
Abstract
Epidemiological models are widely used to analyse the spread of diseases such as the global COVID-19 pandemic caused by SARS-CoV-2. However, all models are based on simplifying assumptions and on sparse data. This limits the reliability of parameter estimates and predictions.
In this manuscript, we demonstrate the relevance of these limitations by performing a study of the COVID-19 outbreak in Wuhan, China. We perform parameter estimation, uncertainty analysis and model selection for a range of established epidemiological models. Amongst others, we employ Markov chain Monte Carlo sampling, parameter and prediction profile calculation algorithms.
Our results show that parameter estimates and predictions obtained for several established models on the basis of reported case numbers can be subject to substantial uncertainty. More importantly, estimates were often unrealistic and the confidence / credibility intervals did not cover plausible values of critical parameters obtained using different approaches. These findings suggest, amongst others, that several models are oversimplistic and that the reported case numbers provide often insufficient information.
Introduction
Epidemiological models are essential tools in public health as they facilitate assessments and forecasts of the spread of infectious diseases. This has been for instance demonstrated for influenza [1], dengue [2], Ebola [3], Zika [4], and – most recently – COVID-19 [5, 6]. These assessments and forecasts are the basis for political decision making [7] and therefore of vital importance.
The spectrum of mathematical modelling approaches in epidemiology ranges from relatively simple ordinary differential equation (ODE) models [8–10], partial differential equation (PDE) models [11, 12], stochastic differential equation (SDE) models [13–15], continuous-time discrete-state Markov chain (CTMC) models [15–17], to complex agent-based models [18, 19]. While ODE, PDE and SDE models provide descriptions at the population level, agent-based models are centered around formulations of the properties and dynamics of individuals. Some models explicitly account for space (usually in terms of countries, regions and/or cities) to capture spreading. Furthermore, models for the infection spread are usually combined with models of testing and reporting strategy to link them to the observed case number [20].
The choice of the modelling approach depends on the purpose of the study, the availability of information about the underlying disease and population, and the amount and quality of experimental data. Yet, all these models rely on estimates of parameter values. The parameters of epidemiological models are mostly inferred using frequentist and Bayesian parameter estimation methods. Frequentist methods often rely on parameter optimisation for obtaining point estimates and profile likelihoods for uncertainty analysis [21]. Bayesian methods exploit sampling strategies such as Markov chain Monte Carlo (MCMC) methods [20, 22] or variational inference [23]. Also flexible emulator based methods based, e.g. on Gaussian process, have been applied [24]. For applications in which competing hypotheses are available, the parameter estimation is often complemented by model selection. Established model selection measures include the Akaike Information Criterion (AIC) [25], the Bayesian Information Criterion (BIC) [26], or Bayes factors [27].
In this study, we exploit state-of-the-art parameter estimation and model selection approaches to perform an analysis of the COVID-19 outbreak in Wuhan, China. The first cases of COVID-19 were reported on December 30, 2019 and the Chinese Center for Disease Control and Prevention confirmed the isolation of a novel virus on January 7, 2020 [28]. Already by January 27, there were 1590 confirmed cases which include severe cases and 85 cumulative death cases in Wuhan, and several exported confirmed cases to Cambodia, Canada, France, Japan, Malaysia, Nepal, Republic of Korea, Singapore, Thailand, United States of America, and Vietnam [29]. As SARS-CoV-2 spread quickly, the Director-General of World Health Organisation (WHO) declared the flood of infections caused by SARS-CoV-2 a global pandemic on March 11 [30].
Our study complements other modelling efforts [31–43] by considering multiple established model types, observables, parameter estimation and model selection approaches. To recapitulate the situation in the beginning of the pandemic, we limit the use of prior knowledge to a minimum. This highlights challenges, e.g. the limited information content of case numbers and the dependence on proper model topology, but also opportunities for quantitative modelling in epidemiology.
Results
Observable selection and parameter identifiability
For this study, we considered the case numbers reported by the Hubei Province Health Commission and Wuhan Municipal Health Commission [44, 45]. These case numbers were particularly relevant for the analysis of the early transmission dynamics and the planning of interventions. Accordingly, these data were the basis of several modelling studies on the dynamics of COVID-19 epidemic (see e.g. [34, 38–40, 46–49]). Here, we used the time interval from January 9 to February 9, as afterwards the definition of a positive test changed [50], which limits the comparability.
