data falling within the 95% prediction intervals.
Assessing the quality of fit requires some benchmark to compare against. Defining external benchmarks in the case of current model is complicated because no other model has attempted to simultaneously match infection and fatality data across this large set of nations. Therefore, we focus on an internal benchmark using quality of fit for the version of the model using the data from the prediction interval for estimation. Specifically, we compare the fit measures from the early model (MAEN scores for reported infection rates and death rates) against the same fit measures coming from the model estimated until October 30th. The updated version uses the data in the prediction interval and thus is likely to have a better fit than the early version of the model. The ratio of MAEN values between these two models informs the speed with which fit quality deteriorates, with values closer to one suggesting robust long-term predictions. Table S4 reports those values across different nations.
Quality of fit for future projections compared to when data is available. Mean Absolute Error Normalized by Mean (MAEN) for daily infection rates in the early model, current model (which uses data from prediction interval of June 17-July 10), and the ratio of current model’s MAEN to the early one. Note that a few countries (Cyprus, Rwanda) are included in the current model but did not meet the inclusion threshold at the time of the early model.
Mean fit ratio: 0.678
S7 SENSITIVITY ANALYSIS
Impact of Cross-country Parameter Variances
Setup-Our estimation method uses a random effects framework, which couples the parameters across different countries, specifying them as instances of some underlying distribution with a given variance. Those variance factors, explained in S2, were specified to incorporate the authors’ judgement on how different each parameter may be across different countries, based on the nature of those parameters. For instance, parameters representing physiological or virological constructs should generally vary less than those representing socio-cultural and behavioral responses. In principle, one could propose other variance factors. Assuming very large variances would essentially decouple the models for different countries, while shrinking variances towards zero will force all parameters to be the same across countries. In this section we assess the sensitivity of results to changes in those variance factors. Specifically, we re-do the analysis when all variance factors are scaled by a factor of 4, or 0.25. We re-estimate the model in each case and measure how much the following 12 outcome measures (organized into 3 groups) change compared to the baseline estimates as a result:
Country level projections for 1) Actual to reported case ratio; 2) Actual to reported death ratio; 3) Projected infection rate at the end of Winter 2021; 4) Projected death rate at the end of winter 2021;
Country level MAEN values for daily infection rates and death rates;
Aggregate (across all countries) cumulative infections, deaths, and IFR, both on 30 October 2020 and at the end of Winter 2021.
The first two groups of measures are country specific, so we report them for all countries, followed by their averages, and then the aggregate outcomes.
Results
In Table S5 and Table S6 results from these two experiments are reported. As expected, increasing allowed variances enables the model to offer a better fit to data (i.e. reduces MAEN values, thus negative values for fit statistics in the second experiment). Other sensitivities remain relatively small for most countries, showing few systematic changes in model’s predictions as in response to changes in the cross-country parameter variances. However, trajectories for a handful of countries are sensitive to these variance factors: Bangladesh, Columbia, Costa Rica, Croatia, Hungry, Kuwait, Madagascar, Mozambique, Singapore, Tunisia and USA. In these cases one would expect a separate country-specific estimation to give results that may be qualitatively different from those we find, and thus caution should be exercised.
Impact of decreasing assumed cross-country parameter variances by a factor of four. All reported outcomes measure percentage change in the given metric from baseline analysis.
Impact of increasing assumed cross-country parameter variances by a factor of four. All reported outcomes measure percentage change in the given metric from baseline analysis.
Sensitivity to Parametric Assumptions
Setup- We conducted sensitivity analysis changing all the major pre-specified (i.e. not estimated) model parameters to assess 1) How sensitive key results are to those parametric assumptions. 2) How overall model fit to data changes with changing those general parameters. In this analysis we changed each parameter by +/- 5%, and calculated the elasticities of the 12 outcome measures discussed in the previous section with respect to each parameter. Those elasticities are calculated as fractional change in the outcome measure divided by fractional change in the input parameter. As such, they are dimensionless, with values below one indicating minor to modest sensitivities.
Table S7 reports the parameters over which we conducted the sensitivity analysis, their base values, and an overview of the results where averages over country-level outcomes and fit measures are reported (first row) along with aggregate outcomes (second row; for a total of 12 outcomes per parameter in two rows). We report full country-level sensitivity results for the reported outcomes online, in the GitHub repository for the research. All reported numbers are elasticity values.
Results
Overall elasticities remain modest, under 1 in all cases and under 0.1 in half of the reported aggregates outcomes. Note that the mechanisms generating these elasticities are complex, as they emerge from new calibration of the model and thus incorporate various compensatory mechanisms and feedback effects. With that caveat in mind, we provide an overview of the results here and tables provide more in-depth outcomes.
The average residence time in hospitals has a small impact on death rates and IFR, as increasing the residence time reduces available beds and exacerbates hospital shortages. Increasing incubation period may modestly increase death under-count ratio and projected death rates, but slightly reduce projected infection rates. Impact of Onset-to-detection delay is somewhat similar. Post-detection resolution time slightly increases cases and deaths as people spend more time in infectious states. Relative risk of transmission by presymptomatics would increase undercounts, infections and deaths, with a stronger impact on case under-count (thus reducing IFR). Increasing this parameter would also slightly increase the gap between the model and case data (MAEN). Finally, increasing the sensitivity of COVID test would reduce undercounts in cases and deaths and thus bring down total cases and deaths by stronger behavioral responses.
Overview of parametric sensitivity results, reported as elasticities. Each parameter is followed by its base value, and two rows of outcomes identified on the top. First row includes averages of 4 outcomes and 2 fit measures across 91 countries. Second row includes measures calculated over all simulated populations on October 30th 2020 and March 20th 2021.
Country level outcome elasticities for model parameters
See the online Github repository at https://github.com/tseyanglim/CovidGlobal for country-level outcome tables.
Sensitivity of results to exclusion of major countries
We repeated the analysis in three additional setups, excluding the top five countries by population (India, USA, Indonesia, Pakistan, Nigeria), by true infections to date (USA, Mexico, Peru, India, Colombia), and by reported infections to date (USA, India, France, Russia, Spain) from the estimation and analysis. These analyses inform the sensitivity of overall findings to data from specific countries.
In each case we report the percentage of change in the country level and aggregate outcome measures (those defined and discussed above). Table S8 summarizes the results; full country-level outcome tables are available on the online Github repository at https://github.com/tseyanglim/CovidGlobal.
Results
Overall, the impact of excluding the top countries from analysis on historical fit and outcome measures is modest: fit quality does not change by more than 3% in 95% of country-outcome combinations. Moreover, the historical under-reporting ratios remain largely unchanged (changing by no more than 5% overall for 95% of country-outcome combinations). Cases and deaths summed up over the sample naturally change when excluding the larger countries or those with more infections (the bottom rows for each analysis). Long-term country level projections (items 3 and 4 in odd rows) change little for most countries, although a few show notable variations, suggesting high sensitivity to their response functions such that minor changes in parameters could significantly alter future outcomes. Those countries with significant sensitivity include: Costa Rica, Dominican Republic, Ethiopia, Iceland, Maldives, and Singapore. Singapore proves an outlier: given the small size of the outbreak there so far, a major outbreak, which may materialize under some of these sensitivity cases, would lead to many times more cases and deaths compared to the baseline.
Sensitivity of outcomes (in percentage change from baseline) to exclusion of top five countries by true infection, population, and reported infection. Each analysis is specified by the removed countries and followed by two rows of outcomes identified on the top. First row includes averages of 4 outcomes and 2 fit measures across 91 countries. Second row includes measures calculated over all simulated populations on 30 October 2020 and 20 March 2021.
S8 COMPLETE MODEL DOCUMENTATION
Below we provide complete model equations and units. The model, in the .mdl format, which can be opened using the Vensim simulation software, or the free Vensim model reader) is available with this appendix as well, and online at https://github.com/tseyanglim/CovidGlobal. Most of the equations are self-explanatory. The “[…]” notation is used to subscript variables over a set of members. For example, the subscript “Rgn” is used to identify different countries. Therefore [Rgn] indicates that a variable is defined separately for each member of the set “Rgn”. Other subscript ranges used in the equations are:
expnt: Used for numerically solving the probability of missing symptoms equation. pdim: Used for setting policy levels for a few variables.
Priors: Used for implementing the random effects estimation components. Each estimated parameter is mapped into an element of this subscript to simplify vector-based calculations.
Series: The data series (Infection, Death, Recovery).
TstSts: The test status including those confirmed (‘Tested’) and those unconfirmed (‘Notest’).