The Chinese Center for Disease Control and Prevention provides time-resolved information on:
Reported number of infected individuals: yI(t)
Reported number of recovered individuals: yR(t)
Reported number of deceased individuals: yD(t)
Reported cumulative number of infected individuals: yT (t) = yI(t) + yR(t) + yD(t)
The reported number of deceased individuals is probably most accurate, yet the overall reliability of the measurement and the distribution of the errors is unknown. As in the literature different combinations of these observables are used for model parameterisation, we consider here the following fitting scenarios:
O1: Observations of yT and yD
O2: Observations of yI and yD
O3: Observations of yI, yR and yD
As different studies considered different aspects of the data, we first asked which scenario is most suited to determine the parameters of the infection process.
To address this question, we employed a deterministic Susceptible-Exposed-Infectious-Recovered-Deceased (SEIRD) model [51]. This compartmental model describes the size of the susceptible (S), exposed (E), infectious (I), recovered (R) and deceased (D) subgroups (Figure 1A). The time-dependence of the subgroup sizes is governed by the ODEs:

(A) Schematic of the SEIRD model. (B,C,D) Fitting results for observation scenarios O1, O2, and O3 assuming log-normally distributed measurement noise. The simulation for the maximum likelihood estimate (line) and interval for +/− one standard deviation of the inferred noise level (shaded area) is depicted.
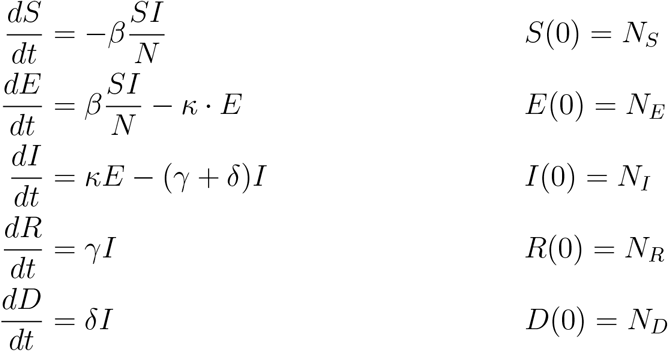 in which β is the average number of contacts per person per time which result in an infection, κ is the rate at which exposed individuals become infectious, γ is the rate at which infectious individuals recover, δ is the rate at which infectious individuals decease, and N = S(t) + E(t) + I(t) + R(t) + D(t) is the overall population size. Note that the inverse of the rate κ is the average incubation time TE = κ−-1. The initial conditions for the different state variables are given by NS, NE, NI, NR and ND. The initial conditions are usually non-zero and have to be inferred along with the unknown model parameters. Following previous work [52], we applied the simplifying assumption that infectious individuals are observed.
in which β is the average number of contacts per person per time which result in an infection, κ is the rate at which exposed individuals become infectious, γ is the rate at which infectious individuals recover, δ is the rate at which infectious individuals decease, and N = S(t) + E(t) + I(t) + R(t) + D(t) is the overall population size. Note that the inverse of the rate κ is the average incubation time TE = κ−-1. The initial conditions for the different state variables are given by NS, NE, NI, NR and ND. The initial conditions are usually non-zero and have to be inferred along with the unknown model parameters. Following previous work [52], we applied the simplifying assumption that infectious individuals are observed.
For all observable scenarios we performed a maximum likelihood estimation assuming normally as well as log-normally distributed measurement noise with unknown standard deviations (see Materials and Methods). The multi-start local optimisations converged (Supplementary Figure S1A) and the simulations with the maximum likelihood estimates achieved a good agreement with the observed data (Figure 1B-D and Supplementary Figure S1C-E). This confirms the findings of other research groups showing that the SEIRD model is sufficient to describe the dynamics of the COVID-19 outbreak in Wuhan. The comparably low noise levels inferred for the number of deceased individuals confirms our expectation that these observations are most reliable. Model selection based on AIC and BIC indicated a strong support for log-normally distributed measurement noise (Supplementary Figure S1B).