Complete equations and units
a[Rgn] = XIDZ (Potential Test Demand from Susceptible Population[Rgn], Positive Candidates Interested in Testing Poisson Subset Adj[Rgn], 1) Units: dmnl
AbsPrcErr[Rgn,Series] = if then else (DataIncluded[Rgn] = 0, :NA:, ZIDZ (abs (FlowResiduals[Rgn,Series]), DataFlowOverTime[Rgn,Series])) Units: dmnl
AbsStd[Priors] = 0.2, 0.3, 0.1, 0.2, 0.0002, 0.2, 10, 0.03, 6, 0.1, 0.1, 0.1, 0.8, 0.1, 1e-05, 10, 0.01, 0.005, 0.01, 10, 10, 10, 0.01, 0.5, 0.5 Units: **undefined**
Active Test Rate[Rgn] = if then else (Time < New Testing Time, DataTestRate[Rgn], External Test Rate[Rgn]) Units: Person/Day
ActiveAve[PriorEndoAve] = INITIAL(InputAve[PriorEndoAve] * (1 - SW EndoAve) + SW EndoAve * CalcAve[PriorEndoAve])
ActiveAve[PMT] = InputAve[PMT] Units: **undefined**
Activities Allowed by Government[Rgn] = 1 Units: dmnl
Additional Asymptomatic Post Detection[Rgn] = Weighted Infected Post Detection Gate[Rgn] * Additional Asymptomatic Relative to Symptomatic[Rgn] / (1 + Additional Asymptomatic Relative to Symptomatic[Rgn]) Units: Person
Additional Asymptomatic Relative to Symptomatic[Rgn] = ZIDZ (Total Asymptomatic Fraction Net[Rgn] - exp (− Covid Acuity[Rgn]), 1 - Total Asymptomatic Fraction Net[Rgn]) Units: dmnl
Adherence Fatigue Time = 100 Units: Day
AdvCntrs[Rgn] = 1 Units: dmnl
All Recovery[Rgn] = Recovery of Confirmed[Rgn] + Recovery of Untested[Rgn] + sum (Hospital Discharges[Rgn,TstSts!]) Units: Person/Day
Allocated Fraction COVID Hospitalized[Rgn] = min (1, (− Expected Positive Poisson Covid Patients[Rgn] + Sqrt (Expected Positive Poisson Covid Patients[Rgn] ^ 2 + 4 * Effective Hospital Capacity[Rgn] * Effective Hospital Capacity[Rgn])) / (2 * Effective Hospital Capacity[Rgn]))Units: dmnl
Allocated Fration NonCOVID Hospitalized[Rgn] = SMOOTHI (Allocated Fraction COVID Hospitalized[Rgn] ^ 2, Hospital Adj T, 1) Units: dmnl
alp[Rgn,Infection] = min (maxAlp, ialp * alpR[Rgn])
alp[Rgn,Death] = min (1, dalp * alpR[Rgn])
alp[Rgn,Test] = min (1, talp * alpR[Rgn]) Units: dmnl
alpR[Rgn] = 1 Units: dmnl
Area of Region[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 5) Units: Km*Km
Average Acuity Hospitalized[Rgn,Tested] = Average Acuity of Positively Tested[Rgn] * XIDZ ((1 - Probability of Missing Acuity Signal at Hospitals[Rgn,Tested] * Fraction Poisson not Hospitalized[Rgn,Tested] ^ 2), 1 - Fraction Poisson not Hospitalized[Rgn,Tested], 2 * Probability of Missing Acuity Signal at Hospitals[Rgn,Tested])
Average Acuity Hospitalized[Rgn,Notest] = ZIDZ (Average Acuity of Untested Poisson Subset[Rgn] * (1 - Probability of Missing Acuity Signal at Hospitals[Rgn,Notest] * Fraction Poisson not Hospitalized[Rgn,Notest] ^ 2), 1 - Fraction Poisson not Hospitalized[Rgn,Notest]) Units: dmnl
Average Acuity Not Hospitalized[Rgn,Notest] = ZIDZ (Average Acuity Not Hospitalized Poisson[Rgn,Notest] * Infectious not Tested or in Hospitals Poisson[Rgn], “Infected Unconfirmed Post-Detection”[Rgn])
Average Acuity Not Hospitalized[Rgn,Tested] = Average Acuity Not Hospitalized Poisson[Rgn,Tested] Units: dmnl
Average Acuity Not Hospitalized Poisson[Rgn,Tested] = Max (0, Probability of Missing Acuity Signal at Hospitals[Rgn,Tested] * Average Acuity of Positively Tested[Rgn] * Fraction Poisson not Hospitalized[Rgn,Tested]
Average Acuity Not Hospitalized Poisson[Rgn,Notest] = Max (0, Probability of Missing Acuity Signal at Hospitals[Rgn,Notest] * Average Acuity of Untested Poisson Subset[Rgn] * Fraction Poisson not Hospitalized[Rgn,Notest]) Units: dmnl
Average Acuity of Positively Tested[Rgn] = Covid Acuity[Rgn] * XIDZ ((1 - Prob Missing Symptom[Rgn] * Fraction Interested not Tested[Rgn] ^ 2), 1 - Fraction Interested not Tested[Rgn], 2 * Prob Missing Symptom[Rgn]) Units: dmnl
Average Acuity of Untested Poisson Subset[Rgn] = ZIDZ (Poisson Subset Reaching Test Gate[Rgn] * Covid Acuity[Rgn] - Positive Tests of Infected[Rgn] * Average Acuity of Positively Tested[Rgn], Poisson Subset Not Tested Passing Gate[Rgn]) Units: dmnl
b[Rgn] = ZIDZ (Testing on Living[Rgn] - Positive Candidates Interested in Testing Poisson Subset Adj[Rgn] - Potential Test Demand from Susceptible Population[Rgn], Positive Candidates Interested in Testing Poisson Subset Adj[Rgn]) Units: dmnl
Base Fatality Rate for Unit Acuity[Rgn] = 0.0006 Units: dmnl
Base Fatality Rate for Unit Acuity Net[Rgn] = INITIAL(Base Fatality Rate for Unit Acuity[Rgn] * (1 - SW Gen[BsFtRt]) + SW Gen[BsFtRt] * InputAve[BsFtRt]) Units: dmnl
BaseError = 5 Units: Person
Baseline Cumulative Cases for Learning = 0.005 Units: dmnl
Baseline Daily Fraction Susceptible Seeking Tests[Rgn] = 0.001 Units: 1/Day
Baseline Fatality Multiplier[Rgn] = INITIAL(Demographic Impact on Fatality Relative to China[Rgn] * Base Fatality Rate for Unit Acuity Net[Rgn] * Liver Disease Impact on Fatality[Rgn] * Obesity Impact on Fatality[Rgn] * Chronic Impact on Fatality[Rgn]) Units: dmnl
Baseline Risk of Transmission by Asymptomatic[Rgn] = INITIAL(Baseline Transmission Multiplier for Untested Symptomatic * Multiplier Transmission Risk for Asymptomatic Net[Rgn]) Units: dmnl
Baseline Transmission Multiplier for Untested Symptomatic = 1 Units: dmnl
Bed per Square Kilometer[Rgn] = INITIAL(Nominal Hospital Capacity[Rgn] / Area of Region[Rgn]) Units: Person/(Km*Km)
Beds per Thousand Population[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 11) Units: dmnl
CalcAve[Priors] = INITIAL(sum (RegionalInputs[Priors,Rgn!]) / ELMCOUNT(Rgn)) Units: **undefined**
cft[Rgn,p2] = lnymix[Rgn,p2]
cft[Rgn,p3] = lnymix[Rgn,p3] - lnymix[Rgn,p2]
cft[Rgn,p4] = (ln (min (100, Max (1e-06, ZIDZ (lnymix[Rgn,p4] - lnymix[Rgn,p2], lnymix[Rgn,p3] - lnymix[Rgn,p2]) / ln (2))))) Units: dmnl
Chng Cml Dth Untst Untrt[Rgn] = Deaths of Symptomatic Untested[Rgn] - Post Mortem Test Rate[Rgn] * Frac Post Mortem from Untreated[Rgn] Units: Person/Day
Chronic Death Rate[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 17) Units: dmnl
Chronic Impact on Fatality[Rgn] = INITIAL((Chronic Death Rate[Rgn] / MeanChronic) ^ Sens Chronic Impact Net[Rgn]) Units: dmnl
Cml Death Frac In Hosp[Rgn] = XIDZ (Cumulative Deaths at Hospital[Rgn,Tested] + Cumulative Deaths at Hospital[Rgn,Notest], Cumulative Deaths[Rgn], 1) Units: dmnl
Cml Death fraction in hospitals large enough = sum (if then else (Cml Death Frac In Hosp[Rgn!] < MinHspDTresh, 1, 0)) Units: dmnl
Cml Death Hsp Inc[Rgn,Tested] = Hospitalized Infectious Deaths[Rgn,Tested] + PostMortemCorrection[Rgn]
Cml Death Hsp Inc[Rgn,Notest] = Hospitalized Infectious Deaths[Rgn,Notest] - PostMortemCorrection[Rgn] Units: Person/Day
Cml Known Death Frac Hosp[Rgn] = XIDZ (Cumulative Deaths at Hospital[Rgn,Tested], Cumulative Deaths[Rgn], 1) Units: dmnl
CmltErrPW = 2 Units: dmnl
CmltPenaltyScl = 0 Units: dmnl
CmltToInclude[Series] = 0, 0, 0 Units: dmnl
Confirmation Impact on Contact[Rgn] = 0.002 Units: dmnl
Confirmed Recovered[Rgn] = INTEG(Recovery of Confirmed[Rgn], 0) Units: Person
Constant Data File :IS: ‘CovidModelInputs - ConstantData.vdf’
Contacts Relative to Normal[Rgn] = min (Voluntary Reduction in Contacts[Rgn], Activities Allowed by Government[Rgn]) Units: dmnl