For an in-depth analysis of the impact of the choice of observables, we performed uncertainty analysis using frequentist and Bayesian methods (Figure 2). Profile likelihood calculation and MCMC sampling revealed that O3 provides improved parameter identifiability and decreased parameter uncertainties compared to O1 and O2 (Figure 2A-C). This was to be expected as O3 uses three observables (I, R and D) while O1 and O2 use two observables (and a subset of the information encoded in O3). Interestingly, the large parameter uncertainties for O1 and O2 are only partially reflected in the prediction uncertainties (Figure 2D-F) due to a strong parameter correlation (Supplementary Figure S2,S3,S4).

(A-C) Parameter confidence / credibility intervals obtained using profile calculation and MCMC samples. The gray lines indicate the employed parameter boundaries. (D-F) Posterior of state variables obtained by MCMC sampling. Medians (line) and 99% confidence (dashed lines) / credibility intervals (area) are indicated.
The most critical observation was that the parameter estimates are not realistic and that the credibility intervals derived from the MCMC samples are too narrow. The 99%-credibility intervals for O1, O2 and O3 suggested that κ is in the interval of [0.35, 4.11] × 10−4 days−1 This would imply an incubation period of [0.24, 2.83] × 104 days. This is unrealistic and not consistent with the estimates reported by the WHO which indicate a median incubation time of 5-6 days [53]. Similar inconsistencies are observed for the basic reproduction number. Not only the Bayesian parameter estimates are off, but also the maximum likelihood estimates. However, in contrast to narrow 99%-credibility intervals computed from MCMC samples, the 99%-confidence intervals derived from profile likelihoods are broad and cover realistic values. This indicates that estimates derived from case numbers can be unrealistic and their reliability should be assessed using different approaches.
As the information encoded in the number of reported cases during the initial infection appears insufficient, we complemented it in the following with a log-normal prior for the incubation period as specified in the Materials and Methods section. The parameters of the prior are derived from the work of [54], which is based on the infections among travellers from Wuhan. As O3 with this prior achieves plausible estimates, we considered for the remainder this setup (Figure 3A).

(A-D) Illustration of model structures (top) and model-data comparison (bottom). The simulation for the maximum likelihood estimate (line) and interval for +/− one standard deviation of the inferred noise level (shaded area) is depicted.
Analysis of transmission process
The SEIRD model with the prior on the incubation period provides a reasonable description of the case numbers reported for Wuhan (Figure 3A). Yet, this widely used model disregards the observation that patients are asymptomatic [55]. These patients can be infectious but are more difficult to detect. To study the impact of asymptomatic patients, we consider besides the basic SEIRD model (M1) also two alternative epidemiological models:
M2: A SAIRD model considering asymptomatic individuals (A) with transmission rate ζ and symptomatic individuals (I) with transmission rate β. The asymptomatic individuals are assumed to become symptomatic.
M3: A SAIRD model similar to M2, which allows for the direct recovery of asymptomatic patients. The recovered asymptomatic patients (R′) are assumed to remain unreported.
We assume that the reported number of infected individuals corresponds to the number of symptomatic patients (I). Accordingly, the reported number of recovered individuals is assumed to count only previously symptomatic individuals.
As a further model extension, we consider the possibility of waning immunity. A recent study suggested that the infection with SARS-CoV-2 does not necessarily induce a long-lived antibody response [56]. This has, to the best of our knowledge, not yet been evaluated using model-based approaches. To address this, we consider:
M4: A SAIRD model similar to M2, which allows recovered individuals (R) to become susceptible (S) with rate ρ.
The parameters of models M1-M4 were estimated using multi-start local optimisation. The simulations of models M1 to M4 for the respective maximum a posterior estimate show a reasonable agreement with the data (Figure 3). Interestingly, while the simulations for M1, M2 and M4 are similar, the simulation for M3 shows an early saturation (Figure 3C). The reason is that the initial number of unobserved recovered patients (which can also be interpreted as immune patients) is estimated to be very high, which does not appear to be plausible.
As the fitting results for all models were highly reproducible (Figure 4A), we evaluated the AIC and BIC for model selection (Figure 4B,C). As all models achieved a relatively similar fit, the complexity penalisation has a critical impact and the ranking differs for AIC and BIC, suggesting that the differences are minor. Only M4 was consistently not supported by the available data. The model selection revealed again the limited information content of the case numbers as there is clear evidence for the relevance of asymptomatic cases.

(A) Waterfall plots for the best 100 out of 200 multi-start runs. The optimisation runs are sorted by increasing negative log-likelihood value. The lower panel shows a magnification of the best 20 starts. (B) Differences in AIC with respect to the lowest value indicate M3 as the most plausible model. (C) Differences in BIC with respect to the lowest value indicate M3 as the most plausible model. Black dashed line in (B) and (C) depicts a change of 10 units considered as a rejection threshold.
To assess the uncertainty of the parameter estimates and predictions, we computed the profile likelihoods and performed MCMC sampling (Figure 5A-D). The results indicate that the parameter uncertainties for M2-M4 are larger than for M1, but that most parameters are well determined. The profile likelihoods yield overall more conservative estimates than the sampling. The predictions of the state variables based on the sampling suggest low uncertainties of all model states (Figure 5E-H). In particular for M3 this appears unrealistic as there are so far no reports about a large number of immune individuals (Figure 5G).

(A-D) Confidence / credibility intervals for the model parameters obtained using profile calculation and MCMC sampling. The gray lines indicate the employed parameter boundaries. (E-H) Confidence / credibility intervals for the state variables obtained using prediction profile likelihood calculation and MCMC sampling. Medians (line) and 99% confidence (dashed lines) / credibility intervals (area) are indicated.
Analysis of intervention effect
A key question in many recent studies is how much interventions such as compulsory masks and social contact restrictions, as well as the rising public awareness impact the transmission rate of SARS-CoV-2. To study how well this question can be assessed based on early case report data, we considered three simple scenarios:
No change of the transmission rate.
Discrete change in the transmission rate due to the compulsory masks introduced by the government in Wuhan on January 22 and substantially increasing contract restrictions.
Continuous change in the transmission rate due to rising public awareness and a broad spectrum of interventions.
These scenarios are illustrated in Figure 6 and a detailed mathematical description is provided in the Materials and Methods section.

Schematic of distinct intervention effects influencing β and ζ. TC denotes the time at which an intervention is performed.
As the result of the analysis of the infection dynamics carried out in the previous section was inconclusive, we considered model M1 to M4. For all 12 combinations of model structures and intervention effects, we performed parameter estimation and uncertainty analysis. The assessment of the model selection criteria provided support for a discrete change in the transmission rate on January 22 (Figure 7A). The resulting model provides an accurate description of the data and suggests that the transmission rate dropped by around 71% (Figure 7B). The uncertainty estimates for the decrease (Δ) depend heavily on the analysis approach. While MCMC sampling yields a 99% credibility interval from 37.9 to 76.4%, the profiles suggests a much broader regime (Figure 7C). Accordingly, the reported case number for the early outbreak were not sufficient for an accurate assessment of all model parameters. Despite the parameter uncertainties, the states seem to be relatively well determined (Figure 7D).

(A) Model selection using AIC weights (top) and BIC weights (bottom). (B) Best model fit (top) and estimated intervention effect (bot-tom). The simulation for the maximum likelihood estimate (line) and interval for +/− one standard deviation of the inferred noise level (shaded area) is depicted. (C) Confidence / credibility intervals for the model parameters obtained using profile calculation and MCMC sampling. The gray lines indicate the employed parameter boundaries. (D) Confidence / credibility intervals for the state variables obtained using prediction profile likelihood calculation and MCMC sampling. Medians (line) and 99% confidence (dashed line) / credibility intervals (area) are indicated.
Discussion
Pandemics pose a global challenge and show the importance of model-based forecasting. Forecasts influence the political decision-making process and have a significant impact on our society. Minimising model uncertainties and properly evaluating them is therefore crucial. Yet, many publications are still only using reported case number and/or omit an identifiability and uncertainty analysis [33–35, 39, 57–60]. Here, we demonstrated that both aspects are problematic.