Continue without Testing[Rgn] = Reaching Testing Gate[Rgn] - Symptomatic Infected to Testing[Rgn] - Untested symptomatic Infected to Hospital[Rgn] Units: Person/Day
Count Missed Death[Rgn] = if then else (Excess Death Start Count[Rgn] = :NA:, 0, if then else (Time >= Excess Death Start Count[Rgn] :AND: Time <= Excess Death End Count[Rgn], Cml Death Hsp Inc[Rgn,Notest] + Chng Cml Dth Untst Untrt[Rgn], 0)) Units: Person/Day
Covid Acuity[Rgn] = Flu Acuity * Covid Acuity Relative to Flu Net[Rgn] Units: dmnl
Covid Acuity Relative to Flu[Rgn] = 6 Units: dmnl
Covid Acuity Relative to Flu Net[Rgn] = INITIAL(Covid Acuity Relative to Flu[Rgn] * (1 - SW Gen[Acty]) + SW Gen[Acty] * InputAve[Acty]) Units: dmnl
Covid Poisson Fraction in Hospital[Rgn] = ZIDZ (Total Covid Hospitalized[Rgn], Infectious not Tested or in Hospitals Poisson[Rgn] + Infectious Confirmed Not Hospitalized[Rgn] + Total Covid Hospitalized[Rgn]) Units: dmnl
CRW[Rgn] Units: dmnl
Cumulative Cases[Rgn] = INTEG(New Cases[Rgn], 0) Units: Person
Cumulative Confirmed Cases[Rgn] = INTEG(SimFlowOverTime[Rgn,Infection], 0) Units: Person
Cumulative Confirmed Recovered[Rgn] = Confirmed Recovered[Rgn] + Cumulative Recovered at Hospitals[Rgn,Tested] Units: Person
Cumulative Death Fraction[Rgn] = ZIDZ (Cumulative Deaths[Rgn], Cumulative Deaths[Rgn] + Cumulative Recoveries[Rgn]) Units: dmnl
Cumulative Deaths[Rgn] = INTEG(Death Rate[Rgn], 0) Units: Person
Cumulative Deaths at Hospital[Rgn,TstSts] = INTEG(Cml Death Hsp Inc[Rgn,TstSts], 0) Units: Person
Cumulative Deaths of Confirmed[Rgn] = INTEG(SimFlowOverTime[Rgn,Death], 0) Units: Person
Cumulative Deaths of Confirmed Untreated[Rgn] = INTEG(Deaths of Confirmed[Rgn] + Post Mortem Test Untreated[Rgn], 0) Units: Person
Cumulative Deaths Untested Untreated[Rgn] = INTEG(Chng Cml Dth Untst Untrt[Rgn], 0) Units: Person
Cumulative Fraction Total Cases Hospitalized[Rgn] = ZIDZ (sum (Cumulative Deaths at Hospital[Rgn,TstSts!] + Cumulative Recovered at Hospitals[Rgn,TstSts!] + Hospitalized Infectious[Rgn,TstSts!]), Cumulative Cases[Rgn]) Units: dmnl
Cumulative Missed Death[Rgn] = INTEG(Count Missed Death[Rgn], 0) Units: Person
Cumulative Negative Tests[Rgn] = INTEG(Negative Test Results[Rgn], 0) Units: Person
Cumulative Recovered at Hospitals[Rgn,TstSts] = INTEG(Hospital Discharges[Rgn,TstSts], 0) Units: Person
Cumulative Recoveries[Rgn] = INTEG(All Recovery[Rgn], 0) Units: Person
Cumulative Tests Conducted[Rgn] = INTEG(SimTestRate[Rgn], 0) Units: Person
Cumulative Tests Data[Rgn] = INTEG(TstInc[Rgn], 0) Units: Person
Current Test Rate per Capita[Rgn] = INITIAL(if then else (DataLastTestRate[Rgn] = :NA:, 0, DataLastTestRate[Rgn] / Population[Rgn])) Units: 1/Day
dalp = 0.1 Units: dmnl
Data Excess Deaths[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 15) Units: Person
Data Pseudo Case Fatality[Rgn] = ZIDZ (DataCmltDeath[Rgn], DataCmltInfection[Rgn]) Units: dmnl
DataAttentionTime[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 9) Units: Day
DataCmltDeath[Rgn] Units: Person
DataCmltInfection[Rgn] Units: Person
DataCmltOverTime[Rgn,Infection] :RAW: := DataCmltInfection[Rgn]
DataCmltOverTime[Rgn,Death] :RAW: := DataCmltDeath[Rgn]
DataCmltOverTime[Rgn,Test] = DataCmltTest[Rgn] Units: Person
DataCmltTest[Rgn] Units: Person
DataFlowDeath[Rgn] Units: Person/Day
DataFlowInfection[Rgn] Units: Person/Day
DataFlowOverTime[Rgn,Infection] :RAW: := DataFlowInfection[Rgn]
DataFlowOverTime[Rgn,Death] :RAW: := DataFlowDeath[Rgn]
DataFlowOverTime[Rgn,Test] :RAW: := DataTestRate[Rgn] Units: Person/Day
DataFlowRecovery[Rgn] :RAW: Units: Person/Day
DataIncluded[Rgn] = if then else (Max (Cumulative Deaths[Rgn], Max (Cumulative Confirmed Cases[Rgn], DataCmltInfection[Rgn])) > ThrsInc[Rgn], 1, 0) * DataLimitFromTime[Rgn] Units: dmnl
DataLastTestRate[Rgn] = INITIAL(GET DATA AT TIME (DataTestRate[Rgn], min (LastTestDate[Rgn], New Testing Time))) Units: Person/Day
DataLimitFromTime[Rgn] = if then else (Time > StopDataUseTime[Rgn], 0, 1) Units: dmnl
DataTestCapacity[Rgn]Units: Person/Day
DataTestRate[Rgn] Units: Person/Day
Day of First Case Report in JHU Database = 99 Units: Day
Days per Year = 365 Units: Day/Year
Death Rate[Rgn] = Deaths of Confirmed[Rgn] + Deaths of Symptomatic Untested[Rgn] + sum (Hospitalized Infectious Deaths[Rgn,TstSts!]) Units: Person/Day
106) DeathFractionCounted[Rgn] = ZIDZ (DataCmltDeath[Rgn], Cumulative Deaths[Rgn]) Units: dmnl
Deaths of Confirmed[Rgn] = Tested Untreated Resolution[Rgn] * Fatality Rate Untreated[Rgn,Tested] Units: Person/Day
Deaths of Symptomatic Untested[Rgn] = Infectious not Tested or in Hospitals Poisson[Rgn] / “Post-Detection Phase Resolution Time” * Fatality Rate Untreated[Rgn,Notest] Units: Person/Day
Delay Order = 1 Units: dmnl
Demographic Impact on Fatality Relative to China[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 12) Units: dmnl
Di[Rgn,Series] = DataFlowOverTime[Rgn,Series] Units: Person/Day
Different Infectious Counted[Rgn] = “Pre-Symptomatic Infected”[Rgn] + Infected pre Detection[Rgn] + (Additional Asymptomatic Post Detection[Rgn] + “Poisson Not-tested Asymptomatic”[Rgn]) + (Infectious not Tested or in Hospitals Poisson[Rgn] - “Poisson Not-tested Asymptomatic”[Rgn]) + Infectious Confirmed Not Hospitalized[Rgn] + sum (Hospitalized Infectious[Rgn,TstSts!]) Units: Person
Discount Rate Annual = 0.03 Units: 1/Year
Discount Rate per Day = INITIAL(Discount Rate Annual / Days per Year) Units: 1/Day
Dread Factor in Risk Perception[Rgn] = 25 Units: dmnl
Dread Factor in Risk Perception Net[Rgn] = if then else (Response Policy Time On < Time, Dread Factor Policy * Response Policy Weight[dfcP] + (1 - Response Policy Weight[dfcP]) * Dread Factor in Risk Perception[Rgn], Dread Factor in Risk Perception[Rgn]) * Impact of Adherence Fatigue[Rgn] Units: dmnl
Dread Factor Policy = 3000 Units: dmnl
Effective Hospital Capacity[Rgn] = Nominal Hospital Capacity[Rgn] * Normalized Hospital density[Rgn] ^ Impact of Population Density on Hospital Availability[Rgn] Units: Person
eps = 0.001 Units: Person/Day
Excess Death End Count[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 14) Units: Day
Excess Death Mean Frac = 0.9 Units: dmnl
Excess Death Range Frac = 0.2 Units: dmnl
Excess Death Rate Error[Rgn] = if then else (Data Excess Deaths[Rgn] < 50, 0, ZIDZ (Cumulative Missed Death[Rgn] - Excess Death Mean Frac * Data Excess Deaths[Rgn], Excess Death Range Frac * Data Excess Deaths[Rgn]) ^ 4) Units: dmnl
Excess Death Start Count[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 13) Units: Day
Expected Positive Poisson Covid Patients[Rgn] = sum (Potential Hospital Demand[Rgn,TstSts!]) * “Post- Detection Phase Resolution Time” Units: Person
expnt : (p2-p4)
External Test Rate[Rgn] = Population[Rgn] * Policy Test Rate[Rgn] Units: Person/Day
Extrapolated Estimator[Rgn] = if then else (Covid Acuity Relative to Flu Net[Rgn] > 1, cft[Rgn,p2] + cft[Rgn,p3] * (Covid Acuity Relative to Flu Net[Rgn] - 1) ^ cft[Rgn,p4], lnymix[Rgn,p2]) Units: dmnl
F[Rgn] = Utility from Normal Activities[Rgn] / (Utility from Limited Activities[Rgn] + Utility from Normal Activities[Rgn]) Units: dmnl
F0[Rgn] = INITIAL(F[Rgn]) Units: dmnl
Fatality Rate Treated[Rgn,TstSts] = min (1, Baseline Fatality Multiplier[Rgn] * TimeVar Impact of Treatment on Fatality[Rgn] * Average Acuity Hospitalized[Rgn,TstSts] ^ Sensitivity of Fatality Rate to Acuity Net[Rgn]) Units: dmnl
Fatality Rate Untreated[Rgn,TstSts] = min (1, Baseline Fatality Multiplier[Rgn] * Average Acuity Not Hospitalized Poisson[Rgn,TstSts] ^ Sensitivity of Fatality Rate to Acuity Net[Rgn] * Time variant change in fatality[Rgn]) Units: dmnl
Final Test Rate Per Capita[Rgn] = INITIAL(Current Test Rate per Capita[Rgn] + Weight Max in Test Goal * (Max Test Rate per Capita - Current Test Rate per Capita[Rgn])) Units: 1/Day
FINAL TIME = 380 Units: Day
FlowResiduals[Rgn,Series] = if then else (DataFlowOverTime[Rgn,Series] = :NA:, :NA:, DataFlowOverTime[Rgn,Series] - MeanFlowOverTime[Rgn,Series]) Units: Person/Day
FlowToInclude[Series] = 1, 1, 0 Units: dmnl
Flu Acuity = 1 Units: dmnl
Flu Acuity Relative to Covid[Rgn] = Flu Acuity / Covid Acuity[Rgn] Units: dmnl
Frac Post Mortem from Untreated[Rgn] = SMOOTHI (ZIDZ (Deaths of Symptomatic Untested[Rgn], Deaths of Symptomatic Untested[Rgn] + Hospitalized Infectious Deaths[Rgn,Notest]), Post Mortem Test Delay, 1) Units: dmnl
FracThresh = 0.001 Units: dmnl
Fraction Covid Death In Hospitals Previously Tested[Rgn] = ZIDZ (Hospitalized Infectious Deaths[Rgn,Tested], sum (Hospitalized Infectious Deaths[Rgn,TstSts!])) Units: dmnl
Fraction Covid Hospitalized Positively Tested[Rgn] = ZIDZ (Hospitalized Infectious[Rgn,Tested], Total Covid Hospitalized[Rgn]) Units: dmnl
Fraction Infected[Rgn] = Cumulative Cases[Rgn] / Initial Population[Rgn] Units: dmnl
Fraction Interested not Tested[Rgn] = 1 - ZIDZ (Total Test on Covid Patients[Rgn], Positive Candidates Interested in Testing Poisson Subset[Rgn]) Units: dmnl
Fraction Interseted not Correctly Tested[Rgn] = 1 - (1 - Fraction Interested not Tested[Rgn]) * Sensitivity of COVID Test Units: dmnl
Fraction of Additional Symptomatic[Rgn] = Additional Asymptomatic Relative to Symptomatic[Rgn] / (1 + Additional Asymptomatic Relative to Symptomatic[Rgn]) Units: dmnl
Fraction of Fatalities Screened Post Mortem[Rgn] = Indicated Fraction Post Mortem Testing[Rgn] * Switch for Government Response[Rgn] Units: dmnl
Fraction of Population Hospitalized for Covid[Rgn] = Total Covid Hospitalized[Rgn] / Population[Rgn] Units: dmnl
Fraction Poisson not Hospitalized[Rgn,Tested] = exp (− Average Acuity of Positively Tested[Rgn] * (1 - Probability of Missing Acuity Signal at Hospitals[Rgn,Tested]))
Fraction Poisson not Hospitalized[Rgn,Notest] = exp (− Average Acuity of Untested Poisson Subset[Rgn] * (1 - Probability of Missing Acuity Signal at Hospitals[Rgn,Notest])) Units: dmnl
Fraction Seeking Test[Rgn] = 1 Units: dmnl
Fraction Tests Positive[Rgn] = ZIDZ (Positive Tests of Infected[Rgn], Testing on Living[Rgn])Units: dmnl
Fraction Tests Positive Data[Rgn] = min (1, ZIDZ (DataFlowInfection[Rgn], Active Test Rate[Rgn])) Units: dmnl
Fractional Value of Limited Activities = 0.5 Units: dmnl
Global Cases = sum (Cumulative Cases[Rgn!]) Units: Person
Global Deaths = sum (Cumulative Deaths[Rgn!]) Units: Person
Global IFR = ZIDZ (Global Deaths, Global Cases - sum (Different Infectious Counted[Rgn!])) Units: dmnl
Government Response Start Time[Rgn] = INITIAL(DataAttentionTime[Rgn] + Day of First Case Report in JHU Database) Units: Day
Herd Immunity Fraction = 0.6 Units: dmnl
Hospital Adj T = 1 Units: Day
Hospital Admission Infectious[Rgn,TstSts] = Hospital Admits All[Rgn,TstSts] Units: Person/Day
Hospital Admit Ratio[Rgn,TstSts] = XIDZ (Hospital Admits All[Rgn,TstSts], Potential Hospital Demand[Rgn,TstSts], 1) Units: dmnl
Hospital Admits All[Rgn,Tested] = Hospital Demand from Tested[Rgn] * Allocated Fraction COVID Hospitalized[Rgn]
Hospital Admits All[Rgn,Notest] = Hospital Demand from Not Tested[Rgn] * Allocated Fraction COVID Hospitalized[Rgn] Units: Person/Day
Hospital Demand from Not Tested[Rgn] = Poisson Subset Not Tested Passing Gate[Rgn] * (1 - exp (− Average Acuity of Untested Poisson Subset[Rgn] * (1 - PMAS Unconfirmed for Hospital Demand[Rgn]))) Units: Person/Day
Hospital Demand from Tested[Rgn] = Positive Tests of Infected[Rgn] * (1 - exp (− Average Acuity of Positively Tested[Rgn] * (1 - PMAS Confirmed for Hospital Demand[Rgn]))) Units: Person/Day
Hospital Discharges[Rgn,TstSts] = (1 - Fatality Rate Treated[Rgn,TstSts]) * Hospital Outflow Covid Positive[Rgn,TstSts] Units: Person/Day
Hospital Outflow Covid Positive[Rgn,TstSts] = Hospitalized Infectious[Rgn,TstSts] / Hospitalized Resolution Time Units: Person/Day
Hospitalized CFR Cumulative[Rgn,TstSts] = ZIDZ (Cumulative Deaths at Hospital[Rgn,TstSts], Cumulative Deaths at Hospital[Rgn,TstSts] + Cumulative Recovered at Hospitals[Rgn,TstSts]) Units: dmnl
Hospitalized Infectious[Rgn,TstSts] = INTEG(Hospital Admission Infectious[Rgn,TstSts] - Hospitalized Infectious Deaths[Rgn,TstSts] - Hospital Discharges[Rgn,TstSts], 0) Units: Person
Hospitalized Infectious Deaths[Rgn,TstSts] = Fatality Rate Treated[Rgn,TstSts] * Hospital Outflow Covid Positive[Rgn,TstSts] Units: Person/Day
Hospitalized Resolution Time = 20 Units: Day
Hospitalized True CFR[Rgn] = ZIDZ (sum (Hospitalized Infectious Deaths[Rgn,TstSts!]), sum (Hospital Outflow Covid Positive[Rgn,TstSts!])) Units: dmnl
Hospitalized True CFR Cumulative[Rgn] = ZIDZ (sum (Cumulative Deaths at Hospital[Rgn,TstSts!]), sum (Cumulative Deaths at Hospital[Rgn,TstSts!] + Cumulative Recovered at Hospitals[Rgn,TstSts!]))Units: dmnl
ialp = 0.1 Units: dmnl
Impact of Adherence Fatigue[Rgn] = Recent Relative Contacts[Rgn] ^ (Strength of Adherence Fatigue[Rgn] * if then else (Time to Stop Adherence Fatigue > Time, 1, SWadhFtg)) Units: dmnl
Impact of Population Density on Hospital Availability[Rgn] = 0.72 Units: dmnl
Impact of Treatment on Fatality Rate[Rgn] = 0.32 Units: dmnl
Incubation Period = 5.6 Units: Day
Indicated fraction negative demand tested[Rgn] = 1 - exp (Flu Acuity * (Prob Missing Symptom[Rgn] - 1)) Units: dmnl
Indicated fraction positive demand tested[Rgn] = 1 - exp (Covid Acuity[Rgn] * (Prob Missing Symptom[Rgn] - 1)) Units: dmnl
Indicated Fraction Post Mortem Testing[Rgn] = Fraction Covid Death In Hospitals Previously Tested[Rgn] ^ Sensitivity Post Mortem Testing to Capacity[Rgn] Units: dmnl
Indicated Risk of Life Loss[Rgn] = min (1, Switch for Government Response[Rgn] * Perceived Hazard of Death[Rgn] * Dread Factor in Risk Perception Net[Rgn] / Discount Rate per Day) Units: dmnl
Infected pre Detection[Rgn] = INTEG(Onset of Symptoms[Rgn] - Continue without Testing[Rgn] - Symptomatic Infected to Testing[Rgn] - Untested symptomatic Infected to Hospital[Rgn], 0) Units: Person
“Infected Unconfirmed Post-Detection”[Rgn] = INTEG(Continue without Testing[Rgn] - Deaths of Symptomatic Untested[Rgn] - Recovery of Untested[Rgn], 0) Units: Person
Infection Rate[Rgn] = Infectious Contacts[Rgn] * (Susceptible[Rgn] / Population[Rgn]) * Weather Effect on Transmission[Rgn] Units: Person/Day
InfectionUFractionCounted[Rgn] = ZIDZ (DataCmltInfection[Rgn], Cumulative Cases[Rgn]) Units: dmnl