Our analysis of the COVID-19 outbreak in Wuhan demonstrates that the parameterisation of epidemiological models can result in incorrect parameter estimates and predictions. Surprisingly, even Bayesian uncertainty analysis using MCMC sampling resulted in an underestimation of the indeterminacy and provided inaccurate predictions. In our opinion there are two reasons for this:
The models considered here and used in various other publications are too simple. They neglect for instance the stochastic nature of the process [61, 62], the heterogeneity of the population (e.g. the age structure [63]), time-dependent testing and reporting protocols [50], and particularities of the process (e.g. a large number of asymptomatic cases [64]). As the parameter estimates depend on the model characteristics, oversimplifications can result in biased estimates and predictions.
The case report data provide only limited information about the process, in particular the distribution of inter-event times are difficult of reconstruct.
Besides parameter estimation, the aforementioned limitations of case numbers were observed in the model selection process. The data did, for instance, not allow to unravel that a large number of the asymptomatic cases is not detected.
We observed that detailed prior information is required if merely case numbers are employed for parameter estimation. While literature-based priors are used in many manuscripts [65], we hypothesise that it would be better to use information about individual cases for parameter estimation and model selection. In particular the date of the onset of symptoms, the date of the positive test, and the date of recovery/death for individuals is highly relevant. These data are being collected and analysed [54, 66–68], but should in the future be shared much earlier. Furthermore, randomised testing would be required, ideally using antibody tests to determine the fraction of completely asymptomatic patients. Such studies are usually not possible during an initial phase of a pandemic but are now on the way [69].
This study does not offer new insights into the COVID-19 pandemic. However, it pin-points important pitfalls and showcases the relevance of the underlying assumptions and the available data. Furthermore, it demonstrates that even a proper uncertainty analysis using state-of-the-art frequentist or Bayesian approaches does not ensure that the true parameters and dynamics are captured within the uncertainty bounds. While we demonstrate this aspect here for deterministic compartmental models – which are the basis of many modelling studies for COVID-19 and beyond – it certainly holds also for other modelling approaches. Similarly, model-free studies are based on assumptions, data and statistical models, rendering them subject to at least the same limitations.
Materials and Methods
Data
The study is based on official reports on the total number of cases and the numbers of infected individuals, recovered individuals and deceased individuals. From January 11 to 20, the reports were made available by the Wuhan Municipal Health Commission [45]. Afterwards, the reports were organised by the Health Commission of Hubei Province [44]. The complete data sets are listed in Table 1.
Missing data in the official reports are indicated by “-”.
The exact population size in the city of Wuhan in the period under consideration is not precisely known due to Chinese New Year. In this study we assume a population size of 9 million which was mentioned by the mayor of Wuhan, Zhou Xianwang [70].
Mathematical models
We considered four different deterministic compartmental models for the description of the transmission process. The state variables of the models are the number of individuals with particular characteristics and the notations can be found in Table 2.
The models allow for various processes which result in the transitions of individuals between compartments (see Figure 3). A description of the rates is provided in Table 3. For the time-dependence of the transmission rates β And ζ,
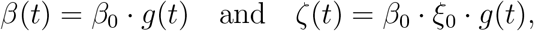 we considered three scenarios:
we considered three scenarios:
No change: g(t) = 1
Discrete change:

Continuous change: g(t) = e−kt
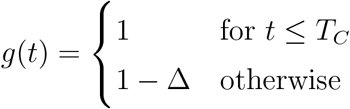
The function g(t) describes the reduction of the transmission rates compared to baseline at t = 0, with g(0) = 1 for all scenarios. The parameters for the discrete change are the time point TC and the relative reduction Δ, and for the continuous change we have the decay rate k. The parameter 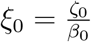 denotes the relative difference between the transmission rates of the symptomatic individuals (β(t)) and asymptomatic individuals (ζ(t)).
denotes the relative difference between the transmission rates of the symptomatic individuals (β(t)) and asymptomatic individuals (ζ(t)).
The ODEs governing the dynamics of the different compartmental models are provided in Table 5. We decided to initialise the model on January 9 since which the virus was detected [71], defining t = 0. As on January 22 the wearing of masks became mandatory, we set for the scenario of a discrete reduction of β for TC = 13 days.
Nominal values, lower bounds, upper bounds, priors and units for the model parameters. The nominal values are only used for model parameters which are not fitted.
ODEs for the transmission dynamics, initial conditions and observations functions are defined for all considered model structures. As some models consider only a subset of the state variables, some rows are empty.