Infectious Confirmed Not Hospitalized[Rgn] = INTEG(Positive Testing of Infected Untreated[Rgn] - Deaths of Confirmed[Rgn] - Recovery of Confirmed[Rgn], 0) Units: Person
Infectious Contacts[Rgn] = (“Pre-Symptomatic Infected”[Rgn] * Transmission Multiplier Presymptomatic[Rgn] + Infected pre Detection[Rgn] * Transmission Multiplier Pre Detection[Rgn] + (Additional Asymptomatic Post Detection[Rgn] + “Poisson Not-tested Asymptomatic”[Rgn]) * Baseline Risk of Transmission by Asymptomatic[Rgn] + (Infectious not Tested or in Hospitals Poisson[Rgn] - “Poisson Not-tested Asymptomatic”[Rgn]) * Baseline Transmission Multiplier for Untested Symptomatic + Infectious Confirmed Not Hospitalized[Rgn] * Transmission Multiplier for Confirmed[Rgn] + sum (Hospitalized Infectious[Rgn,TstSts!] * Transmission Multiplier for Hospitalized[Rgn,TstSts!])) * Reference Force of Infection[Rgn] * Contacts Relative to Normal[Rgn] Units: Person/Day
Infectious not Tested or in Hospitals Poisson[Rgn] = “Infected Unconfirmed Post-Detection”[Rgn] - Additional Asymptomatic Post Detection[Rgn] Units: Person
Initial Population[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 1) Units: Person
INITIAL TIME = 30 Units: Day
InpAveErr = INITIAL(sum (InpAveErrCmp[PriorEndoAve!] * PriorCounts[PriorEndoAve!])) Units: **undefined**
InpAveErrCmp[PriorEndoAve] = INITIAL((abs (CalcAve[PriorEndoAve] - InputAve[PriorEndoAve]) / Max (1e-06, CalcAve[PriorEndoAve]) * SW EndoAve)) Units: **undefined**
InputAve[Priors] = 1, 1.8, 0.47, 1, 0.0009, 0.81, 58, 0.017, 6.2, 0.1, 0.24, 0.4, 2.27, 0.52, 0.00055, 0.76, 5.9, 2.07, 0.55, 1e-06, 1e-06, 1e-06, 0.28, 0, 0 Units: **undefined**
IrD : Travel,InformalDeath
Known death fraction in hospitals large enough = sum (if then else (Cml Known Death Frac Hosp[Rgn!] < MinHspDTreshAdv, 1, 0) * AdvCntrs[Rgn!]) Units: dmnl
lastTestData[Rgn] = INITIAL(GET DATA Last TIME (DataTestRate[Rgn])) Units: Day
LastTestDate[Rgn] = INITIAL(GET DATA Last TIME (DataTestRate[Rgn])) Units: Day
Learning and Death Reduction Rate[Rgn1] = 0 Units: dmnl
Liver Disease Impact on Fatality[Rgn] = INITIAL((Liver Disease Rate[Rgn] / MeanLiver) ^ Sens Liver Impact Net[Rgn]) Units: dmnl
Liver Disease Rate[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 18) Units: dmnl
lnymix[Rgn,expnt] = - ln (Max (1e-06, 1 - Ymix[Rgn,expnt])) Units: dmnl
lnymix 0[Rgn,expnt] = - ln (Max (1e-06, 1 - Ymix[Rgn,expnt])) Units: dmnl
Max Test Rate per Capita = 0.001 Units: 1/Day
Max Time Data Used = 380 Units: Day
maxAlp = 1 Units: dmnl
MaxData[Rgn] = INITIAL(GET DATA MAX (DataCmltInfection[Rgn], 0, 500)) Units: Person
MaxRTresh = 8 Units: dmnl
MeanChronic = GET VDF CONSTANTS(Constant Data File, ‘MeanChronic’, 1) Units: dmnl
MeanFlowOverTime[Rgn,Infection] = Post Mortem Test Rate[Rgn] + Positive Tests of Infected[Rgn]
MeanFlowOverTime[Rgn,Death] = Recorded Deaths[Rgn]
MeanFlowOverTime[Rgn,Test] = Total Simulated Tests[Rgn] Units: Person/Day
MeanLiver = GET VDF CONSTANTS(Constant Data File, ‘MeanLiver’, 1) Units: dmnl
MeanObesity = GET VDF CONSTANTS(Constant Data File, ‘MeanObesity’, 1) Units: dmnl
Min Contact Fraction[Rgn] = 0.04 Units: dmnl
Min Excess Death Attributable to COVID = 0.5 Units: dmnl
Min Fatality Multiplier = 0.1 Units: dmnl
MinAdjT = 1 Units: Day
MinHspDTresh = 0.2 Units: dmnl
MinHspDTreshAdv = 0.8 Units: dmnl
MinSuscTresh = 0.7 Units: dmnl
Mu[Rgn,Series] = Max (eps, MeanFlowOverTime[Rgn,Series]) Units: Person/Day
Multiplier Recent Infections to Test[Rgn] = 45 Units: dmnl
Multiplier Transmission Risk for Asymptomatic[Rgn] = 0.3 Units: dmnl
Multiplier Transmission Risk for Asymptomatic Net[Rgn] = INITIAL(Multiplier Transmission Risk for Asymptomatic[Rgn] * (1 - SW Gen[MTrAsym]) + SW Gen[MTrAsym] * InputAve[MTrAsym]) Units: dmnl
NBL1[Rgn,Series] = if then else (DataFlowOverTime[Rgn,Series] = 0, - ln (1 + alp[Rgn,Series] * Mu[Rgn,Series])/ alp[Rgn,Series], 0) Units: dmnl
NBL2[Rgn,Series] = if then else (DataFlowOverTime[Rgn,Series] > 0, GAMMA LN (Di[Rgn,Series] + 1 / alp[Rgn,Series]) - GAMMA LN (1 / alp[Rgn,Series]) - GAMMA LN (Di[Rgn,Series] + 1) - (Di[Rgn,Series] + 1 / alp[Rgn,Series]) * ln (1 + alp[Rgn,Series] * Mu[Rgn,Series]) + Di[Rgn,Series] * (ln (alp[Rgn,Series]) + ln (Mu[Rgn,Series])), 0) Units: dmnl
NBL3[Rgn,Series] = if then else (Di[Rgn,Series] > 0, - GAMMA LN (Di[Rgn,Series] + 1) - (Di[Rgn,Series] + 1 / alp[Rgn,Series]) * ln (1 + alp[Rgn,Series] * Mu[Rgn,Series]) + Di[Rgn,Series] * (ln (alp[Rgn,Series]) + ln (Mu[Rgn,Series])), 0) Units: dmnl
NBLLFlow[Rgn,Series] = (NBL1[Rgn,Series] + NBL2[Rgn,Series]) * FlowToInclude[Series] * DataIncluded[Rgn] Units: dmnl
Negative Test Results[Rgn] = Testing on Living[Rgn] - Positive Tests of Infected[Rgn] Units: Person/Day
New Cases[Rgn] = Infection Rate[Rgn] + Patient Zero Arrival[Rgn] Units: Person/Day
New Testing Time = 1000 Units: Day
Nominal Hospital Capacity[Rgn] = INITIAL(Initial Population[Rgn] * Beds per Thousand Population[Rgn] / 1000 Units: Person
Normalized Hospital density[Rgn] = INITIAL(Bed per Square Kilometer[Rgn] / Reference Hospital Density) Units: dmnl
Not too few susceptibles = sum (if then else (SuscFrac[Rgn!] < MinSuscTresh, 1, 0)) Units: dmnl
NSeed = 1 Units: dmnl
numTrial[Rgn,UsedSeries] = INITIAL(Max (1.01, 1 / alp[Rgn,UsedSeries])) Units: dmnl
Obesity Impact on Fatality[Rgn] = INITIAL((Obesity Rates[Rgn] / MeanObesity) ^ Sens Obesity Impact Net[Rgn]) Units: dmnl
Obesity Rates[Rgn] = GET VDF CONSTANTS(Constant Data File, ‘DataConstants[Rgn]’, 16) Units: dmnl
Onset of Symptoms[Rgn] = DELAY N (Infection Rate[Rgn], Incubation Period, 0, Delay Order) Units: Person/Day
Onset to Detection Delay = 5 Units: Day
Overall Death Fraction[Rgn] = ZIDZ (Death Rate[Rgn], All Recovery[Rgn]) Units: dmnl
Patient Zero Arrival[Rgn] = if then else (Time < Patient Zero Arrival Time[Rgn] :AND: Time + TIME STEP >= Patient Zero Arrival Time[Rgn], PatientZero / TIME STEP, 0) Units: Person/Day
Patient Zero Arrival Time[Rgn] = 1 Units: Day
PatientZero = 1 Units: Person
payoff = 0 Units: dmnl
pdim : tstP,dfcP,dgtP,scuP
Perceived Hazard of Death[Rgn] = (Weight on Reported Probability of Infection[Rgn] * Reported Hazard of Death[Rgn] + (1 - Weight on Reported Probability of Infection[Rgn]) * True Hazard of death[Rgn]) Units: 1/Day
Perceived Risk of Life Loss[Rgn] = INTEG((Indicated Risk of Life Loss[Rgn] - Perceived Risk of Life Loss[Rgn]) / if then else (Indicated Risk of Life Loss[Rgn] > Perceived Risk of Life Loss[Rgn], Time to Upgrade Risk[Rgn], Time to Downgrade Risk Net[Rgn]), 0) Units: dmnl
PG1 : PG
PMAS Confirmed for Hospital Demand[Rgn] = (1 - Reference COVID Hospitalization Fraction Confirmed[Rgn]) ^ (1 / Average Acuity of Positively Tested[Rgn]) Units: dmnl
PMAS Unconfirmed for Hospital Demand[Rgn] = PMAS Confirmed for Hospital Demand[Rgn] + (1 - PMAS Confirmed for Hospital Demand[Rgn]) * Untested PMAS Gap with Tested[Rgn] Units: dmnl
“Poisson Not-tested Asymptomatic”[Rgn] = Infectious not Tested or in Hospitals Poisson[Rgn] * exp (− Average Acuity Not Hospitalized Poisson[Rgn,Notest]) Units: Person
Poisson Subset Not Tested Passing Gate[Rgn] = Poisson Subset Reaching Test Gate[Rgn] - Positive Tests of Infected[Rgn]Units: Person/Day
Poisson Subset Reaching Test Gate[Rgn] = Reaching Testing Gate[Rgn] / (1 + Additional Asymptomatic Relative to Symptomatic[Rgn]) Units: Person/Day
Policy Test Rate[Rgn] = if then else (Time < New Testing Time, Current Test Rate per Capita[Rgn], Final Test Rate Per Capita[Rgn]) Units: 1/Day
Population[Rgn] = Infected pre Detection[Rgn] + “Infected Unconfirmed Post-Detection”[Rgn] + Susceptible[Rgn] + Recovered Unconfirmed[Rgn] + Confirmed Recovered[Rgn] + Infectious Confirmed Not Hospitalized[Rgn] + “Pre-Symptomatic Infected”[Rgn] + sum (Hospitalized Infectious[Rgn,TstSts!]) + sum (Cumulative Recovered at Hospitals[Rgn,TstSts!]) Units: Person
PopulationCheck[Rgn] = Recovered Unconfirmed[Rgn] + Confirmed Recovered[Rgn] + sum (Cumulative Recovered at Hospitals[Rgn,TstSts!]) + Different Infectious Counted[Rgn] + Susceptible[Rgn] Units: Person
Positive Candidates Interested in Testing Poisson Subset[Rgn] = Poisson Subset Reaching Test Gate[Rgn] * Fraction Seeking Test[Rgn] Units: Person/Day
Positive Candidates Interested in Testing Poisson Subset Adj[Rgn] = Max (0.001 * Potential Test Demand from Susceptible Population[Rgn], Positive Candidates Interested in Testing Poisson Subset[Rgn]) Units: Person/Day
Positive Testing of Infected Untreated[Rgn] = Positive Tests of Infected[Rgn] * Fraction Poisson not Hospitalized[Rgn,Tested] Units: Person/Day
Positive Tests of Infected[Rgn] = Positive Candidates Interested in Testing Poisson Subset[Rgn] * (1 - Fraction Interseted not Correctly Tested[Rgn]) Units: Person/Day
Post Mortem Test Delay = 1 Units: Day
Post Mortem Test Rate[Rgn] = Post Mortem Tests Total[Rgn] * Sensitivity of COVID Test Units: Person/Day
Post Mortem Test Untreated[Rgn] = Post Mortem Test Rate[Rgn] * Frac Post Mortem from Untreated[Rgn] Units: Person/Day
Post Mortem Testing Need[Rgn] = SMOOTHI ((Deaths of Symptomatic Untested[Rgn] + Hospitalized Infectious Deaths[Rgn,Notest]) * Fraction of Fatalities Screened Post Mortem[Rgn], Post Mortem Test Delay, 0)
Units: Person/Day
Post Mortem Tests Total[Rgn] = min (Post Mortem Testing Need[Rgn], Active Test Rate[Rgn]) Units: Person/Day “Post-Detection Phase Resolution Time” = 10 Units: Day
PostMortemCorrection[Rgn] = min (Hospitalized Infectious[Rgn,Notest] / MinAdjT, Post Mortem Test Rate[Rgn] * (1 - Frac Post Mortem from Untreated[Rgn])) Units: Person/Day
Potential Hospital Demand[Rgn,Notest] = Hospital Demand from Not Tested[Rgn]
Potential Hospital Demand[Rgn,Tested] = Hospital Demand from Tested[Rgn] Units: Person/Day
Potential Test Demand from Susceptible Population[Rgn] = (Susceptible[Rgn] + Recovered Unconfirmed[Rgn] + Cumulative Recovered at Hospitals[Rgn,Notest]) * (Baseline Daily Fraction Susceptible Seeking Tests[Rgn] * Fraction Seeking Test[Rgn] + Multiplier Recent Infections to Test[Rgn] / Population[Rgn] * Recent Detected Infections[Rgn]) Units: Person/Day
“Pre-Symptomatic Infected”[Rgn] = INTEG(Infection Rate[Rgn] + Patient Zero Arrival[Rgn] - Onset of Symptoms[Rgn], 0) Units: Person
PriorCounts[PriorEndoAve] = INITIAL(if then else (PriorEndoAve < 26, 1, 0)) Units: dmnl
PriorEndoAve : UpAdj,DwnAdj,RFI,RfSkTs,WRpPIn,MInfTs,MnCnFrc,SnCnRdUt,CfImCn,ImPDnHs,ImTrFt,DrdFac,MxHsFr,B sFtRt,SnsWth,Acty,SnFtAc,TtAsyFr,ObsImp,ChrImp,LivImp,MTrAsym,HspLrng,AdhrFtg
PriorErrs[Rgn,Priors] = INITIAL(ZIDZ (ActiveAve[Priors] - RegionalInputs[Priors,Rgn], (AbsStd[Priors] * StdScale)) ^ 2 / 2) Units: **undefined**
PriorGen : BsFtRt,SnsWth,Acty,SnFtAc,TtAsyFr,ObsImp,ChrImp,LivImp,MTrAsym
Priors :
UpAdj,DwnAdj,RFI,PMT,RfSkTs,WRpPIn,MInfTs,MnCnFrc,SnCnRdUt,CfImCn,ImPDnHs,ImTrFt,DrdFac,Mx HsFr,BsFtRt,SnsWth,Acty,SnFtAc,TtAsyFr,ObsImp,ChrImp,LivImp,MTrAsym,HspLrng,AdhrFtg
Prob Missing Symptom[Rgn] = Max (0, ln (Y[Rgn]) / Flu Acuity + 1) Units: dmnl
Probability of Missing Acuity Signal at Hospitals[Rgn,Tested] = ZIDZ (ln (Max (1e-06, 1 - ZIDZ (Hospital Admits All[Rgn,Tested], Positive Tests of Infected[Rgn]))), Average Acuity of Positively Tested[Rgn]) + 1
Probability of Missing Acuity Signal at Hospitals[Rgn,Notest] = ZIDZ (ln (Max (1e-06, 1 - ZIDZ (Hospital Admits All[Rgn,Notest], Poisson Subset Not Tested Passing Gate[Rgn]))), Average Acuity of Untested Poisson Subset[Rgn]) + 1 Units: dmnl
PseudoCFR Units: dmnl
R Effective Reproduction Rate[Rgn] = ZIDZ (Infection Rate[Rgn], Total Weighted Infected Population[Rgn]) * Total Disease Duration Units: dmnl
RandFlowTime = 1000 Units: Day
Reaching Testing Gate[Rgn] = Infected pre Detection[Rgn] / Onset to Detection Delay Units: Person/Day
Realistic R0 = sum (if then else (R Effective Reproduction Rate[Rgn!] > MaxRTresh, 1, 0)) Units: dmnl
Recent Detected Infections[Rgn] = SMOOTHI (Positive Tests of Infected[Rgn], Time to Respond with Tests, 0) Units: Person/Day
Recent Relative Contacts[Rgn] = SMOOTHI (Contacts Relative to Normal[Rgn], Adherence Fatigue Time, 1) Units: dmnl
Recorded Deaths[Rgn] = Post Mortem Test Rate[Rgn] + Deaths of Confirmed[Rgn] + Hospitalized Infectious Deaths[Rgn,Tested] Units: Person/Day
Recovered Unconfirmed[Rgn] = INTEG(Recovery of Untested[Rgn], 0) Units: Person
Recovery of Confirmed[Rgn] = Tested Untreated Resolution[Rgn] * (1 - Fatality Rate Untreated[Rgn,Tested]) Units: Person/Day
Recovery of Untested[Rgn] = (“Infected Unconfirmed Post-Detection”[Rgn] / “Post-Detection Phase Resolution Time”) - Deaths of Symptomatic Untested[Rgn] Units: Person/Day
Reference COVID Hospitalization Fraction Confirmed[Rgn] = 0.7 Units: dmnl
Reference Force of Infection[Rgn] = 0.6 Units: 1/Day
Reference Hospital Density = 6.06 Units: Person/(Km*Km)
RegionalInputs[UpAdj,Rgn] = Log (Time to Upgrade Risk[Rgn], 10)
RegionalInputs[DwnAdj,Rgn] = Log (Time to Downgrade Risk[Rgn], 10)
RegionalInputs[RFI,Rgn] = Reference Force of Infection[Rgn]
RegionalInputs[PMT,Rgn] = Sensitivity Post Mortem Testing to Capacity[Rgn]
RegionalInputs[RfSkTs,Rgn] = Baseline Daily Fraction Susceptible Seeking Tests[Rgn]
RegionalInputs[WRpPIn,Rgn] = Weight on Reported Probability of Infection[Rgn]
RegionalInputs[MInfTs,Rgn] = Multiplier Recent Infections to Test[Rgn]
RegionalInputs[MnCnFrc,Rgn] = Min Contact Fraction[Rgn]
RegionalInputs[SnCnRdUt,Rgn] = Sensitivity of Contact Reduction to Utility[Rgn]
RegionalInputs[CfImCn,Rgn] = Confirmation Impact on Contact[Rgn]
RegionalInputs[ImPDnHs,Rgn] = Impact of Population Density on Hospital Availability[Rgn]
RegionalInputs[ImTrFt,Rgn] = Impact of Treatment on Fatality Rate[Rgn]
RegionalInputs[DrdFac,Rgn] = Log (Dread Factor in Risk Perception[Rgn], 10)
RegionalInputs[MxHsFr,Rgn] = Reference COVID Hospitalization Fraction Confirmed[Rgn]
RegionalInputs[BsFtRt,Rgn] = Base Fatality Rate for Unit Acuity Net[Rgn]
RegionalInputs[SnsWth,Rgn] = Sensitivity to Weather Net[Rgn]
RegionalInputs[Acty,Rgn] = Covid Acuity Relative to Flu Net[Rgn]
RegionalInputs[SnFtAc,Rgn] = Sensitivity of Fatality Rate to Acuity Net[Rgn]
RegionalInputs[TtAsyFr,Rgn] = Total Asymptomatic Fraction Net[Rgn]
RegionalInputs[ObsImp,Rgn] = Sens Obesity Impact Net[Rgn]
RegionalInputs[ChrImp,Rgn] = Sens Chronic Impact Net[Rgn]