The state variables of the model were linked to the observed case numbers using observation functions. The observation functions for the total number of cases (yT) as well as for the number of infected (yI), recovered (yR) and deceased (yD) people are provided in Table 5. As the reported numbers are subject to unknown measurement noise, we considered two error models:
Additive normally distributed measurement noise:
Multiplicative log-normally distributed measurement noise:
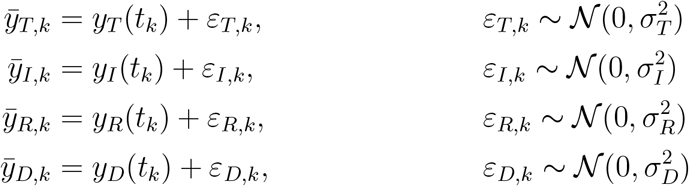

The observation time points tk, k = 1, …, 32, are the days listed in Table 1, and the measurements (as indicated with the superscript m) are the respective case numbers. The distribution parameters σT, σI, σR and σD were considered as unknown.
In the following the parameters of the transition rates, the total and initial number of people in different compartments, and the parameters of the noise distribution are inferred. A comprehensive list of all model parameters and implemented constraints is provided in Table 4. The boundaries of the search space were chosen very conservatively to indicate the initial knowledge gap about SARS-CoV-2 and COVID-19.
Parameter estimation
To infer the unknown model parameters we used frequentist and Bayesian approaches. These approaches considered the conditional probability p(𝒟|θ) of the data 𝒟 given the parameters θ, also known as likelihood. For additive normally distributed measurement noise the likelihood function is
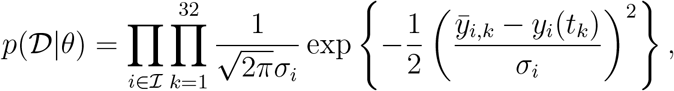 and for multiplicative log-normally distributed measurement it is
and for multiplicative log-normally distributed measurement it is
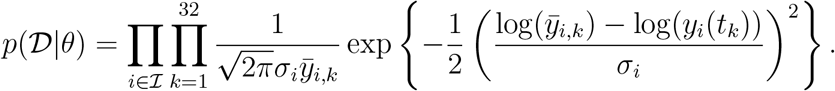
The set of considered observables is encoded by ℐ and differs for the scenarios O1 to O3: ℐO1 = {T, D}, ℐO2 = {I, D}, and ℐO3 = {I, R, D}. In addition to the case reports, we also incorporated knowledge available before the parameter estimation. For Bayesian approaches this was done by defining a prior distributions. These prior distributions are mostly log-uniform with conservative upper and lower bounds, meaning that the distribution over the log-transformed parameter values is flat. For κ we include in parts of the study information about the incubation period [54], given by a log-normal prior:
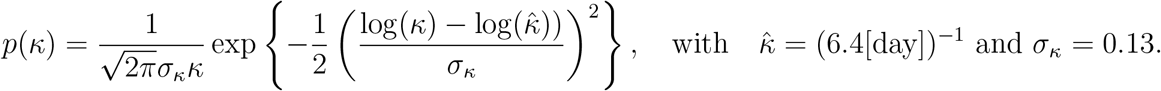
For the frequentist approaches the available estimate of κ is treated as a data point.
Remark: For the parameter estimation we consider the log-transformed parameter values. For the log-transformed parameters, the log-uniform prior become effectively a uniform prior. This renders the frequentist and the Bayesian approaches comparable, namely, the maximum likelihood and the maximum a posteriori estimates coincide.
Maximum likelihood and maximum a posteriori estimates
To determine the maximum likelihood and the maximum a posteriori estimates, we minimised the negative log-likelihood function and negative log-posterior function, respectively. As these optimisation problems are non-linear and non-convex, we used multi-start local optimisation. The starting points for the local optimisations were generated using latin hypercube sampling. Local optimisation was performed using the interior point algorithm implemented in the MATLAB function lsqnonlin.m, which exploits the least-squares like structure of the optimisation problems. To facilitate convergence, we computed the gradients of the residuals via forward sensitivity equations. The convergence of the global optimisation was assessed using waterfall plots.