RegionalInputs[LivImp,Rgn] = Sens Liver Impact Net[Rgn]
RegionalInputs[MTrAsym,Rgn] = Multiplier Transmission Risk for Asymptomatic Net[Rgn]
RegionalInputs[HspLrng,Rgn] = Learning and Death Reduction Rate[Rgn]
RegionalInputs[AdhrFtg,Rgn] = Strength of Adherence Fatigue[Rgn] Units: **undefined**
Relative Risk of Transmission by Hospitalized = 1 Units: dmnl
Relative Risk of Transmission by Presymptomatic = 1 Units: dmnl
Reported Hazard of Death[Rgn] = SimFlowOverTime[Rgn,Death] / Susceptible[Rgn] Units: 1/Day
Response Policy Time On = 1000 Units: Day
Response Policy Weight[pdim] = 0 Units: dmnl
Rgn:
Australia,Austria,Bahrain,Bangladesh,Belarus,Belgium,Bolivia,Bulgaria,Canada,Chile,Colombia,CostaRica,Croatia,Cuba,Cyprus,CzechRepublic,Denmark,DominicanRepublic,Ecuador,ElSalvador,Estonia,Ethiopia,Finland,France,Germany,Ghana,Greece,Hungary,Iceland,India,Indonesia,Iran,Iraq,Ireland,Israel,Italy,Jamaica,Japan,Kazakhstan,Kenya,Kuwait,Latvia,Lithuania,Luxembourg,Madagascar,Malawi,Malaysia,Maldives,Malta,Mexico,Morocco,Mozambique,Nepal,Netherlands,NewZealand,Nigeria,NorthMacedonia,Norway,Pakistan,Panama,Paraguay,Peru,Philippines,Poland, Portugal,Qatar,Romania,Russia,Rwanda,SaudiArabia,Senegal,Serbia,Singapore,Slovakia,Slovenia,SouthAfrica,South Korea,Spain,SriLanka,Sweden,Switzerland,Thailand,Togo,Tunisia,Turkey,UAE,UK,Ukraine,Uruguay,USA,Zambia
Rgn1 : Rgn
SAVEPER = 1 Units: Day
Sens Chronic Impact = 1e-06 Units: dmnl
Sens Chronic Impact Net[Rgn] = INITIAL(Sens Chronic Impact * (1 - SW Gen[ChrImp]) + SW Gen[ChrImp] * InputAve[ChrImp]) Units: dmnl
Sens Liver Impact = 1e-06 Units: dmnl
Sens Liver Impact Net[Rgn] = INITIAL(Sens Liver Impact * (1 - SW Gen[LivImp]) + SW Gen[LivImp] * InputAve[LivImp]) Units: dmnl
Sens Obesity Impact = 1e-06 Units: dmnl
Sens Obesity Impact Net[Rgn] = INITIAL(Sens Obesity Impact * (1 - SW Gen[ObsImp]) + SW Gen[ObsImp] * InputAve[ObsImp]) Units: dmnl
SensCovidUntestedAdmission = 1 Units: dmnl
Sensitivity of Contact Reduction to Utility[Rgn] = 15 Units: dmnl
Sensitivity of Contact Reduction to Utility Net[Rgn] = if then else (Response Policy Time On < Time, Sensitivity of Contact Reduction to Utility Policy * Response Policy Weight[scuP] + (1 - Response Policy Weight[scuP]) * Sensitivity of Contact Reduction to Utility[Rgn], Sensitivity of Contact Reduction to Utility[Rgn]) * Impact of Adherence Fatigue[Rgn] Units: dmnl
Sensitivity of Contact Reduction to Utility Policy = 10 Units: dmnl
Sensitivity of COVID Test = 0.7 Units: dmnl
Sensitivity of Fatality Rate to Acuity[Rgn] = 2 Units: dmnl
Sensitivity of Fatality Rate to Acuity Net[Rgn] = INITIAL(Sensitivity of Fatality Rate to Acuity[Rgn] * (1 - SW Gen[SnFtAc]) + SW Gen[SnFtAc] * InputAve[SnFtAc]) Units: dmnl
Sensitivity Post Mortem Testing to Capacity[Rgn] = 1 Units: dmnl
Sensitivity to Weather = 0.76 Units: dmnl
Sensitivity to Weather Net[Rgn] = INITIAL(Sensitivity to Weather * (1 - SW Gen[SnsWth]) + SW Gen[SnsWth] * InputAve[SnsWth]) Units: dmnl
Series : Infection,Death,Test
SeriesErrorTerm[Rgn,Series] = if then else (DataCmltOverTime[Rgn,Series] = :NA:, 0, (abs (DataCmltOverTime[Rgn,Series] - SimCmltOverTime[Rgn,Series])) ^ CmltErrPW) / (BaseError + DataCmltOverTime[Rgn,Series]) * CmltPenaltyScl * CmltToInclude[Series] * DataIncluded[Rgn]Units: dmnl
Sim Pseudo Case Fatality[Rgn] = ZIDZ (Cumulative Deaths of Confirmed[Rgn], Cumulative Confirmed Cases[Rgn]) Units: dmnl
SimCmltOverTime[Rgn,Infection] = Cumulative Confirmed Cases[Rgn]
SimCmltOverTime[Rgn,Death] = Cumulative Deaths of Confirmed[Rgn]
SimCmltOverTime[Rgn,Test] = Cumulative Tests Conducted[Rgn] Units: Person
SimFlowOverTime[Rgn,UsedSeries] = if then else (SwitchRandFlowTime < Time, RANDOM NEGATIVE BINOMIAL (−1, 1e+06, successP[Rgn,UsedSeries], numTrial[Rgn,UsedSeries], 0, 1, NSeed), Mu[Rgn,UsedSeries]) Units: Day/Person
SimTestRate[Rgn] = Total Simulated Tests[Rgn] Units: Person/Day
SqrdErr[Rgn,Series] = if then else (FlowResiduals[Rgn,Series] = :NA:, :NA:, FlowResiduals[Rgn,Series] ^ 2) Units: Person*Person/(Day*Day)
StdScale = 1 Units: dmnl
StopDataUseTime[Rgn] = INITIAL(min (lastTestData[Rgn], Max Time Data Used))Units: Day
Strength of Adherence Fatigue[Rgn] = 0 Units: dmnl
successP[Rgn,UsedSeries] = 1 / (1 + alp[Rgn,UsedSeries] * Mu[Rgn,UsedSeries]) Units: dmnl
Susceptible[Rgn] = INTEG(− Infection Rate[Rgn], Initial Population[Rgn]) Units: Person
SuscFrac[Rgn] = Susceptible[Rgn] / Population[Rgn] Units: dmnl
SW EndoAve = INITIAL(if then else (ELMCOUNT(Rgn) > 1, 1, 0)) Units: dmnl
SW Gen[PriorGen] = 0 Units: dmnl
SWadhFtg = 0 Units: dmnl
Switch for Government Response[Rgn] = if then else (Time > Government Response Start Time[Rgn], 1, 0) Units: dmnl
SwitchRandFlow = 1 Units: dmnl
SwitchRandFlowTime = if then else (SwitchRandFlow = 1, min (Max Time Data Used, RandFlowTime), 1000) Units: Day
Symptomatic Fraction in Poisson[Rgn] = INITIAL(1 - exp (− Covid Acuity[Rgn])) Units: dmnl
Symptomatic Fraction Negative[Rgn] = INITIAL(1 - exp (− Flu Acuity)) Units: dmnl
Symptomatic Infected to Testing[Rgn] = Positive Testing of Infected Untreated[Rgn] + Hospital Admission Infectious[Rgn,Tested] Units: Person/Day
t3[Rgn] = (−9 * b[Rgn] + 1.7321 * Sqrt (4 * a[Rgn] ^ 3 + 27 * b[Rgn] ^ 2)) ^ (1 / 3) Units: dmnl
talp = 5 Units: dmnl
Tested Untreated Resolution[Rgn] = Infectious Confirmed Not Hospitalized[Rgn] / “Post-Detection Phase Resolution Time” Units: Person/Day
TestErrorFrac = 0.0001 Units: dmnl
TestFlowErr[Rgn] = ((DataFlowOverTime[Rgn,Test] - MeanFlowOverTime[Rgn,Test]) * WTestFlowErr[Rgn])
^ 2 Units: dmnl
Testing Capacity Net of Post Mortem Tests[Rgn] = Active Test Rate[Rgn] - Post Mortem Tests Total[Rgn] Units: Person/Day
Testing Demand[Rgn] = Positive Candidates Interested in Testing Poisson Subset[Rgn] * Symptomatic Fraction in Poisson[Rgn] + Potential Test Demand from Susceptible Population[Rgn] * Symptomatic Fraction Negative[Rgn]
Units: Person/Day
Testing on Living[Rgn] = min (Testing Capacity Net of Post Mortem Tests[Rgn], Testing Demand[Rgn])Units: Person/Day
Tests on Negative Patients[Rgn] = Testing on Living[Rgn] * ZIDZ (Indicated fraction negative demand tested[Rgn] * Potential Test Demand from Susceptible Population[Rgn], Indicated fraction negative demand tested[Rgn] * Potential Test Demand from Susceptible Population[Rgn] + Indicated fraction positive demand tested[Rgn] * Positive Candidates Interested in Testing Poisson Subset[Rgn]) Units: Person/Day
Tests Per Million[Rgn] = Cumulative Tests Data[Rgn] / Initial Population[Rgn] * 1e+06Units: dmnl
ThrsInc[Rgn] = Max (FracThresh * MaxData[Rgn], 50) Units: Person
TIME STEP = 0.25 Units: Day
Time to Adjust Testing = 30 Units: Day
Time to Downgrade Risk[Rgn] = 60 Units: Day
Time to Downgrade Risk Net[Rgn] = if then else (Response Policy Time On < Time, Time to Downgrade Risk Policy * Response Policy Weight[dgtP] + (1 - Response Policy Weight[dgtP]) * Time to Downgrade Risk[Rgn], Time to Downgrade Risk[Rgn]) Units: Day
Time to Downgrade Risk Policy = 300 Units: Day
Time to Herd Immunity[Rgn] = XIDZ (Herd Immunity Fraction * Susceptible[Rgn], Total Weighted Infected Population[Rgn] / Total Disease Duration, 0) Units: Day