For each of the 18 considered combinations of compartment model, noise model, observable scenario and intervention scenario, we performed 200 local optimisations. For all combinations at least 15 runs converged to the observed global optimum. This suggested that the results are highly reliable.
Frequentist uncertainty analysis
To evaluate the (frequentist) parameter and prediction confidence intervals we used profile likelihoods [72, 73]. The profile likelihoods were computed using the MATLAB toolbox Data2Dynamics [74]. This toolbox implements optimisation-based methods with adaptive step-size selection as well as fast integration-based methods [75]. To ensure the robustness of the results, the consistency of the outcomes was checked and confirmed.
The profile likelihoods were used to derive the (finite sample) confidence intervals. For a significance level α, the bounds of the confidence interval were determined as the smallest and largest parameter values for which the profile likelihood stays above the threshold defined by the αth-percentile of the χ2-distribution [76]. We used the χ2-distribution with one degree of freedom which yields the so called point-wise confidence intervals.
Bayesian uncertainty analysis
To evaluate the (Bayesian) parameter and prediction credibility intervals we used Markov chain Monte Carlo sampling [77]. The parameter posterior distribution was sampled using the Adaptive Metropolis algorithm implemented in the MATLAB toolbox PESTO [78]. The methods are self-tuning and provided good convergence properties. Convergence after burn-in was assessed using the Geweke test [79]. The parameter samples were used to generate samples for the model states and observables.
The samples of parameters and predictions were used to derive the credibility intervals. For a credibility level α, the bounds of the credibility interval were determined as the 100α/2-and the 100(1 − α/2)-percentile of the respective sample. This procedure yields the so called equal-tailed interval.
Model selection
We considered competing hypotheses on the dynamics of the infection process, the effect of the intervention and the noise distribution. Each of the resulting models was assessed using the Akaike information criterion (AIC),
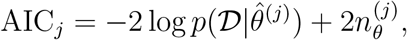 and the Bayesian information criterion (BIC),
and the Bayesian information criterion (BIC),
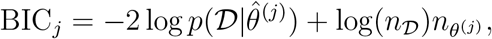 in which j is the model index,
in which j is the model index, 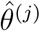 is the maximum likelihood estimate for the j-th model, and nθ(j) is the number of parameter of the j-th model. The number of independent data points is denoted by nD. AIC and BIC account for the likelihood of the data and penalise model complexity. Low AIC and BIC values are favorable. We consider a difference 10 between AIC/BIC values of different models as substantial [80].
is the maximum likelihood estimate for the j-th model, and nθ(j) is the number of parameter of the j-th model. The number of independent data points is denoted by nD. AIC and BIC account for the likelihood of the data and penalise model complexity. Low AIC and BIC values are favorable. We consider a difference 10 between AIC/BIC values of different models as substantial [80].
For analysis and visualisation we also evaluated the AIC and BIC weights [80]. The AIC weight for the j-th model is defined as
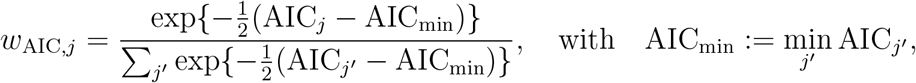 and provides the weight of evidence in favor of the j-th model being the actual best model in terms of the Kullback–Leibler Information (assuming that the true model is in the considered set). The BIC weight for the j-th model is defined as
and provides the weight of evidence in favor of the j-th model being the actual best model in terms of the Kullback–Leibler Information (assuming that the true model is in the considered set). The BIC weight for the j-th model is defined as
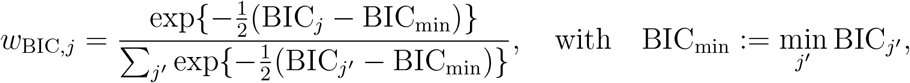 and provides an approximation to the Bayesian posterior probability of the j-th model. AIC and BIC weights are between 0 and 1, and a high value indicates a strong support.
and provides an approximation to the Bayesian posterior probability of the j-th model. AIC and BIC weights are between 0 and 1, and a high value indicates a strong support.