Time to Respond with Tests = 5 Units: Day
Time to Stop Adherence Fatigue = 1000 Units: Day
Time to Upgrade Risk[Rgn] = 10 Units: Day
Time variant change in fatality[Rgn] = Max (Min Fatality Multiplier, (Max (Baseline Cumulative Cases for Learning, Cumulative Cases[Rgn] / Initial Population[Rgn]) / Baseline Cumulative Cases for Learning) ^ (− Learning and Death Reduction Rate[Rgn])) Units: dmnl
TimeVar Impact of Treatment on Fatality[Rgn] = Impact of Treatment on Fatality Rate[Rgn] * Time variant change in fatality[Rgn] Units: dmnl
Total Asymptomatic Fraction[Rgn] = 0.5 Units: dmnl
Total Asymptomatic Fraction Net[Rgn] = INITIAL(Total Asymptomatic Fraction[Rgn] * (1 - SW Gen[TtAsyFr])
+ SW Gen[TtAsyFr] * InputAve[TtAsyFr]) Units: dmnl
Total Covid Hospitalized[Rgn] = sum (Hospitalized Infectious[Rgn,TstSts!]) Units: Person
Total Disease Duration = Onset to Detection Delay + “Post-Detection Phase Resolution Time” + Incubation Period Units: Day
Total Simulated Tests[Rgn] = Post Mortem Tests Total[Rgn] + Testing on Living[Rgn] Units: Person/Day
Total Test on Covid Patients[Rgn] = Max (0, min (Positive Candidates Interested in Testing Poisson Subset[Rgn], Testing on Living[Rgn] - Tests on Negative Patients[Rgn]))Units: Person/Day
Total to Official Cases Simulated[Rgn] = ZIDZ (Cumulative Cases[Rgn], SimCmltOverTime[Rgn,Infection]) Units: dmnl
Total Weighted Infected Population[Rgn] = Infected pre Detection[Rgn] + “Pre-Symptomatic Infected”[Rgn] + Weighted Infected Post Detection Gate[Rgn] Units: Person
Transmission Multiplier for Confirmed[Rgn] = INITIAL(Baseline Transmission Multiplier for Untested Symptomatic * Confirmation Impact on Contact[Rgn]) Units: dmnl
Transmission Multiplier for Hospitalized[Rgn,TstSts] = INITIAL(Baseline Transmission Multiplier for Untested Symptomatic * Relative Risk of Transmission by Hospitalized * if then else (TstSts = 1, Confirmation Impact on Contact[Rgn], 1)) Units: dmnl
Transmission Multiplier Pre Detection[Rgn] = INITIAL(Baseline Transmission Multiplier for Untested Symptomatic * (1 - Total Asymptomatic Fraction Net[Rgn]) + Total Asymptomatic Fraction Net[Rgn] * Baseline Risk of Transmission by Asymptomatic[Rgn]) Units: dmnl
Transmission Multiplier Presymptomatic[Rgn] = INITIAL((Baseline Transmission Multiplier for Untested Symptomatic * Relative Risk of Transmission by Presymptomatic) * (1 - Total Asymptomatic Fraction Net[Rgn]) + Total Asymptomatic Fraction Net[Rgn] * Baseline Risk of Transmission by Asymptomatic[Rgn] * Relative Risk of Transmission by Presymptomatic) Units: dmnl
True Hazard of death[Rgn] = Death Rate[Rgn] / Susceptible[Rgn] Units: 1/Day
TstInc[Rgn] = Active Test Rate[Rgn] Units: Person/Day
TstSts : Tested,Notest
Untested PMAS Gap with Tested[Rgn] = (1 - Allocated Fration NonCOVID Hospitalized[Rgn]) ^ SensCovidUntestedAdmission Units: dmnl
Untested symptomatic Infected to Hospital[Rgn] = Hospital Admission Infectious[Rgn,Notest] Units: Person/Day
UsedSeries : Infection,Death
Utility from Limited Activities[Rgn] = exp (Sensitivity of Contact Reduction to Utility Net[Rgn] * Fractional Value of Limited Activities) Units: dmnl
Utility from Normal Activities[Rgn] = exp (Sensitivity of Contact Reduction to Utility Net[Rgn] * (1 - Perceived Risk of Life Loss[Rgn])) Units: dmnl
Voluntary Reduction in Contacts[Rgn] = F[Rgn] / F0[Rgn] * (1 - Min Contact Fraction[Rgn]) + Min Contact Fraction[Rgn]Units: dmnl
W Ave Acuity Hospitalized[Rgn] = ZIDZ (sum (Average Acuity Hospitalized[Rgn,TstSts!] * Hospitalized Infectious[Rgn,TstSts!]), sum (Hospitalized Infectious[Rgn,TstSts!])) Units: dmnl
Weather Effect on Transmission[Rgn] = CRW[Rgn] ^ Sensitivity to Weather Net[Rgn] Units: dmnl
Weight Max in Test Goal = 0 Units: dmnl
Weight on Reported Probability of Infection[Rgn] = 0.78 Units: dmnl
Weighted Infected Post Detection Gate[Rgn] = “Infected Unconfirmed Post-Detection”[Rgn] + Infectious Confirmed Not Hospitalized[Rgn] + sum (Hospitalized Infectious[Rgn,TstSts!]) * “Post-Detection Phase Resolution Time” / Hospitalized Resolution Time Units: Person
WTestFlowErr[Rgn] = if then else (DataFlowOverTime[Rgn,Test] = :NA:, 0, 1 / Max (10, DataFlowOverTime[Rgn,Test] * TestErrorFrac)) Units: Day/Person
Y[Rgn] = min (1, Max (1e-06, 1 - exp (− Extrapolated Estimator[Rgn]))) Units: dmnl
Ymix[Rgn,p2] = - b[Rgn] / (1 + a[Rgn])
Ymix[Rgn,p3] = (Sqrt (a[Rgn] ^ 2 - 4 * b[Rgn]) - a[Rgn]) / 2
Ymix[Rgn,p4] = (−0.87358 * a[Rgn]) / t3[Rgn] + 0.38157 * t3[Rgn] Units: dmnl
Acknowledgements
We thank Tom Fiddaman and Ventana Systems for access to the Vensim parallel simulation engine; Stephen Eubank, Navid Ghaffarzadegan, and Madhav Marathe for thoughtful comments on an earlier draft; X.H. Chan and K. Jani for sharing clinical insights; and Nezam Jazayeri for assistance with graphs.
Footnotes
- Updated with data until October 30, 2020 - Added 5 countries to the estimates - Incorporated impact of adherence fatigue - Incorporated the impact of learning on fatality reduction - Enhanced out of sample prediction test - Added comparison with seriological data - Edited the manuscript extensively
↵1 In the equations below we use short-hands to simplify mathematical notations. The full model documentation uses full variable names. Table S1 provides the mapping between the short-hands and the full names, as well as the sources and equations for those variables and parameters discussed below.
↵2 https://blog.ons.gov.uk/2020/03/31/counting-deaths-involving-the-coronavirus-covid-19/
↵3 https://www.cdc.gov/coronavirus/2019-ncov/cases-updates/previous-testing-in-us.html
↵4 See e.g. https://www.wcvb.com/article/massachusetts-coronavirus-reporting-delay-due-to-quest-lab-it-glitch/32288903#
↵5 It may be argued that there are weekly cycles in large-scale human behaviour that may drive some true weekly cyclicality in the true rates of infection and death, and as such it may be wrong to consider such cycles to be artefacts of the data- generation process. However, we find this unlikely for a few reasons. First, weekly cycles in human interactions, largely driven by the work and school week and weekend, will have been significantly attenuated by widespread adoption of social distancing measures around the world. Second and more importantly, variation in incubation period and time before development of symptoms means that any true cyclicality in the timing of initial infection will be further attenuated in the timing of symptom development. By the same logic, wide variability in the delay from symptom development to death means there should be minimal cyclicality, if any, in the timing of deaths, meaning any such cycles visible in the data are due to measurement and reporting lags.
↵6 https://docs.scipy.org/doc/scipy/reference/generated/scipy.interpolate.PchipInterpolator.html
↵7 Cleveland R.B., Cleveland W.S., McRae J.E., Terpenning I. (1990) STL: A seasonal-trend decomposition procedure based on Loess. J Off Stat 6: 3-73
↵8 https://www.statsmodels.org/stable/generated/statsmodels.tsa.seasonal.STL.html
References and notes