Implementation and availability
The model formulation, parameter estimation and profile likelihoods were performed in the MATLAB toolbox Data2Dynamics (https://github.com/Data2Dynamics/d2d) [74]. Outliers in the computed prediction profiles arising from calculation error were corrected subsequently. The calculation of parameter confidence intervals and MCMC sampling was carried out using the MATLAB toolboxes PESTO (https://github.com/ICB-DCM/PESTO) [78] and AMICI (https://github.com/ICB-DCM/AMICI) [81, 82]. For numerical integration Data2Dynamics and AMICI rely on the SUNDIALS solver CVODES [83].
The complete implementation (including the respective version of the used toolboxes) and data are available on ZENODO (https://doi.org/10.5281/zenodo.3757227). This includes the MATLAB code as well as the the specification of the parameter estimation problems as PEtab files [84] (with the model in SBML format [85]).
Data Availability
The complete implementation (including the respective version of the used toolboxes) and data are available on ZENODO (https://doi.org/10.5281/zenodo.3757227). This includes the MATLAB code as well as the the specification of the parameter estimation problems as PEtab files (with the model in SBML format).
Funding
This work was supported by the European Union’s Horizon 2020 research and innovation program (CanPathPro; Grant no. 686282; E.D., J.H., S.M.), the Federal Ministry of Education and Research of Germany (Grant no. 031L0159C; E.A. & Grant no. 01ZX1705; J.H.), the Federal Ministry of Economic Affairs and Energy (Grant no. 16KN074236; J.V.), and the German Research Foundation (Clusters of Excellence EXC 2047 & EXC 2151; E.R., F.B., J.H.).
Author contributions
J.H., F.B. designed the study. E.R., E.D., J.V. implemented the models. E.R., E.D. implemented the pipeline. F.B. extracted and formatted data. E.R., E.D., performed parameter estimation and model selection. E.A., L.F. researched the literature. S.M. implemented the models in the PEtab format. E.R., E.D., J.H. drafted the manuscript. All authors discussed and approved the study, and revised and approved the final manuscript.
Additional Information
No competing interests.
Supplementary Figures

(A) Waterfall plots for the best 150 out of 200 multi-start runs. The optimisation runs are sorted by increasing negative log-likelihood value. (B) AIC and BIC values. (C,D,E) Fitting results for observation scenarios O1, O2, and O3 assuming normally distributed noise. The simulation for the maximum likelihood estimate (line) and interval for +/− one standard deviation of the inferred noise level (shaded area) is depicted.

The scatter plot matrix for the MCMC samples are depicted. The maximum a posterior estimate (MAP) and the profile likelihoods with respect to the parameter in the x-axis and y-axis are indicated.

The scatter plot matrix for the MCMC samples are depicted. The maximum a posterior estimate (MAP) and the profile likelihoods with respect to the parameter in the x-axis and y-axis are indicated.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The scatter plot matrix for the MCMC samples are depicted. The maximum a posterior estimate (MAP) and the profile likelihoods with respect to the parameter in the x-axis and y-axis are indicated.
References
- [1].↵
- [2].↵
- [3].↵
- [4].↵
- [5].↵
- [6].↵
- [7].↵
- [8].↵
- [9].
- [10].↵
- [11].↵
- [12].↵
- [13].↵
- [14].
- [15].↵
- [16].
- [17].↵
- [18].↵
- [19].↵
- [20].↵
- [21].↵
- [22].↵
- [23].↵
- [24].↵
- [25].↵
- [26].↵
- [27].↵
- [28].↵
- [29].↵
- [30].↵
- [31].↵
- [32].
- [33].↵
- [34].↵
- [35].↵
- [36].
- [37].
- [38].↵
- [39].↵
- [40].↵
- [41].
- [42].
- [43].↵
- [44].↵
- [45].↵
- [46].↵
- [47].
- [48].
- [49].↵
- [50].↵
- [51].↵
- [52].↵
- [53].↵
- [54].↵
- [55].↵
- [56].↵
- [57].↵
- [58].
- [59].
- [60].↵
- [61].↵
- [62].↵
- [63].↵
- [64].↵
- [65].↵
- [66].↵
- [67].
- [68].↵
- [69].↵
- [70].↵
- [71].↵
- [72].↵
- [73].↵
- [74].↵
- [75].↵
- [76].↵
- [77].↵
- [78].↵
- [79].↵
- [80].↵
- [81].↵
- [82].↵
- [83].↵
- [84].↵
- [85].↵




